一种基于新闻列表实时抓取方法与流程
本发明涉及一种基于新闻列表实时抓取方法。
背景技术:
网络爬虫是一种自动搜集互联网信息的程序。通过网络爬虫不仅能够为搜索引擎采集网络信息,而且可以作为定向信息采集器,定向采集某些网站下的特定信息。
目前,传统意义上的爬虫无法保证数据的实时抓取,在抓取时,会产生重复抓取,延长搜索时间,降低了数据检索的效率。
技术实现要素:
针对以上不足,本发明所要解决的技术问题是提供一种基于新闻列表的实时抓取方法,用于提高网页的检索效率。
为解决以上技术问题,本发明采用的技术方案是,
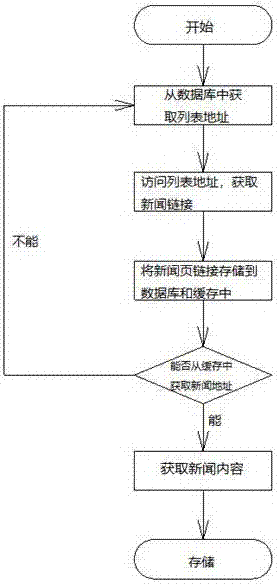
一种基于新闻列表实时抓取方法,包括以下步骤,
(1)输入新闻列表页地址;
(2)读取、访问网页数据;
(3)获取地址列表;
(4)分别在数据库和缓存中进行存储;
(5)从缓存中读取地址,通过数据库判断子地址数量;
(6)抓取网站地址中的内文本内容;
(7)将抓取的文本内容进行存储。
在采用以上技术方案的同时,本发明还进一步采用或者组合采用了以下技术方案。
步骤(6)中对网站地址抓取完成后,将抓取的网站地址标记地址状态为已抓取,返回步骤(4)。
当步骤(5)中输出的地址数量为0时,返回步骤(2);当步骤(5)中输出的地址数量不为0时,进行步骤(6)。
该抓取方法还包括数据更新方法和数据查询方法。
数据查询方法包括以下步骤,
数据查询方法包括以下步骤,
1)从缓存中取数据;
2)请求路由到对应的内存队列,并交给队列进行处理;
3)判断能否从缓存中取到数据;
4)若不能取到数据,则从数据库中查询;
5)判断数据库中是否存在该数据;
6)若存在数据,则创建强制刷新缓存请求,并加入列队中;
7)内存列队对数据进行处理;
8)若不存在数据,则将该数据挂起,不做任何处理,处于一个等待的状态;
当步骤3)中能取到对应数据时,则直接将数据发送至内存列队对数据进行处理。
数据更新方法包括以下步骤,
1)将缓存中的数据删除;
2)更新数据库中的数据。
本发明的有益效果是,通过在原有爬虫技术的基础上加入缓存技术,可以避免网站列表的重复抓取,也可以在较短的时间内获取最新的新闻列表数据。
附图说明
图1是本发明的流程图。
图2是数据查询流程图。
具体实施方式
下面结合附图对本发明进行进一步描述。
一种基于新闻列表实时抓取方法,包括以下步骤,
(1)输入新闻列表页地址;
(2)读取、访问网页数据;
(3)获取地址列表;
(4)分别在数据库和缓存中进行存储;
(5)从缓存中读取地址,通过数据库判断子地址数量,并保证数据库与缓存同步;
(6)抓取网站地址中的内文本内容;
(7)将抓取的文本内容进行存储。
步骤(6)中对网站地址抓取完成后,将抓取的网站地址标记地址状态为已抓取,返回步骤(4),进行循环从缓存数据库中读取地址进行页面抓取,当缓存数据库中的地址待抓取的状态为0时,程序请求地址列表页地址,继续获取列表子页,当获取的地址重复时程序挂起,否则继续请求。
当步骤(5)中输出的地址数量为0时,返回步骤(2);当步骤(5)中输出的地址数量不为0时,进行步骤(6)。
该抓取方法还包括数据更新方法和数据查询方法。
数据查询方法包括以下步骤,
1)从缓存中取数据;
2)请求路由到对应的内存队列,并交给队列进行处理;
3)判断能否从缓存中取到数据;
4)若不能取到数据,则从数据库中查询;
5)判断数据库中是否存在该数据;
6)若存在数据,则创建强制刷新缓存请求,并加入列队中;
7)内存列队对数据进行处理;
8)若不存在数据,则将该数据挂起,不做任何处理,处于一个等待的状态;
当步骤3)中能取到对应数据时,则直接将数据发送至内存列队对数据进行处理。
步骤6)中,如果不能从缓存取到数据,则等待20毫秒,强制刷新缓存,同步缓存与数据库间的数据,然后再次取数据,如果超过200毫秒还不能取到数据,则从数据库中取,并强制刷新缓存数据。
数据更新方法包括以下步骤,
1)将缓存中的数据删除;
2)更新数据库中的数据。
在一些优选的方式中,在进行数据查询时,每个查询对象均设有id标志位,在查询过程中对id标志位进行判断,若id标志位存在,则判断id标志位为ture还是false,若为false则结束,进行下一个查询,若为ture,则刷新数据库缓存;若id标志位不存在,则直接刷新数据库缓存。
技术特征:
技术总结
一种基于新闻列表实时抓取方法,包括以下步骤,输入新闻列表页地址;读取、访问网页数据;获取地址列表;分别在数据库和缓存中进行存储;从缓存中读取地址,通过数据库判断子地址数量;抓取网站地址中的内文本内容;将抓取的文本内容进行存储,通过在原有爬虫技术的基础上加入缓存技术,可以避免网站列表的重复抓取,也可以在较短的时间内获取最新的新闻列表数据。
技术研发人员:贝超
受保护的技术使用者:中译语通科技股份有限公司
技术研发日:2018.08.29
技术公布日:2019.01.25
- 还没有人留言评论。精彩留言会获得点赞!