一种分布式多引擎数据质量管理系统的制作方法
本发明涉及计算机软件系统技术领域,尤其涉及一种分布式多引擎数据质量管理系统。
背景技术:
数据质量管理系统一般需要跨多系统或跨多数据源进行校验,为避免网络异常对跨库校验可能引起的影响或对源库造成的性能浪费,通常解决方案是通过etl技术将源数据抽到中间库中进行校验。但如果校验数据量十分庞大,或者中间库硬件要求不达标,使用sql对传统关系数据库数据进行检索,整个校验过程可能会是十分漫长,甚至会造成服务器宕机,影响用户使用体验,并且要对校验出来的问题数据进行进一步分析或展示,对校验库来说也是一个大考验。
技术实现要素:
本发明的目的在客服现有技术的不足,提供一种响应速度快、容错率高、对硬件要求较低的分布式多引擎数据质量管理系统。
为了实现以上目的,本发明所采用的技术方案是:
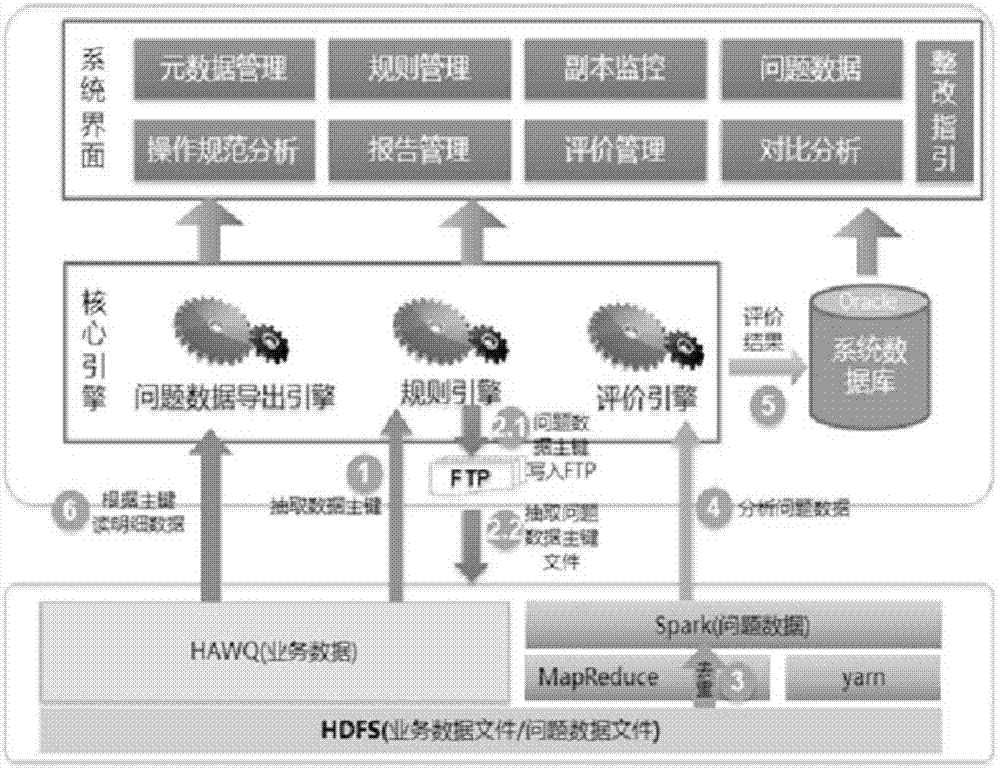
一种分布式多引擎数据质量管理系统,包括分布储存于多个设备内的数据库、前端系统界面以及用于从数据库内抽取数据至前端系统界面的核心引擎,所述数据库包括有业务数据以及问题数据,所述核心引擎包括有规则引擎、评价引擎和问题数据导出引擎;所述规则引擎抽取数据主键从数据库内抽取业务数据并,所述评价引擎使用分布式运算方式对问题数据进行数据去重和分类;所述问题数据导出引擎根据主键读取明细数据。
进一步,所述数据库为hwaq数据库并以hdfs文件作为业务数据以及问题数据的储存方式。
进一步,还包括有用于储存元数据于校验规则的oracle数据库。
进一步,所述规则引擎可并行执行n个任务,当规则引擎的任务数量大于n个时,根据预设规则的优先级对该多个任务进进行任务调度。
进一步,当所述规则引擎执行任务后将结果数据按主键分类并反馈至数据库中作为问题数据进行储存。
本发明的有益效果是:本发明的分布式多引擎数据质量管理系统,由于其数据库分布储存于多个设备内,使用分布式系统,可扩展性高,用低成本方案即可提高系统性能;可用性及容错性高,数据存储使用多副本策略,避免原节点宕机导致服务不可用。
附图说明
图1为本发明的分布式多引擎数据质量管理系统的原理图。
图2为本发明的规则引擎并行处理任务的示意图。
图3为本发明的拓扑图。
具体实施方式
现结合附图和具体实施例对本发明所要求保护的技术方案作进一步详细说明。
参见图1所示,本实施例中的分布式多引擎数据质量管理系统包括分布储存于多个设备内的数据库、前端系统界面以及用于从数据库内抽取数据至前端系统界面的核心引擎、用于储存元数据于校验规则的oracle数据库。
参见图3示,在本实施例中,用于储存数据库的设备包括有一个主控节点以及多个计算节点构成分布式数据储存平台,oracle数据库的储存设备与分布式数据储存平台之间通过应用服务器进行连接,所述分布式数据储存平台还连接营销库系统库集群、生产系统库集群、人力资源系统库集群以及其他业务系统库集群,从而对接不同的功能系统。在本实施例中,前期约有50台机器作为实际节点,后续可根据数据量适当扩容。在本实施例中,所述数据库包括有业务数据以及问题数据,所述数据库为hwaq数据库并以hdfs文件作为业务数据以及问题数据的储存方式。
在本实施例中,所述核心引擎包括有规则引擎、评价引擎和问题数据导出引擎;所述规则引擎抽取数据主键从数据库内抽取业务数据,一般情况下选取对象id主键作为数据主键,规则执行引擎执行规则时即可快速命中规则使用的对象记录,并使用分布式运算提高执行速度。
参见图2所示,所述评价引擎使用分布式运算方式对问题数据进行数据去重和分类,在本实施例中评价算分阶段,平台使用spark、hive使用分布式运算方式进行数据去重、分类,进而实现数据分析功能,此外评价引擎还对规则结果利用mapreduce技术进行去重、算分及对比分析,获取该次评价结果。。所述问题数据导出引擎根据主键读取明细数据,其中当所述规则引擎可并行执行n个任务,当规则引擎的任务数量大于n个时,根据预设规则的优先级对该多个任务进进行任务调度,当规则引擎完成相应的任务后所述规则引擎执行任务后将结果数据按主键分类并反馈至数据库中作为问题数据进行储存。
本实施例的分布式多引擎数据质量管理系统,其分布式多引擎数据质量管理系统分层体系架构可以提供系统最大的灵活性和可扩展性,层次与层次之间的逻辑分离,耦合度很低,系统具有高度的灵活性和可扩展性。系统底层依托基于hadoop的大数据平台,利用hive、spark框架以及多线程技术搭建多个核心引擎,最大限度拆分大数据并尽可能使用服务器性能并行完成多个校验、分析任务。任务完毕后再将问题数据以分布式存储,用户需要提取或系统需要对数据进行分析时亦能通过线程进行快速读取,提升用户体验并实现实时数据分析功能。
以上所述之实施例仅为本发明的较佳实施例,并非对本发明做任何形式上的限制。任何熟悉本领域的技术人员,在不脱离本发明技术方案范围情况下,都可利用上述揭示的技术内容对本发明技术方案作出更多可能的变动和润饰,或修改为等同变化的等效实施例。故凡未脱离本发明技术方案的内容,依据本发明之思路所作的等同等效变化,均应涵盖于本发明的保护范围内。
技术特征:
技术总结
本发明公开了一种分布式多引擎数据质量管理系统,包括分布储存于多个设备内的数据库、前端系统界面以及用于从数据库内抽取数据至前端系统界面的核心引擎,所述数据库包括有业务数据以及问题数据,所述核心引擎包括有规则引擎、评价引擎和问题数据导出引擎;所述规则引擎抽取数据主键从数据库内抽取业务数据并,所述评价引擎使用分布式运算方式对问题数据进行数据去重和分类;所述问题数据导出引擎根据主键读取明细数据。
技术研发人员:杨秋勇;杨朝谊;黄剑文;伍江瑶;魏理豪;万婵;陈健欣;范国勇;卢小攀;李松
受保护的技术使用者:广东电网有限责任公司信息中心;广州博纳信息技术有限公司
技术研发日:2018.09.27
技术公布日:2019.01.22
- 还没有人留言评论。精彩留言会获得点赞!