一种人脸图像融合方法与流程
本发明涉及一种图像融合方法,特别是涉及一种人脸图像融合方法。
背景技术:
人脸图像的融合即将两张不同的人脸图像融合成一张人脸图像,新得到的融合图像应保留有原人脸图像的面部特征。现目前最主流的融合方法是基于面部特征点匹配的方法,其主要依赖于基于人脸的面部特征工程,并已获得了较好的融合效果,但整个过程既复杂又耗时,而且这种方法会模糊目标图像的细节特征,也不具备扩展及多图像泛化的特性。
而由于gan生成的图像具有清晰和逼真等特性,因此也被广泛应用于图像生成方面,如alecradford等人提出了深度卷积性生成对抗网络,在这些网络中,对gan的卷积性架构拓扑进行了一组约束,使它们在大多数情况下都能稳定地进行训练;但是由于对抗生成网络gan从随机噪声点生成图像,它不能生成特定细节的图像,另外,生成式对抗模型参照图像中的样子,没有办法强制它所生成的图像必须看起来像图像本身。这就造成了图像的样式不会非常写实。
因此,需要一种新的人脸图像融合方法,去简化融合过程并实现完整保存人脸图像的面部细节的要求。
发明/
技术实现要素:
本发明主要解决的技术问题是提供一种人脸图像融合方法,能够解决现有融合方法存在的融合过程复杂耗时以及融合的结果图像不写实的问题。
为解决上述技术问题,本发明采用的一个技术方案是:提供一种人脸图像融合方法,它包括以下步骤:
将待融合的原始人脸图像输入到人脸融合网络模型中;
在人脸融合网络模型中设置相应的融合偏倚参数;
人脸融合网络模型根据输入的偏倚参数将输入的原始图像进行重构融合,输出融合后的目标图像。
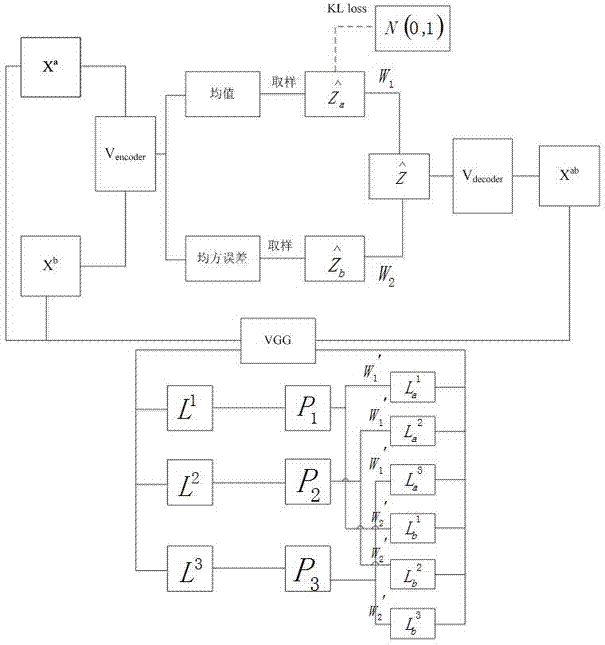
在进行所述将待融合的人脸图像输入到人脸融合网络模型中的步骤之前,还需要进行建立人脸融合网络模型;所述的人脸融合网络模型包括变分自动编码器vae和vgg网络;所述的变分自动编码器包括编码器vencoder和解码器vdecoder。
生成解码器vdecoder的步骤为:在变分自动编码器vae中引入一个隐藏向量z,得到解码器pθ(x|z),利用隐藏向量z重构原始图像x。
生成编码器vencoder的步骤为:根据解码器pθ(x|z)得到pθ(x|z)的后验分布pθ(z|x),利用神经网络得到pθ(z|x)的正态分布
人脸融合网络模型根据输入的偏倚参数将输入的图像进行融合,输出融合后的图像的具体步骤如下:
将输入的原始图像xa和xb输入到编码器vencoder中,得到两个服从正态分布的
将两个正态分布进行随机采集和处理得到一个100维特征向量
将100维特征向量
对融合得到的目标图像xab输入到vgg网络中,根据vgg网络进行优化。
步骤将两个正态分布进行随机采集和处理得到一个100维特征向量
将得到的两个正态分布
对特征向量
根据vgg网络进行优化包括求出度量重构的目标图像和原始图像之间差异性的重构误差以及通过kl散度使编码器vencoder输出的正态分布向标准正态分布看齐两部分构成。
求出度量重构的目标图像和原始图像之间差异性的重构误差的具体步骤为:
将原始图像xa和xb以及目标图像xab分别单独输入到vgg网络中,并提取原始图像xa和xb以及目标图像xab输出的前三个卷积层;
将原始图像xa和xb得到每一个卷积层输出结果进行加权求和;
将加权求和的结果结合目标图像xab的每一个卷积层输出结果求取均方误差,并将求得的各个均方误差进行求和得到重构误差的值。
人脸融合网络模型中设置相应的融合偏倚参数的步骤中,所述的融合偏倚参数包括w1和w2,其中w1和w2分别表示为特征向量
融合偏倚参数w1和w2的取值包括0或者1,其中0表示舍弃图像此维度的特征,1表示保留图像此维度的特征;并且两个融合偏移参数w1和w2的和为每个维度值为1的100维列向量。
本发明的有益效果是:区别于现有技术的情况,本发明通过vae和vgg网络的结合,利用vgg小卷积特征提取优势,获取输入的原始图像和新生成的目标图像的之间信息损失,并使其信息损失最小化,能够将两张人脸图像融合成一张自然完整的新的人脸图像,通过对融合偏倚参数的设置能够进一步的保存完整的头发的颜色、发型、面部表情等细节,且本方法具有融合处理过程简单快捷的特点。
附图说明
图1是本发明的网络结构图;
图2是本发明的第一实验图;
图3是本发明的第二实验图;
图4是本发明的第一对比实验图;
图5是本发明的第二对比实验图;
图6是本发明的第三对比实验图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中描述和示出的本发明实施例的组件可以以各种不同的配置来布置和设计。
因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
应注意到:相似的标号和字母在下面的附图中表示类似项,因此,一旦某一项在一个附图中被定义,则在随后的附图中不需要对其进行进一步定义和解释。
在本发明的描述中,需要说明的是,术语“上”、“内”、“外”等指示的方位或位置关系为基于附图所示的方位或位置关系,或者是该发明产品使用时惯常摆放的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
在本发明的描述中,还需要说明的是,除非另有明确的规定和限定,术语“设置”、“安装”、“连接”应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或一体地连接;可以是机械连接,也可以是电连接;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通。对于本领域的普通技术人员而言,可以具体情况理解上述术语在本发明中的具体含义。
如图1所示,一种人脸图像融合方法,它包括以下步骤:
s1、将待融合的两张不同原始人脸图像输入到人脸融合网络模型中;
s2、在人脸融合网络模型中设置相应的融合偏倚参数;
s3、人脸融合网络模型根据输入的偏倚参数将输入的原始图像进行重构融合,输出融合后的目标图像。
在进行所述将待融合的人脸图像输入到人脸融合网络模型中的步骤之前,还需要进行建立人脸融合网络模型;所述的人脸融合网络模型包括变分自动编码器vae和vgg网络;所述的变分自动编码器包括编码器vencoder和解码器vdecoder。
优选地,在建立好人脸融合网络模型之后,通过数据集celeba对人脸融合网络模型进行训练,并进行实验来验证对融合结果产生影响的融合偏倚参数。
生成解码器vdecoder的步骤为:在变分自动编码器vae中引入一个隐藏向量z,通过z来自动生成目标图像,得到解码器pθ(x|z),利用隐藏向量z重构原始图像x。
生成编码器vencoder的步骤为:根据解码器pθ(x|z)得到pθ(x|z)的后验分布pθ(z|x),认为pθ(z|x)是一种标准的正态分布,利用神经网络得到pθ(z|x)的正态分布
步骤s3人脸融合网络模型根据输入的偏倚参数将输入的原始图像进行融合,输出融合后的目标图像的具体步骤如下:
s31、将输入的两张不同的原始图像xa和xb输入到编码器vencoder中,得到相应的两个服从正态分布的
s32、将两个正态分布进行随机采集和处理得到一个100维特征向量
s33、将100维特征向量
s34、对融合得到的目标图像xab输入到vgg网络中,根据vgg网络进行优化。
步骤s32将两个正态分布进行随机采集和处理得到一个100维特征向量
s321、将得到的两个正态分布
s322、对特征向量
其中,参数w1和w2是100维的列向量,取值为0或者1,取值0表示向量
根据vgg网络进行优化包括求出度量重构的目标图像和原始图像之间差异性的重构误差以及通过kl散度使编码器vencoder输出的正态分布向标准正态分布看齐两部分构成。
求出度量重构的目标图像和原始图像之间差异性的重构误差的具体步骤为:
a1、将原始图像xa和xb以及目标图像xab分别单独输入到vgg网络中,并提取原始图像xa和xb以及目标图像xab输出的前三个卷积层;
a2、将原始图像xa和xb得到每一个卷积层输出结果进行加权求和;
a3、将加权求和的结果结合目标图像xab的每一个卷积层输出结果求取均方误差,并将求得的各个均方误差进行求和得到重构误差的值。
优选地,设la(i)表示xa关于第i个卷积层的输出;lb(i)表示xb关于第i个卷积层的输出;l(i)是x关于第i个卷积层的输出;其中i的取值范围从1到3;这样在每个卷积层上,加权求和的表达式为:
pi=w1×la(i)+w2×lb(i)
上式中,w1'和w2'是取值范围在0~1之间,则重构误差可以表示为:
优选地,使用kl散度衡量
在上式中,右边第一项是kl散度用于衡量两个分布
因此我们对变分下界进行了一些优化以实现对优化边界的优化。在上式中,右边第一项为正则化器,第二项与重构误差有关。
在进行重构融合图片过程中,希望最小化原始图像和目标图像之间的差距,而由于隐藏向量z是通过重新采样过的,而不是由编码器vencoder直接计算出来的,隐藏重构过程受到噪声影响;噪声会增加重构的难度,而这个噪声强度(也就是均方误差)是由神经网络模拟得到的,所以人脸融合网络模型为了降低重构误差,就会尽量让均方误差为0,然后如果均方误差为0时,人脸融合网络模型就会丧失随机性,所以不管怎样采样都只是得到确定的结果(也就是均值),而均值是通过另外一个神经网络计算得到的。
因此,为了解决这个问题,需要让所以的编码器vencoder真正输出的向量p(z|x)都向标准正态分布看齐,这样能够防止噪声强度(也就是均方误差)为0,同时保证了人脸融合网络模型具有生成能力。
其中,
因此p(z)服从标准正态分布,这样就可以从n(0,1)中采样生成图像。
最后,根据重构误差和kl散度,vgg网络的误差函数可以表示为:
人脸融合网络模型中设置相应的融合偏倚参数的步骤中,所述的融合偏倚参数包括w1和w2,其中w1和w2分别表示为特征向量
融合偏倚参数w1和w2的取值包括0或者1,其中0表示舍弃图像此维度的特征,1表示保留图像此维度的特征;并且两个融合偏移参数w1和w2的和为每个维度值为1的100维列向量。
优选地,融合偏倚参数还包括w1'和w2',其取值范围皆在0~1之间,且w1'和w2'之和为1。
现根据以下几个实验来进一步说明本发明的效果以及对人脸融合网络模型进行评估。
实验一:首先将融合偏倚参数w1'和w2'的值都设置为0.5并保持不变为前提,然后将融合偏倚参数w2的前50维的值设置为“1”,后50维的值设置为“0”;由于w1和w2两个向量的和为每个维度值为1的100维列向量,因此融合偏倚参数w1的前50维的值相应设置为“0”,后50维的值相应设置为“1”。
其次,设置w1的前70维度的值为“1”,相应的向量w2中最后30维度的值为“1”。最后将w2每一维度的值设置为“1”,相应的w1每一维度的值设置为“0”。
如图2所示,通过以上三组参数的实验结果可以得知,对于向量w2,随着向量中取值为“1”的维度数的增加,最后的融合结果中有很多的面部特征与下方箭头所指的图片相似;因此,从中可以得知w1和w2中取值为“1”的维度数越多,最后的融合图片中就有更多的面部特征来源于相应的原始图像。
实验二:首先将向量w1的前50维的值设置为“1”,w2的后50的值设置为“1”保持不变为前提;然后对融合偏倚参数w1'和w2'的值进行如下设置:
w1’=0.3,w2’=0.7;
w1’=0.4,w2’=0.6;
w1’=0.5,w2’=0.5;
w1’=0.6,w2’=0.4;
如图3所示,当设置w1'=0.5,w2'=0.5时,可以看到在图片右侧相关的融合结果包含了箭头上下两侧的原始图像的面部特征,但是不能判断融合结果在整体上是与上箭头所指的图片还是与下箭头所指的图片更为相近或者类似;当设置w1'>0.5时,可以看到融合结果的更多面部特征与上箭头所指的图片更为相近,并且整体上也与上箭头所指的图片类似;相反,当设置w1'<0.5时,实验结果刚好与w1'>0.5时相反。并且w1'的值越小,最后的融合结果就会在整体上与下箭头所指的原始图像的图片更加相近或者类似。
因此,当w1和w2中维度值保持不变时,融合偏倚参数w1'和w2'会对融合结果产生影响,其原因在于在训练整个人脸融合网络模型时使用随机梯度下降算法去减小重构误差引起的,如果w1'>w2',则重构误差更多来源于上箭头所指的图片,并且整个vgg网络会尽可能减少这一部分的误差,进而导致最后的融合结果与上箭头所指的图片更加相近或者类似。
所以,从上面的实验中可以得知,融合偏倚参数w1和w2以及w1'和w2'能够影响最后目标图像的融合结果。
为了进一步确定融合偏倚参数w1和w2以及w1'和w2'哪一组参数为影响最后目标图像融合结果的主要因素,进行了以下几组对比实验。
第一组:w1=[1,1,1,…,1,1,1],w2=[0,0,0,…,0,0,0],w1'=w2'=0.5;w1=[1,…,1,0,…,0],w2=[0,…,0,1,…,1],w1'=0.6,w2'=0.4。
第二组:w1=[1,1,1,…,1,1,1],w2=[0,0,0,…,0,0,0],w1'=0.7,w2'=0.3;w1=[1,1,1,…,1,1,1],w2=[0,0,0,…,0,0,0],w1'=1,w2'=0。
第三组:w1=[1,1,1,…,1,1,1],w2=[0,0,0,…,0,0,0],w1'=0.3,w2'=0.7。
如图4所示,在第一组对比实验中将w1的每个维度取值都设置为“1”以及取w1'=w2'=0.5,将w1的前50个维度的取值为“1”,剩下的维度取值为“0”,同时设置w1'=0.6,w2'=0.4,从中可知实验得到的融合图片整体上都与上箭头所指的图片相近或者类似;在第一个取值实验中解码器的100维特征向量中的每一个维度都来源于上箭头所指的图片,而在第二个取值实验中仅仅该向量的前50个维度来源于下箭头所指的图片,但是第二个取值实验的融合效果更好。
如图5所示,在第二组对比实验中,将w1的每一个维度值都设置为“1”,也就意味着这两次实验中的100维特征向量都来源于上箭头所指的图片,另外设置w1'=0.7,w2'=0.3以及w1'=1,w2'=0;从中可以得知两次实验的结果整体都与上箭头所指的图片相近或者类似,但是第二个取值实验在一些面部特征的细节上(如头发的颜色、发型和面部表情等等)表现的更好。
如图6所示,在第三组实验中,输入解码器的100维特征向量的每一个维度都来源于上箭头所指的图片,但是设置w1'<0.5,最后得到的融合结果不与箭头上下两侧的任何一张图片相近或者类似。
因此,最终可以得知融合偏倚参数w1'和w2'是影响最后目标图像融合效果的主要因素。
以上所述仅为本发明/发明的实施例,并非因此限制本发明/发明的专利范围,凡是利用本发明/发明说明书及附图内容所作的等效结构或等效流程变换,或直接或间接运用在其他相关的技术领域,均同理包括在本发明/发明的专利保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!