一种元数据管理查询的方法与流程
本发明涉及存储技术领域,尤其涉及一种元数据管理查询的方法。
背景技术:
随着互联网和物联网的发展,网络中的数据量出现爆发式的增长,对数据处理提出的新的要求,复杂的语义关系在海量数据的环境中进行应用。mdm在存储系统中变得异常困难,复杂元数据查询需求不断增长。元数据(metadata),又称中介数据、中继数据,为描述数据的数据(dataaboutdata),主要是描述数据属性(property)的信息,用来支持如指示存储位置、历史数据、资源查找、文件记录等功能。
基于上述问题,因此,对于本领域技术人员而言,如何实现元数据更加高效的管理查询,是亟需解决的技术问题。
技术实现要素:
基于背景技术存在的技术问题,本发明提出了一种元数据管理查询的方法,元数据管理统一采用b+树方式进行管理节点,在非叶子节点中增加一个entry用于存储该节点的子节点最大值以及最大值所在的index。当元数据满足一定条件后,进行刷盘,采用version思想进行刷盘。
本发明提出的一种元数据管理查询的方法,包括以下步骤:
将数据存放在每一个node上;
采用b+树对每一个node进行管理,非叶子节点的node增加一项entry,用来存放子节点的最大值以及最大值所在index;
当元数据满足预设条件后,将元数据刷到磁盘中进行存储。
优选地,将元数据刷到磁盘进行存储的过程中,采用version思想进行刷盘。
优选地,采用version思想进行刷盘,具体包括以下步骤:在刷盘这一层增加一个缓存层,每一个下刷的元数据作为一个version1,当version2来的时候与version1进行融合,采用version2中的数据为最终数据,对version1中的数据进行修改。
优选地,当多个version总量的数据到达阈值的时候进行下刷。
本发明中提供的一种元数据管理查询的方法,1.数据存放在每一个node上,b+树对每一个node进行管理,非叶子节点的node增加一项entry,用来存放子节点的最大值以及最大值所在index。提高了查询的效率,查询非叶子节点时首先根据最大值和查询的值进行比较可以判断是否在该node中,直接去该节点的右节点中查询,就不需要将该节点从开始到结束遍历。如果需要查询的恰好是最大值,那么就直接根据这个index获得下一层节点的地址。当元数据满足一定条件后需要刷到磁盘中进行存储。由于元数据是不停在变化插入,删除,频繁的进行io操作会严重影响性能。本专利采用version思想,在刷盘这一层增加一个缓存层,每一个下刷的元数据作为一个version1,当version2来的时候与version1进行融合,采用version2中的数据为最终数据,对version1中的数据进行修改。当多个version总量的数据到达阈值的时候进行下刷。此外多个version对于查询可以提高效率,查询的数据首先判断是否在融合如果在融合,去融合数据中查询,如果没有融合按照version从后往前中查询,一旦查询到数据就不需要再去磁盘中查询。
附图说明
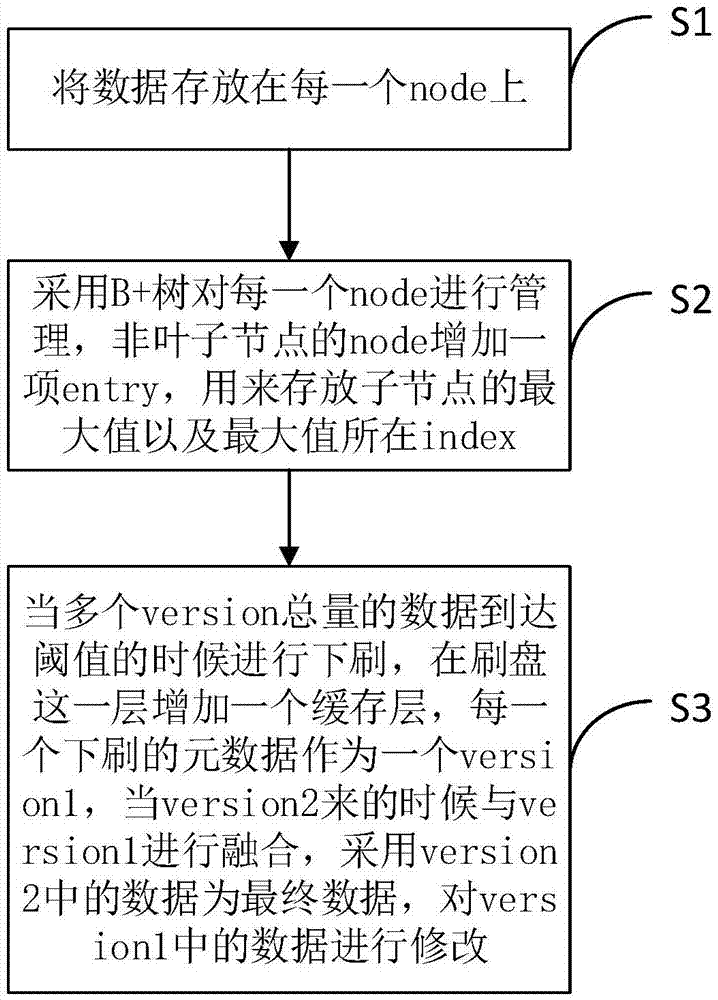
图1为本发明提出的一种元数据管理查询的方法的流程图。
具体实施方式
如图1所示,图1为本发明提出的一种元数据管理查询的方法的流程图。
下面结合附图和实施例对本发明进行详细的描述。
一种元数据管理查询的方法,包括以下步骤:
s1:将数据存放在每一个node上;
s2:采用b+树对每一个node进行管理,非叶子节点的node增加一项entry,用来存放子节点的最大值以及最大值所在index;
s3:当多个version总量的数据到达阈值的时候进行下刷,在刷盘这一层增加一个缓存层,每一个下刷的元数据作为一个version1,当version2来的时候与version1进行融合,采用version2中的数据为最终数据,对version1中的数据进行修改。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
技术特征:
技术总结
本发明公开了一种元数据管理查询的方法,包括以下步骤:将数据存放在每一个node上;采用B+树对每一个node进行管理,非叶子节点的node增加一项entry,用来存放子节点的最大值以及最大值所在index;当元数据满足预设条件后,将元数据刷到磁盘中进行存储。本发明公开的元数据管理查询的方法,元数据管理统一采用B+树方式进行管理节点,在非叶子节点中增加一个entry用于存储该节点的子节点最大值以及最大值所在的index。当元数据满足一定条件后,进行刷盘,采用version思想进行刷盘。
技术研发人员:姜腾光
受保护的技术使用者:郑州云海信息技术有限公司
技术研发日:2018.10.30
技术公布日:2019.01.25
- 还没有人留言评论。精彩留言会获得点赞!