基于图像熵的无参考图像质量评价方法与流程
本发明涉及图像质量处理技术领域,尤其涉及一种基于图像熵的无参考图像质量评价方法。
背景技术:
我们处于一个信息大爆炸的时代,每天被铺天盖地的信息重重包围。图像作为视觉信息的来源,蕴含了大量的有价值信息。由于图像信息相对于其它信息有着无可比拟的优点,因此对图像信息进行合理处理成为各领域中不可或缺的手段。在图像的处理和传输等过程中,由于成像系统、处理方法和传输介质等的不完善,加上物体运动、噪声污染等原因,不可避免地带来图像的失真和降质。而图像质量的好坏直接影响到人们的主观感受和信息量的获取,因此,图像质量评价(imagequalityassessment,iqa)的研究在近年来受到越来越广泛的重视。
按照是否需要人的参与,图像质量评价方法可以分为主观评价和客观评价。主观图像质量评价由人眼视觉效果对图像进行评价。与此对应,客观图像质量评价算法则基于特定算法由计算机设备对图像进行自动评价,其终极目标是希望用计算机来代替人类视觉系统去观察和认知图像。主观评价结果随机性较强,很难在实时图像系统中应用,于是客观质量评价算法被广泛研究。客观质量评价算法又被分为全参考(fullreference,fr)质量评价方法、半参考(部分参考)(reducedreference,rr)质量评价方法和无参考(noreference,nr)质量评价方法。其中,全参考方法同时有原始(无失真、参考)图像和失真图像,难度较低,核心是对比两幅图像的信息量或特征相似度,是研究比较成熟的方向。无参考方法只有失真图像,难度较高,是近些年的研究热点,也是iqa中最有挑战的问题,由于无参考方法最具实用价值,有着非常广泛的应用前景。
目前,学者们提出的无参考质量评价方法可以分为两大类:专用型图像质量评估方法和通用型图像质量评估方法。通用型图像质量评估方法又可以分为显式和隐式两种。现有的显式通用型nr-iqa算法面临以下问题:1)图像的彩色空间在nr-iqa算法中较少被考虑;2)部分nr-iqa算法仅利用像素的统计特征而未考虑特征的空间分布。liu等人分别在空域和频域中计算图像块的一维熵,将所有局部熵值的平均数和偏度作为图像的特征来实现sseq算法。s.gabarda等人使用空间/空间频率分布作为概率密度函数的近似来在局部基础上计算逐像素熵值,测量出的熵的方差是方向性的函数,将方差作为各向异性指标,并用这种各向异性度量来衡量图像的保真度和质量。基于一维熵的算法能体现图像灰度分布的聚集特征,却不能反映图像灰度分布的空间特征。
技术实现要素:
本发明针对显式通用型nr-iqa算法中存在的问题,提出了一种基于图像熵的通用无参考图像质量评价算法(eniqa),该算法利用图像块间的统计学规律,通过计算图像块的信息熵,提取图像局部结构特征。使用大量样本训练模型,通过交叉验证确定合适的模型参数,对测试图像进行质量预测。算法分别提取图像颜色通道之间的互信息、反映图像空间特征的二维熵以及滤波后的子带图像的二维熵和互信息,作为彩色图像的特征集合,然后利用支持向量分类(supportvectorclassifier,svc)进行失真分类,利用支持向量回归(supportvectorclassifier,svr)进行质量预测,得到最终的质量评价分数。本发明在live和tid2013数据库上进行测试,均取得了很好的结果。实验表明,本发明对彩色图像的评价表现出良好主客观评价一致性,体现了其良好的整体性能和泛化能力。
本发明的上述技术问题主要是通过下述技术方案得以解决的,基于图像熵的无参考图像质量评价方法,具体步骤如下:
步骤s1,提取待测图像特征,利用支持向量分类(supportvectorclassifier,svc)识别出待测图像属于每种失真类型的概率pi;
所述图像特征包括不同彩色通道之间的互信息、灰度图像的二维熵以及滤波后的子带图像的二维熵和互信息;
步骤s2,分别假设待测图像属于某个特定失真类型,用支持向量回归(supportvectorregression,svr)计算对应失真类型的得分qi,通过加权求和得到待测图像的质量指数,所述质量指数越高,图像质量越好。其中,步骤s1中提取图像特征的过程,通过引入不同彩色通道之间的互信息、灰度图像的二维熵以及滤波后的子带图像的二维熵和互信息来表征图像的局部结构信息。由于,图像的一维熵表示图像中灰度分布的聚集特征所包含的信息量,却不能反映图像灰度分布的空间特征。为了表征这种空间特征,在一维熵的基础上引入能够反映图像灰度分布空间特征的二维熵。
进一步的,步骤s1中提取图像特征的具体实现方式如下,
步骤s11,对于输入彩色图像,首先计算r/g/b三个颜色通道之间的互信息作为特征组1,特征组1包含3个特征;当自然彩色图像的某个区域色彩发生了变化,其相应r、g及b分量的像素灰度值也同时发生变化。而且,虽然一幅彩色图像的r、g及b分量的像素灰度值大小不同,但是它们的纹理、边缘、相位和灰度变化梯度具有非常好的相似性和一致性。因此,将r、g和b三通道间的互信息作为特征;
步骤s12,将彩色图像灰度化后进行分块,分别计算每一块区域的局部二维熵,对获得的所有局部熵值进行池化后计算平均值以及偏度作为特征组2,特征组2中包含2个特征;
步骤s13,对灰度输入图像进行2尺度4方向的log-gabor滤波,得到滤波后的8张子带图像,并分别对这8个子带图像进行分块,计算每幅子带图像局部块的二维熵,对获得的所有局部熵值进行池化后计算平均值和偏度,作为特征组3,特征组3中包含16个特征;
步骤s14,计算4个不同方向上的子带图像间的互信息,作为特征组4,特征组4中包含6个特征;
步骤s15,计算2个不同尺度上的子带图像间的互信息,作为特征组5,特征组5包含1个特征;
步骤s16,对输入彩色图像进行1次下采样,得到类似的28个特征,并入对应的特征组,因此,对于一幅输入彩色图像,共提取56个特征。
进一步的,步骤s12中,图像二维熵的具体计算方式如下,
将彩色图像x灰度化后,选择灰度图像的邻域均值作为空间分布特征量,与图像的像素灰度组成特征二元组,记为(x1,x2),其中x1表示像素的灰度值(0≤x1≤255),x2表示领域灰度均值(0≤x2≤255),某像素的灰度值与其周围像素的灰度分布的综合特征为:
其中,f(x1,x2)为特征二元组(x1,x2)出现的频数,m、n为图像x的尺寸;
选取像素点x1的8邻域像素均值作为x2,定义离散的图像二维熵为:
其中,依此构造的图像二维熵可以在反映图像所包含的信息量的前提下,突出反映图像中像素位置的灰度信息和像素邻域内灰度分布的综合特征。不论是失真等级还是失真类型,都可以用二维熵区分,因此将二维熵作为特征。
进一步的,步骤s12中,首先对待测图像进行显著性检测,按照人眼视觉优先级来对图像块进行池化,从而筛选出人类更为重视的图像块,根据不同图像块的显著性值,对其排序后筛选显著性更高的80%进行局部二维熵的统计特性(均值和偏度)计算。
进一步的,使用基于傅里叶频谱残差方法计算待测图像的显著性图。
进一步的,步骤s11中,互信息的具体计算方式如下,
以彩色图像x的r和g通道为例,假设xr和xg分别表示彩色图像x中这两个通道的灰度值,p(xr)、p(xg)和p(xr,xg)分别表示对应的灰度概率分布和联合概率分布,则r和g通道之间的互信息定义为:
其中,h(xr)是彩色图像x的r通道的二维熵,h(xg)是g通道的二维熵,h(xr,xg)是两幅图像之间的联合熵,定义为:
进一步的,步骤s13中,使用的二维log-gabor滤波器的传递函数可表示为:
其中,f0为中心频率,θ0为滤波器方向,σr用于确定径向带宽,σθ用于确定方向带宽;
采用的log-gabor滤波器组从左到右的方向依次为:0°、45°、90°、135°,并且有2个尺度,利用这个log-gabor滤波器组对待测图像滤波,分别得到图像在对应4个方向,2个尺度的8个子带分量。
进一步的,步骤s16中使用最近邻算法对待测图像进行下采样。
进一步的,步骤s2中,通过加权求和得到待测图像的质量指数的计算公式为,
index=σpiqi(5)
其中pi为待测图像属于第i种失真类型的概率,qi待测图像为对应第i种失真类型的得分。
进一步的,步骤s1中所述失真类型包括高斯模糊、高斯白噪声、jpeg压缩、jpeg2000压缩。
本发明的优点和有益效果:
本发明提出了一种基于图像熵的nr-iqa算法(eniqa)。该算法利用图像块间的统计学规律,通过计算图像块的信息熵,提取图像局部结构特征。我们使用大量样本训练模型,通过交叉验证确定合适的模型参数,对测试图像进行质量预测。在live和tid2013数据库上的实验表明,该算法表现出良好的性能和主客观评价一致性。
附图说明
图1是本发明实施例算法框架流程图。
图2是本发明实施例计算图像二维熵过程中的像素点及其8邻域图。
图3是本发明实施例中二维熵统计特性图,其中(a)为原图及5张相同失真等级不同失真类型的失真图求取二维熵的统计特性图,(b)为原图及5张相同失真类型不同失真等级的失真图求取二维熵的统计特性图。
图4是本发明实施例live数据库中不同iqa算法的srocc分布箱型图。
图5是本发明提出的图像质量评价方法eniqa在数据库live和tid2013上的散点图拟合实验结果,其中(a)为eniqa在数据库live上的散点图拟合实验结果,(b)为eniqa在数据库tid2013上的散点图拟合实验结果。
具体实施方式
下面结合附图和实施例对本发明作进一步说明:
实施例
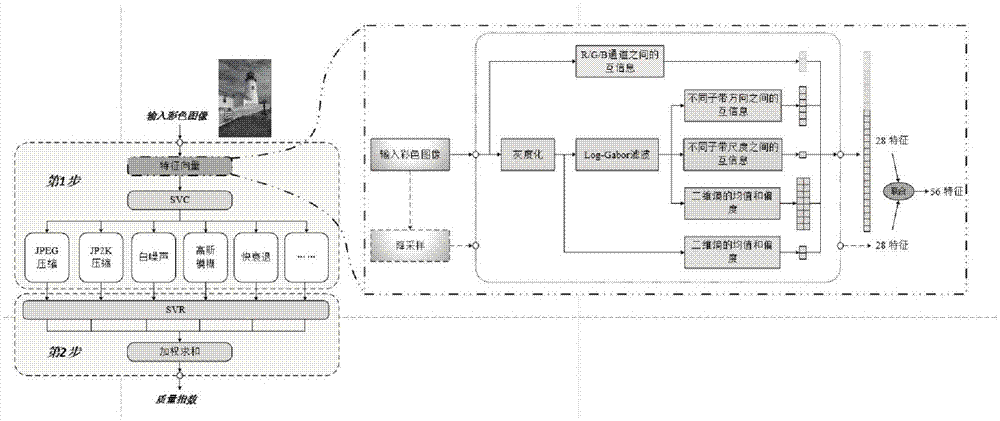
如图1所示,本发明提出的基于图像熵的无参考图像质量评价方法(简称eniqa),包含以下步骤:
第一步,提取图像特征,利用支持向量分类识别出待测图像每种失真类型的概率p1/p2/p3/p4。
第二步,用支持向量回归计算对应失真类型的得分q1/q2/q3/q4,通过加权求和得到待测图像的质量指数。
本实施例在live和tid2013数据库上开展实验。live数据库由29张参考图像和779张失真图像5种失真类别组成;tid2013数据库由25张参考图像和3000张失真图像24种失真类别组成。在这25张参考图像中,只有24张是自然图像,所以我们仅在24自然图像上开展测试。同时,为了保证训练和测试的一致性,我们在开展跨库测试时,仅选取与live数据库相同的4种失真类别(jp2k、jpeg、高斯噪声和高斯模糊)开展测试。
本发明提出的基于图像熵的无参考图像质量评价方法,第一步中提取图像特征的过程,通过引入不同彩色通道之间的互信息、灰度图像的二维熵以及滤波后的子带图像的二维熵和互信息来表征图像的局部结构信息。
表1特征描述
对于输入彩色图像,首先计算r/g/b三个通道之间的互信息作为特征组1;然后将彩色图像灰度化后进行分块,分别计算每一块区域的局部二维熵,对获得的所有局部熵值进行池化后计算平均值以及偏度作为特征组2;同时对灰度输入图像进行2尺度4方向的log-gabor滤波,得到滤波后的8张子带图像,并分别对这8个子带图像进行分块,计算每幅子带图像局部块的二维熵,对获得的所有局部熵值进行池化后计算平均值和偏度,作为特征组3;计算4个不同方向上的子带图像间的互信息,作为特征组4;计算2个不同尺度上的子带图像间的互信息,作为特征组5。使用最近邻算法对图像进行1次下采样,得到类似的28个特征,并入对应的特征组。这样,对于一幅输入彩色图像,共提取56个特征。每组特征向量的特征描述如表1所示。
图像二维熵的计算过程如下:将彩色图像x灰度化后,选择灰度图像的邻域均值作为空间分布特征量,与图像的像素灰度组成特征二元组,记为(x1,x2),其中x1表示像素的灰度值(0≤x1≤255),x2表示领域灰度均值(0≤x2≤255),某像素的灰度值与其周围像素的灰度分布的综合特征为:
其中,f(x1,x2)为特征二元组(x1,x2)出现的频数,m、n为图像x的尺寸。
选取像素点x1的8邻域像素均值作为x2,如图2所示,定义离散的图像二维熵为:
依此构造的图像二维熵可以在反映图像所包含的信息量的前提下,突出反映图像中像素位置的灰度信息和像素邻域内灰度分布的综合特征。我们对一张原图(选自live库无失真图”monarch.bmp”)以及对应的5张相同失真等级不同失真类型的失真图(dmos值都在25左右,失真类型分别是jp2k、jpeg、白噪声、高斯模糊和快衰落)进行图像分块求取二维熵,统计特性如图3(a)所示。类似的,我们对同样的原图以及对应的5张相同失真类型不同失真等级的失真图(以whitenoise为例)进行图像分块求取二维熵,统计特性如图3(b)所示。图3中,横轴代表熵值,纵轴代表归一化后的图像块数。从图3可以看出,不论是失真等级还是失真类型,都可以用二维熵区分,因此我们将二维熵作为特征是有意义的。
计算图像块的二维熵的统计特性时,对待测图像进行显著性检测,按照人眼视觉优先级来对图像块进行池化,从而筛选出人类更为重视的图像块。根据不同图像块的显著性值,对其排序后筛选显著性更高的80%进行局部二维熵的统计特性(均值和偏度)计算。本实施例使用基于傅里叶频谱残差方法计算待测图像的显著性图。
步骤s1中提取不同彩色通道之间的互信息作为特征组。以彩色图像x的r和g通道为例,假设xr和xg分别表示彩色图像x中这两个通道的灰度值,p(xr)、p(xg)和p(xr,xg)分别表示对应的灰度概率分布和联合概率分布。则r和g通道之间的互信息定义为:
其中,h(xr)是彩色图像x的r通道的二维熵,h(xg)是g通道的二维熵,h(xr,xg)是两幅图像之间的联合熵,定义为:
所述步骤s1中使用的二维log-gabor滤波器的传递函数可表示为:
其中,f0为中心频率,θ0为滤波器方向,σr用于确定径向带宽,σθ用于确定方向带宽。采用的log-gabor滤波器组从左到右的方向依次为:0°、45°、90°、135°,并且有2个尺度。利用这个log-gabor滤波器组对待测图像滤波,分别得到图像在对应4个方向,2个尺度的8个子带分量。
根据提取的图像特征,用支持向量回归计算对应失真类型的得分q1/q2/q3/q4,通过加权求和得到待测图像的质量指数:
本文采用5参数非线性逻辑回归函数拟合数据,采用斯皮尔曼等级相关等级相关系数srocc、皮尔森线性相关系数plcc和均方根误差rmse评估算法性能。
其中,z是客观iqa分数,f(z)是iqa回归拟合分数,βi(i=1,2,...,5)是回归函数的参数。
性能比较如下:
在live数据库上实验时,我们将eniqa和10种最先进的方法进行比较测试。三种friqa模型包括:psnr,ssim和vif,七种nriqa模型包括:biqi,diivine,bliindsii,brisque,niqe,ilniqe和sseq。为了保证实验的公平性,我们随机抽取80%的样本组成训练集,20%的样本组成测试集,通过1000次训练-测试实验,得到1000次交叉验证的结果,取1000次实验结果的中位数作为最终指标。在nr模型的训练中,我们使用libsvm工具包实现svc和svr,两者均采用径向基函数(radialbasisfunction,rbf)内核。因为fr模型不需要训练,我们只测试针对失真图像的fr方法(不包括live数据库的参考图像)。实验结果见表2-4,表现最好的两个指数用黑体标了出来。可以看出,eniqa在live数据库上表现出色。整体性能除了略逊于brisque之外,均超过其它nr算法,甚至领先于ssim等经典fr算法。
表2在live数据库上的1000次训练测试对的srocc的中值
表3在live数据库上的1000次训练测试对的plcc的中值
表4在live数据库上的1000次训练测试对的rmse的中值
为了更加直观的比较不同算法的性能差异,提供有关数据位置和分散情况的关键信息,图4显示了1000次训练-测试试验中11种iqa方法(包括本发明实施例提出的eniqa方法)的srocc分布的箱形图。同时,我们针对这些算法开展t测试,实验结果如表5所示。零假设是指相关的行等于平均相关值的列在95%置信水平。另一种假设是,行的平均相关值大于(或小于)列的平均相关值。表5显示哪一行在统计上优于(1)、等同(0)或低于(-1)哪一列。
表5srocc值的t测试结果
从图4可以看出,除了略逊于brisque之外,eniqa在t测试中均超过其它fr和nr算法。在异常值数量上,eniqa除了略逊于ssim之外,甚至超过了brisque。表5可以得到和图4类似的结论,充分说明了eniqa的优异性能。
为了测试评价模型对不同样本的泛化能力,本文将整个live数据库用作训练集,在tid2013数据库中选择与训练样本失真类型相同(jpeg2000、jpeg压缩、白噪声和高斯模糊)的图像作为测试集,得到算法的性能指标,如表6所示。表现最好的两个iqa指数已用黑体标出。从表6可以看出,eniqa算法在tid2013数据库上有优越的表现,性能指标超过所有其他nr算法,甚至超过了在live库上表现一直很好的brisque,反映了eniqa良好的泛化能力。
表6模型在live数据库上训练,tid2013数据库上进行测试的性能指标
图5示出了eniqa在live和tid2013数据库上的散点图拟合实验结果。同前面的实验类似,在live数据库上开展散点图实验时,我们用80%的随机样本训练,然后用剩下的20%样本测试,得到某次散点图拟合结果,如图5(a)。在tid2013数据库上开展散点图实验时,我们用整个live数据库训练,然后在tid2013数据库(部分)中测试,得到散点图拟合结果,如图5(b)。从图5可以看出,算法拟合的散点图在整个坐标系中均匀分布,并且与dmos/mos具有很强的线性关系,进一步证明了算法的优越表现。
本领域的技术人员容易理解,以上所述仅为本发明较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所做的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!