一种基于用户学习行为的个性化试题推荐方法与流程
本发明涉及在线教育领域,更具体的,涉及一种基于用户学习行为的个性试题推荐方法。
背景技术:
随着计算机技术的普及和移动互联网的快速发展,许多传统行业也逐渐往着互联网化的方向靠拢,教育行业就是这众多传统行业中的一员。近年来,国内外涌现了许多在线教育平台,并且进行了许多成功的实践。国内比较热门的在线教育平台有网易云课堂、腾讯课堂、慕课网、mooc中国等等。国外比较热门的在线教育平台有coursera、edx、udacity、可汗学院等等。在线教育平台内容覆盖了各个学科领域、各个年龄阶层,功能丰富多样,包括在线课程、在线实验、学习路径规划、在线做题等等。这种基于互联网的教育方式使得学习者可以不受时间和空间的限制,足不出户就能够获得海量的教育和学习资源。
有了在线教育平台之后,如何衡量用户的学习效果是一个复杂的问题,于是,在线考试系统、在线试题推荐系统等作为教育辅助平台应运而生,通过为用户提供试题练习,有效地对用户学习效果进行评估。但是,在现实情况中,这些在线教育平台的试题资源数量十分庞大,种类繁多,而且每个用户的学习能力和方向具有很大的个体化差异,如何有效地在众多的试题资源中找出合适的试题推荐给用户是一个非常严峻的问题。
技术实现要素:
本发明为了解决在众多的试题资源中无法找出合适的试题推荐给目标用户的问题,提供了一种基于用户学习行为的个性化试题推荐方法,其能根据掌握的知识点的程度,在众多试题资源中找出合适的试题推荐给目标用户。
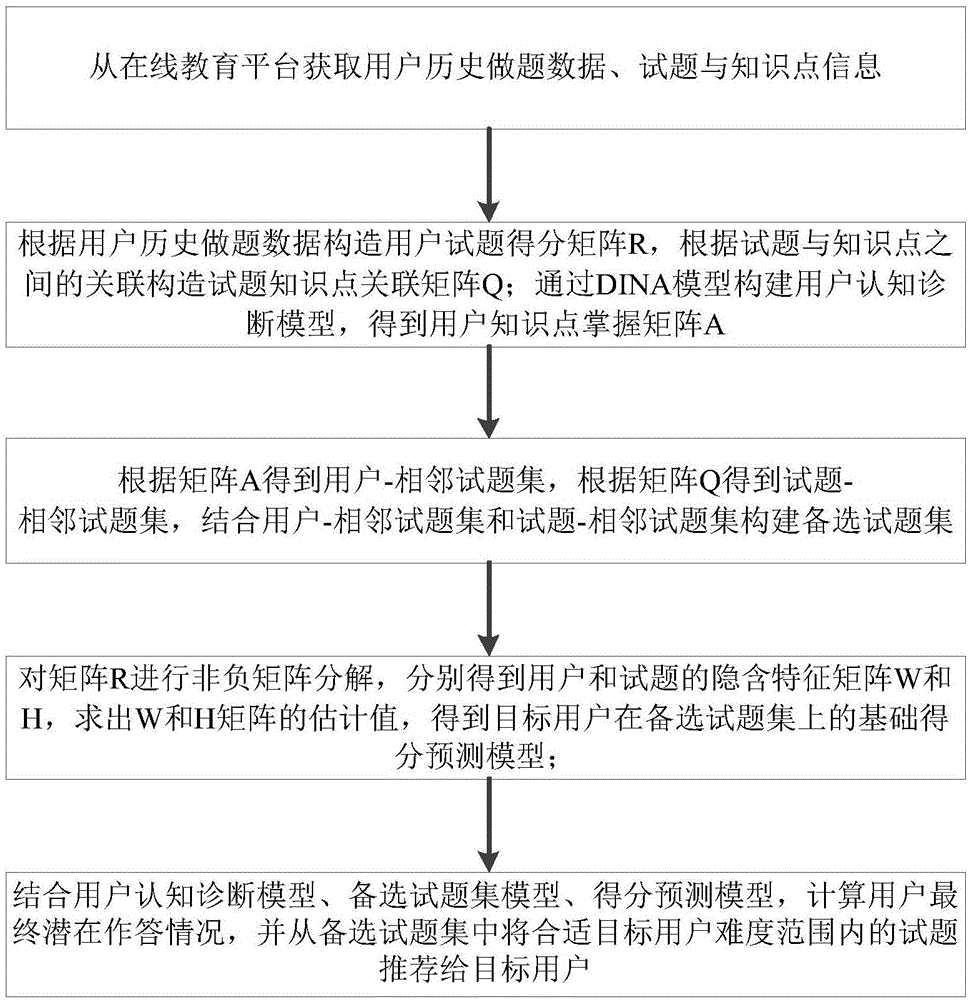
为实现上述本发明目的,采用的技术方案如下:一种基于用户学习行为的个性化试题推荐方法,所述该个性化试题推荐方法步骤如下:
步骤1:从在线教育平台获取用户历史做题数据、试题与知识点信息;
步骤2:根据用户历史做题数据构造用户-试题得分矩阵r,根据试题与知识点之间的关联构造试题-知识点关联矩阵q;基于矩阵r、矩阵q构建用户认知诊断模型,也即用户知识点掌握矩阵a;
步骤3:基于矩阵a得到用户-相邻试题集,用户-相邻试题集表示从矩阵a中得出的相邻用户已做试题而目标用户未做的试题集合;根据矩阵q得到试题-相邻试题集,试题-相邻试题集表示利用皮尔逊相关系数从矩阵q得到的相邻试题集合;结合用户-相邻试题集和试题-相邻试题集构建备选试题集;
步骤4:对矩阵r进行非负矩阵分解,将r矩阵分解为用户和试题的隐含特征矩阵w、h,其中w∈ru×d,h∈rd×v,r=wh,利用梯度下降法求出w和h矩阵的估计值;其中:u表示总的用户数目;v为总的试题数目;d为某个小于u和v的整数;
步骤5:结合矩阵a,计算用户在备选试题集的最终潜在作答情况:
ηuv=ω1μu+ω2μv+ω3ruv
其中:
ω1+ω2+ω3=1
μu表示根据认知诊断情况对用户pu在试题tv上的得分的预测结果;μv表示试题tv的整体平均分;ω1、ω2、ω3为计算潜在作答情况时的权值,分别表示μu、μv、ruv在最终的潜在作答情况中所占的比重;qvk表示试题tv对知识点ck的考察情况,即知识点ck在试题tv中所占的权重值;ruv表示用户pu在试题tv上的作答情况;αuk表示用户pu对知识点ck的掌握情况,αuk=1表示用户pu掌握了知识点ck,αuk=0表示用户pu尚未掌握了知识点ck;
步骤6:结合上一步得到的用户潜在作答情况,从备选试题集当中推荐目标用户自己选择难度范围(d1,d2)的试题给用户。
优选地,所述用户认知诊断模型采用基于离散认知建模的dina模型进行建模,建模步骤如下:
步骤21:根据已知用户pu对知识点ck的掌握情况αuk,得到用户pu在试题tv上的潜在作答情况,公式表示为
其中:ηuv表示用户pu在试题tv上的潜在作答情况,ηuv=1表示用户pu正确作答,ηuv=0表示不能正确作答;qvk表示试题tv对知识点ck的考察情况,即知识点ck在试题tv中所占的权重值;
步骤22:结合失误率sv和猜测率gv,得到用户pu在试题tv上的正确作答的概率,公式表示如下:
其中:ruv表示用户pu在试题tv上的作答情况;αu表示用户pu对所有知识点的掌握情况;
步骤23:利用最大期望算法来最大化p(ruv=1|αu)的边缘似然概率,从而得到每道题的失误率sv和猜测率gv两个随机参数的估计值
步骤24:结合估计值
其中,ru表示用户u在所有题目上的作答情况向量;
步骤25:获得用户的所有知识点掌握向量,得到用户的所有知识点掌握矩阵a。
进一步地,所述失误率的表达式为:
sv=p(ruv=0|ηuv=1)
所述猜测率的表达式为:
gv=p(ruv=1|ηuv=0)
优选地,所述构建备选试题集步骤如下:
步骤31:根据认知诊断模型,得出用户知识点掌握矩阵a,计算任意两个用户x和y的相似性;
步骤32:计算出所有用户与目标用户的相似性之后,根据相似性排序,选出相似度最高的θ1个用户,然后得到这θ1个用户的已做试题集合,剔除掉目标用户的已做试题,得到的集合pt即为用户-相邻试题集pt;
步骤33:根据试题-知识点关联矩阵q,利用皮尔逊相关系数从矩阵q得到的相邻试题集合,即为试题-相邻试题集tt;
步骤34:取用户-相邻试题集pt和试题-相邻试题集交集tt,即为目标备选试题集。
进一步地,所述相似性计算公式如下:
其中:αx表示用户x的知识点掌握向量;αy表示用户y的知识点掌握向量,
优选地,所述w和h的求解过程如下:
步骤41:根据噪声矩阵e∈ru×v,对于任意给定的d值,求矩阵w和h矩阵,使得||e||最小;其中:噪声矩阵、w矩阵、h矩阵、矩阵r的关系表达式为:
e=r-wh
步骤42:设噪声矩阵服从高斯分布,则最大似然函数定义如下:
两边同时取对数,可得:
步骤43:定义损失函数为:
设各数据点噪声的方差一样,若要使得对数似然函数取值最大,则损失函数取得最小值即可,将损失函数分别对w和h求偏导,可得:
步骤44:采用梯度下降的方法进行迭代,可以得到最终的迭代式为:
这是一个乘性迭代,保证了每一步迭代结果都一定为正数,设定迭代的阈值为ε,最大迭代次数为γmax,当误差函数值小于ε或者迭代次数达到γmax时终止迭代,最终结果会收敛,得到所求的w、h矩阵;
其中:σij表示高斯分布中的标准差;
hdj表示矩阵h的第d行第j列。
本发明的有益效果如下:
(1)本发明通过基于离散认知建模的dina模型构建认知诊断模型,同时引入失误率、猜测率,能准确得到用户所有知识点掌握矩阵a。
(2)本发明构建用户认知诊断模型、备选试题集、得分预测模型,结合用户认知诊断模型、备选试题集、得分预测模型计算出目标用户潜在做答情况,能根据计算公式准确无误的将用户在备选试题集的最终潜在作答情况;将适合目标用户难度范围内的试题推荐给用户,本发明能准确的将试题推荐给用户,使用户能达到良好的学习状态。
附图说明
图1是本发明基于用户学习行为的个性化试题推荐方法的流程图。
图2是本发明基于用户学习行为的个性化试题推荐方法的结构图。
具体实施方式
下面结合附图和具体实施方式对本发明做详细描述。
实施例1
现有的大多数试题推荐系统都是面向中小学生在校教育的,题目类型也基本都是应试教育里面的传统科目,在现有的在线教育平台中,虽然也不乏一些集成了试题推荐模块的平台,没有充分考虑了用户的个体独特性、用户之间的共性。因此设计了一种基于用户学习行为的个性化试题推荐算法,如图1、图2所示,所述该个性化试题推荐方法步骤如下:
步骤1:从在线教育平台获取用户历史做题数据、试题与知识点信息;
步骤2:根据用户历史做题数据构造用户-试题得分矩阵r,根据试题与知识点之间的关联构造试题-知识点关联矩阵q;基于矩阵r、矩阵q构建用户认知诊断模型,也即用户知识点掌握矩阵a;
步骤3:基于矩阵a得到用户-相邻试题集,用户-相邻试题集表示从矩阵a中得出的相邻用户已做试题而目标用户未做的试题集合;根据矩阵q得到试题-相邻试题集,试题-相邻试题集表示利用皮尔逊相关系数从矩阵q得到的相邻试题集合;结合用户-相邻试题集和试题-相邻试题集构建备选试题集;
步骤4:对矩阵r进行非负矩阵分解,将r矩阵分解为用户和试题的隐含特征矩阵w、h,其中w∈ru×d,h∈rd×v,r=wh,利用梯度下降法求出w和h矩阵的估计值;
其中:u表示总的用户数目;v为总的试题数目;d为某个小于u和v的整数;
步骤5:结合矩阵a,计算用户在备选试题集的最终潜在作答情况:
ηuv=ω1μu+ω2μv+ω3ruv
其中:
ω1+ω2+ω3=1
μu表示根据认知诊断情况对用户pu在试题tv上的得分的预测结果;μv表示试题tv的整体平均分;ω1、ω2、ω3为计算潜在作答情况时的权值,分别表示μu、μv、ruv在最终的潜在作答情况中所占的比重;qvk表示试题tv对知识点ck的考察情况,即知识点ck在试题tv中所占的权重值;ruv表示用户pu在试题tv上的作答情况;αuk表示用户pu对知识点ck的掌握情况,αuk=1表示用户pu掌握了知识点ck,αuk=0表示用户pu尚未掌握了知识点ck;
步骤6:结合上一步得到的用户潜在作答情况,从备选试题集当中推荐目标用户自己选择难度范围(d1,d2)的试题给用户;用户目标难度读范围由用户自己决定,用户在做题前可选择自己要做的题目难度范围(d1,d2)。
本实施例所述用户认知诊断模型,所述的认知诊断原本是心理测量的一种方法,但是通过实践发现将认知诊断应用于其他学科领域也是适用的。本发明中的用户认知诊断模型采用了应用较广泛的基于离散认知建模的dina模型。
定义集合p={p1,p2,…,pu}为用户集合,集合t={t1,t2,…,tv}为试题集合,集合c={c1,c2,…,ck}为知识点集合,矩阵q为试题-知识点关联矩阵,qvk表示试题tv对知识点ck的考察情况,即知识点ck在试题tv中所占的权重值(0-1之间),矩阵r为用户-试题得分矩阵,ruv表示用户pu在试题tv上的作答情况,dina模型通过结合q矩阵和r矩阵对学生认知情况进行建模,αuk表示用户pu的知识点ck掌握向量αu,k表示不同知识点ck,αuk=1表示用户掌握了知识点ck,αuk=0表示用户尚未掌握了知识点ck。
步骤21:根据已知用户pu对知识点ck的掌握情况αuk,得到用户pu在试题tv上的潜在作答情况,公式表示为
其中,ηuv表示用户pu在试题tv上的潜在作答情况,ηuv=1表示用户pu正确作答,ηuv=0表示不能正确作答;qvk表示试题tv对知识点ck的考察情况,即知识点ck在试题tv中所占的权重值;
步骤22:在用户pu在试题tv上的潜在作答情况的基础上,dina模型还引入了失误率(slipping)和猜测率(guessing)两个随机参数,用来模拟用户在真实状态下的作答情况。
其中,失误率定义如下:
sv=p(ruv=0|ηuv=1)
其中:ruv表示用户pu在试题tv上的作答情况;
失误率用于表示用户本来已经掌握了试题tv涉及的所有知识点,应该能正确作答试题的,但是却因为粗心或者是失误导致意外答错的概率。
猜测率的定义如下:
gv=p(ruv=1|ηuv=0)
猜测率用于表示用户本来并未掌握试题tv所涉及的所有知识点,本来应该无法正确作答的,但是却因为运气成分或者猜测导致意外答对的概率。
加入失误率和猜测率两个随机参数之后,可以得出已知用户知识点掌握向量αu之后,用户pu在试题tv上的正确作答的概率表示如下:
步骤23:在dina模型中,采用最大期望算法(em)来最大化p(ruv=1|αu)用户pu在试题tv上的正确作答的概率的边缘似然概率,从而得到每道题的失误率sv和猜测率gv两个随机参数的估计值
步骤24:结合估计值
其中,ru表示用户u在所有题目上的作答情况向量;
步骤25:获得所有用户知识点掌握向量之后,便得到用户知识点掌握矩阵a。
本实施例中本发明所述的一种基于用户学习行为的个性化试题推荐方法,其中在试题推荐系统中,最终推荐的试题都是从备选试题集当中挑选出来的,因此需要构建一个备选试题集,而合理构建备选试题集可以在后面的推荐过程中减少很多的计算量。
所述构建备选试题集步骤如下:
步骤31:根据认知诊断模型,得出用户知识点掌握矩阵a,计算任意两个用户x和y的相似性;
步骤32:计算出所有用户与目标用户的相似性之后,根据相似性排序,选出相似度最高的θ1个用户,然后得到这θ1个用户的已做试题集合,剔除掉目标用户的已做试题,得到的集合pt即为用户-相邻试题集pt;
步骤33:根据试题-知识点关联矩阵q,利用皮尔逊相关系数从矩阵q得到的相邻试题集合,即为试题-相邻试题集tt;
步骤34:取用户-相邻试题集pt和试题-相邻试题集交集tt,即为目标备选试题集。
本方法主要通过两个指标来构建备选试题集,分别是用户-相邻试题集和试题-相邻试题集。定义集合pt={pt1,pt2,…,ptn}为用户-相邻试题集,表示从认知诊断模型里面的用户知识点掌握矩阵a中得出的相邻用户已做试题而目标用户未做的试题集合;定义集合tt={tt1,tt2,…,ttm}为试题-相邻试题集,表示利用皮尔逊相关系数从试题-知识点权重矩阵中得到的相邻试题集合;定义集合ft={ft1,ft2,…,fto}为最终的备选试题集。
用户-相邻试题集主要依赖于认知诊断模型,根据认知诊断模型,可以得出用户知识点掌握矩阵a;
定义:对于任意两个用户x和y,他们的知识点掌握向量分别为αx和αy,则这两个用户之间的相似性为:
其中,
试题-相邻试题集主要是从试题-知识点关联矩阵q计算得来的。根据试题-知识点关联矩阵q,对于任意两道试题,利用皮尔逊相关系数从矩阵q得到的相邻试题集合,然后选出与目标用户已做试题集相似度最高的θ2道试题集合即为试题-相邻试题集。
将所述的用户-相邻试题集和试题-相邻试题集取交集,即为目标备选试题集。
本实施例所述的得分预测模型,用来预测目标用户在备选试题集上的每道试题的原始得分。
步骤41:首先,由于在现实情况中,用户已完成的题目只是整个题库中的一小部分,所以用户-试题得分矩阵r矩阵一般是一个稀疏矩阵,采用非负矩阵分解的方式,将r矩阵分解为用户和试题的隐含特征矩阵w、h,其中w∈ru×d,h∈rd×v,r=wh,其中d为某个小于u和v的整数,可进行调整。
假设噪声矩阵为e∈ru×v,则对于任意给定的d值,最终的目标为找出合适的w和h矩阵,使得||e||最小,其中:
e=r-wh
步骤42:设噪声矩阵服从高斯分布,则最大似然函数定义如下:
两边同时取对数,可得:
步骤43:定义损失函数为:
设各数据点噪声的方差一样,那么,若要使得对数似然函数取值最大,只需要使得损失函数取得最小值即可。
将损失函数分别对w和h求偏导,可得:
步骤44:采用梯度下降的方法进行迭代,可以得到最终的迭代式为:
这是一个乘性迭代,保证了每一步迭代结果都一定为正数,设定迭代的阈值为ε,最大迭代次数为γmax,当误差函数值小于ε或者迭代次数达到γmax时终止迭代,最终结果会收敛,得到所求的w、h矩阵。
其中:σij表示高斯分布中的标准差;
hdj表示矩阵h的第d行第j列。
最后,将得到的w、h矩阵的乘积来估计r矩阵中缺失的值,作为用户答题的基础得分预测值。
本实施例结合用户认知诊断模型、备选试题集、得分预测模型,计算用户最终潜在作答情况。因此需要先结合认知诊断模型得到的a矩阵,定义用户最终潜在作答情况:
ηuv=ω1μu+ω2μv+ω3ruv
其中:
ω1+ω2+ω3=1
其中:μu表示根据认知诊断情况对用户pu在试题tv上的得分的预测结果,μv表示试题tv的整体平均分,一定程度上代表了试题本身的难度系数;ω1、ω2、ω3为计算潜在作答情况时的权值,分别表示μu、μv、ruv在最终的潜在作答情况中所占的比重。
最后一步,根据用户最初选择的难度范围(d1,d2),结合得到的用户潜在作答情况,从备选试题集中将合适目标用户难度范围内的试题推荐给目标用户,完成个性化试题推荐。
显然,本发明的上述实施例仅仅是为清楚地说明本发明所作的举例,而并非是对本发明的实施方式的限定。凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!