一种混合信号二进制CNN处理器的制作方法
本实用新型涉及一种cnn处理器,特别涉及一种混合信号二进制cnn处理器。
背景技术:
卷积神经网络(convolutionalneuralnetwork,cnn)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。它包括卷积层(convolutionallayer)和池化层(poolinglayer)。
由于对延迟,带宽和隐私的关注,将云深度学习推向边缘的趋势已经形成了对低能量深度卷积神经网络(cnn)的需求。
现有的单层分类器实现了sub-nj操作,但仅限于在低复杂度任务(mnist上的90%)实现中等精度。较大的cnn芯片为mj能源的高复杂度任务(alexnet)提供数据流计算,但由于片外dram访问能量的缘故,边缘部署仍然是一个挑战。
因此,特别需要一种混合信号二进制cnn处理器,以解决上述现有存在的问题。
技术实现要素:
本实用新型的目的在于提供一种混合信号二进制cnn处理器,针对现有技术的不足,执行中等复杂度的图像分类(cifar-10中为86%),并采用近存储器计算来实现3.8μj的分类能量,比truenorth提高40倍。
本实用新型所解决的技术问题可以采用以下技术方案来实现:
一种混合信号二进制cnn处理器,其特征在于,它包括神经元阵列单元、二进制温度译码单元、控制单元、输入图像单元、输出图像单元和存储单元,rgb图像通过二进制温度译码单元的输入端输入,二进制温度译码单元的输出端通过输入图像单元与神经元阵列单元的输入端相连接,神经元阵列单元的输出端与输出图像单元相连接,控制单元与神经元阵列单元相连接,控制指令通过控制单元的输入端输入,存储单元与神经元阵列单元相连接。
在本实用新型的一个实施例中,所述存储单元包括本地存储器、第一过滤器存储器和第二过滤器存储器,所述本地存储器、第一过滤器存储器和第二过滤器存储器分别与神经元阵列单元相连接。
进一步,第一过滤器存储器和第二过滤器存储器以乒乓方式交替输入和输出。
在本实用新型的一个实施例中,所述输入图像单元包括输入图像存储器和输入多路分配器,二进制温度译码单元的输出端依次通过输入图像存储器和输入多路分配器与神经元阵列单元的输入端相连接。
在本实用新型的一个实施例中,所述输出图像单元包括输出图像存储器和输出多路分配器,神经元阵列单元的输出端依次通过输出多路分配器和输出图像存储器输出。
本实用新型的混合信号二进制cnn处理器,与现有技术相比,通过二进制温度译码单元的binarynet算法来完成工作,其权重和激活约束为+1/-1,极大地简化了乘法运算(xnor)并允许集成所有片上存储单元;神经元阵列单元为解决binarynet宽矢量求和的挑战的高能效开关电容(sc)神经元;执行中等复杂度的图像分类(cifar-10中为86%),并采用近存储器计算来实现3.8μj的分类能量,比truenorth提高40倍,实现本实用新型的目的。
本实用新型的特点可参阅本案图式及以下较好实施方式的详细说明而获得清楚地了解。
附图说明
图1为本实用新型的混合信号二进制cnn处理器的网络拓扑示意图;
图2为本实用新型的混合信号二进制cnn处理器的结构示意图;
图3为本实用新型的混合信号二进制cnn处理器局部性如何转化为减少的负载的示意图;
图4为本实用新型的混合信号二进制cnn处理器神经元原理的示意图;
图5是本实用新型的混合信号二进制cnn处理器室温下测量结果的示意图。
具体实施方式
为了使本实用新型实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体图示,进一步阐述本实用新型。
实施例
如图1至图5所示,本实用新型的混合信号二进制cnn处理器,它包括神经元阵列单元10、二进制温度译码单元20、控制单元30、输入图像单元40、输出图像单元50和存储单元60,rgb图像通过二进制温度译码单元20的输入端输入,二进制温度译码单元20的输出端通过输入图像单元40与神经元阵列单元10的输入端相连接,神经元阵列单元10的输出端与输出图像单元50相连接,控制单元30与神经元阵列单元10相连接,控制指令通过控制单元30的输入端输入,存储单元60与神经元阵列单元10相连接。
在本实施例中,神经元阵列单元10、二进制温度译码单元20、控制单元30、输入图像单元40和输出图像单元50的具体电路原路图参见附图,在此就不赘述了;存储单元60采用hynix的hy62lf16806b。
在本实施例中,存储单元60包括本地存储器61、第一过滤器存储器62和第二过滤器存储器63,本地存储器61、第一过滤器存储器62和第二过滤器存储器63分别与神经元阵列单元10相连接。第一过滤器存储器62和第二过滤器存储器63以乒乓方式交替输入和输出。
在本实施例中,输入图像单元40包括输入图像存储器41和输入多路分配器42,二进制温度译码单元20的输出端依次通过输入图像存储器41和输入多路分配器42与神经元阵列单元10的输入端相连接。
在本实施例中,输出图像单元50包括输出图像存储器51和输出多路分配器52,神经元阵列单元10的输出端依次通过输出多路分配器52和输出图像存储器51输出。
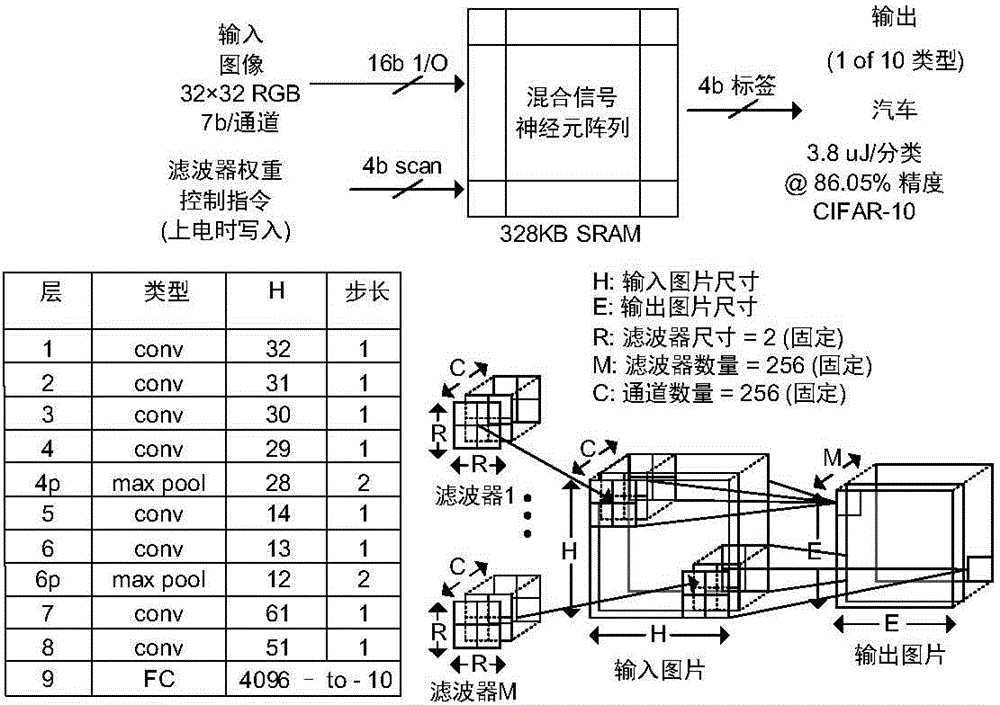
如图1所示,说明了本实用新型的混合信号二进制cnn处理器的功能和网络拓扑结构。通过强制执行结构规则化,允许物理体系结构最大限度地利用cnn算法的局部性。每个cnn层执行多通道多过滤器卷积。每个卷积层中的过滤器数量限制为256,过滤器大小为2×2,通道数量为256;这种规律性带来的电路优点是短线路和阵列式低扇出分路器,使内存和逻辑之间路径负载最小化。
如图2所示,本实用新型的混合信号二进制cnn处理器最多可支持9层,并具有用于输入输出操作,cnn和全连接(fc)层的定制的指令集。本实用新型的混合信号二进制cnn处理器读取rgb图像,将通道通过二进制温度译码单元20转换为85级温度计代码,并将它们叠加成一个256通道的图像,作为本实用新型的混合信号二进制cnn处理器的输入。在输出端,通过本地存储器61以数字方式计算4个比特的类标签。对于cnn层,第一过滤器存储器62和第二过滤器存储器63以乒乓方式交替输入和输出角色。这些存储单元60宽度为256比特,每个字代表一个256通道像素。本实用新型的混合信号二进制cnn处理器的计算在神经元阵列单元10内完成,消除部分和。权重从sram传输到本地存储器61(锁存器)并被重新使用,而第一过滤器存储器62和第二过滤器存储器63则遍历图像。64个数据并行阵列形式的神经元处理输入图像的一个片段,将输入图像存储器41处每个过滤器对应的读取能量分摊64倍。输入多路分配器42在输入图像存储器41(加载像素)和神经元阵列单元10(接收片段)之间的交互。对于fc层,权重一次从单独的sram库64个通道加载,乘法累加操作在数字域中顺序执行。
如图3所示,显示了局部性如何转化为减少的负载。输入多路分配器42是一组带有输出寄存器的1至4解复用器。输入图像的每个像素可以重用于处理两个重叠的片段,将每个过滤器计算的输入图像存储器41读取能量分摊2倍。一个2乘2的横杆在神经元阵列单元10的输入处交换像素对。过滤器权重通过每个神经元4比特的bus转移,分成北半部和南半部,以将权重传输的负荷降低2倍。为了使神经元阵列与存储器的接线最简化,每个神经元写入每个cnn层中相同的4个输出通道(每个过滤器组1个),允许将输出多路分配器52用1至4解复用器阵列来实现。通过首先读取输出图像存储器51中的一个位,然后用神经元输出写回其逻辑或,maxpooling逐步发生在卷积过程中。
如图4所示,显示了神经元原理图,每个神经元计算过滤器在一个输入图像片段上的加权和。随着存储能量通过平行分配和再利用的降低,乘法减少到xnor,高扇入加法成为主要瓶颈。然而,在所采用的sc神经元中,加法的的能量成本通过电荷保存节点处的小电压摆动而减小。相比之下,数字加法器树在其不同阶段将涉及到轨到轨的电压摆动并带来更大量的开关电容。神经元的主要噪声源是比较器,但其能量成本被1024个权重平摊,并且cnn可以承受一些噪声。因此sc神经元适用于低电压操作,并使用0.6v数字电源/模拟参考电压和0.8v比较器电源电压。由于sc神经元执行与数据相关的切换(除了比较器之外)的加权和,其能量随着活动而变化,像静态cmos。sc神经元使用容性dac(cdac),分为四个部分:1024比特温度计部分,用于实现过滤器,神经元偏置的二进制加权部分,阈值部分(比较器)和共模(cm)设置部分,以补偿电荷存储处的寄生效应节点。比较器偏移量在启动时使用校准进行数字化,存储在本地寄存器中,并在权重传送期间从sram加载的偏差中减去。在大的温度变化可能引起显着的偏移漂移的环境中,可以对比每个分类和吞吐量的平均能量可忽略的成本周期性地(例如每秒一次)执行校准。通过行为蒙特卡罗模拟来确定cnn在不降低分类准确度的情况下可以承受的比较器噪声,偏移和单位电容失配的数量,得到为4.6mv失调而设计的比较器和1ff的单位电容。由于表示加权和的电压是在电荷存储节点产生的,因此顶部和底部的寄生参数不会影响线性度。在卷积期间,根据顶板泄漏的要求定期清除cdac(采样0v)。为防止从电源汲取过量电荷,在顶部电容器通过clre放电之前,通过开关clr对单元电容器底板节点放电。为防止非对称电荷注入,顶板开关在底板电压恢复由过滤器权重,图像输入和偏置设置的值之前打开。
如图5所示,显示了室温下的测量结果。测量了10个不同的芯片以评估由于sc神经元中的热噪声和不匹配导致的准确度差异。在标称电源电压(vdd=vmem=1.0v,vneu=0.6v,vcomp=0.8v)时,芯片的运行速度高达380帧/秒(fps),达到5.4μj/分类。将vdd和vmem降低到0.8v时,在237fps时可达到3.8μj/分级(1.43×降低)。平均分类准确率为86.05%(见直方图),与完美数字模型中观察到的一样。直方图传播仅由sc神经元中的噪声和不匹配引起(这可能导致比完美数字模型更高的分类准确度)。平均分类准确度的95%置信区间为86.01%至86.10%,测量超过10个芯片,每个通过cifar-10测试集10,000图像30次。不包括在这些能量数字中的是1.8v芯片i/o能量,相当于0.43μj(核心能量的一小部分)。
以上显示和描述了本实用新型的基本原理和主要特征和本实用新型的优点。本行业的技术人员应该了解,本实用新型不受上述实施例的限制,上述实施例和说明书中描述的只是说明本实用新型的原理,在不脱离本实用新型精神和范围的前提下,本实用新型还会有各种变化和改进,这些变化和改进都落入要求保护的本实用新型范围内,本实用新型要求保护范围由所附的权利要求书及其等效物界定。
- 还没有人留言评论。精彩留言会获得点赞!