用于交织通道数据的可配置卷积引擎的制作方法
背景技术:
由图像传感器捕获的图像数据或从其他数据源接收的图像数据通常在进一步处理或消耗之前在图像处理流水线中处理。例如,在提供给诸如视频编码器的后续部件之前,可校正、过滤或以其他方式修改原始图像数据。为了对捕获的图像数据执行校正或增强,可采用各种部件、单元级或模块。
可构造这样的图像处理流水线,使得能够以有利的方式执行对捕获的图像数据的校正或增强,而不消耗其他系统资源。虽然可通过在中央处理单元(cpu)上执行软件程序来执行许多图像处理算法,但是在cpu上执行这些程序将消耗cpu和其他外围资源的大量带宽以及增加功耗。因此,图像处理流水线通常被实现为与cpu分离的硬件部件,并且专用于执行一个或多个图像处理算法。
各种类型的图像处理涉及核和数据之间的卷积。不同的核可用于例如模糊、锐化、压花或在图像中执行边缘检测。此类卷积操作通常由cpu执行,这降低了cpu对于其他进程的可用性。
技术实现要素:
实施方案涉及一种可配置卷积引擎,其用于通过配置卷积引擎中的部件的操作,以期望的方式对各种通道的输入数据执行卷积和机器学习操作。该卷积引擎包括第一卷积电路、第二卷积电路和耦接到第一卷积电路和第二卷积电路的通道合并电路。第一卷积电路和第二卷积电路各自通过将卷积内核应用于输入数据来生成值的流,等等。值的流可各自以交织方式限定一个或多个图像数据通道。通道合并电路根据所选择的操作模式组合来自第一卷积电路和第二卷积电路的值的流。在双卷积模式中,将来自卷积电路的第一流和第二流合并成输出流,该输出流具有采用交织方式的第一流和第二流的组合通道。在级联模式中,来自第一卷积电路的第一流被馈送到第二卷积电路的输入中。通道合并电路将第二卷积电路的结果作为输出流输出。在并联模式中,通道合并电路将来自第一卷积电路和第二卷积电路的第一流和第二流作为单独的流输出。
附图说明
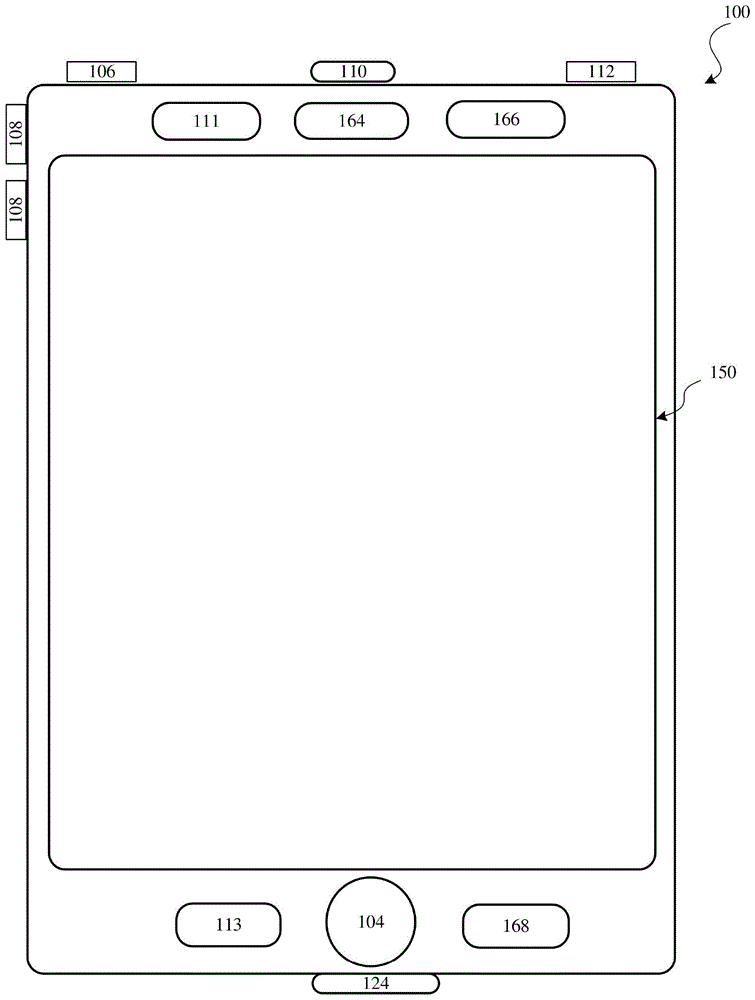
图1是根据一个实施方案的电子设备的高级图。
图2是示出根据一个实施方案的电子设备中的部件的框图。
图3是示出根据一个实施方案的使用图像信号处理器实现的图像处理流水线的框图。
图4是示出根据一个实施方案的图像信号处理器中的视觉模块的框图。
图5是根据一个实施方案的卷积引擎的框图。
图6a是根据一个实施方案的卷积引擎的双卷积模式的框图。
图6b是根据一个实施方案的卷积引擎的级联模式的框图。
图6c是根据一个实施方案的卷积引擎的并联模式的框图。
图7是示出根据一个实施方案的以多种模式操作卷积引擎的方法的流程图。
图8是示出根据一个实施方案的卷积核心电路的框图。
图9是根据一个实施方案的由响应整流器单元施加的非线性变换的曲线图。
图10是示出根据一个实施方案的卷积核心的框图。
图11a是示出根据一个实施方案的多平面格式卷积核心电路的输入和输出的概念图。
图11b是示出根据一个实施方案的平面化格式卷积核心电路的输入和输出的概念图。
图12是示出根据一个实施方案的空间合并电路的框图。
图13a和图13b是示出根据一个实施方案的多平面格式空间合并电路的输入和输出的概念图。
图13c和图13d是示出根据一个实施方案的平面化格式空间合并电路的输入和输出的概念图。
图14是示出根据一个实施方案的操作空间合并电路的方法的流程图。
图15是示出根据一个实施方案的通道合并器的框图。
图16是示出根据一个实施方案的平面化格式通道合并器的输入和输出的概念图。
仅仅出于示例目的,附图描绘以及详细说明描述各种非限定性实施方案。
具体实施方式
现在将详细地参考实施方案,这些实施方案的示例在附图中示出。下面的详细描述中示出许多具体细节,以便提供对各种所描述的实施方案的充分理解。然而,可以在没有这些具体细节的情况下实施所述实施方案。在其他情况下,没有详细地描述众所周知的方法、过程、部件、电路和网络,从而不会不必要地使实施方案的各个方面晦涩难懂。
本公开的实施方案涉及一种可配置卷积引擎,其用于通过配置卷积引擎中的部件的操作,以期望的方式对各种通道的输入数据执行卷积和每通道机器学习操作。该卷积引擎是一种电路,其包括第一卷积电路、第二卷积电路和耦接到第一卷积电路和第二卷积电路的通道合并电路。第一卷积电路和第二卷积电路各自通过将卷积内核应用于输入数据来生成值的流,等等。值的流可各自以交织方式限定一个或多个图像数据通道。通道合并电路可以根据所选择的操作模式组合来自第一卷积电路和第二卷积电路的值的流。在双卷积模式中,将值的流组合成单个输出流,该单个输出流具有以交织方式布置的来自第一流的通道和来自第二流的通道。
示例性电子设备
本文描述了电子设备、此类设备的用户界面和使用此类设备的相关过程的实施方案。在一些实施方案中,该设备为还包含其他功能诸如个人数字助理pda和/或音乐播放器功能的便携式通信设备,诸如移动电话。便携式多功能设备的示例性实施方案包括但不限于来自appleinc.(cupertino,california)的
图1是根据一个实施方案的电子设备100的高级图。设备100可包括一个或多个物理按钮,诸如“home”按钮或菜单按钮104。菜单按钮104例如用于导航到在设备100上执行的一组应用程序中的任何应用程序。在一些实施方案中,菜单按钮104包括识别菜单按钮104上的指纹的指纹传感器。指纹传感器能够被用来确定菜单按钮104上的手指是否具有与为解锁设备100存储的指纹匹配的指纹。另选地,在一些实施方案中,菜单按钮104被实现为触摸屏上显示的图形用户界面(gui)中的软键。
在一些实施方案中,设备100包括触摸屏150、菜单按钮104、用于使设备开/关机和用于锁定设备的下压按钮106、音量调节按钮108、用户身份模块(sim)卡槽110、耳麦插孔112和对接/充电外部端口124。下压按钮106可被用于通过压下该按钮并将该按钮保持在压下状态达预定义的时间间隔来对设备进行开关机;通过压下该按钮并在该预定义的时间间隔过去之前释放该按钮来锁定设备;和/或对设备进行解锁或发起解锁过程。在另选的实施方案中,设备100还通过麦克风113接受用于激活或去激活某些功能的语音输入。设备100包括各种部件,包括但不限于存储器(可包括一个或多个计算机可读存储介质)、存储器控制器、一个或多个中央处理单元(cpu)、外围设备接口、rf电路、音频电路、扬声器111、麦克风113、输入/输出(i/o)子系统和其他输入或控制设备。设备100可包括一个或多个图像传感器164、一个或多个接近传感器166,以及一个或多个加速度计168。设备100可包括图1中未示出的部件。
设备100仅是电子设备的一个示例,并且设备100可具有比上面列出的更多或更少的部件,其中一些部件可组合成部件或具有不同的配置或布置。以上列出的设备100的各种部件体现为硬件、软件、固件或其组合,包括一个或多个信号处理和/或专用集成电路(asic)。
图2是示出根据一个实施方案的设备100中的部件的框图。设备100可执行包括图像处理在内的各种操作。出于此目的和其他目的,设备100可包括图像传感器202、片上系统(soc)部件204、系统存储器230、永久存储器(例如,闪存)228、运动传感器234和显示器216,以及其他部件。图2中所示的部件仅为例示性的。例如,设备100可包括图2中未示出的其他部件(诸如扬声器或麦克风)。另外,一些部件(诸如运动传感器234)可从设备100中省略。
图像传感器202是用于捕获图像数据的部件,并且可实现为例如互补金属氧化物半导体(cmos)有源像素传感器、相机、摄像机或其他设备。图像传感器202生成原始图像数据,其被发送到soc部件204以进行进一步处理。在一些实施方案中,由soc部件204处理的图像数据显示在显示器216上,存储在系统存储器230、永久存储器228中,或经由网络连接发送到远程计算设备。由图像传感器202生成的原始图像数据可以是bayer滤色器阵列(cfa)图案(下文中也称为“bayer图案”)。
运动传感器234是用于感测设备100的运动的部件或一组部件。运动传感器234可生成指示设备100的取向和/或加速度的传感器信号。传感器信号被发送到soc部件204以用于各种操作,诸如打开设备100或旋转显示器216上显示的图像。
显示器216是用于显示由soc部件204生成的图像的部件。显示器216可包括例如液晶显示器(lcd)设备或有机发光二极管(oled)设备。基于从soc部件204接收的数据,显示器116可显示各种图像,诸如菜单、所选择的操作参数、由图像传感器202捕获并由soc部件204处理的图像,和/或从设备100的用户界面接收的其他信息(未示出)。
系统存储器230是用于存储由soc部件204执行的指令以及用于存储由soc部件204处理的数据的部件。系统存储器230可体现为任何类型的存储器,包括例如动态随机存取存储器(dram)、同步dram(sdram)、双倍数据速率(ddr、ddr2、ddr3等)rambusdram(rdram)、静态ram(sram)或其组合。在一些实施方案中,系统存储器230可以各种格式存储像素数据或其他图像数据或统计。
永久存储器228是用于以非易失性方式存储数据的部件。即使电力不可用,永久存储器228也保留数据。永久存储器228可体现为只读存储器(rom)、nand或nor、闪存或其他非易失性随机存取存储器设备。
soc部件204体现为一个或多个集成电路(ic)芯片并执行各种数据处理过程。soc部件204可包括图像信号处理器(isp)206、中央处理器单元(cpu)208、网络接口210、传感器接口212、显示控制器214、图形处理器(gpu)220、存储器控制器222、视频编码器224、存储控制器226和各种其他输入/输出(i/o)接口218以及连接这些子部件的总线232等其他子部件。soc部件204可包括比图1中所示的子部件更多或更少的子部件。
isp206是执行图像处理流水线的各级的硬件。在一些实施方案中,isp206可从图像传感器202接收原始图像数据,并将原始图像数据处理成soc部件204的其他子部件或设备100的部件可用的形式。isp206可执行各种图像处理操作,诸如图像翻译操作、水平和垂直缩放、颜色空间转换和/或图像稳定化变换,如下面参考图3详细描述的。
cpu208可使用任何合适的指令集架构来实现,并且可被配置为执行在该指令集架构中定义的指令。cpu108可以是使用各种指令集架构(isa)中的任一者的通用或嵌入式处理器,诸如x86、powerpc、sparc、risc、arm或mipsisa,或任何其他合适的isa。尽管图2中示出了单个cpu,但是soc部件204可包括多个cpu。在多处理器系统中,每个cpu可共同实现相同的isa,但不是必需的。
图形处理单元(gpu)220是用于执行图形数据的图形处理电路。例如,gpu220可渲染要显示到帧缓冲器中的对象(例如,包括整个帧的像素数据的帧缓冲器)。gpu220可包括一个或多个图形处理器,该图形处理器可执行图形软件以进行部分或全部的图形操作或某些图形操作的硬件加速。
i/o接口218是用于与设备100中的各种输入/输出部件交接的硬件、软件、固件或其组合。i/o部件可包括诸如键盘、按钮、音频设备和诸如全球定位系统的传感器之类的设备。i/o接口218处理用于将数据发送到此类i/o部件的数据或处理从这些i/o部件接收的数据。
网络接口210是使得能够经由一个或多个网络(例如,载体或代理设备)在设备100和其他设备之间交换数据的子部件。例如,视频或其他图像数据可经由网络接口210从其他设备接收并被存储在系统存储器230中以用于后续处理(例如,经由到图像信号处理器206的后端接口,诸如下面在图3中讨论的)和显示。网络可包括但不限于局域网(lan)(例如,以太网或公司网络)和广域网(wan)。经由网络接口210接收的图像数据可由isp206进行图像处理过程。
传感器接口212是用于与运动传感器234交接的电路。传感器接口212从运动传感器234接收传感器信息并处理传感器信息以确定设备100的取向或移动。
显示控制器214是用于发送要在显示器216上显示的图像数据的电路。显示控制器214从isp206、cpu208、图形处理器220或系统存储器230接收图像数据,并将图像数据处理成适于在显示器216上显示的格式。
存储器控制器222为用于与系统存储器230通信的电路。存储器控制器222可从系统存储器230读取数据以供isp206、cpu208、gpu220或soc部件204的其他子部件处理。存储器控制器222还可将数据写入从soc部件204的各种子部件接收的系统存储器230。
视频编码器224是硬件、软件、固件或其组合,用于将视频数据编码成适于存储在永久存储器128中的格式,或者用于将数据传递到网络接口210以通过网络传输到另一设备。
在一些实施方案中,soc部件204的一个或多个子部件或这些子部件的一些功能可由在isp206、cpu208或gpu220上执行的软件部件来执行。此类软件部件可存储在系统存储器230、永久存储器228或经由网络接口210与设备100通信的另一设备中。
图像数据或视频数据可流过soc部件204内的各种数据路径。在一个示例中,可从图像传感器202生成并由isp206处理原始图像数据,然后经由总线232和存储器控制器222发送到系统存储器230。在图像数据存储在系统存储器230中之后,它可由视频编码器224访问以进行编码,或者由显示器116访问以通过总线232进行显示。
在另一示例中,从图像传感器202以外的源接收图像数据。例如,视频数据可经由有线或无线网络流式传输、下载或以其他方式传送到soc部件204。可以经由网络接口210接收图像数据并经由存储器控制器222将图像数据写入系统存储器230。然后,图像数据可由isp206从系统存储器230获得,并通过一个或多个图像处理流水线级处理,如下面参考图3详细描述的。然后可将图像数据返回到系统存储器230或者将其发送到视频编码器224、显示控制器214(用于在显示器216上显示)或存储控制器226以便存储在永久存储器228中。
示例性图像信号处理流水线
图3是示出根据一个实施方案的使用isp206实现的图像处理流水线的框图。在图3的实施方案中,isp206耦接到图像传感器202以接收原始图像数据。isp206实现图像处理流水线,该图像处理流水线可包括从创建、捕获或接收到输出的处理图像信息的一组级。除了其他部件之外,isp206可包括传感器接口302、中央控制320、前端流水线级330、后端流水线级340、图像统计模块304、视觉模块322、后端接口342和输出接口316。isp206可包括图3中未示出的其他部件或者可省略图3中所示的一个或多个部件。
在一个或多个实施方案中,isp206的不同部件以不同的速率处理图像数据。在图3的实施方案中,前端流水线级330(例如,原始处理级306和重新采样处理级308)可以初始速率处理图像数据。因此,由这些前端流水线级330以初始速率执行各种不同技术、调整、修改或其他处理操作。例如,如果前端流水线级330每个时钟周期处理2个像素,则原始处理级308操作(例如,黑电平补偿、高亮恢复和缺陷像素校正)可一次处理2个像素的图像数据。相比之下,一个或多个后端流水线级340可以小于初始数据速率的不同速率处理图像数据。例如,在图3的实施方案中,可以降低的速率(例如,每个时钟周期1个像素)来处理后端流水线级340(例如,噪声处理级310、颜色处理级312和输出重新缩放314)。尽管本文所述的实施方案包括其中一个或多个后端流水线级340以与初始数据速率不同的速率处理图像数据的实施方案,但在一些实施方案中,后端流水线级340可以初始数据速率处理图像数据。
传感器接口302从图像传感器202接收原始图像数据,并将原始图像数据处理成可由流水线中的其他级处理的图像数据。传感器接口302可执行各种预处理操作,诸如图像裁剪、合并或缩放以减小图像数据大小。在一些实施方案中,像素以光栅顺序(即,水平地、逐行地)从图像传感器202发送到传感器接口302。流水线中的后续处理也可以光栅顺序执行,并且结果也可以光栅顺序输出。尽管图3中仅示出了单个图像传感器202和单个传感器接口302,当在设备100中提供多于一个图像传感器时,可在isp206中提供相应数量的传感器接口以处理来自每个图像传感器的原始图像数据。
前端流水线级330处理原始或全色域中的图像数据。前端流水线级330可包括但不限于原始处理级306和重新采样处理级308。例如,原始图像数据可是bayer原始格式。在bayer原始图像格式中,在每个像素中提供特定于特定颜色(而不是所有颜色)的值的像素数据。在图像捕获传感器中,图像数据通常以bayer模式提供。原始处理级308可以bayer原始格式处理图像数据。
原始处理级308执行的操作包括但不限于传感器线性化、黑电平补偿、固定模式噪声降低、缺陷像素校正、原始噪声滤波、镜头阴影校正、白平衡增益和高光恢复。传感器线性化是指将非线性图像数据映射到线性空间以进行其他处理。黑电平补偿是指为图像数据的每个颜色分量(例如,gr,r,b,gb)独立地提供数字增益、偏移和剪辑。固定模式噪声降低是指通过从输入图像中减去暗帧并将不同增益乘以像素来去除偏移固定模式噪声并获得固定模式噪声。缺陷像素校正是指检测缺陷像素,然后替换缺陷像素值。原始噪声滤波是指通过平均亮度相似的相邻像素来降低图像数据的噪声。突出显示恢复是指对从其他通道剪辑(或接近剪辑)的那些像素的像素值进行估计。镜头阴影校正是指对每像素应用增益来补偿与距离透镜光学中心的距离大致成比例的强度下降。白平衡增益是指为所有颜色分量(例如bayer格式的gr,r,b,gb)独立地提供针对白平衡的数字增益、偏移和剪辑。isp206的部件可将原始图像数据转换为全色域中的图像数据,因此,除了原始图像数据之外或代替原始图像数据,原始处理级308可处理全色域中的图像数据。
重采样处理级308执行各种操作以转换、重采样或缩放从原始处理级306接收的图像数据。由重采样处理级308执行的操作可包括但不限于去马赛克操作、每像素颜色校正操作、γ映射操作、颜色空间转换和缩小或子带分裂。去马赛克操作是指将颜色缺失样本从原始图像数据(例如,在bayer模式中)转换或内插成输出图像数据输到全色域中。去马赛克操作可包括对内插样本进行的低通定向滤波以获得全色像素。每像素颜色校正操作是指使用关于每个颜色通道的相对噪声标准偏差的信息在每个像素的基础上执行颜色校正以校正颜色而不放大图像数据中的噪声的处理。γ映射是指将图像数据从输入图像数据值转换为输出数据值以执行特殊图像效果,包括黑白转换、棕褐色调转换、负转换或曝光转换。出于γ映射的目的,可使用针对每个像素的不同颜色分量或通道的查找表(或将像素值索引到另一值的其他结构)(例如,针对y,cb和cr颜色分量的单独查找表)。颜色空间转换是指将输入图像数据的颜色空间转换为不同的格式。在一个实施方案中,重采样处理级308将rbd格式转换为ycbcr格式以供进一步处理。
中央控制320可控制和协调isp206中的其他部件的整体操作。中央控制320执行包括但不限于以下项的各种操作:监视各种操作参数(例如,记录时钟周期、存储器等待时间、服务质量和状态信息)、更新或管理isp206的其他部件的控制参数以及与传感器接口302交接以控制isp206的其他部件的开始和停止。例如,在isp206中的其他部件处于空闲状态时,中央控制320可更新其他部件的可编程参数。在更新可编程参数之后,中央控制320可将isp206的这些部件置于运行状态以执行一个或多个操作或任务。中央控制320还可指示isp206的其他部件在重采样处理级308之前、期间或之后存储图像数据(例如,通过写入图2中的系统存储器230)。以这种方式,除了处理从重采样处理级308通过后端流水线级340输出的图像数据之外或代替处理从重采样处理级308通过后端流水线级340输出的图像数据,可存储原始或全色域格式的全分辨率图像数据。
图像统计模块304执行各种操作以收集与图像数据相关联的统计信息。收集统计信息的操作可包括但不限于传感器线性化、掩模图案缺陷像素、子样本原始图像数据、检测和替换非图案化缺陷像素、黑电平补偿、镜头阴影校正和反相黑电平补偿。在执行一个或多个此类操作之后,可收集或跟踪统计信息诸如3a统计(自动白平衡(awb)、自动曝光(ae)、自动聚焦(af))、直方图(例如,2d颜色或分量)和任何其他图像数据信息。在一些实施方案中,当先前的操作识别被剪辑的像素时,某些像素的值或像素值的区域可从某些统计数据的集合(例如,af统计)中排除。尽管图3中仅示出了单个统计模块304,多个图像统计模块可包括在isp206中。在此类实施方案中,每个统计模块可由中央控制320编程,以收集相同或不同图像数据的不同信息。
视觉模块322执行各种操作以促进cpu208处的计算机视觉操作,诸如图像数据中的面部检测。视觉模块322可执行各种操作,包括预处理、全局色调映射和γ校正、视觉噪声滤波、尺寸调整、关键点检测,卷积以及方向梯度直方图(hog)的生成。如果输入图像数据不是ycrcb格式,则预处理可包括子采样或合并操作以及亮度计算。可对亮度图像上的预处理数据执行全局映射和γ校正。执行视觉噪声滤波以去除像素缺陷并减少图像数据中存在的噪声,从而改善后续计算机视觉算法的质量和性能。此类视觉噪声滤波可包括检测和固定点或缺陷像素,以及通过平均相似亮度的相邻像素来执行双边滤波以降低噪声。各种视觉算法使用不同大小和比例的图像。例如,通过合并或线性插值操作来执行图像的尺寸调整。关键点是图像内被非常适合于匹配同一场景或对象的其他图像的图像块包围的位置。此类关键点在图像对齐、计算相机姿势和对象跟踪方面很有用。关键点检测是指识别图像中的此类关键点的过程。卷积可在图像/视频处理和机器视觉中使用。例如,可以执行卷积以生成图像的边缘图或使图像平滑。hog提供图像分析和计算机视觉中用于任务的图像块的描述。例如,可通过(i)使用简单的差分滤波器计算水平梯度和垂直梯度,(ii)根据水平梯度和垂直梯度计算梯度方向和量值,以及(iii)对梯度方向进行合并来生成hog。
后端接口342从图像传感器202之外的其他图像源接收图像数据,并将其转发到isp206的其他部件以进行处理。例如,可通过网络连接接收图像数据并将其存储在系统存储器230中。后端接口342检索存储在系统存储器230中的图像数据,并将其提供给后端流水线级340以进行处理。由后端接口342执行的许多操作之一是将检索的图像数据转换为可由后端处理级340使用的格式。例如,后端接口342可将rgb、ycbcr4:2:0或ycbcr4:2:2格式化的图像数据转换为ycbcr4:4:4颜色格式。
后端流水线级340根据特定的全色格式(例如,ycbcr4:4:4或rgb)处理图像数据。在一些实施方案中,后端流水线级340的部件可在进一步处理之前将图像数据转换为特定的全色格式。后端流水线级340可包括噪声处理级310和颜色处理级312等其他级。后端流水线级340可包括图3中未示出的其他级。
噪声处理级310执行各种操作以减少图像数据中的噪声。由噪声处理级310执行的操作包括但不限于颜色空间转换、γ/去γ映射、时间滤波、噪声滤波、亮度锐化和色度噪声降低。颜色空间转换可将图像数据从一种颜色空间格式转换为另一种颜色空间格式(例如,转换为ycbcr格式的rgb格式)。γ/去γ操作将图像数据从输入图像数据值转换为输出数据值以执行特殊图像效果。时间滤波使用先前滤波的图像帧来滤除噪声以减少噪声。例如,先前图像帧的像素值与当前图像帧的像素值组合。噪声滤波可包括例如空间噪声滤波。亮度锐化可锐化像素数据的亮度值,而色度抑制可将色度衰减为灰色(即,没有颜色)。在一些实施方案中,亮度锐化和色度抑制可与空间噪声滤波同时进行。可针对图像的不同区域不同地确定噪声滤波的积极性。可包括空间噪声滤波作为实现时间滤波的时间循环的一部分。例如,先前的图像帧可以在被存储为用于待处理的下一个图像帧的参考帧之前由时间滤波器和空间噪声滤波器处理。在其他实施方案中,空间噪声滤波可不被包括作为用于时间滤波的时间循环的一部分(例如,空间噪声滤波器可以在图像帧被存储为参考图像帧(并且因此不是空间上过滤的参考帧)之后应用于图像帧)。
颜色处理级312可执行与调整图像数据中的颜色信息相关联的各种操作。在颜色处理级312中执行的操作包括但不限于局部色调映射、增益/偏移/剪辑、颜色校正、三维颜色查找、γ转换和颜色空间转换。局部色调映射指的是空间变化的局部色调曲线,以便在渲染图像时提供更多控制。例如,色调曲线的二维网格(其可以由中央控制320编程)可以是双线性内插的,由此使得在图像上产生平滑变化的色调曲线。在一些实施方案中,局部色调映射还可应用空间变化和强度变化的颜色校正矩阵,其可例如用于使天空更蓝,同时在图像中的阴影中调低蓝色。可为每个颜色通道或图像数据的分量提供数字增益/偏移/剪辑。颜色校正可将颜色校正变换矩阵应用于图像数据。3d颜色查找可利用颜色分量输出值的三维阵列(例如,r,g,b)来执行高级色调映射、颜色空间转换和其他颜色变换。例如,可通过将输入图像数据值映射到输出数据值来执行γ转换,以便执行γ校正、色调映射或直方图匹配。可以实现颜色空间转换以将图像数据从一个颜色空间转换为另一个颜色空间(例如,rgb到ycbcr)。其他处理技术也可以作为颜色处理级312的一部分来执行,以执行其他特殊图像效果,包括黑白转换、棕褐色调转换、负转换或曝光转换。
当isp206处理图像数据时,输出重缩放模块314可以即时重采样、变换和校正失真。输出重缩放模块314可以计算每个像素的分数输入坐标,并且使用该分数坐标来经由多相重采样滤波器内插输出像素。可以从输出坐标的多种可能的变换产生分数输入坐标,诸如对图像调整大小或裁剪(例如,经由简单的水平和垂直缩放变换)、旋转和剪切图像(例如,经由不可分离的矩阵变换)、透视翘曲(例如,经由附加的深度变换)以及以条带状分段施加的每像素透视分割以说明图像数据捕获期间(例如,由于卷帘式快门所引起的)的图像传感器中的变化的原因,以及几何失真校正(例如,经由计算距光学中心的径向距离以便索引内插的径向增益表,并且将径向扰动应用于坐标以说明径向透镜失真的原因)。
当在输出重缩放模块314处处理图像数据时,输出重缩放模块314可将变换应用于图像数据。输出重缩放模块314可包括水平缩放部件和垂直缩放部件。该设计的垂直部分可实现一系列图像数据行缓冲器以保持该垂直滤波器所需的“支持”。由于isp206可以是流设备,因此可能只有行的有限长度滑动窗口中的图像数据行可供过滤器使用。一旦行被丢弃来为新进来的行腾出空间,则该行可不可用。输出重缩放模块314可统计地监视先前行上的计算输入y坐标,并使用它来计算要保持在垂直支持窗口中的一组最佳行。对于每个后续行,输出重缩放模块可自动生成关于垂直支持窗口的中心的猜测。在一些实施方案中,输出重缩放模块314可实现被编码为数字差分分析器(dda)步进器的分段透视变换表,以在输入图像数据和输出图像数据之间执行每像素透视变换,以便校正在图像帧的捕获期间由传感器运动引起的伪像和运动。输出重缩放可以经由输出接口314将图像数据提供到系统100的各种其他部件,如上面关于图1和图2所论述的。
在各种实施方案中,部件302到342的功能可以与图3中所示的图像处理流水线中的这些功能单元的顺序所暗含的顺序不同的顺序执行或者可由与图3中所示的功能部件不同的功能部件来执行。此外,如图3中所描述的各种部件可以硬件、固件或软件的各种组合来体现。
示例性视觉模块
如上文参考图3所述,视觉模块322执行各种操作以促进cpu208处的计算机视觉操作。为此,除其他部件之外,视觉模块322可包括方向梯度直方图(hog)模块412、复用器420和卷积引擎414,如图4所示。视觉模块322可包括图4中未示出的其他部件,诸如缩放模块。
hog引擎400处理图像以生成每个图像的hog数据426。hog数据426的一个示例是基于图像内所识别的梯度方向为图像生成的方向梯度直方图。hog数据426可用于各种计算机视觉应用,诸如图像分类、场景检测、面部表情检测、人体检测、对象检测、场景分类和文本分类。
复用器420从hog引擎412接收hog数据426并从图像处理处理器206的除hog引擎412之外的部件(例如,dram存储器)接收像素数据424,并且根据各种操作模式选择hog数据426或像素数据424作为输入数据422以转发到卷积引擎414。在一种模式中,复用器420可将hog数据426作为输入数据422转发到卷积引擎414。在另一种模式中,复用器420可将像素数据424作为输入数据422转发到卷积引擎414,以用于执行诸如锐化、模糊和边缘检测之类的操作。用于控制复用器420的配置信号可从中央控制320接收。像素数据422是多个通道的交织像素值的流。
卷积引擎414是对输入数据422执行卷积操作的可配置电路。为此,卷积引擎414包括用于存储卷积核信息,用于执行计算和用于积累相乘值以生成输出428的部件,如下文结合图5详细描述的。
图4所示的视觉模块322的结构仅为例示性的,并且可对图4的结构进行各种改变。例如,可省略诸如hog引擎412和复用器420之类的部件。另选地,复用器420可从多于两个源接收像素数据并选择一个源用于作为流输入数据422输入到卷积引擎414。
在以下描述中,为便于说明,假定输入数据422是像素值。但需注意,输入数据422可以是适用于卷积操作的其他类型的数据(例如,hog数据)。
示例性卷积引擎架构
图5是示出根据一个实施方案的卷积引擎414的框图。卷积引擎414是对交织的多通道图像数据执行操作以促进图像/视频处理和计算机视觉的电路。卷积引擎414可对多通道图像数据执行各种类型的操作,诸如卷积操作、通道间处理操作和每通道处理操作。示例性卷积操作可包括生成边缘图或平滑图像。例如,与高斯核卷积的图像可产生具有减小的噪声和混叠的平滑图像。又如,当图像与一组多方向卷积核卷积时,卷积引擎414生成用于分类的图像特征,诸如gabor特征。另外,在一些实施方案中,卷积引擎414促进用于深度机学习分类任务(诸如人员或对象检测)的模板匹配。
卷积引擎414执行各种操作以促进卷积神经网络(cnn)任务,诸如空间合并和局部响应归一化。cnn是一种深度学习架构,可以执行图像分类、对象检测和其他计算机视觉任务。
卷积引擎414接收输入数据422,诸如来自总线232的输入数据,并且基于所存储的卷积核信息对输入数据422执行卷积操作,对卷积操作的结果执行通道间和每通道处理,并且生成输出数据428。
除了其他部件之外,卷积引擎414可包括第一卷积电路502、解复用器电路503、第二卷积电路504和通道合并电路506。尽管卷积引擎414被示出为包括第一卷积电路502和第二卷积电路504,但在一些实施方案中,卷积引擎414可包括n个卷积电路。第一卷积电路502接收输入数据422的流,并且向输入数据422施加一个或多个卷积核以生成值530的流。第二卷积电路504还接收输入数据422的流(或另选地,从第一卷积电路502输出的值530的流),并将一个或多个卷积核应用于输入数据422以生成值532的流。由卷积电路502或504接收和处理的输入数据的流各自以交织方式定义输入数据的一个或多个通道。
第一卷积电路502包括复用器508、预处理电路510、卷积核心电路512和空间合并电路514。复用器508耦接到预处理电路510,预处理电路510耦接到卷积核心电路512,并且卷积核心电路512耦接到空间合并电路514。
复用器508从总线232接收输入数据422,并将输入数据422提供给预处理电路510。在一些实施方案中,复用器508在来自总线232的输入数据424和一个或多个其他数据源(例如,hog数据426)之间进行选择,并将所选择的数据提供给预处理电路510。在其他实施方案中,从第一卷积电路502中省略了复用器508,并且预处理电路510从总线232接收输入数据424。
预处理电路510对交织的输入数据422执行预处理操作,诸如通过对输入数据422应用增益、偏移和限幅操作。这些操作可用于在卷积之前应用各种类型的处理,诸如均值减法或对比度拉伸。在一些实施方案中,预处理电路510从输入数据422的流中识别每个通道的值,并且独立地处理每个通道以对不同通道的输入值应用不同的增益、偏移或限幅操作。例如,输入数据422可以是bayer原始格式,包括交织的gr、r、b和gb通道。预处理电路510可对不同通道的像素数据应用不同的增益、偏移或限幅操作。在一些实施方案中,预处理电路510以旁路模式操作,该旁路模式将输入传递到卷积核心电路512而不应用预处理操作。
卷积核心电路512从预处理电路510接收经预处理的输入数据,并且将一个或多个卷积核应用于输入数据。卷积核心电路512还可对卷积结果执行后处理。后处理可包括产生用于深度机学习的值的操作,诸如多通道归一化互相关(ncc)或通道间局部响应归一化(lrn)。多通道或通道间操作将来自两个或更多个通道的值组合用于卷积结果。由卷积核心电路512生成的流中的值序列以交织方式限定多个数据通道。卷积核心电路512的结果被提供到空间合并电路514。在一些实施方案中,卷积核心电路512的结果从卷积引擎414输出,如由值436的流所示。
空间合并电路514对卷积核心电路512的输出执行每通道操作,诸如每通道空间合并和每通道局部响应归一化(lrn),并且输出值530的流。每通道操作分别处理与每个通道相关联的值。每通道lrn在响应图中将局部对比度归一化。每通道操作可在卷积层之后应用以促进深度机器学习。与卷积层相比,空间合并电路514的每通道操作具有较低的计算成本,因为它们通常在较小的局部窗口中应用并且不使用卷积核系数。
第二卷积电路504包括复用器518、预处理电路520、卷积核心电路522和空间合并电路525。以上关于第一卷积电路502的讨论可以适用于第二卷积电路504,以及可以包括在卷积引擎414中的任何其他卷积电路。mux518在从第一卷积核心电路502输出的值530的流和来自总线232的输入值422之间进行选择,并且将所选择的输入发送到预处理电路520。第二卷积电路504可以将类似的操作应用于值530的流或输入值424的流,因为这两个流都包括交织方式的数据的通道。预处理电路520、卷积核心电路522和空间合并电路524的操作和功能与预处理电路510、卷积核心电路512和空间合并电路514基本上相同,因此,为了简洁起见,本文中省略对这些电路的详细描述。
解复用器电路503是接收值530的流并且将输出发送到通道合并电路506或第二卷积电路504的电路。解复用器503可以基于来自中央控制320的指令来选择路线。中央控制320基于操作模式来设置解复用器503的选择,操作模式为卷积电路502和504串联操作的级联模式,以及卷积电路502和504并联操作的其他模式。在一些实施方案中,从卷积引擎414中省略去复用器电路503。
通道合并电路506的输入耦接到第一卷积电路502的输出,并且另一输入耦接到第二卷积电路504的输出。通道合并电路506分别从卷积电路502和504接收值530和532的流,并将这些值组合成输出值428的一个或多个输出流,诸如值428a和428b的流。从卷积电路502和504接收的值的流可以根据为卷积引擎414选择的操作模式以各种方式进行处理,如下面结合图6a至图6c更详细地讨论的。
通道合并电路506包括通道合并器526和复用器528。通道合并器526从第一卷积核心电路502接收值530的流并从第二卷积核心电路504接收值532的流,并且将值530和532交织以生成值534的流。值534的流包括来自值530的流的通道和来自值532的流的通道,如由通道合并器526以交织方式组合的。
复用器528具有耦接到来自通道合并器526的值534的流的输入,以及耦接到来自第二卷积核心电路504的值532的流的输入。复用器528在值534的流和值532的流之间选择,以作为值428b的流输出。通道合并电路506还可以从第一卷积电路502输出值530的流作为值428a的流。
卷积引擎处理模式
卷积引擎414以多种模式操作,包括双卷积模式、级联模式和并联模式。中央控制320将配置信息发送到卷积引擎414,该配置信息将卷积引擎414配置为以指定模式操作。配置信息包括对卷积引擎414的部件的指令。配置信息还可以指定部件的输入和功能,诸如每个卷积电路502和504使用的卷积核。
图6a为示出根据一个实施方案的卷积引擎414的双卷积模式的框图。在双卷积模式中,卷积电路502和504通过将不同的卷积核应用于相同的输入数据424而并联操作,并且通道合并电路506将来自卷积电路502和504的结果进行组合以生成输出值428b的输出流。与每个卷积核相关联的属性可以包括滤波器元素值、卷积核的核尺寸(例如,由核定义的窗口的高度和宽度,以像素为单位),卷积核的稀疏值以及卷积之间的步进值。从第一卷积电路502输出的值530的流和从第二卷积电路504输出的值532的流被输入到通道合并电路506。通道合并电路506通过将输出值530和532交织来生成输出值428b的输出流。值428b的输出流以双卷积模式从卷积引擎414输出。
在一些实施方案中,中央控制320通过控制复用器508、518、528和解复用器503进行的选择以将数据流路由到数据流,从而将卷积引擎414设置为双卷积模式。解复用器503(如果使用)将值530的流路由到通道合并电路506,该流作为输出值428a的输出流输出。复用器518选择从第一卷积电路502输出的值530的流作为第二卷积电路504的输入。复用器528选择从通道合并526输出的值534的流作为输出值428b的输出流。复用器508(如果使用)选择来自总线232的输入数据424作为第一卷积电路502的输入。
双卷积模式是卷积引擎414的一种配置,其在两个卷积核心电路502和504上并联处理相同输入流。卷积电路502和504可以将不同的卷积核应用于输入数据。为了促进许多输出通道的计算,卷积引擎414在卷积电路502和504之间分配处理任务。例如,第一卷积电路502可以处理输出通道的前一半,而第二卷积电路504可以处理输出通道的后一半。通道合并电路506将来自卷积电路502和504的多个通道的流组合成单个流,该单个流具有来自彼此交织的两个流的通道。
在一些实施方案中,每个卷积电路502和504具有两个执行集群,每个执行集群生成一个像素每时钟(ppc)。因此,每个卷积电路502和504生成两个ppc。在双卷积模式下合并通道之后,通道合并电路506组合卷积电路502和504的结果以生成四ppc输出。
图6b为示出根据一个实施方案的卷积引擎414的级联模式的框图。在级联模式中,卷积电路502和504串联操作。第一卷积电路502将一个或多个卷积核应用于来自总线232的输入数据422,以生成值530的流。第二卷积电路504接收值530的流,并将一个或多个第二卷积核应用于值530,以生成值532的流。卷积电路502和504可使用不同的卷积核。通道合并电路506使来自卷积电路504的值532的流通过,从而生成输出值428b的输出流。
中央控制320通过控制复用器508、518、528和解复用器503进行的选择,将卷积引擎414设置为级联模式。复用器508(如果使用)选择来自总线232的输入数据424作为第一卷积电路502的输入。解复用器503(如果使用)将值530的流路由到复用器518。复用器518选择从卷积引擎414输出的值530的流作为第二卷积电路504的输入。复用器528选择从第二卷积电路504输出的值532的流作为输出值428b的输出流。
在级联模式中,卷积电路502和504串联执行两个卷积操作,而无需在这些操作之间进行存储器传输。级联中的第一卷积电路502诸如通过使用两个执行集群中的仅一个来生成一个ppc。如果第一卷积电路502生成两个ppc输出流,则随后的第二卷积电路504将需要二进程四个ppc。因此,在第一卷积电路502中使用单个执行集群以生成输入到第二卷积电路504的一个ppc流。第二卷积电路504从第一卷积电路502的一个ppc流生成两个ppc输出流。
图6c为示出根据一个实施方案的卷积引擎414的并联模式的框图。在并联模式中,卷积电路502和504作为两个单个单元并联地操作,以生成两个单独的交织输出流。例如,图像可以被分成两个竖直条,并且每个卷积电路502和504处理一个条。卷积电路502和504可以处理相同的输入数据或不同的输入数据。当输入数据相同时,卷积电路502和504可以将不同的卷积核应用于输入数据。又如,卷积电路502和504将不同的核应用于不同的输入数据。
第一卷积电路502将一个或多个卷积核应用于来自总线232的输入数据422,以生成值530的流。第二卷积电路504将一个或多个第二卷积核应用于来自总线232的输入数据422以生成值532的流。通道合并电路506通过使值530的流通过来生成输出值428a的输出流,并且通过使值532的流通过来生成输出值428b的输出流。单独的输出流428a和428b可以各自以交织的方式定义多个数据通道。在并联模式中,来自卷积电路502和504的输出被保持在交织通道的单独流中,而不是被组合成交织通道的单个流。
中央控制320通过控制复用器508、518、528和解复用器503处的选择,将卷积引擎414设置为并联模式。复用器508(如果使用)选择来自总线232的输入数据422作为第一卷积电路502的输入。解复用器503(如果使用)将值530的流从第一卷积电路502的输出路由到通道合并电路506,以作为输出值428a的输出流输出。复用器518选择来自总线232的输入数据422作为第二卷积电路504的输入。复用器528选择从第二卷积电路504输出的值532的流用于通道合并电路506的输出值428b的输出流。通道合并电路506还将值530的流传递到输出值428a的输出流。
在并联模式中,每个卷积电路502和504可以使用两个执行集群来生成两个ppc。通道合并电路506以两个ppc从第一卷积电路502输出第一流,并且以两个ppc从第二卷积电路504输出第二流。
图7是示出了根据一个实施方案的以多种模式操作卷积引擎414的方法的流程图。中央控制320将配置信息发送702到卷积引擎414。配置信息可包括用于将卷积引擎置于特定操作模式(诸如双卷积模式、级联模式或串联模式)的卷积引擎的部件的参数。
配置信息还可包括限定输入到每个卷积核心电路502和504的值的流的信息。例如,配置信息可限定图像大小和/或通道计数,使得卷积引擎414的部件可识别来自串联流的每个通道的像素。
配置信息还可包括限定每个卷积核心电路502和504使用的一个或多个卷积核的信息,诸如过滤元件值、核尺寸、稀疏值和步进值。限定卷积核的配置信息指定由每个卷积核心电路502和504执行的卷积操作。
在接收到配置信息之后,根据配置信息更新704卷积引擎414的配置以执行配置信息中所述的操作。更新配置可包括根据所选择的操作模式在卷积引擎内路由流。可使用卷积引擎414的复用器508、518和528来设置路由控制,如上文结合图6a至图6c所讨论的。更新配置可包括向卷积电路502和504提供卷积核。卷积电路502和504也可被配置为使用一个或两个执行集群,这取决于如上所述的操作模式。
在一些实施方案中,配置指令还可限定在通道合并之前在每个卷积电路502和504处对卷积结果执行的一个或多个深度学习操作。示例性操作可包括归一化互相关计算、响应整流、空间合并和局部响应归一化。在一些实施方案中,通道间操作可由卷积核心电路502和504的后处理电路704执行,每通道操作由空间合并电路514和524执行。
卷积引擎414的第一卷积电路502通过将一个或多个第一卷积核应用于第一输入数据来生成706值的第一流。卷积引擎414的第二卷积电路504通过将一个或多个第二卷积核应用于第二输入数据来生成708值的第二流。生成第一输入数据和第二输入数据可包括执行卷积,并且还可包括利用卷积核心电路512/522的后处理电路或空间合并电路514/524来应用一个或多个深度学习操作。
在双卷积模式中,卷积电路502和504所使用的第一输入数据和第二输入数据可以是相同的,并且第一卷积核和第二卷积核可以是不同的。在级联模式中,第二卷积电路504所使用的第二输入数据是第一卷积电路502的输出,并且第一卷积核和第二卷积核可以是不同的。在并联模式中,第一输入数据和第二输入数据可以是相同的,并且第一卷积核和第二卷积核可以是不同的。
通道合并电路基于来自第一卷积电路502的值的第一流和来自第二卷积电路504的值的第二流来生成710一个或多个输出流。在双卷积模式中,通道合并电路710通过将来自第一卷积电路502的交织通道值的交织的第一流与来自第二卷积电路504的交织通道值的第二流以交织方式组合来生成输出流。在级联模式中,通道合并电路710生成包括来自第二卷积电路504的交织通道值的第二流的输出流,其中通过在第二卷积电路504处将一个或多个第二卷积核应用于交织通道值的第一流来导出交织通道值的第二流。在串联模式中,通道合并电路710生成第一输出流和单独的第二输出流,该第一输出流包括来自第一卷积电路502的交织通道值的第一流,该单独的第二输出流包括来自第二卷积电路504的交织通道值的第二流。
如图7所示的过程仅是例示性的,并且可对该过程作出各种改变。例如,如由卷积引擎414的配置信息和操作模式所指定的,生成706值的第一流和生成708值的第二流可并联或串联地执行。
卷积核心电路
图8是示出根据一个实施方案的卷积核心电路800的框图。卷积核心电路800为第一卷积电路502的卷积核心电路512或第二卷积电路504的卷积电路522的示例,如图5所示。卷积核心电路800包括卷积核心802和后处理电路804。卷积核心802接收输入数据836,并且通过将一个或多个卷积核h应用于输入数据836来执行卷积操作。输入数据836可以是来自总线323的输入数据422、另一个卷积电路的输出或来自一些其他源的输入数据,并且可如上所述由预处理电路510进行预处理。后处理电路804对卷积核心802的输出执行后处理。
卷积核心电路802包括卷积前端806、核内存808、执行集群810、执行集群812和卷积后端814。卷积前端806耦接到执行集群810和812。卷积前端806接收输入数据836并准备输入数据836以供执行集群810和812处理。卷积前端806在执行集群810和812之间分配涉及输入数据和卷积核的处理任务。
每个执行集群810和812耦接到卷积前端和核内存808。每个执行集群810和812可包括多乘法与累加(mac)单元。当使用多个输出通道时,具有偶数索引的输出通道可由一个执行集群处理,而具有偶数索引的输出通道可由另一个执行集群处理。每个执行集群810和812可生成一个ppc,因此卷积核心802整体上可生成两个ppc。执行集群810生成包括偶数索引输出通道的偶数数据值842的流和包括奇数索引输出通道的奇数数据值844的流。
核内存808存储提供给执行集群810和812的一个或多个卷积核h。在一些实施方案中,中央控制320向核内存808提供一个或多个卷积核h以控制卷积操作。每个执行集群810和812将来自核内存808的卷积核应用于由卷积前端806准备的输入数据836。执行集群810和812可并行地执行以生成输出值,例如以两个ppc。在一些实施方案中,仅启用单个执行集群810或812以生成输出值,例如以一个ppc。
在一个示例中,执行集群810和812将一系列卷积核应用于输入数据的不同部分,以生成包括偶数索引输出通道的偶数数据值842的流和包括奇数索引输出通道的奇数数据值844的流。偶数数据值842和奇数数据值844表示多通道数据,这些数据值在后处理流水线中利用通道间操作(诸如局部响应归一化和归一化互相关)来进行独立地处理。
在一些实施方案中,卷积前端806为卷积核生成核统计840,这些核统计被存储在核内存808中并由执行集群810和812进行处理。核统计可从卷积核的属性中得出。核统计840可包括∑h和∑h2,其中h为卷积核的核数据。卷积核心802将核统计840发送到后处理电路804。
卷积后端814耦接到执行集群810和812的输出。卷积后端814对来自每个执行集群的输出值执行进一步处理。此类操作可包括但不限于用于大位数据的多循环累加器。
在一些实施方案中,卷积后端814或卷积核心802的一些其他部件基于输入数据836生成局部统计信息。局部统计可包括∑i、∑i2和∑i*h,其中i是输入数据836,h是应用于输入数据836的卷积核。在一些实施方案中,经由偶数数据值842的流和奇数数据值844的流将局部统计传输到后处理电路804。例如,局部统计可为流842和844的辅助通道,诸如多通道流的最后活动通道。在其他实施方案中,局部统计可与核统计840一起在流中传输,或者在单独的流中传输。
因此,卷积核心802生成偶数数据值842的流、奇数数据值844的流、核统计840和局部统计。将这些值提供给后处理电路804以进行附加处理。下面结合图10更详细地讨论卷积核心802的示例性电路。
后处理电路804包括用于每个执行集群810和812的处理流水线以处理相应的输出流842和844。为了处理来自执行集群810的流842,后处理电路804包括多通道归一化互相关(ncc)单元816、响应整流器单元818、通道间局部响应归一化(lrn)单元820和输出生成单元822。为了处理来自执行集群812的流844,后处理电路804包括多通道ncc单元824、响应整流器单元826、通道间lrn单元828和输出生成单元830。后处理电路804还可包括峰值查找器843、解复用器832和核心合并器846。
多通道ncc单元816计算偶数数据值842的流的ncc得分和归一化核统计。多通道ncc单元816耦接到卷积核心802以接收偶数数据值842的流、局部统计和核统计840。多通道ncc单元816基于偶数数据值842、局部统计和核统计840来确定每个卷积核的ncc得分。
多通道ncc单元816可计算每个卷积核的ncc得分。通过由局部统计定义的输入方差和由核统计定义的核的方差来对ncc得分进行归一化。ncc得分可用于查找两个帧之间的最佳对应关系。
对于每个卷积核,ncc得分可由公式1定义:
其中i为输入数据,h为核数据,mi和mh为i和h的平均值,σi和σh为i和h的标准差,n为卷积核的尺寸。可应用附加缩放和偏移系数以避免除以零,并减小量化误差。
多通道ncc单元816还可计算归一化核统计。例如,多通道ncc单元816计算核统计,如公式2所定义的:
(n∑h2-(∑h)2)(2)
其中n为卷积核的尺寸,h为核数据。公式2构成公式1分母的一部分,因此可在计算ncc得分的过程中计算核统计。
归一化核统计是使用缩放系数来处理的核统计的缩放版本。缩放系数可由公式3定义:
其中n为卷积核的尺寸。缩放系数将核统计归一化为与核尺寸无关。多通道ncc单元816将归一化核统计852和/或ncc得分发送到峰值查找器834。
响应整流器单元818耦接到多通道ncc单元816。响应整流器单元818接收数据值842的流并对数据值842执行非线性变换。非线性变换有利于对描述高级特征进行深度机器学习。可从多通道ncc单元816传输输入到响应整流器单元的数据值842的流。在一些实施方案中,从后处理电路804中省略了多通道ncc单元816,并且响应整流器单元818从执行集群接收数据值842的流。
图9是根据一些实施方案的由响应整流器单元818施加的非线性变换的曲线图。响应整流器单元818将值842的流作为输入来接收,并且将偏移参数912应用于值842。可选择偏移参数912以在深度学习架构中对卷积层之后应用的偏置进行建模。在应用偏移之后,响应整流器单元818基于可配置的缩放系数904将缩放应用于负输入值。响应整流器单元818输出整流数据值的流。在一些实施方案中,响应整流器单元818将负值限幅为0。在其他实施方案中,响应整流器单元818将负值转换为正值。
重新参见图8,响应整流器单元818可对不同的通道应用不同的偏移和缩放参数。响应整流器单元818的参数可由中央控制320指定。在一些实施方案中,中央控制320可停用响应整流器单元818。在此,响应整流器单元818可用作后处理流水线中的值的流的旁路。在一些实施方案中,从后处理电路804中省略了响应整流器单元818。
通道间lrn单元820耦接到响应整流器单元818并对响应整流器单元818的输出执行通道间lrn。具体地,通道间lrn单元820接收数据值842的流和局部统计,并且执行局部响应归一化以生成数据值的归一化卷积输出流。通道间lrn单元820有利于用于深度学习架构的处理。通道间lrn单元1200可执行由公式4定义的操作的定点近似值:
其中xi为像素索引值,α为归一化的强度,i’为约xi的本地窗口内像素的索引,n为窗口中像素的数量。对本地窗口的支持是通道间的,因此以平面化格式表示为矩形区域。通道间lrn单元820在后处理阶段中执行通道间lrn以利用交织通道的串联流,而每通道归一化诸如由空间合并电路514单独地进行处理。
输出生成单元822耦接到通道间lrn单元820。输出生成单元822将缩放、偏移和移位应用于通道间lrn单元820的输出。
用于奇数值844的流的后处理流水线可基本上与用于偶数值842的流的处理流水线操作相同,因此为了简洁起见,本文省略了对这些电路的详细描述。
核心合并器846将具有偶数通道和奇数通道的偶数流842和奇数流844(例如,在后处理之后)组合成数据值848的流,该流包括呈交织方式的偶数通道和奇数通道。核心合并器847耦接到输出生成单元822和输出生成单元830。
后处理电路804还可包括解复用器832。解复用器832耦接到输出生成单元830并且选择性地将来自输出生成单元830的值的流提供给核心合并器846(以用于组合到输出流848中)或将其作为输出流850来提供。值的流848组合来自执行集群810和812两者的像素值,并因此核心合并器846例如以两个ppc生成输出。值850的流仅使用来自执行集群812的值来生成,并因此可例如以一个ppc来生成。如上文结合图6a至图6c所讨论的,卷积核心电路800可被设置成在卷积引擎414的不同操作模式下生成一个ppc或两个ppc。
峰值查找器834耦接到第一后处理流水线的多通道ncc单元816和输出生成单元822,并且耦接到第二后处理流水线的多通道ncc单元824和输出生成单元830。在一些实施方案中,归一化核统计可用作模板匹配结果的可靠性的置信度度量。峰值查找器834接收归一化核统计852和卷积结果,并且基于ncc得分来确定为模板提供最佳匹配最佳匹配位置的位置。峰值查找器843基于预先确定的标准来确定位置。例如,峰值查找器843可为所选择的通道查找到最小像素位置或最大像素位置。当给出高维特征向量的列表作为输入数据时,峰值查找器可基于由卷积核心评估的距离度量来查找到最靠近原点的向量。
在一些实施方案中,峰值查找器834监视来自输出生成单元822和830的数据的流。针对所选择的通道,峰值查找器834访问流中的通道的每个值以跟踪具有最小值或最大值的位置。所选择的输出通道可包含ncc得分或任何其他卷积结果。如果该通道包含ncc得分(例如,针对所选择的通道启用多通道ncc单元816),则峰值查找器834输出具有峰值位置和峰值ncc得分的归一化核统计。如果未启用ncc,则峰值查找器834输出峰值位置和峰值。
在一些实施方案中,中央控制320将配置信息发送到卷积核心802和卷积核心电路800的后处理电路804。配置指令可以包括用于每个后处理电路804的每个流水线的后处理指令,并且定义要应用于来自卷积核心802的卷积结果的后处理。
后处理指令定义是启用还是禁用多通道ncc单元、响应整流器单元、通道间lrn单元或峰值查找器。在一些实施方案中,后处理电路804以由后处理指令指定的多种模式操作。在ncc模式下,启用多通道ncc单元,并禁用通道间lrn单元。在lrn模式下,禁用多通道ncc单元,并启用通道间lrn单元。在混合lrn/ncc模式下,启用多通道ncc单元和通道间lrn单元。在直通模式下,禁用多通道ncc单元和通道间lrn单元。后处理流水线中的禁用部件可以将其输入数据流传递到后处理流水线中的下一个部件而不处理该流。
图10是示出根据一个实施方案的卷积核心802的框图。如上所述,卷积核心802包括诸如卷积前端806、执行集群810和812以及卷积后端814之类的电路。
卷积前端806可以包括输入缓冲器1002、数据路径路由器1006、定序器1018和核统计单元1024。输入缓冲器1002在输入数据836被流传输到卷积前端806时存储该输入数据。输入数据836可以是值的流,具有采用交织方式的多个输入通道的数据。输入数据836可以是像素数据、hog数据、卷积电路800的前一周期的输出、另一卷积电路800的输出,或从设备100的其他部件接收的其他数据。
数据路径路由器1006是一种电路,其以扫描顺序读取输入缓冲器1002的预定位置中的一组数据1004,并将读取的数据1008发送至执行集群810或812以用于计算卷积值。数据路径路由器1006可以将输入数据836的不同部分发送到执行集群810和812,以利用卷积核并行处理。本文描述的扫描序列是指处理输入数据的子集的操作。数据路径路由器1006可以在卷积引擎414的处理周期内执行多个扫描序列的数据的读取和发送,以用像素值填充执行集群810和812。在一个实施方案中,数据路径路由器1006选择性地读取中心像素的像素值和与中心像素相邻的像素子集的像素值,同时根据稀疏值跳过其他相邻像素。此外,在扫描序列内要处理的中心像素可以被由步进值限定的多个像素分隔开。在随后的扫描中,可以处理由相同或不同数量的像素分隔开的一组新的中心像素。
核存储器808是存储核信息的电路。核信息包括卷积核中的过滤器元素的值、稀疏值、步进值、核尺寸等。核信息1022被发送到执行集群810,以填充执行集群810的乘法器电路fe0至fen中的寄存器。核信息1022还被发送到执行集群812,以填充执行集群812的乘法器电路fe0至fen中的寄存器。核存储器808可以存储多个卷积核,以用于执行与像素数据的不同通道的卷积和/或执行与像素数据的相同通道的卷积。
执行集群810和812是执行计算操作的可编程电路。为此,执行集群810和812可包括乘法器电路fe0至fen、压缩器1010和多周期累加器1014。乘法器电路fe0至fen中的每一个可将像素值存储在读取数据1008中,并将对应的滤波器元素值存储在核存储器808中。在乘法器电路中将像素值和对应的滤波器元素值相乘以生成相乘值1009。在一些实施方案中,压缩器1010接收相乘值1009并将相乘值1009的子集累加以生成压缩值1012。在其他实施方案中,代替累加相乘值1009的子集,压缩器1010可以从相乘值1009的每个子集中选择(i)最小值、(ii)最大值,或(iii)中值。多周期累加器1014接收压缩值1012,并对在卷积核802的多个处理周期上生成的压缩值1012执行累加(或选择最小值、最大值或中值)。
返回到卷积前端806,定序器1018控制卷积核心802的其他部件的操作以执行多个操作周期。定序器1018可以在执行集群810和812之间有效地分配处理任务。如上所述,执行集群810和812将一系列卷积核应用于输入数据的不同部分,以生成包括偶数索引输出通道的偶数数据值842的流和包括奇数索引输出通道的奇数数据值844的流。例如,核存储器808为存储在乘法器电路fe0至fen中的每组像素数据提供一系列卷积核的滤波器元素。每个卷积核生成偶数数据值842和奇数数据值844的不同输出通道。
在定序器1018的另一个示例性操作中,输入数据的大小和/或卷积核的数量或大小可能太大,以至于不能在执行集群的单个处理周期中执行所有计算。定序器1018在偶数和奇数输出通道之间划分计算操作,将偶数通道的处理任务分配给执行集群810,将奇数通道的处理任务分配给执行集群812。
在一些实施方案中,输入数据的大小和/或卷积核的数量或大小可能太大,以置于不能使用这两个执行核心在卷积核心802的单个处理周期中执行所有计算。在此类情况下,定序器1018将计算操作分成多个批次,并且在单个周期中基于输入数据的子集或卷积核的子集来执行计算。每个周期中的计算结果由多周期累加器1014处理以生成跨多个周期的输出值1013。为了将其他部件配置为执行多周期操作,定序器1018将多周期控制信号1019发送至其他部件。
卷积后端814包括输出缓冲器1024、大数据处理器1028和输出缓冲器1030,以及大数据处理器1032。输出缓冲器1024是将输出值1013存储在其指定位置的电路。在一个实施方案中,多个输出通道的一系列输出值在输出缓冲器1024中交织。在再次反馈执行集群810的输出值1015作为卷积前端806处的输入数据836的操作中,可以将输出缓冲器1024中的数据复制到输入缓冲器1002以用于卷积操作的下一个周期。输出缓冲器1024处理执行集群810的输出值1013,并且输出缓冲器1030处理执行集群812的输出值1013。
大数据处理器1032是对存储在输出缓冲器1024中的输出值进行进一步处理的电路。例如,卷积核802可以处理具有不同位大小(诸如8位或16位精度)的输入数据和卷积核。当输入数据或卷积核具有16位精度时,每个输出像素将使用两倍的时钟周期数。当输入数据和卷积核都具有16位精度时,将使用超过四倍的时钟周期。卷积后端814可以将来自多个时钟周期的8位像素数据卷积的结果合并为具有16位精度的数据。大数据处理器1032可以对输出缓冲区1024中存储的来自执行集群812的输出值执行类似的处理。偶数数据值842的流从大数据处理器1028输出,奇数数据值844的流从大数据处理器1032输出。在一些实施方案中,从卷积后端814中省略了大数据处理器1028和1032。偶数数据值842和奇数据值844的流分别从输出缓冲器1024和1030输出。较小的数据大小可支持对机器推理任务或其他可以使用较低精度数据的任务进行更快的处理。相比之下,较大的数据大小可用于机器培训或精度更高的任务。
卷积核心802中的部件(以及卷积引擎414的其他部件)可在配置期间通过从中央控制320接收配置信息来配置。在配置信息中指示的可配置参数和模式可以包括但不限于稀疏值、步进值、像素数据值和滤波器元素之间的映射、将在压缩器1010处执行的操作类型(例如,累加,最小值、最大值或中值)、输入数据或输出值的通道数以及要在后处理电路804执行的后处理操作的选择。
图10中的卷积核802的结构仅是例示性的。例如,可以省略多周期累加器1014,从而在卷积引擎上仅执行单周期操作。
图11a是示出根据一个实施方案的多平面格式卷积核心电路800的输入和输出的概念图。卷积核心电路800对多通道输入数据1102进行卷积,并生成多通道输出数据1110。输入通道和输出通道的数量可以不同。图11a中所示的多平面格式将每个输入通道和输出通道表示为单独的图像平面。多通道输入数据1102具有三个输入通道1104、1106和1108的像素值。每个输入通道1104、1106和1108可使用一个或多个核来处理。例如,将如图11a所示的四个卷积核即核0到卷积核3应用到通道1106产生包括四个输出通道1112、1114、1116和1118的多通道输出数据1110。如果对于每个通道都将相同的四个卷积核0到3(例如,使用稀疏核)应用于每个输入通道1104、1106和1108,则多通道输出将为每个处理的输入通道包括四个通道,所以总共有十二个输出通道。可使用不同的卷积核来生成每个不同的输出通道。卷积核的大小、稀疏值和步进值可以很灵活,以允许针对不同应用使用不同类型的卷积。
图11b是示出根据一个实施方案的平面化格式卷积核心电路800的输入和输出的概念图。多通道输入数据1102和多通道输出数据1110分别由n个交织的多个通道的流定义,其中每个通道的对应像素值(由图11b中的不同阴影图案的框标识)在流中彼此相邻,然后是下一个像素的每个通道的相应像素值,以此类推,采用如该平面化格式所示的光栅样式。该平面化格式包括来自被表示为交织通道的单个图像平面的多个交织通道的图像。
多通道输入数据1102由流定义,其中来自不同通道的相关像素值以平面化格式彼此相邻。例如,第一通道像素1124、第二通道像素1126和第三通道像素1128代表由多通道输入数据1102定义的输入图像的第一个(0,0)像素。多通道输入数据1102的下一个像素(0,1)的像素值跟随像素1124、1126和1128。下一个像素(0,1)包括第一通道像素1130、第二通道像素132和第三通道像素1134。第一行(0)中的后续像素可以相应地跟随(0,1)像素。后续行(1)的像素值可以跟随第一行的像素值。例如,第二行中的第一个像素(1,0)包括第一通道像素1136,其后是第二通道像素1138,然后是第三通道像素1140。
例如,多通道输入数据1102的输入通道包括rgb颜色通道。又如,多通道输入数据1102可以包括ycbcr颜色通道。又如,多通道输入数据1102可以包括利用卷积核导出的卷积结果的输出通道。
通过应用卷积核(诸如卷积核1150),从多通道输入数据1102导出多通道输出数据1110。多通道输出数据1100包括来自流中彼此相邻的不同输出通道的相关像素值的流,如该平面化格式所示。例如,输出通道像素1142、1144、1146和1148与输出数据1110的(0,0)像素相对应。如图11a所示,输出通道像素1142、1144、1146和1148分别属于输出通道1112、1114、1116和1118。因此,串行流可以以光栅样式定义输出数据1110的交织通道。
当卷积引擎414以级联模式操作时,卷积核心电路800使用另一个卷积核心电路800的输出作为输入,如上面结合图6b所讨论的。卷积核心电路800的多通道输入数据1102和多通道输出数据1110具有共同的交织格式以促进多种操作模式,包括使用卷积核心电路800的输出数据作为另一个卷积核心电路800的输入数据的模式。
每通道空间合并和归一化
图12是示出根据一个实施方案的空间合并电路1200的框图。空间合并电路1200对具有多个交织通道的流执行每通道空间合并或归一化操作,并且还生成多个交织通道的输出流。如上结合图5所述,卷积电路502和504分别包括空间合并电路514和空间合并电路524,以处理相应卷积核心电路512和522的输出流。空间合并电路1200是第一卷积电路502的空间合并电路512或第二卷积电路504的空间合并电路524的一个实施方案。根据来自中央控制320的指令,空间合并电路1200在一些或所有输入交织通道上执行每通道空间合并和/或每通道局部响应归一化。
空间合并电路1200包括输入缓冲器1202、每像素计算块1204、列压缩器1206、列累加缓冲器1208、行压缩器1210、延迟器1222,以及空间合并和归一化(spn)处理器1212。spn处理器1212包括平方根单元1214、局部响应归一化单元(lrn)1216、复用器1218和spn后处理器1220。
输入缓冲器1202从卷积核心电路512接收值1232的流并存储输入数据。输入数据包括以交织方式定义多个通道的数据值的流,并且这些数据值在被接收在流中时被存储在输入缓冲器1202中。输入缓冲器1202存储相同通道的多个像素值以促进每通道处理。为了生成空间合并像素,输入缓冲器1202的大小被设定成存储至少足够适合局部窗口的输入像素值。在其中来自多个交织通道的像素值表示为单个图像平面的平面化格式中,局部窗口具有仅针对单个通道选择像素值的稀疏性。局部窗口的尺寸(例如,高度或宽度),其定义了要在空间上合并的同一通道的像素值的数量,可以是可配置的,诸如可由来自中央控制320的指令配置。局部窗口的水平步幅定义了局部窗口的中心像素之间的像素间距,也可以是可配置的,例如可由来自中央控制320的指令配置。因为输入缓冲器1202接收交织通道的流,其中通道的像素值被一个或多个其他通道的像素值分开,所以输入缓冲器1202存储多个通道中的每一个的多个像素值。
局部窗口可以包括单个通道的多个像素值,以在空间上合并为空间合并的像素值。对于每个空间合并的像素,空间合并电路1200执行列合并以合并来自局部窗口的一列的像素值,然后执行行合并以合并该局部窗口的列合并的值。需注意,“行”和“列”是指平面化图像的垂直像素线,并且不一定是特定的水平或垂直方向。
对于每个空间合并的像素,每像素计算1204从输入缓冲器1202检索局部窗口的通道的数据值,并对这些数据值执行操作。所述操作可以包括对数据值施加偏移,对数据值求平方或确定数据值的绝对值。
列压缩器1206将来自与局部窗口的一列相关联的每像素计算1204的多个数据值组合成表示该列的单个空间合并值。列压缩器1206可以采用各种方式组合多个数据值,如可以由中央控制320指定的。例如,列压缩器1206可以选择最小值、最大值,或者可以将这些值组合为和。
列累加缓冲器1208从列压缩器1204接收多个空间合并的列值,并且存储空间合并的列像素值。例如,列累加缓冲器1208至少存储局部窗口的每一列的空间合并的列值。
行压缩器1210将局部窗口的每一列的空间合并列值组合。类似于列压缩器1206,行压缩器1210可以采用各种方式组合多个数据值,如由中央控制320指定的。例如,行压缩器1210可以选择最小值、最大值,或者可以将这些值组合为和。行压缩器1210的输出表示从局部窗口的每个像素导出的空间合并值。
spn处理器1202处理从行压缩器1210接收的空间合并的值。例如,spn处理器1202可确定空间合并的值的平方根。spn处理器1202可另选地或除此之外使用空间合并的值来对输入流1222执行局部响应归一化。
spn处理器1202包括平方根单元1214、lrn单元1216、复用器1218和spn后处理器1220。平方根单元1214计算来自行压缩器1210的空间合并值的平方根。
lrn单元1216通过将来自行压缩器的空间合并值应用于存储在延迟器1222中的输入值以生成每通道归一化值来执行局部响应归一化。延迟器1222通过使空间合并值与来自输入缓冲器1202的对应输入值同步来促进局部响应归一化。延迟器1222耦接到输入缓冲器1202和lrn单元1216。延迟器1222可以包括先进先出(fifo)存储器缓冲器。
复用器1218从行压缩器1210的空间合并的值中选择输出,从平方根单元1214选择空间合并值的平方根,或者从lrn单元1216选择归一化值。spn后处理器1220接收复用器1218的所选输出,并且执行缩放、偏移和/或移位操作。spn后处理器1220的输出是以交织方式定义多个通道的像素值的流,其中像素值通过每通道空间合并和/或每通道归一化进行处理。
在一些实施方案中,中央控制320通过配置部件的操作组合以不同的模式来操作空间合并电路1200。
如上文结合图5所述,第一卷积电路502的空间合并电路514的输出流530可以用作第二卷积电路504的输入,或者可以被提供给通道合并电路506以与第二卷积电路504的输出交织。
图13a和图13b是示出根据一个实施方案的多平面格式空间合并电路1200的输入和输出的概念图。空间合并电路1300对多通道输入图像执行每通道空间合并和/或每通道lrn,并生成多通道输出。保留输入通道和输出通道的数量,其中每个图像的像素图像大小经由空间合并而减小。
图13a和图13b的多平面格式将每个输入通道和输出通道表示为单独的图像平面。多通道输入数据1302具有来自多个通道诸如通道1304、1306和1308的像素值。在该示例中,在空间上合并具有三个像素的宽度和高度的本地窗口1310的像素值,以生成用于输出通道1304的空间合并值1312。空间合并电路1200使用针对每个通道的本地窗口1310在单独的基础上为通道1304、1306和1308生成多通道输出数据1314。
在如图13a所示计算出多个通道的第一空间合并值(例如,值1312)之后,如图13b所示将本地窗口1310移位以计算这些通道的下一个空间合并值(例如,值1322)。在该示例中,本地窗口1310根据光栅样式在列维度上移位了两个像素。这导致本地窗口1310的中心像素在列维度上移位了两个像素。每空间合并像素计算的本地窗口1310的中心像素移位量可以是可配置的。本地窗口可根据每个空间合并像素的预定义的行(“步幅x”)和列(“步幅y”)参数以光栅样式移位,直到计算出所有的空间合并像素。使用大于1的步幅x和步幅y参数会导致进行子采样以减少数据大小和计算成本。当这些因子等于1时,不跳过输出像素。在空间上合并移位的本地窗口1310的像素值以生成输出通道1316的空间合并值1322。
图13c和图13d是示出根据一个实施方案的平面化格式空间合并电路1300的输入和输出的概念图。图13c对应于图13a中所示的多平面格式,图13d对应于图13b中所示的多平面格式。在平面化格式中,将每个输入通道表示为以cin的水平间隔放置的像素列,其中cin表示输入通道的数量。因此,当将每通道操作应用于本地窗口时,核支持在平面化格式中变得稀疏,如本地窗口1310所示。
在多平面格式中,以通道的空间坐标中的像素为单位定义行(“步幅x”)和列(“步幅y”)移位值。在平面格式中,通过将行移位值步幅x乘以输入通道cin的数量来确定实际的行移位量。
图14是示出根据一个实施方案的操作空间合并电路1200的方法1400的流程图。中央控制320将配置信息发送1402到空间合并电路1200。可结合用于卷积引擎414的其他配置指令来发送配置指令,如方法700的702处所讨论的。
配置指令可包括限定空间合并电路1200的操作模式的指令。不同的操作模式可限定不同类型的空间合并或每通道lrn。在最大合并模式中,列压缩器1206和行压缩器1210选择最大值,并且复用器1218选择行压缩器1210的输出。此处,绕过spn处理器1212的后累积处理,使得空间合并电路1200的输出不具有局部响应归一化或平方根应用。在平均合并模式中,列压缩器1206和行压缩器1210生成总和,并且复用器1218选择行压缩器1210的输出以绕过后累积处理。
在l1合并模式中,每像素计算1204确定绝对值,列压缩器1206和行压缩器1210计算绝对值的和,并且复用器1218选择行压缩器1210的输出以绕过后累积处理。在l2合并模式中,每像素计算1204确定平方值,列压缩器1206和行压缩器1210计算平方值的和,平方根单元1214确定平方值的和的平方根,并且复用器1218选择平方根单元1214的输出。
在每通道lrn模式中,每像素计算1204确定平方值,列压缩器1206和行压缩器1210计算平方值的和,lrn单元1216使用平方值的和的平方根来归一化值,并且复用器1218选择lrn单元1216的输出。
在接收到配置信息之后,根据配置信息更新1404空间合并电路1200的配置以执行配置信息中所述的操作。更新配置可包括根据由配置信息限定的操作模式来设置每像素计算1204、列压缩器1206和行压缩器1210、平方根单元1214和复用器1218的操作。
卷积核心电路512(或522)通过对输入数据执行卷积操作,以交织方式生成1406多个通道的值的流。例如,卷积核心电路512使用多个卷积核对输入数据执行卷积运算,以根据配置指令生成包括多个通道的值的流。卷积电路512可进一步对由配置指令指定的卷积结果执行一个或多个后处理操作。在一些实施方案中,后处理操作包括通道间操作诸如多通道ncc和通道间lrn。这些操作组合来自不同通道的值,并且不同于空间合并电路1200的每通道操作。如果卷积核心电路512包括多个执行集群,则可组合多个执行集群的输出流以通过卷积核心电路512输出的交织方式生成多个通道的值的流。
空间合并电路1200通过将来自每个通道的值的子集相互合并来生成1408空间合并值。例如,如果来自卷积核心电路512的流包括第一交织通道和第二交织通道,则空间合并电路1200通过合并第一通道的值的子集(例如,如局部窗口所定义的)来生成第一空间合并值,并且通过合并第二通道的值的子集来生成第二空间合并值。输入缓冲器1202确保来自流1224的单个通道的值的子集被存储以促进空间合并。基于每像素计算1204、列压缩器1206、行压缩器1210和spn处理器1212的选定操作,可以各种方式合并来自每个通道的值的子集。空间合并值可包括来源于不同类型的空间合并的值,诸如最大合并模式、平均合并模式、l1合并模式或l2合并模式。又如,空间合并值可包括来源于归一化诸如每通道lrn模式的值。
空间合并电路1200将来自多个通道的空间合并值交织1410在输出流1226中。空间合并电路1200因此在输出流1226处保持作为输入流1224接收的多通道交织格式,同时对输入流1224执行每通道深度机器学习操作。
空间合并电路1200可从卷积核心电路512(或504)接收2ppc输入流,并生成2ppc输出流。如果卷积核心电路512提供1ppc流,则空间合并电路1200忽略无效值并且仅处理有效值。如果输出帧的总宽度为奇数,则可在每行的末尾添加一个零,以使宽度均匀。
如图14所示的过程仅是例示性的,并且可对该过程作出各种改变。例如,在旁路模式下,空间合并电路1200可对输入流进行重新分组,以确保包含有效值的2ppc输出流。像素处理部件诸如每像素计算1204以及列压缩器1206和行压缩器1210可在旁路模式中被绕过。
交织式通道合并
当应用程序需要高吞吐量时或当使用大型深度学习模型时,两个卷积电路502和504可在双卷积模式中并行运行,如上文结合图6a所讨论的。两个卷积电路502和504对同一输入流应用不同的卷积核。例如,第一卷积电路502生成具有一个或多个卷积核的输出通道的前半部分,而第二卷积电路504生成具有一个或多个不同卷积核的后半部分。通道合并电路506从卷积电路502和504接收流,并且以交织方式将这些流组合成包括输出通道的前半部分和输出通道的后半部分的单个输出流。为了执行交织,通道合并电路具有通道合并器526。
图15是示出根据一个实施方案的通道合并器1500的框图。通道合并器1500是通道合并电路506的通道合并器526的实施方案。当以双卷积模式操作时,通道合并器1500的输出被选择为卷积引擎414的输出。
通道合并器1500包括输入缓冲器1502、复用器1504和通道选择器1506。输入缓冲器1502耦接至用于接收值530的流的卷积电路502和用于接收值532的流的卷积电路504。值530和532的流可各自包括多个交织通道。输入缓冲器1502存储值530和532以促进用于交织的值的同步。
复用器1504耦接至输入缓冲器,并从输入缓冲器1502接收值530和532的流。通道选择器1506向复用器1504提供选择信号,以控制从输入流中选择值,用于插入输出值534的输出流中。复用器交织值530和532的流,诸如通过另选地从每个输入流选择一个或多个值,以生成输出值534的输出流。选自特定输入流的顺序值的数量可由流中每个像素的通道数来限定。输出值534的序列以交织方式限定值530和532的流的通道。
通道合并器1500支持同步的两个2ppc输入流,而不会减慢任何输入流。合并输出的吞吐量为4ppc。如果两个输入流不同步,则可使用输入缓冲器1502来存储一个或多个输入源以提供延迟,使得通道合并器1500从两个输入流接收同步的输入。
图16是示出根据一个实施方案的平面化格式通道合并器1500的输入和输出的概念图。在一些实施方案中,通道合并器1500组合具有相同尺寸的两个输入帧,如多通道输入数据1602和多通道输入数据1604所示。此外,输入流530和532具有相同数量的输入通道cin。在该示例中,cin为5,因此每个像素p0、p1、p2等对于每个流具有五个通道的值。通道合并器1500通过交织多通道输入数据1602和多通道输入数据1604来生成多通道输出数据1606,使得第一流的p0像素的每个通道的像素值之后是第二流的p0像素的每个通道的像素值。以平面化格式的光栅方式进行,第一流的p1像素的每个通道的像素值跟随第二流的p0像素的像素值。对于p1像素,第一流的p1像素的每个通道的像素值后面是第二流的p1像素的每个通道的像素值。
通道合并器1500从每个输入流530(包括多通道输入数据1602)和532(包括多通道输入数据1604)中生成具有两倍于输入通道数量的通道数量的输出值534的输出流。例如,多通道输出数据的每个像素p0、p1等具有10通道输出cout。
在一些实施方案中,当输入流530和532中的图像的高度和宽度不匹配时,或者当输入流530和532中的通道数量不匹配时,通道合并器1500在通道合并电路506中被禁用。卷积引擎414可在绕过通道合并器1500的不同模式下操作,诸如图6b所示的级联模式或图6c所示的并行模式,而不是在双卷积模式下操作。
在一些实施方案中,通道合并器1500是核心合并器846的实施方案。核心合并器847从每个执行集群810和812接收两个1ppc输入流(在单独管线中进行后处理之后),并将这些1ppc输入流组合到卷积核心电路800的2ppc输出流中。相比之下,通道合并器526接收2ppc输入流并生成4ppc输出流。因此,通道合并器526具有比核心合并器847更高的吞吐量。核心合并器847可包括:复用器,其从偶数流842和奇数流844中选择数据值以生成输出流;以及通道选择器,其控制由复用器进行的值的选择。在一些实施方案中,核心合并器846可包括一个或多个输入缓冲器,以通过存储偶数流842和奇数流844中的一者或多者来促进交织的同步。由于较低的吞吐量,核心合并器846的存储器和处理部件的尺寸可小于通道合并器1500的存储器和处理部件的尺寸。
- 还没有人留言评论。精彩留言会获得点赞!