一种基于时空轨迹快速碰撞的算法的制作方法
本发明涉及算法领域,尤其涉及一种基于时空轨迹快速碰撞的算法。
背景技术:
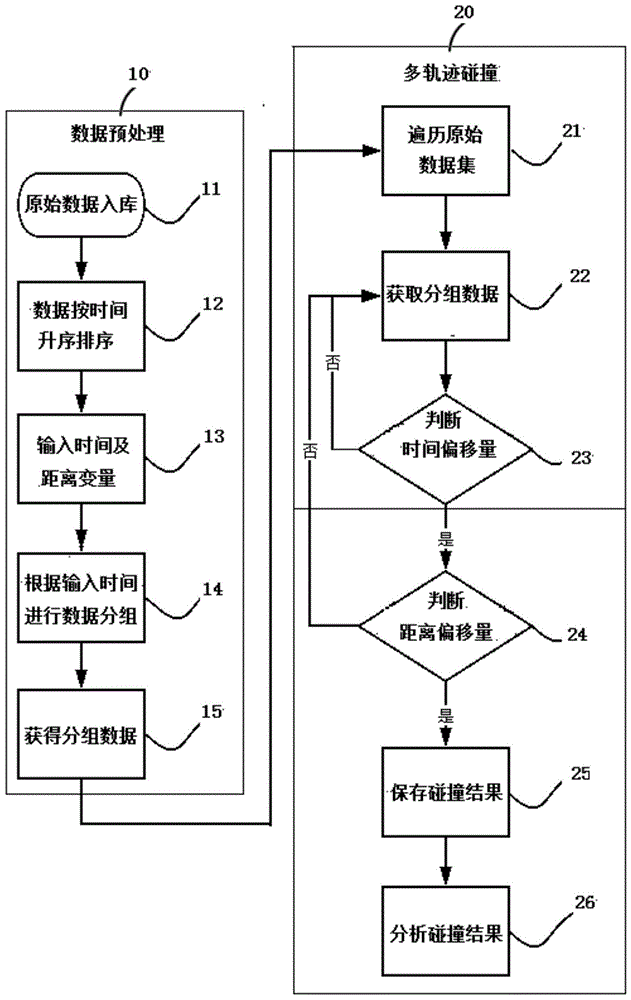
:随着信息化的普及,人们的活动信息都被电子数据记录,通过分析轨迹活动数据可以分析出特定人员的时空活动轨迹,在各大刑事案件中,通过信息化手段来获取线索的案例越来越多,逐渐成为一条重要的线索来源。传统的算法对[s0,s1,s2...sn]数据集合按人物分成m个集合,并依次遍历m个集合获取不同的数据组合,当m为1时候,时间复杂度为o(n);当m为n的时候,时间复杂度为o(n!)。通过全量数据循环遍历比对,来推断一个案件中多个人是否有接触或碰面,以及统计接触或碰面的次数来推断案件中多人的关系。在现今可获取的原始数据量大幅增长,犯罪案件涉及人数越来越多,关系越来越复杂的背景下,传统分析方法的运算量显著增长,分析效率低下,无法满足大数据量、多人物应用场景下的数据分析要求。技术实现要素:本发明的目的就在于解决现有算法在数据量大、人物多的情况下效率低下的问题,提供一种基于时空轨迹快速碰撞的算法,将运算复杂度保持在0(n),有效提升时空轨迹碰撞的运算效率,减少运算时间,提升用户体验。本发明目的目的是这样实现的,具体地说,本方法包括下列步骤:①数据预处理;a、原始数据入库多轨迹碰撞分析开始;b、数据按时间升序排序原始数据按时间升序排序,获得数据集合so(sorigin);c、输入时间及距离变量输入多轨迹碰撞条件时间范围δt和距离范围δd;d、根据输入时间进行数据分组根据δt将数据集合so进一步分组;e、获得分组数据获得分组后的数据集合sg(sgroup),使每一组数据里的第一条记录sfirst与最后一条记录slast的时间差小于等于δt,即每组数据内的所有记录都满足条件δt;②多轨迹碰撞a、遍历原始数据集遍历数据集合so,获得记录s1;b、获取分组数据从sg获得s1所在时间范围的分组sg1,以及该分组的下一分组sg2;c、判断时间偏移量比较s1与sg1、sg2里的记录,判断时间间隔是否小于δt,是则执行步骤d,否则跳转到步骤b;d、判断距离偏移量根据s1和被比较记录的经纬度,获得两条记录的地点之间的距离,判断距离是否小于δd,是则执行步骤e,否则跳转到步骤b;e、保存碰撞结果将碰撞结果保存到以s1的id为key,list集合为值的map中,后续s1的其他碰撞结果同样保存到该list集合中;遍历完成后,即可获得以记录id为key,该记录的碰撞结果list为值的map;f、分析碰撞结果提取每一个list中的所有人物的身份证号,去重复后获得人物身份证号码组合key,将相同组合key的数据组放到同一个list。本发明具有下列优点和积极效果:①独创性支持大数据量的时空轨迹碰撞保持在一定的运算复杂度,减少运算时间,提升用户体验;②算法具有可扩展性。附图说明:图1是本方法的流程图。其中:10—数据预处理;11—原始数据入库;12—数据按时间升序排序;13—输入时间及距离变量;14—根据输入时间进行数据分组;15—获得分组数据;20—多轨迹碰撞;21—遍历原始数据集;22—获取分组数据;23—判断时间偏移量;24—判断距离偏移量;25—保存碰撞结果;26—分析碰撞结果。图2是本系统的最终结果数据结构图;图3是碰撞结果map的数据结构图;其中key为人物身份证组合字符串,value为包含多组碰撞结果的数据集合。英译汉1、map:键值对容器;2、key:键;3、value:值4、list:数据集合;4、starttime:开始时间;6、endtime:结束时间。具体实施方式下面结合附图和实际案例对进一步的说明。一、算法如图1,本算法是:①数据预处理-10,a、原始数据入库-11;b、数据按时间升序排序-12;c、输入时间及距离变量-13;d、根据输入时间进行数据分组-14;e、获得分组数据-15;②多轨迹碰撞-20,a、遍历原始数据集-211;b、获取分组数据-22;c、判断时间偏移量-23;d、判断距离偏移量-24;e、保存碰撞结果-25;f、分析碰撞结果-26。二、实施例应用场景对一段时间[starttime,endtime]内的轨迹数据进行碰撞分析,寻找出在一定时间误差范围δt分钟内,一定距离范围δd公里以内的轨迹重合次数,寻找出共同团伙。(案例中δt设为60min,δd设为1km。)①数据加载,对一段时间范围内数据进行抽取,将原始数据按照时间升序排序,形成[s0,s1,s2…sn]数据列表集合s。(代表排序后的原始数据sorigin)-12。表1:原始数据sorigin记录序号记录人时间其他信息s0a2018-01-0108:00其他s1b2018-01-0108:30其他s2a2018-02-0109:30其他s3c2018-02-0109:50其他s4b2018-03-0108:00其他s5c2018-03-0108:10其他s6c2018-03-0108:40其他s7b2018-03-0109:10其他s8a2018-03-0109:20其他s9c2018-03-0109:50其他②输入δt,δd-13,将[s0,s1,s2…sn]集合按照时间范围分组,获得{[s0,s1..sm],[sm+1,sm+2..sm+k]...}的数据组sg(代表按时间分组后的数据sgroup),每一个数据组里的所有数据两两之间的时间差小于等于δt,如s1-s0的时间差<=△t,如下表-14。表2:分组数据sgroup③遍历集合so的数据,每一条记录可能出现的碰撞记录一定处于它所在的时间分组或下一时间分组两组数据内(如果被比较数据处于分组内的时间靠后位置,则有可能在下一分组存在碰撞结果,如表2中的数据s1和数据s2,因此每条记录需要与所在组及下一组数据进行比较),仅需与这两个数据组内的数据进行比较时间和距离比较-22。④从so中获取数据s1,从sg中获得s1所在的书简组数据sg1和下一书简组数据sg2,比较s1与集合sg1、sg2中数据,获取时间差值t,若t<=△t,则继续进行距离比对(步骤⑤,否则终止该次比对,返回步骤③-23。⑤获取比较中的两条记录的经纬度数据,采用haversine公式根据经纬度获取两点之间的距离d,比较d与距离范围△d,若d<=△d,则获取一条碰撞记录。haversine公式如下-24:r为地球半径,可取平均值6371km;表示两点的纬度;δλ表示两点经度的差值。⑥创建结果集map用于保存碰撞结果,将碰撞记录保存到以s1的id为key,list为值的map中,后续s1再获得其他碰撞结果时,也将保存到该list中-25。⑦s1与sg1、sg2里的所有数据比较完后,将s1及其碰撞结果从so中移除,避免重复数据,回到步骤③,取下一条记录,及需要碰撞的两个数据组,重复以上步骤。⑧全部记录碰撞完后,获得的结果map数据结构如图3。⑨继续分析结果map,从value中提取所有人物的身份证号码,去重复后生成身份证号码组合idnums,将相同idnums的数据集放到以idnums为key,list为值的集合中,数据结构如图2。案例碰撞结果见表3。表3:案例碰撞结果综上所述,本发明首先将原始数据预处理,按照输入的时间误差范围δt将数据分组,再遍历原始数据,对每一条待分析数据,仅与数据所在组的数据以及下一分组数据做比较,摒弃传统的全量遍历分析方法,改为划时段分析方法,大幅减少运算量,在大数据量,多人物场景下,仍能以较高性能快速分析,获取人物之间的碰面或接触次数、接触地点信息。三、应用本专利算法应用于公安办案系统,通过分析采集的案件相关人员数据,分析人员之间的接触关系,为案件提供线索支持。应用步骤如下:①采集案件相关人员的出行、住宿和话单等数据,录入系统原始数据库;②获取数据的发生地和发生时间,通过本算法快速进行多人轨迹数据碰撞分析,获取案件相关人员之间的接触次数、接触时间和接触地点。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1