基于情感词典和词概率分布的情感会话生成方法与流程
本发明涉及数据挖掘技术领域,具体而言涉及一种基于情感词典和词概率分布的情感会话生成方法。
背景技术:
由于智能手机的普及、宽带无线技术的发展,现在我们处于社交媒体时代,更多的人以数据方式互相联结,机器会话生成发展成一种社交方式就很自然了。早先的交互系统,如eliza(weizenbaum,1966)、parry(colby,1975)和alice(wallace,2009)都是以模仿人类行为为方向设计的文本会话生成,在控制范围内通过了图灵测试(turing,1950;shieber,1994)。尽管取得了令人印象深刻的成功,这些当前会话生成的前身主要还是基于手工定制的规则运行的。所以,它们只能在有限的环境中有良好的性能。
现如今,会话生成与用于闲聊的早期聊天机器人不同,它们的目的是满足用户的交流、情感和社交归属感需求(maslow,1943),而不是为了通过图灵测试。人工智能(ai)的一项基本挑战就是赋予机器使用自然语言与人交流的能力。会话系统的主要目标不一定是解决用户可能会有的所有问题,而是成为用户的虚拟伙伴,通过与用户建立情感联系,会话系统可以更好地理解用户,并在长期时间范围内帮助他们。因此,会话系统必须能够识别情绪、跟踪对话中的情绪变化。
在会话系统中引入情感存在两个主要的开放性问题:
第一个问题是因为情感注释是一个相对主观的任务,而且情感分类也很具有挑战性。在大型语料库中,高质量的情感标签很难获得。
第二个问题是因为需要平衡生成句子的语法通顺性和情感表达,所以很难以一种自然而连贯的方式去考虑情感。在现有的神经模型中简单的嵌入情感只会产生令人难以理解的表达,很难产生令人满意的回答。
技术实现要素:
本发明目的在于提供一种基于情感词典和词概率分布的情感会话生成方法,通过将传统的词嵌入与外部情感词典相结合,实现情感词嵌入来捕捉输入句子中的情感,利用情感词嵌入,结合编码器-解码器框架,对情感词和普通词分配不同的概率来模拟情感的表达,再根据不同的词概率分布进行采样来生成下一个单词;另外,本发明还提出通过情感损失函数对模型进行训练,以使生成句子与输入句子情感更为贴合;本发明提出在生成句子时考虑情感的方法,平衡了生成句子时的语法通顺性和情感表达,提高了会话生成的效率和满意度。
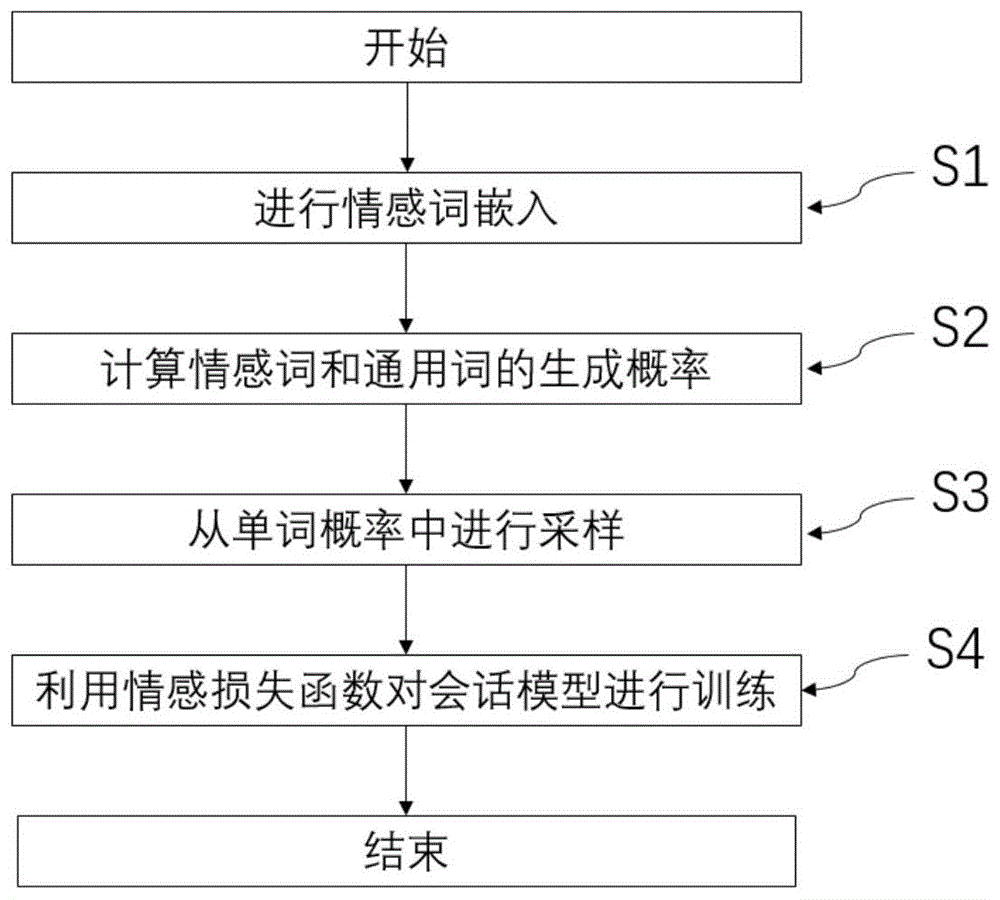
为达成上述目的,结合图1,本发明提出一种基于情感词典和词概率分布的情感会话生成方法,所述方法包括:
s1:对生成句子中的单词进行情感词嵌入,包括利用具有3d情感空间的外部词典将所述单词转化为情感向量,再将转换生成的情感向量与传统词嵌入相结合以完成情感词嵌入;
s2:将从步骤s1中得到的情感词嵌入输入到编码器-解码器框架中,利用解码器的状态计算所述生成句子中下一个单词分别对应于情感词和通用词的生成概率;
s3:针对情感词和通用词的生成概率设置对应的权重,根据预设的规则将步骤s2中得到的情感词和通用词的生成概率进行连接,建立会话模型p(yt),得到生成句子中的下一个单词;
s4:计算输入句子和生成句子中已生成部分的情感相似度,采用情感损失函数对步骤s3中得到的会话模型p(yt)进行训练,以使生成的句子与输入句子的情感偏差小于设定偏差阈值。
进一步的实施例中,步骤s1中,对生成句子中的单词进行情感词嵌入,利用具有3d情感空间的外部词典将所述单词转化为情感向量,再将转换生成的情感向量与传统词嵌入相结合以完成情感词嵌入的方法包括以下步骤:
s101:创建一包含有若干个情感词汇的外部词典,所述外部词典中的每个情感词汇被映射到一个三维实值的向量vad中,分别为喜悦度v、强度a和支配度d;
s102:根据下述公式对生成句子中的单词进行情感投射:
其中,w2av表示单词向情感向量的投射;l(w)表示单词w的词形还原;
s103:将每个单词的w2av嵌入与传统的词嵌入相连接以形成所有单词的情感词嵌入。
进一步的实施例中,所述外部词典包含有13915个情感词汇。
进一步的实施例中,所述喜悦度v的范围为v≌1,5,9,分别对应于悲伤、无情感和喜悦;
所述强度a的范围为a≌1,5,9,分别对应于低情感强度、中等情感强度和高情感强度;
所述支配度d的范围为d≌1,5,9,分别对应于情感负支配度、情感无支配度以及情感正支配度;
所述中性向量
进一步的实施例中,步骤s2中,将从步骤s1中得到的情感词嵌入输入到编码器-解码器框架中,利用解码器的状态计算所述生成句子中下一个单词分别对应于情感词和通用词的生成概率的方法包括以下步骤:
s201:将情感词嵌入输入到编码器-解码器框架中,计算出解码器状态st;
s202:将通用词汇表和解码器状态st相结合以计算通用词的生成概率,将情感词汇表和解码器状态st相结合以计算情感词的生成概率,其中,通用词汇表和情感词汇表无交集。
进一步的实施例中,步骤s202中,根据下述公式以计算通用词和情感词的生成概率:
其中,wg和we分别表示通用词和情感词;pg和pe分别表示通用词和情感词的生成概率;st表示解码器的状态;
进一步的实施例中,所述编码器和解码器均采用gru。
进一步的实施例中,步骤s3中,针对情感词和通用词的生成概率设置对应的权重,根据预设的规则将步骤s2中得到的情感词和通用词的生成概率进行连接,建立会话模型p(yt),得到生成句子中的下一个单词的方法包括以下步骤:
s301:利用类型选择器αt用于控制情感词和通用词的生成权重,根据下述公式将两者的权重概率相连接:
αt=sigmoid(vutst)
其中,αt∈[0,1]是用于平衡情感词we和通用词wg选择的一个标量;vu为权重参数;st表示解码器的状态;
s302:根据下述公式从连接的权重中采样得到下一个单词:
其中,wg和we分别表示通用词和情感词;pg和pe分别表示通用词和情感词的生成概率;p(yt)是情感词和通用词权重概率的连接,是最终的词解码分布;ot为输出的概率分布,从中采样得到下一个单词yt。
进一步的实施例中,步骤s4中,计算输入句子和生成句子中已生成部分的情感相似度,采用情感损失函数对步骤s3中得到的会话模型p(yt)进行训练,以使生成的句子与输入句子的情感偏差小于设定偏差阈值的方法包括以下步骤:
s401:最小化生成句子与输入句子的情感噪音来仿真人与人之间的交流;
s402:利用情感损失函数对会话模型p(yt)进行训练,以使生成的句子与输入句子的情感偏差小于设定偏差阈值。
进一步的实施例中,所述情感损失函数为:
其中,第一项为标准的交叉熵损失函数,x表示输入的句子,yt表示生成的第t个单词;‖·‖2表示欧几里得距离;|x|表示输入句子的长度,
以上本发明的技术方案,与现有相比,其显著的有益效果在于:
1)本发明引入了具有3d空间的情感词典,并使之与传统的词嵌入相结合,在不影响词义的情况下加入高质量的情感词典,使情感自然地嵌入到会话模型中。
2)为了平衡句子的语法和情感,生成明确的情感表达,本发明计算了情感词和通用词的生成概率,再利用类型选择器来平衡他们之间的权重。
3)本发明提出采用情感损失函数对会话模型进行训练,以使生成句子与输入句子情感更为贴合。
4)本发明提出在生成句子时考虑情感的方法,平衡了生成句子时的语法通顺性和情感表达,提高了会话生成的效率和满意度。
应当理解,前述构思以及在下面更加详细地描述的额外构思的所有组合只要在这样的构思不相互矛盾的情况下都可以被视为本公开的发明主题的一部分。另外,所要求保护的主题的所有组合都被视为本公开的发明主题的一部分。
结合附图从下面的描述中可以更加全面地理解本发明教导的前述和其他方面、实施例和特征。本发明的其他附加方面例如示例性实施方式的特征和/或有益效果将在下面的描述中显见,或通过根据本发明教导的具体实施方式的实践中得知。
附图说明
附图不意在按比例绘制。在附图中,在各个图中示出的每个相同或近似相同的组成部分可以用相同的标号表示。为了清晰起见,在每个图中,并非每个组成部分均被标记。现在,将通过例子并参考附图来描述本发明的各个方面的实施例,其中:
图1是本发明的基于情感词典和词概率分布的情感会话生成方法的流程图。
图2是本发明的不同词汇概率分布的结构示意图。
具体实施方式
为了更了解本发明的技术内容,特举具体实施例并配合所附图式说明如下。
结合图1,本发明提出一种基于情感词典和词概率分布的情感会话生成方法,所述方法包括:
s1:对生成句子中的单词进行情感词嵌入,包括利用具有3d情感空间的外部词典将所述单词转化为情感向量,再将转换生成的情感向量与传统词嵌入相结合以完成情感词嵌入。
s2:将从步骤s1中得到的情感词嵌入输入到编码器-解码器框架中,利用解码器的状态计算所述生成句子中下一个单词分别对应于情感词和通用词的生成概率。
s3:针对情感词和通用词的生成概率设置对应的权重,根据预设的规则将步骤s2中得到的情感词和通用词的生成概率进行连接,建立会话模型p(yt),得到生成句子中的下一个单词。
s4:计算输入句子和生成句子中已生成部分的情感相似度,采用情感损失函数对步骤s3中得到的会话模型p(yt)进行训练,以使生成的句子与输入句子的情感偏差小于设定偏差阈值。
本发明引入了具有3d空间的情感词典,使之与传统的词嵌入相结合,在不影响词义的情况下加入高质量的情感词典,使情感自然地嵌入到会话模型中,继而对情感词和通用词分配不同的概率来显式的表达情感,避免了通用句子和情感模糊句子的生成,最后采用情感损失函数针对性的对情感模型进行训练,使生成的句子在情感上更加贴合。
本发明通过前述方法在会话系统中自然地引入情感,使生成句子的情感更加丰富,提高了会话生成系统的效率和满意度。
下面结合具体的例子对本发明提出的基于情感词典和词概率分布的情感会话生成方法的步骤进行详细阐述。
第一步,对生成句子中的单词进行情感词嵌入
步骤s1中,对生成句子中的单词进行情感词嵌入,利用具有3d情感空间的外部词典将所述单词转化为情感向量,再将转换生成的情感向量与传统词嵌入相结合以完成情感词嵌入的方法包括以下步骤:
s101:创建一包含有若干个情感词汇的外部词典,所述外部词典中的每个情感词汇被映射到一个三维实值的向量vad中,分别为喜悦度v、强度a和支配度d。
此处的外部词典可以根据具体的使用需求自行创建,也可以直接采用现有的情感词典,还可以根据需要将现有词典中的一部分提取出来另行创建,创建或者选用的情感词典对语言没有限制,优选的,情感词典包括使用所需的所有语言种类。
优选的,使用一外部词典,所述外部词典包含有13915个情感词汇,情感词汇包括高兴(happy)、生气的(angry)、可爱的(lovely)、伤心(sad)、无聊(bored)等等可以表达情感的词汇。
s102:根据下述公式对生成句子中的单词进行情感投射:
其中,w2av表示单词向情感向量的投射;l(w)表示单词w的词形还原;
在一些例子中,所述喜悦度v的范围为v≌1,5,9,分别对应于悲伤、无情感和喜悦。
所述强度a的范围为a≌1,5,9,分别对应于低情感强度、中等情感强度和高情感强度。
所述支配度d的范围为d≌1,5,9,分别对应于情感负支配度、情感无支配度以及情感正支配度。
所述中性向量
以前述情感词汇为例,happy的情感向量为[8.47,6.05,7.21],sad的情感向量为[2.1,3.49,3.84],而类似for这类不属于所述外部词典内的词汇的情感向量统一定义成中性向量
s103:将每个单词的w2av嵌入与传统的词嵌入相连接以形成所有单词的情感词嵌入,从而将生成句子中的单词均映射到高维的向量中来代表所述单词。
优选的,采用同样的方法对输入句子的单词进行情感词嵌入,以判断并且计算输入句子所包含的情感。
第二步,计算所述生成句子中下一个单词分别对应于情感词和通用词的生成概率
结合图2,步骤s2中,将从步骤s1中得到的情感词嵌入输入到编码器-解码器框架中,利用解码器的状态计算所述生成句子中下一个单词分别对应于情感词和通用词的生成概率的方法包括以下步骤:
s201:将情感词嵌入输入到编码器-解码器框架中,计算出解码器状态st。优选的,所述编码器和解码器均采用gru。
s202:将通用词汇表和解码器状态st相结合以计算通用词的生成概率,将情感词汇表和解码器状态st相结合以计算情感词的生成概率,其中,通用词汇表和情感词汇表无交集。
例如,根据下述公式以计算通用词和情感词的生成概率:
其中,wg和we分别表示通用词和情感词;pg和pe分别表示通用词和情感词的生成概率;st表示解码器的状态;
第三步,建立会话模型,得到生成句子中的下一个单词
步骤s3中,针对情感词和通用词的生成概率设置对应的权重,根据预设的规则将步骤s2中得到的情感词和通用词的生成概率进行连接,建立会话模型p(yt),得到生成句子中的下一个单词的方法包括以下步骤:
s301:利用类型选择器αt用于控制情感词和通用词的生成权重,根据下述公式将两者的权重概率相连接:
αt=sigmoid(vutst)
其中,αt∈[0,1]是用于平衡情感词we和通用词wg选择的一个标量;vu为权重参数;st表示解码器的状态。
s302:根据下述公式从连接的权重中采样得到下一个单词:
其中,wg和we分别表示通用词和情感词;pg和pe分别表示通用词和情感词的生成概率;p(yt)是情感词和通用词权重概率的连接,是最终的词解码分布;ot为输出的概率分布,从中采样得到下一个单词yt。
第四步,采用情感损失函数对步骤s3中得到的会话模型进行训练
步骤s4中,计算输入句子和生成句子中已生成部分的情感相似度,采用情感损失函数对步骤s3中得到的会话模型p(yt)进行训练,以使生成的句子与输入句子的情感偏差小于设定偏差阈值的方法包括以下步骤:
s401:最小化生成句子与输入句子的情感噪音来仿真人与人之间的交流。
s402:利用情感损失函数对会话模型p(yt)进行训练,以使生成的句子与输入句子的情感偏差小于设定偏差阈值。
例如,采用的情感损失函数为:
其中,第一项为标准的交叉熵损失函数,x表示输入的句子,yt表示生成的第t个单词;‖·‖2表示欧几里得距离;|x|表示输入句子的长度,
设定偏差阈值越小,生成的句子与输入的句子的情感越一致。
在本公开中参照附图来描述本发明的各方面,附图中示出了许多说明的实施例。本公开的实施例不必定义在包括本发明的所有方面。应当理解,上面介绍的多种构思和实施例,以及下面更加详细地描述的那些构思和实施方式可以以很多方式中任意一种来实施,这是因为本发明所公开的构思和实施例并不限于任何实施方式。另外,本发明公开的一些方面可以单独使用,或者与本发明公开的其他方面的任何适当组合来使用。
虽然本发明已以较佳实施例揭露如上,然其并非用以限定本发明。本发明所属技术领域中具有通常知识者,在不脱离本发明的精神和范围内,当可作各种的更动与润饰。因此,本发明的保护范围当视权利要求书所界定者为准。
- 还没有人留言评论。精彩留言会获得点赞!