一种基于词性和模糊模式识别组合的短文本分类方法与流程
本发明涉及计算机自然语言处理技术领域,特别涉及一种基于词性和模糊模式识别组合的短文本分类方法。
背景技术:
随着计算机技术的飞速发展及各种智能设备的广泛应用,智能化的客户服务在我们生活中出现的越来越多,人们可以通过简单的语音输入与智能设备进行人机交互。首先,用户的语音信息被转换为请求文本,然后对请求文本进行解析得到结果,最后将解析成功的文本数据传送到终端设备进行后续处理。为了更好地解析用户的请求文本,对文本进行领域分类显得尤为重要。
目前常用的文本分类算法,有朴素贝叶斯算法、knn算法、支持向量机算法及神经网络算法等。朴素贝叶斯算法虽然原理简单、易于实现,但是它需要一个很强的条件独立性假设前提,因此对被分类的文本要求较高,它要求文本中一个词汇出现与其他词汇是否出现无关,然而在实际应用中往往不成立,因为同一领域的词汇一起出现的概率很高,存在关联;knn算法分类效率较低,对大规模语料库进行文本分类时计算量大、复杂度高;支持向量机算法同样也是适用于小样本语料库,对大规模文本分类效果并不好;神经网络算法训练时间长,而且分类效果对训练集有一定依赖。
除此之外,用户对智能设备的请求文本通常是短文本,由于短文本具有长度短、特征少、实时性强等特点,短文本分类相对于长文本分类更具难度与挑战性,上述分类算法很难发挥好的效果。目前针对短文本分类也有基于语料扩充的方法,但是扩充方法过于复杂且效果无法保证。短文本分类的准确率不高是现阶段亟待解决的问题。
技术实现要素:
本发明的目的是克服上述背景技术中不足,提供一种基于词性和模糊模式识别组合的短文本分类方法,将中文分词工具中的词性标注与模糊数学中的模糊模式识别相结合,可用于对人机交互过程中的用户请求文本进行领域分类,进而提高短文本分类的准确率与效率。
为了达到上述的技术效果,本发明采取以下技术方案:
一种基于词性和模糊模式识别组合的短文本分类方法,包括:针对领域分类失败的用户请求文本,通过对领域分类正确的历史数据进行不同词性的特征词提取形成基础领域特征,结合知识图谱抽取相关领域的实体形成扩展领域特征;将基础领域特征和扩展领域特征进行延展词性标注构成自定义词典;基于先粗分后细分的思想,通过词性模式匹配及最大隶属度原则相结合对待分类文本进行领域分类,最终得到准确率较高的短文本分类结果。
进一步地,具体包括以下步骤:
a.将领域分类正确的请求文本数据分为个不同的领域,领域集合记为;
b.通过不同词性对领域分类正确的文本数据进行高频特征词提取作为该领域的基础领域特征(此步骤可借助分词工具实现),从该领域的相关知识图谱中抽取实体(该知识图谱可通过网络数据获取),作为该领域的扩展领域特征;
c.将每个领域的基础领域特征和扩展领域特征进行延展词性标注,构成自定义词典;
d.对待分类文本进行二值粗分,结果为领域待定和分类失败两种;
e.对结果为领域待定的待分类文本进行领域细分。
进一步地,所述步骤e具体包括:
e1.加载步骤c得到的包含不同领域特征的自定义词典;
e2.根据自定义词典对待分类文本进行分词,并对分词后的词语标注词性;
e3.对分词及标注词性后的待分类文本进行词性模式匹配与模糊模式识别。
进一步地,所述步骤e3具体为:
e3.1构建自定义词典中每个领域di的隶属度函数
e3.2分别计算待分类文本属于领域di(1≤i≤n)的隶属度m(d1),m(d2),…,m(dn),然后计算最大隶属度mx=max{m(d1),m(d2),…,m(dn)};
e3.3若mx≠0且唯一,则根据最大隶属度原则将待分类文本分类到第x类领域;否则,待分类文本领域分类失败。
进一步地,所述步骤d中,具体是通过判断待分类文本中是否含有名词性语素对待分类文本进行领域二值粗分,若待分类文本中包含名词性语素则被判定为领域待定的待分类文本,否则被判定为分类失败的待分类文本。
本发明与现有技术相比,具有以下的有益效果:
本发明的基于词性和模糊模式识别组合的短文本分类方法,通过对已知领域进行不同词性的特征词提取形成基础领域特征,并从知识图谱中抽取相关领域的实体形成扩展领域特征,对基础领域特征和扩展领域特征进行延展词性标注后,通过词性模式匹配与最大隶属度原则相结合对待分类文本进行领域分类,对短文本分类的准确率及效率有一定提高。
附图说明
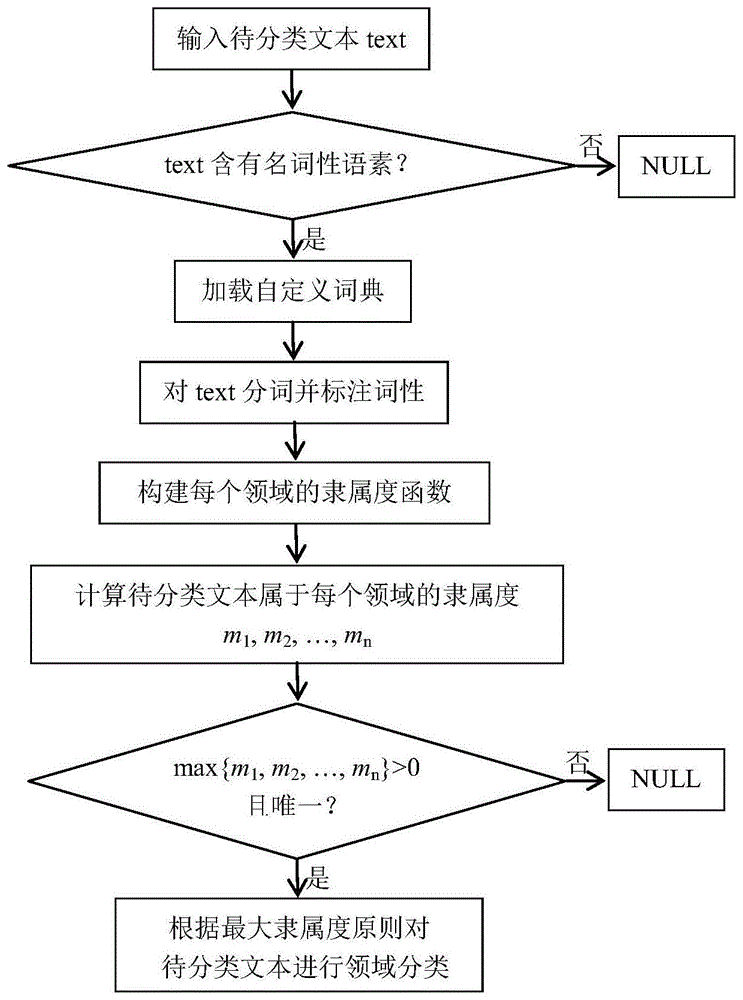
图1是本发明的基于词性和模糊模式识别组合的短文本分类方法的流程示意图。
图2是本发明的自定义词典的构建流程示意图。
具体实施方式
下面结合本发明的实施例对本发明作进一步的阐述和说明。
实施例:
如图1所示,一种基于词性和模糊模式识别组合的短文本分类方法,如图1所示,具体包括以下流程:
步骤1:将领域分类正确的请求文本数据分为个不同的领域,领域集合记为d={d1,d2,…,dn};
如本实施例中将领域分类正确的请求文本数据分为不同的领域,如将用户对智能电视的请求文本分为video、tv、music和app四个领域,则d={video,tv,music,app}。
步骤2:通过不同词性对领域分类正确的文本数据进行高频特征词提取作为该领域的基础领域特征,从该领域的相关知识图谱中抽取实体,作为该领域的扩展领域特征。
本实施例中,根据词性不同,分别对video、tv、music和app四个领域进行高频特征词提取,得到这四个领域的基础领域特征。
以video领域为例,根据名词和动词得到video领域的高频特征词如下:
动词:verb_video=[播放/v,点播/v,看电视/v,打开/v,搜索/v,……];
名词:noun_video=[电影/n,电视/n,电视剧/n,影片/n,连续剧/n,……];
这些高频特征词将作为video领域的基础领域特征,其他三个领域(tv、music和app)的基础领域特征可以通过相同的方法得到。
然后从知识图谱中抽取video领域的实体如下:
影视作品:entity_video=[某出没/n,某某的游戏/n,某某队长/n,我不是某某/n,泰某/n,……];
演员:actor_video=[刘某华/nr,周某驰/nr,成某/nr,刘某菲/nr,张某山/nr,……];
这些实体词语将作为video领域的扩展领域特征,其他三个领域的扩展领域特征可以通过相同的方法得到。
步骤3:将每个领域的基础领域特征和扩展领域特征进行延展词性标注,构成自定义词典。
本实施例中具体为:分别对video、tv、music和app四个领域的基础领域特征和扩展领域特征进行延展词性标注,这里所说的延展词性标注,是指在原来的词性基础上对词语的词性进一步地细化标注。如video领域的基础领域特征被标注为vvideo(动词)、nvideo(名词),video领域的扩展领域特征被标注为nvideo(影视作品)、nra(演员),而music领域的基础领域特征被标注为vmusic(动词)、nmusic(名词),music领域的扩展领域特征被标注为nmusic(歌曲作品)、nrs(歌手),tv领域和app领域的领域特征可以通过相同的方法进行延展词性标注。将延展词性标注后的每个领域的特征词构成自定义词典,自定义词典的构成流程具体如图2所示。
步骤4:对待分类文本进行二值粗分,结果为领域待定和分类失败两种。
本实施例中具体为通过判断待分类文本中是否含有名词性语素对待分类文本进行领域二值粗分,若待分类文本text形如语料库corpus1=[播放/v,漂亮/a吗/y,几点/m了/ul,……]中的形式,由于corpus1中的文本不包含名词性语素,则领域分类失败,即领域分类结果为分类失败null。
若待分类文本text包含名词性语素,则需要进一步对领域进行分类,即进入步骤5。
步骤5:加载步骤3得到的包含不同领域特征的自定义词典。
步骤6:对待分类文本进行分词,并对分词后的词语标注词性。
本实施例中假设有4条待分类文本,分别是text1=“周某伦不能说的秘密”,text2=“播放周某伦的不能说的秘密”,text3=“打开我的世界”,text4=“点播周某伦的电影不能说的秘密”。
上述4条待分类文本在加载自定义词典之前的分词和词性标注结果如下:
text1=[周某伦/nr,不/d,能/v,说/v,的/uj,秘密/n],
text2=[播放/v,周某伦/nr,的/uj,不能/v,说/v,的/uj,秘密/n],
text3=[打开/v,我/r,的/uj,世界/n],
text4=[点/m,播/v,周某伦/nr,的/uj,电影/n,不/d,能/v,说/v,的/uj,秘密/n]。
本方法中,加载包含不同领域特征的自定义词典之后,待分类文本的分词和词性标注结果如下:
text1=[周某伦/{nra:0.2,nrs:0.8},不能说的秘密/{nvideo:0.4,nmusic:0.6}],
text2=[播放/{vvideo:0.35,vmusic:0.35,vtv:0.3},周某伦/{nra:0.2,nrs:0.8},的/uj,不能说的秘密/{nvideo:0.4,nmusic:0.6}],
text3=[打开/{vapp:0.7,vvideo:0.3},我的世界/napp],
text4=[看看/vvideo,周某伦/{nra:0.2,nrs:0.8},的/uj,电影/nvideo,不能说的秘密/{nvideo:0.4,nmusic:0.6}]。
在本发明的自定义词典中,对不同词语在不同领域的不同词性的具有一个权重的分配,如“周某伦”一词既可能以歌手(singer)的身份出现在music领域,也可能以演员(actor)的身份出现在video领域,因此对它的词性延展标注为{nra:0.2,nrs:0.8},意思是“周某伦”的词性为nra的权重为0.2,词性为nrs的权重为0.8,在根据自定义词典进行分词和词性标注时,需同时参照该权重的分配对权重进行标注。
具体的,上述权重值的分配值可采取现有技术中的任意一种技术实现,如本实施例中采取根据从互联网抓取数据并对数据清洗后建立相关的数据库,然后根据该数据在数据库的不同领域中出现的次数确定该数据的不同词性的权重,如在数据库中搜索“周某伦”出现的结果为:80%的结果是其以作为歌手出现,20%的结果是其以演员的身份出现。
步骤7:构建自定义词典中每个领域di的隶属度函数
其中,如果一个词语以相同的词性出现在多个领域的领域特征中,则认为这个词语对领域分类的区分度不高,因此权重偏小;如果一个词语以不同的词性出现在多个领域的领域特征中,则将这个词语按照不同词性的权重在领域分类中加以区分。
具体在本实施例中,构建video、tv、music、app四个领域的隶属度函数如下:
步骤8:分别计算待分类文本属于领域di(1≤i≤n)的隶属度m(d1),m(d2),…,m(dn),然后计算最大隶属度mx=max{m(d1),m(d2),…,m(dn)}。
本实施例中以text2为例,参照步骤6中分词和词性标注结果,计算:
综上即:text2中:m(video)=0.2375,m(tv)=0.075,m(music)=0.4375,m(app)=0,mmusic=max{m(video),m(tv),m(music),m(app)}=0.4375>0。
步骤9:若mx≠0且唯一,则根据最大隶属度原则将待分类文本分类到第x类领域;否则,待分类文本领域分类失败。
本实施例中,由于mmusic=max{m(video),m(tv),m(music),m(app)}=0.4375>0,因此根据最大隶属度原则,待分类文本text2应该分类为music领域。同理可得,text1分类为music领域,text3分类为app领域,text4分类为video领域。
可以理解的是,以上实施方式仅仅是为了说明本发明的原理而采用的示例性实施方式,然而本发明并不局限于此。对于本领域内的普通技术人员而言,在不脱离本发明的精神和实质的情况下,可以做出各种变型和改进,这些变型和改进也视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!