一种基于主题模型的主题检索方法与流程
本发明属于主题建模和主题检索领域。特别是将两种方法的一种结合,利用人的先验知识和主题建模得到的统计信息共同构建主题并进行主题检索的方法。
背景技术:
主题模型(topicmodel)在机器学习和自然语言处理等领域是用来在数据集中(一系列文档中)发现抽象主题的一种统计模型。主题模型会根据输入的主题个数n,自动分析数据集中每个文档,统计文档内的词语,对数据集的词进行聚类,最后得到每个主题的词概率分布。
主题检索即将预先定义好的查询语句作为主题,在检索时只检索主题名称即等价于检索其对应的查询语句。比如,定义一个主题名称为“人工智能”的主题:“人工智能^5or机器人^3or自动驾驶^4”查询语句由关键字和关键词组成,上例中“人工智能”“机器人”“自动驾驶”是关键词。“or”和“^5”“^3”“^4”是关键字,分别代表关键词之间的关系(例子中为逻辑关系:or),以及每个关键词的权重(5,3,4)。逻辑或(or)表示有一个关键词命中就算命中,权重则代表关键词的重要性,命中含有权重高的关键词的文档得分高,会优先出现在搜索结果页的最前面。(注:不同搜索引擎支持的关键字语法形式略有不同,比如aorb,a<or>b,or(a,b),但都表示逻辑或,语义相同)主题检索的目的在于,可以把人(业务人员,运营人员和领域专家)的经验知识(哪些关键词最恰当的描述了该主题,他们的权重是多少,他们的关系是什么)通过查询语句给描绘捕获保存下来,而使用者不需知道该主题的查询语句是如何定义的,只需通过主题名称进行检索以达到浏览相关主题文章的目的,同时因为主题是查询语句,有很好的复用性,易修改性。
现有技术在定义主题的时候,都是利用人的经验知识直接来写查询语句。仍然举上述例子,如定义某主题名称为:“人工智能”,其查询语句为:“人工智能^5or机器人^3or自动驾驶^4”,这里面查询语句的每一个部分都来源人的经验。人通过经验决定哪些词最好的描述了“人工智能”这个主题,这些词的权重大小,以及这些词的关系。虽然人在捕捉实时热点词汇,设定词间关系上有很大优势;也有很好的主观能动性,能够让使用主题检索的人通看到主题定义者期望看到的文章集。但由于忽略客观数据集(数据集时搜索引擎索引的所有文章的集合)中的统计信息而完全依靠人来定义查询语句会带来一些缺陷。下面仍然通过上文的实例,定义某主题名称:“人工智能”,查询语句:“人工智能^5or机器人^3or自动驾驶^4”一一说明。1.召回率低,数据集中可能存在一些和人工智能相关的文章但并没有出现“人工智能”,“机器人”,“自动驾驶”这些词。取而代之是大量“ai”“机器学习”这些词汇。这将导致很多和该主题相关的文章在用户检索该主题时被遗漏,从而导致召回率低(召回率低指本符合条件的文章没有被检索到)。2.关键词设置不准确,数据集中可能存在一些和人工智能相关的文章但并没有出现“自动驾驶”。取而代之是“无人汽车”。虽然意思相同,但没有贴合数据集,不是数据集中描述方式最准确的词。所以仍然匹配不到这些文章降低召回率。3.权重比例定义不当。数据集中存在和人工智能相关的文章中,大量出现“机器人”关键词,而出现“自动驾驶”的次数少之又少。此时如果在定义主题时把“自动驾驶”的权重调整的过大于“机器人”的权重,会导致用户主题检索到最靠前的文章的都是冷门文章,而大量数据集的主流文章由于权重调整不当被沉在后面。4.效率低当数据集很大时,每一个主题的查询语句完全由人来思考描绘会大大降低效率。
技术实现要素:
本发明的目的在在于为了解决上述背景技术中提及的问题:由于仅依靠人的主观经验知识来定义主题的查询语句,而忽视了客观数据集本身的信息造成的。故本发明的目的就是提出一种由利用概率统计模型lda,从数据集挖掘统计信息,得到主题的词分布进而生成查询语句,同时仍可以在此基础上人为加工修改查询语句以达到人的经验知识和数据集的统计信息共同构建主题的技术方案。
本发明采用的技术方案为一种基于主题模型的主题检索方法,该方法包括如下步骤,
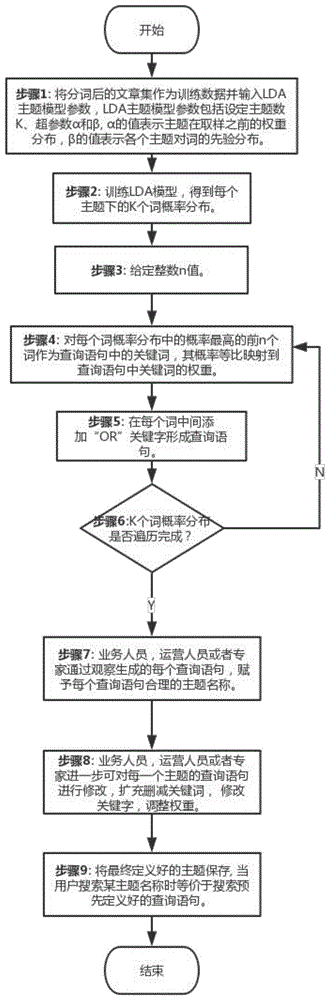
步骤1:将分词后的文章集作为训练数据并输入lda主题模型参数,lda主题模型参数包括设定主题数k、超参数α和β,α的值表示主题在取样之前的权重分布,β的值表示各个主题对词的先验分布。
步骤2:训练lda模型,得到每个主题下的k个词概率分布。
步骤3:给定整数n值。
步骤4:对每个词概率分布中的概率最高的前n个词作为查询语句中的关键词,其概率等比映射到查询语句中关键词的权重。
步骤5:在每个词中间添加“or”关键字形成查询语句。
步骤6:重复步骤4-5,直到k个词概率分布都转换成查询语句。
步骤7:业务人员,运营人员或者专家通过观察生成的每个查询语句,赋予每个查询语句合理的主题名称。
步骤8:业务人员,运营人员或者专家进一步对每一个主题的查询语句进行修改,扩充删减关键词,修改关键字,调整权重。
步骤9:将最终定义好的主题保存,用户搜索主题名称时等价使用预定义好的查询语句检索。
与现有技术相比较,本发明具有如下技术效果。
解决了完全依靠人来定义主题查询语句造成的缺陷,提高了制造主题的效率,提高主题检索的准确率与召回率。是客观数据集的统计数据和人的主观经验知识的取长补短,共同作用的结果。
附图说明
图1为本方法的流程图。
具体实施方式
以下结合附图和实施例对本发明进行详细说明。
本方法包括如下步骤:
步骤1:将分词后的文章集作为训练数据并输入lda主题模型参数,lda主题模型参数包括设定主题数k、超参数α和β,α的值表示主题在取样之前的权重分布,β的值表示各个主题对词的先验分布。
步骤2:训练lda模型,得到每个主题下的k个词概率分布。
步骤3:给定整数n值。
步骤4:对每个词概率分布中的概率最高的前n个词作为查询语句中的关键词,其概率等比映射到查询语句中关键词的权重。
步骤5:在每个词中间添加“or”关键字形成查询语句。
步骤6:重复步骤4-5,直到k个词概率分布都转换成查询语句。
步骤7:业务人员,运营人员或者专家通过观察生成的每个查询语句,赋予每个查询语句合理的主题名称。
步骤8:业务人员,运营人员或者专家进一步可对每一个主题的查询语句进行修改,扩充删减关键词,修改关键字,调整权重。
步骤9:将最终定义好的主题保存,用户搜索主题名称时等价使用预定义好的查询语句检索。
技术特征:
技术总结
本发明公开了一种基于主题模型的主题检索方法,将分词后的文章集作为训练数据并输入LDA主题模型参数。训练LDA模型,对每个词概率分布中的概率最高的前n个词作为查询语句中的关键词,其概率等比映射到查询语句中关键词的权重;在每个词中间添加“OR”关键字形成查询语句。业务人员,运营人员或者专家通过观察生成的每个查询语句,赋予每个查询语句合理的主题名称。进一步对每一个主题的查询语句进行修改,扩充删减关键词,修改关键字,调整权重。将最终定义好的主题保存,用户搜索主题名称时等价使用预定义好的查询语句检索。本发明解决了完全依靠人来定义主题查询语句造成的缺陷,提高了制造主题的效率,提高主题检索的准确率与召回率。
技术研发人员:徐晨;段娟;肖创柏
受保护的技术使用者:北京工业大学
技术研发日:2019.01.26
技术公布日:2019.06.21
- 还没有人留言评论。精彩留言会获得点赞!