一种基于API全局词向量和分层循环神经网络的恶意代码检测方法与流程
本发明涉及恶意代码检测领域,尤其涉及一种基于时序序列的恶意代码检测方法,属于计算机技术领域。
背景技术:
随着计算机和网络的飞速发展,带给人们诸多便利的同时也带给人们一定的威胁。网络黑客针对各种网络漏洞发起各种恶意攻击。恶意代码的传播不仅会干扰网络以及软件的正常使用,破坏重要数据,给个人和企业造成重大损失。
目前比较成熟的恶意代码检测主要通过匹配特征库中的特征检测恶意代码(如基于签名的检测方法)。这种方法对数据库中存在的特征检测准确率很高,但不能识别混淆后和未知的恶意代码。基于行为的检测方法监视的是程序活动行为,通过执行相关代码捕获行为信息,不受混淆技术的影响,并在一定程度上能识别未知恶意代码。然而,上述两种方法都需要相关领域专家的大量经验知识,无法实现自动化检测。
深度学习是近几年来人工智能领域发展最快的技术之一,在自然语言处理等具有时序信息相关领域中(如,命名实体识别,中文文本情感分析,文章分类,词性标注,机器翻译,对话系统等,循环神经网络等),取得了巨大进展。恶意代码检测过程中会触发一系列含有时序信息api行为序列,循环神经网络可以通过学习其内在的行为时序信息检测恶意代码,因此在未知恶意代码检测方面具有较好应用前景。
技术实现要素:
本发明利用深度学习思想,采用动态行为分析技术,提出一种基于api时序序列的恶意代码检测方法。由于恶意代码进行远程攻击时会触发一系列系统api,通常有较为频繁出现的序列组合。循环神经网络在处理时序信息方面有独特优势,将此优势与api时序结合,提出一种基于api时序序列的恶意代码检测方法,实现自动化的恶意代码检测,提高检测的正确率和检测速率,并能识别更多的未知恶意代码。
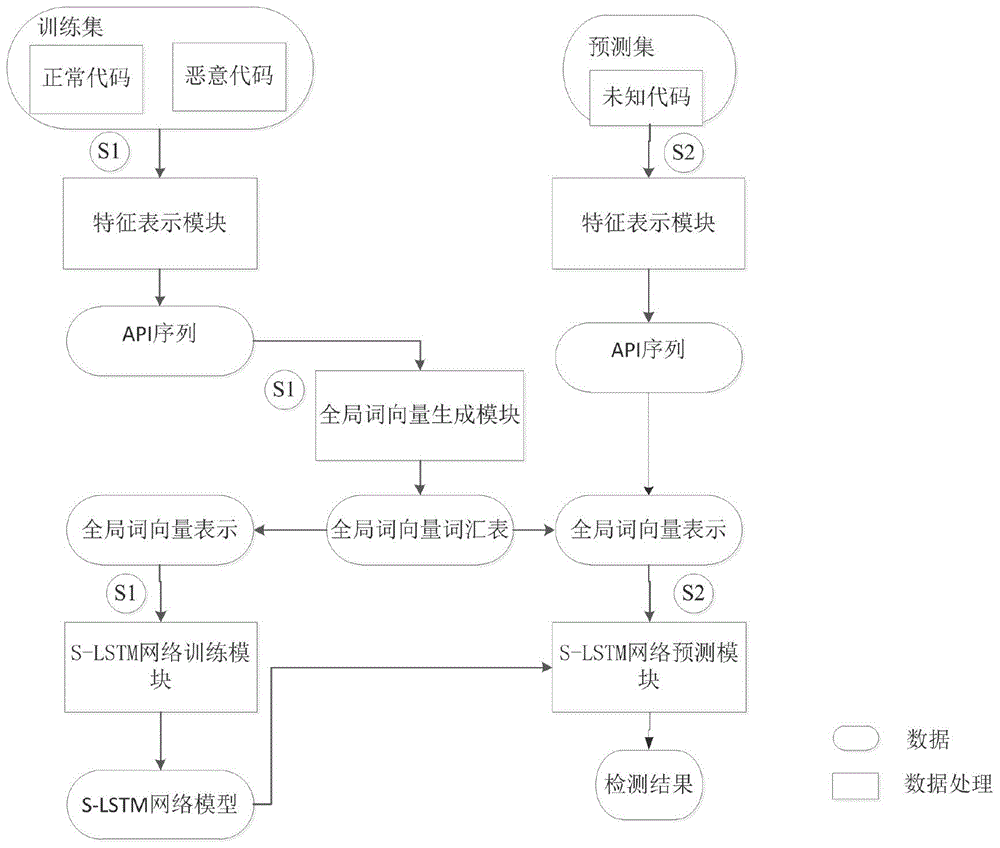
本发明采用的技术方案为一种基于全局词向量及分层循环神经网络(slice-longshort-termmemorynetworks,s-lstm)的恶意代码检测方法,该恶意代码检测方法包括两个阶段:s1已知样本的训练阶段,本阶段的目的主要为得到使用已知样本训练之后的网络模型。(s2)未知样本的预测阶段,预测阶段的目的主要为使用(s1)中的网络模型预测未知代码是否为恶意代码。
其中(s1)已知样本的训练阶段一共包含三个模块:(s1-1)特征表示模块,(s1-2)全局词向量生成模块,(s1-3)s-lstm网络训练模块。
(s2)未知样本的预测阶段一共包含两个模块:(s2-1)特征表示模块,此模块运行过程与(s1-1)相同,(s2-2)s-lstm网络预测模块。
对上述涉及到的模块做如下介绍:
首先,对(s1)已知样本的训练阶段涉及到的模块做如下介绍:
(s1-1)特征表示模块包括如下步骤:
步骤1,收集样本。收集恶意代码、正常代码以及代码标注组成样本训练集。
步骤2,获取样本api序列。在虚拟机中执行步骤1收集到的代码,使用apihook技术捕获代码执行过程中调用的api,并按照调用的先后顺序组成api序列。
(s1-2)全局词向量生成模块包括如下步骤:
步骤1,生成样本词汇表c。对(s1-1)中生成的api序列进行api统计,组成api词汇表c,c={api1,api2,...,apin},n表示词汇表c中api的个数。
步骤2,对词汇表c中所有的api生成相应的语义词向量。使用word2vec方法中的cbow模型对(s1-1)中生成的api序列进行训练,得到词汇表c中每个api的含有语义信息的词向量。
步骤3,对词汇表c中所有的api计算相应的信息增益值。使用信息增益方法计算词汇表c中每个api的信息增益值。
步骤4,对词汇表c中所有的api生成相应的全局词向量。对于词汇表c中的每个api,用步骤2中得到的词向量乘以步骤3中相应的信息增益值,得到每个api的全局词向量表示方法,组成全局词向量词汇表。
(s1-3)s-lstm网络训练模块包括如下步骤:
步骤1,对网络输入序列进行切分操作。对(s1-1)中得到的api序列进行截断和填充操作到统一长度,并对操作之后的序列进行切分,使得子序列长度合适并满足s-lstm网络的输入要求。
步骤2,设置网络超参数。对s-lstm网络中的超参数如网络训练数据集的次数epochs,网络每次训练的样本数batch_size,学习率α进行设置。
步骤3,训练s-lstm网络模型。将s1-1中生成的api序列用(s2-1)中生成的全局词向量表示,并作为s-lstm网络的输入,得到训练之后的s-lstm网络模型。
步骤4,对网络模型进行评价。网络训练过程采用5折交叉验证,其中4份作为训练集,剩下一份作为测试集,本发明的正确率为5折交叉验证的平均正确率,当平均正确率小于98%时,返回步骤2对网络超参数进行调整,直到网络平均正确率高于98%。
其次,对(s2)未知样本的预测阶段涉及到的模块做如下介绍:
(s2-1)特征表示模块步骤与(s1-1)相同,得到预测样本的api序列。
(s2-2)s-lstm网络预测模块包括如下步骤:
步骤1,利用(s1-2)中生成的全局词向量词汇表,将(s2-1)中api序列用全局词向量表示。
步骤2,将步骤1中的词向量作为(s1-3)训练生成的s-lstm网络的输入,得到未知样本的检测结果。
本方法利用深度学习的思想对恶意代码进行检测,与其他检测方法相比,有如下好处:
1、本发明提出了一种基于检测重要性的全局词向量方法。传统词向量word2vec方法只表示了上下文词语相关性关系,本发明提出的api全局词向量方法将api对检测的重要性信息融入传统的上下文相关性信息中,提高了恶意代码检测的准确率。在使用相同数据样本集(2000个恶意样本及910个非恶意样本)和lstm网络进行恶意代码检测的前提下,经过5折交叉验证发现,与采用经典的word2vec方法输出的词向量作为lstm的输入(5折交叉验证的平均检测正确率为98.69%)相比,采用本发明提出的全局词向量方法输出的词向量作为lstm的输入(5折交叉验证的平均检测正确率为98.8%),检测正确率有稳定提高(5折交叉验证正确率提高0.09%到0.14%不等,平均正确率提高0.11%)。
2、本发明提出了一种适用于恶意代码检测场景的分层循环神经网络快速检测方法。由于代码运行过程中会触发大量api,例如本发明使用的数据样本触发的api序列的平均长度为19000,提取的api序列特征会过多,从而导致检测时间过长。本发明将s-lstm网络应用于恶意代码检测场景,将超长api序列划分为多个子序列,采用多层网络进行子序列并行检测。在使用相同数据样本集上和使用传统词向量word2vec方法作为网络输入的前提下,与采用传统lstm网络进行检测相比,本发明提出的基于分层循环神经网络的恶意代码检测方法,能将检测时间从750分钟缩减到99分钟,检测时间减少了86.8%。
3、本发明方法提出的基于api全局词向量和分层循环神经网络的恶意代码检测方法,具有检测自动化程度高、准确识别未知恶意代码行为特点。在提高检测自动化程度方面,本方法只需要对已有样本的恶意性进行人工标记,与现有机器学习算法相比,不需要额外进行api行为特征选择,有利于提高检测自动化程度;在准确识别未知恶意代码行为方面,本方法主要通过循环神经网络发现的代码api行为时序关系进行恶意代码识别,因此能够识别未知但具有相似行为的恶意代码。而进行恶意代码行为识别的机器学习算法通常不直接识别这些api之间的时序关系,而是基于多个选择特征api(如设置共享文件夹netshareadd,强制结束一个进程terminateprocess等)进行综合检测,因此更依赖样本质量。与k近邻算法(正确率为97.66%),支持向量机(正确率为96.49%),决策树(正确率为97.94%)等常用机器学习算法相比,本方法检测正确率为98.86%,正确率有明显提升(分别提高了1.2%,2.37%,0.92%)。
附图说明
图1本发明总体框架图
图2全局词向量模型结构图
图3s-lstm网络结构
具体实施方式
下面结合附图和具体实施方式对本发明做进一步的说明。
本发明的整体架构图如图1所示,恶意代码检测方法包括两个阶段:(s1)已知样本的训练阶段,本阶段的目的主要为得到使用已知样本训练之后的网络模型。(s2)未知样本的预测阶段,本阶段的目的主要为使用(s1)中的网络模型预测未知代码是否为恶意代码。
其中(s1)已知样本的训练阶段一共包含3个模块:(s1-1)特征表示模块,(s1-2)全局词向量生成模块,(s1-3)s-lstm网络训练模块。
(s2)未知样本的预测阶段一共包含2个模块:(s2-1)特征表示模块,此模块运行过程与(s1-1)相同,(s2-2)s-lstm网络预测模块。
首先,对(s1)已知样本的训练阶段涉及到的模块做如下介绍:
(s1-1)特征表示模块包括如下步骤:
步骤1,获取样本。收集恶意代码、正常代码以及代码标注组成样本训练集。恶意样本来自http://academictorrents.com/,正常样本来自系统文件以及http://xiazai.zol.com.cn/。
步骤2,获取样本api序列。在虚拟机中执行步骤1收集到的代码,使用apihook技术捕获代码执行过程中调用的api,并按照调用的先后顺序组成api序列。
(s1-2)全局词向量生成模块如图2所示,包括如下步骤:
步骤1,生成样本词汇表c。对(s1-1)中生成的api序列进行api统计,组成api词汇表c,c={api1,api2,...,apin},n表示词汇表c中api的个数。
步骤2,对词汇表c中所有的api生成相应的语义词向量v(w)。使用经典的word2vec方法中的cbow模型对(s1-1)中生成的api序列进行训练,得到词汇表c中每个api的含有语义信息的词向量v(w)。
cbow模型结构如图2左侧cbow模型所示,分为输入层、投影出、输出层。cbow模型是用周围词即context(w)=w-c,...,w-1,w1,...,wc来预测中心词w,本发明中w即api,c表示窗口大小。用条件概率p(w|content(w))表示中心词w在窗口为c的上下文中出现的概率,cbow模型的优化目标为
步骤3,对词汇表c中所有的api计算相应的信息增益值ig(w)。使用信息增益方法计算词汇表c中每个api的信息增益值。信息增益值表示api为分类带来的信息量,带来的信息量越多,该api越重要。
步骤4,对词汇表c中所有的api生成相应的全局词向量v(w)。对于词汇表c中的每个api,用w表示,用步骤2中得到的词向量v(w)乘以步骤3中相应的信息增益值ig(w),即v(w)=v(w)*ig(w),得到每个api的全局词向量v(w)表示方法,组成全局词向量词汇表,并保存在g_cbow_file文件中。
(s1-3)s-lstm网络训练模块包括如下步骤:
步骤1,切分输入序列,构建s-lstm网络结构。对s1-1中得到的api序列进行截断和填充操作到统一长度,并对操作之后的序列进行切分,使得子序列长度合适。并且构建适合本发明的s-lstm网络,s-lstm网络结构包含输入层、隐藏层、输出层。本步骤介绍s-lstm网络的输入层和隐藏层,输出层在步骤3介绍。
假设输入序列长度为[x1,x2,...,xt],其中x表示每一时刻的输入,t表示序列的长度。将序列x切分为n个子序列,子序列n的长度t=t/n。因此输入序列x可表示为x=[n1,n2,...,nn],对于给定的子序列np可表示为np=[x(p-1)*t+1,x(p-1)*t+2,...,xp*t]。同样,再将子序列n划分为n个等长的子序列,并且重复这样的操作k次,直到最底层的子序列长度合适,然后通过k次分割,得到k+1层网络。第0层网络的最小子序列长度为
本发明中提取的api序列平均长度高达19000,并且在k=2时网络模型取得最好效果。因此,本发明中t=19683,k=2,为了使序列能整分将n设置为27。本发明s-lstm网络如图3所示,网络输入层的长度t=19683,通过2次切分操作,得到3层隐藏层。隐藏层第0层子序列的数量为27,子序列长度为729;隐藏层第1层子序列数量为27,子序列长度为27;隐藏层第2层子序列长度为1,子序列长度为27,通过3层隐藏层得到最终隐层状态f。
步骤2,设置网络超参数。对s-lstm网络中的超参数,根据经验值设置网络训练数据集的次数epoch=15,网络每次训练的样本数batch_size=30,学习率α=0.01。
步骤3,训练s-lstm网络模型。将(s1-1)中生成的api序列用(s2-1)中生成的全局词向量表示,并作为s-lstm网络的输入,通过三层隐藏层之后得到最终隐层状态f,并通过softmax函数得到网络输出值
步骤4,对网络模型进行评价。网络训练过程采用5折交叉验证,其中9份作为训练集,剩下一份作为测试集,本发明的正确率为5折交叉验证的平均正确率,当平均正确率小于98%时,返回步骤2对网络超参数进行调整,直到网络平均正确率高于98%。
其次,对(s2)未知样本的预测阶段涉及到的模块做如下介绍:
(s2-1)特征表示模块步骤与(s1-1)相同,得到预测样本的api序列。
(s2-2)s-lstm网络预测模块包括如下步骤:
步骤1,利用(s1-2)中生成的全局词向量词汇表,将(s2-1)中api序列用全局词向量表示。
步骤2,将步骤1中的词向量作为(s1-3)训练生成的s-lstm网络的输入,得到未知样本的检测结果。
- 还没有人留言评论。精彩留言会获得点赞!