适用于国密sm2p256v1算法的快速蒙哥马利模乘器优化组件的制作方法
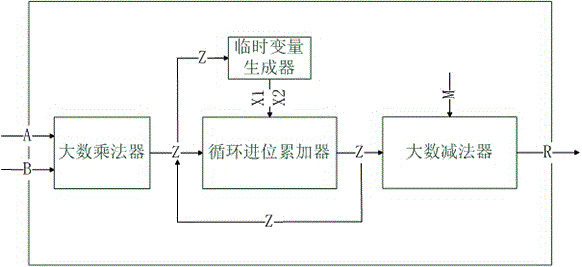
本发明涉及信息安全领域,尤其涉及适用于国密sm2p256v1算法的快速蒙哥马利模乘器优化组件。
背景技术:
在信息安全芯片进行国密运算时,蒙哥马利模乘器是调用频率最高最耗时的模块,虽然通用算法可以适配任何曲线参数,但是针对使用频率占绝对优势的国密推荐曲线sm2p256v1,使用嵌套循环的计算方式,时间复杂度高,硬件设计复杂度高,功耗高。
技术实现要素:
本发明的目的在于,大量减少了乘法器资源,降低了蒙哥马利模乘器的设计复杂度,降低了硬件功耗,设计适用于国密sm2p256v1算法的快速蒙哥马利模乘器优化组件。
本发明的发明目的是通过以下技术方案实现的:
适用于国密sm2p256v1算法的快速蒙哥马利模乘器优化组件,包括:大数乘法器、临时变量生产器、循环进位累加器和大数减法器,输入位宽为256bit的大整数a和b通过大数乘法器得到一个位宽为512bit的大整数z,通过z生成临时变量x1和x2后与z进行8次进位累加操作,每一位进位累加得到的结果z再作为进位累加器和临时变量生成器的输入,在完成8次进位累加操作后,如果z大于或等于大整数常量m,则将m于z进行一次大数减法运算,否则直接输出8次循环进位累加器的结果。
进一步的,所述的大数乘法器运算方式为:z=(z16,...,z0)=a×b。
进一步的所述的临时变量生产器运算方式为:通过公式t=zi、x1=t<<32-t和x2=x1-t计算x1和x2,其中x1和x2的数据位宽均为64bit。
进一步的,所述的循环进位累加器运算方式为:按照以下步骤依次计算出
(zi+8,...,zi+0):s1:(c,zi+0)=zi+0+x1+c;
s2:(c,zi+1)=zi+1+x1+c;
s3:(c,zi+2)=zi+2+0+c;
s4:(c,zi+3)=zi+3+x1+c;
s5:(c,zi+4)=zi+4+x1+c;
s6:(c,zi+5)=zi+5+x1+c;
s7:(c,zi+6)=zi+6+x1+c;
s8:(c,zi+7)=zi+7+x2+c;
s9:(carry,zi+8)=zi+8+c+caary;
如s1中(c,zi+0)=zi+0+x1+c,其中zi+0的数据位宽为32bit,x1和c的数据位宽均为64bit,步骤s2~s9以此类推,zi为32bit中间变量。
进一步的,所述的大数减法器运算方式为:如果(z16,...,z8)≥m,则r=(z16,...,z8)-m。
有益效果:本发明适用于国密sm2p256v1算法的快速蒙哥马利模乘器优化组件大量减少了乘法器资源,降低了蒙哥马利模乘器的设计复杂度,降低了硬件功耗,并且提高了信息安全芯片在运算国密sm2p256v1曲线参数时蒙哥马利模乘器的运算效率,在降低芯片运算功耗的基础上可以相应的简化信息安全芯片的内部结构,从而降低芯片的生产制造成本。
附图说明
图1是蒙哥马利模乘器优化组件结构图。
具体实施方式
对本发明做进一步的描述,但本发明的保护范围不局限于以下所述。
如图1所示,适用于国密sm2p256v1算法的快速蒙哥马利模乘器优化组件,包括:大数乘法器、临时变量生产器、循环进位累加器和大数减法器,输入位宽为256bit的大整数a和b通过大数乘法器得到一个位宽为512bit的大整数z,通过z生成临时变量x1和x2后与z进行8次进位累加操作,每一位进位累加得到的结果z再作为进位累加器和临时变量生成器的输入,在完成8次进位累加操作后,如果z大于或等于大整数常量m,则将m于z进行一次大数减法运算,否则直接输出8次循环进位累加器的结果。
进一步的,所述的大数乘法器运算方式为:z=(z16,...,z0)=a×b。
进一步的所述的临时变量生产器运算方式为:通过公式t=zi、x1=t<<32-t和x2=x1-t计算x1和x2,其中x1和x2的数据位宽均为64bit。
进一步的,所述的循环进位累加器运算方式为:按照以下步骤依次计算出
(zi+8,...,zi+0):
s1:(c,zi+0)=zi+0+x1+c;
s2:(c,zi+1)=zi+1+x1+c;
s3:(c,zi+2)=zi+2+0+c;
s4:(c,zi+3)=zi+3+x1+c;
s5:(c,zi+4)=zi+4+x1+c;
s6:(c,zi+5)=zi+5+x1+c;
s7:(c,zi+6)=zi+6+x1+c;
s8:(c,zi+7)=zi+7+x2+c;
s9:(carry,zi+8)=zi+8+c+caary;
如s1中(c,zi+0)=zi+0+x1+c,其中zi+0的数据位宽为32bit,x1和c的数据位宽均为64bit,步骤s2~s9以此类推,zi为32bit中间变量。
进一步的,所述的大数减法器运算方式为:如果(z16,...,z8)≥m,则r=(z16,...,z8)-m。
进一步的,所述的sm2p256v1是国密推荐的素数域256位椭圆曲线参数,椭圆曲线方程为y2=x3+ax+b。曲线参数如下:
其中参数p为蒙哥马利模乘中需要固定使用参数。
有益效果:本发明适用于国密sm2p256v1算法的快速蒙哥马利模乘器优化组件大量减少了乘法器资源,降低了蒙哥马利模乘器的设计复杂度,降低了硬件功耗,并且提高了信息安全芯片在运算国密sm2p256v1曲线参数时蒙哥马利模乘器的运算效率,在降低芯片运算功耗的基础上可以相应的简化信息安全芯片的内部结构,从而降低芯片的生产制造成本。
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
技术特征:
技术总结
适用于国密sm2p256v1算法的快速蒙哥马利模乘器优化组件,包括大数乘法器、临时变量生产器、循环进位累加器和大数减法器,输入位宽为256bit的大整数A和B通过大数乘法器得到一个位宽为512bit的大整数Z,通过Z生成临时变量X1和X2后与Z进行8次进位累加操作,每一位进位累加得到的结果Z再作为进位累加器和临时变量生成器的输入,在完成8次进位累加操作后,如果Z大于或等于大整数常量M,则将M于Z进行一次大数减法运算,否则直接输出8次循环进位累加器的结果。
技术研发人员:吴汶泰;秦放;周健;薛珊珊
受保护的技术使用者:四川卫士通信息安全平台技术有限公司
技术研发日:2019.03.20
技术公布日:2019.06.25
- 还没有人留言评论。精彩留言会获得点赞!