一种基于RISC_V串行FLASH系统架构的高效CPU指令读取法的制作方法
本发明公开了一种处理器的验证方法,尤其是涉及一种基于risc_v串行flash系统架构的高效cpu指令读取法。
背景技术:
现有技术中,传统的mcu将spiflash芯片作为软件指令存储,往往为了满足软件高效运行指令的需求,需要在mcu芯片内部嵌入大容量的内存sram用于指令的执行和存储,该种方法这不利于mcu芯片的成本控制且指令执行效率低下,运算速度极慢,极大的浪费了企业的生产成本,消耗了大量的人力和时间,给企业造成巨大的经济损失。
技术实现要素:
本发明的目的在于提供一种基于risc_v串行flash系统架构的高效cpu指令读取法,本发明采用的技术方案是:。
本发明具有的有益效果是:定义了一种基于spi串行flash接口的flash读取加速器的硬件逻辑架构,达到可以在不需要太多sram支持的前提下,实现cpu直接从flash里高效地读取指令并执行的目的,达到平均95%以上的指令命中效率,利用片外串行flash的大容量,低成本优势来满足软件对程序空间和指令执行效率的双重要求,降低了企业生产成本,降低了企业的经济损失,给企业正常运营带来极大的便利。
附图说明
图1为本发明的指令读取加速硬件逻辑架构示意图;
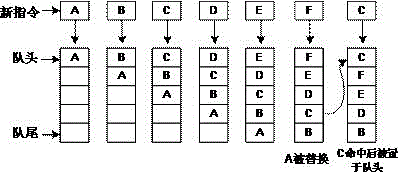
图2为本发明的算法说明图。
具体实施方式
下面将结合附图和实施例对本发明作进一步的说明。
本发明的一种基于risc_v串行flash系统架构的高效cpu指令读取法,其特征是:硬件架构内cacheline共16条,cacheline使用一块片内sram来实现软件指令存储,sram的存储空间大小可根据每一条cacheline缓存的指令条数以及cacheline的条数来决定;每次cpu读取某条地址的指令时,硬件逻辑会在16条cacheline中做地址匹配,当指令地址已经存在于当前的指令缓存中,则直接从sram中读取指令;当cpu读取的指令地址不存在于当前的指令缓存中时,逻辑才会发起对flash访问命令,并一次性读取一定条数的地址连续的指令并存储到sram中,用于替换旧的缓存指令。
具体的,spiflash接口控制逻辑模块,是基于硬件逻辑实现的spiflash访问命令执行模块,软件不参与spiflash的访问控制。
具体的,cpu取指令接口控制模块是基于mcu访问总线协议设计逻辑,根据ahb或axi协议处理。
具体的,匹配替换算法为lru算法,当mcu读取指令的地址在所有的16条cacheline中都不存在的时候,硬件逻辑则自动用从片外spiflash读取进来的新的64条指令替换掉16条cacheline中最久没用被命中过的那一条。
具体的,16条cacheline,每条缓存32条32bit指令,所以sram的大小是16x32x4=2kb。
下面结合附图对本发明的具体实施方式做出简要说明。
本发明提供了一种基于risc_v串行flash系统架构的高效cpu指令读取法。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。
本发明指令读取加速硬件逻辑架如图1所示,硬件架构内cacheline共16条,cacheline使用一块片内sram来实现软件指令存储,sram的存储空间大小可根据每一条cacheline缓存的指令条数以及cacheline的条数来决定;每次cpu读取某条地址的指令时,硬件逻辑会在16条cacheline中做地址匹配,当指令地址已经存在于当前的指令缓存中,则直接从sram中读取指令;当cpu读取的指令地址不存在于当前的指令缓存中时,逻辑才会发起对flash访问命令,并一次性读取一定条数的地址连续的指令并存储到sram中,用于替换旧的缓存指令。spiflash接口控制逻辑模块,是基于硬件逻辑实现的spiflash访问命令执行模块,软件不参与spiflash的访问控制。cpu取指令接口控制模块是基于mcu访问总线协议设计逻辑,根据ahb或axi协议处理。匹配替换算法为lru算法,当mcu读取指令的地址在所有的16条cacheline中都不存在的时候,硬件逻辑则自动用从片外spiflash读取进来的新的64条指令替换掉16条cacheline中最久没用被命中过的那一条,16条cacheline,每条缓存32条32bit指令,所以sram的大小是16x32x4=2kb,算法如图2所示。
在上述硬件架构中,mcu取指令在运行coremark程序时基本可以达到平均95%的命中率,即95%的指令可以在片内的sram中直接读取,从而减少片外flash的访问次数,达到提高cpu指令运行效率的目的。
本发明不局限于上述实施方式,任何人应得知在本发明的启示下做出的与本发明具有相同或相近的技术方案,均落入本发明的保护范围之内。
本发明未详细描述的技术、形状、构造部分均为公知技术。
技术特征:
技术总结
本发明公开了CPU指令读取技术,尤其是涉及一种基于RISC_V串行FLASH系统架构的高效CPU指令读取法。该一种基于RISC_V串行FLASH系统架构的高效CPU指令读取法,硬件架构内cache line共16条;每次CPU读取某条地址的指令时,硬件逻辑会在16条Cache line中做地址匹配,当指令地址已经存在于当前的指令缓存中,则直接从SRAM中读取指令;当CPU读取的指令地址不存在于当前的指令缓存中时,逻辑才会发起对FLASH访问命令,并一次性读取一定条数的地址连续的指令并存储到SRAM中,用于替换旧的缓存指令。其有益效果是:降低了企业生产成本,降低了企业的经济损失,给企业正常运营带来极大的便利。
技术研发人员:饶勇;黄勇华;吴海龙;徐桂洪
受保护的技术使用者:威海优微科技有限公司
技术研发日:2019.03.22
技术公布日:2019.07.26
- 还没有人留言评论。精彩留言会获得点赞!