一种用于评价草地退化程度的训练数据处理方法与流程
本发明涉及草地退化改良
技术领域:
,具体地说,是一种用于评价草地退化程度的训练数据处理方法。
背景技术:
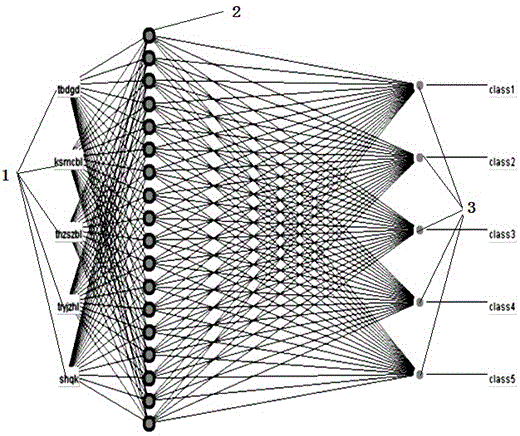
:在大数据时代,各个领域每天会产生大量的数据,若这些数据不能服务于人类,则可能会成为无用数据,甚至是垃圾。但是,当我们很好的利用这些大数据,则可能会变废为宝。处于世界屋脊青藏高原的青海地区,是三江源腹地,是长江、黄河、澜沧江的发源之地、这里的气候会影响到长江、黄河的中下游乃至中南亚的气候。因此,三江源生态保护是国家重要的战略之一,多年来投入大量的资金,在做这项伟大而又艰巨的任务。三江源高寒草甸作为一种独特的草地类型,成为了很多研究者研究的对象。当地的草原总站、畜牧厅以及生态保护工作者、研究者每年会收集大量的工作数据,记录着多年来他们的心血。在长期的三江源生态环境保护研究中,科研工作者采集了有关生态学、地理学、地质学、环境学、社会学、经济学等各方面的大量数据,这些数据凝聚着几代科研工作者的心血和汗水,但由于科研工作者学科的关系,往往都是一些孤立的信息数据,具有本学科的特点和数据孤立性。长期以来一直依靠专家的经验并用人工的方法来进行评价草地退化情况。在长期的研究工作中,针对三江源高寒草甸,利用计算机人工智能技术开发高寒草甸草地分级决策与治理的专家系统来解决三江源地区草地退化程度判定和决策问题。一方面可以以计算机代替草地专家进行专家级别的决策,节省人力、物力、财力;另一方面,可以将专家的知识进行系统的总结,长期的存于计算机中,对专家知识的保护和传承。对于草地退化,研究方法很多,角度不同,切入点不同,结论也不同。草地退化对环境的影响尤为恶劣,现有的草原退化信息采集处理方法,过于简单,适用性较低。技术实现要素:为了解决上述技术问题,本发明披露了一种用于评价草地退化程度的训练数据处理方法,该方法能够将采集到的海量数据进行科学处理,然后进行归纳总结,去除一些错误和非必要的数据,对剩余的高质量数据进行分析,协助专家对待评价草地的退化程度进行科学评价。本发明采用的具体技术方案如下:一种用于评价草地退化程度的训练数据处理方法,将现有的数据作为神经网络的参数集,根据草地退化程度对该参数集进行分类,即,未退化、轻度退化、中度退化、重度退化和极度退化,然后建立神经网络模型,再将待评价草地上的可视草地植被数据采集整理作为训练集,通过神经网络模型,将训练集与参数集进行比对分析,得到该待评价草地的退化程度。在上述技术方案中,将现有的数据作为神经网络的参数集,根据草地退化程度对该参数集进行分类:未退化、轻度退化、中度退化、重度退化和极度退化。每种退化类别的草类有明显的特征,按照这些特征,按照专家的观点将其总结为5个因素,即,凸斑地盖度、可食牧草比例、退化指示草种比例、土壤有机质含量、鼠害情况。每条可视草地植被信息对应的五种输入数据在分布上有个明显的特点,是每种类型的数据大致分布在不同的区域的,五种类型的数据的分布是有一定规律的,因此可以用不用颜色来标注数据的类型,只要看哪种颜色数据分布比较大即可获得待评价草地的退化程度。其中,神经网络结构采用tbdgd(凸斑地盖度)、ksmcbl(可食牧草比例)、thzsczbl(退化指示草种比例)、tryjzhl(土壤有机质含量)、shqk(鼠害情况)五个重要的影响草地退化的因素作为神经网络的5个输入结点,class1(未退化)、class2(轻度退化)、class3(中度退化)、class4(重度退化)和class5(极度退化)五个退化类别作为神经网络的5个输出结点,隐含结点的确定,通过大量的训练数据进行实验而确定的。本发明的进一步改进,对参数集采用公式最小最大规范化进行格式化,最小最大规范化如公式如下:其中,其中,v为参数数据,mina为训练集数据的最小值,maxa为训练集数据的最大值。最小最大规范化后,把所有数据定义在[0,1]范围之内,这样做的好处是将所有数据集体放大或集体缩小,以使得这些数据都落在一个统一的范围之内,但数据之间的关系是不会发生变化的。本发明的进一步改进,神经网络模型采用BP神经网络模型;训练集内的数据量小于等于参数集内的数据量。本发明的有益效果:本发明采用大数据与计算机专用程序结合,使得草地退化程度评价更加客观准确,且具有很强的通用性,可以适用于任何地区的草地退化评价。附图说明图1为隐含结点数为18的神经网络结构图;图2为隐含结点数为4的神经网络结构图;图3为五种类别的数据是基本均匀分布的数据集分布图。图4为集中分布在3,4,5类中的数据分布图。具体实施方式为了加深对本发明的理解,下面将结合附图和实施例对本发明做进一步详细描述,该实施例仅用于解释本发明,并不对本发明的保护范围构成限定。实施例:数据来源介绍:三江源高寒草甸作为一种独特的草地类型,成为了很多研究者研究的对象。具体实施方案:一种用于评价草地退化程度的训练数据处理方法,将现有的数据作为神经网络的参数集,根据草地退化程度对该参数集进行分类,即,未退化、轻度退化、中度退化、重度退化和极度退化,然后建立神经网络模型,再将待评价草地上的可视草地植被数据采集整理作为训练集,通过神经网络模型,将训练集与参数集进行比对分析,得到该待评价草地的退化程度,其中,对参数集采用公式最小最大规范化进行格式化,最小最大规范化如公式如下:其中,其中,v为参数数据,mina为训练集数据的最小值,maxa为训练集数据的最大值。最小最大规范化后,把所有数据定义在[0,1]范围之内,这样做的好处是将所有数据集体放大或集体缩小,以使得这些数据都落在一个统一的范围之内,但数据之间的关系是不会发生变化的。在本实施例中,神经网络设计:神经网络结构采用BP神经网络模型,将tbdgd(凸斑地盖度)、ksmcbl(可食牧草比例)、thzsczbl(退化指示草种比例)、tryjzhl(土壤有机质含量)、shqk(鼠害情况)五个重要的影响草地退化的因素作为神经网络的5个输入结点,class1(未退化)、class2(轻度退化)、class3(中度退化)、class4(重度退化)和class5(极度退化)五个退化类别作为神经网络的5个输出结点。在本发明技术方案中,收集了2万多条数据,分析并预处理后,部分作为神经网络设计、训练与测试,进行首次草地的评价;部分用于补充评价,图1和图2实验过程中随机截图的隐含结点为18和4的两种结构的神经网络结构,其中,绿色部分1为神经网络的输入,黄色部分2为神经网络的输出,中间红色部分3为隐含结点。对草地的研究是很多草地专家研究的热点问题,针对三江源地区高寒草甸草地退化的原因及影响因素,很多专家做了大量的研究,因研究的手段不同、研究地区不同、着眼点不同,研究的结果也会不同。有些专家学者从健康草甸(hm)、退化斑块(dp)、2年的Zokor土堆(zm2)三个方面进行研究草地的退化情况。本实施例以另一类专家的观点为例进行草地退化程度的决策方法的研究。此观点认为,三江源地区高寒草地的分类分为5个级别,分别为未退化、轻度退化、中度退化、重度退化、极度退化,而影响这五个级别主要影响因素有5个,分别为禿斑地盖度、可食牧草比例、退化指示种比例、0—10cm土壤有机质含量、鼠害情况。因为神经网络模型的质量跟训练数据质量有很大的关系,当数据质量不够好的情况下,调整神经网络的各种参数,可以让神经网络模型在训练数据上的正确率提高;但这种神经网络模型对测试数据的正确率不会太高;当数据质量足够好的情况下,神经网络模型将会具有很好的预测能力。数据质量包括很多因素,比如数据的数量、数据的格式、数据的分布等,这里的数据包括训练数据和测试数据。采用规模大小为40的数据集作为训练集,进行训练,通过调整神经网络参数,网络的模型的正确率能达到100%,随机的选择5条数据作为测试进行测试,结果错误率为90%,即正确率为10%。当不断增大数据规模时,测试正确率不断提高,直到数据模型规模达到10000多条时,训练网络模型的正确率为依然为100%,而测试集的正确率持续增长,最后达到98%。如下表1。表1数据规模对测试集的正确率增长训练数据规模测试集正确率4010%10012%100052%500061%8000082%1500098%当选择原始数据进行实验时,自己编写的bp神经网络尚可识别此格式,但模型的正确率不是很高。而在weaka中无法识别此格式。实验中原始数据如下表2。表2原始数据对原始数据采用公式最小最大规范化进行格式化,最小最大规范化如公式(1):其中,v为原始数据,mina为本列数据的最小值,maxa为本列数据的最大值。最小最大规范化后,把所有数据定义在[0,1]范围之内,这样做的好处是将所有数据集体放大或集体缩小,以使得这些数据都落在一个统一的范围之内,但数据之间的关系是不会发生变化的,最小最大规范化后的数据如下表3。表3格式化后数据0.8163270.0808080.7857140.0481480.899194class50.8265310.0808080.9591840.129630.989919class5………………0.6428570.3131310.7346940.2111110.788306class40.6428570.3131310.7346940.2111110.465726class4………………0.2765310.4444440.3581630.2962960.304435class30.2857140.4444440.3877550.2370370.385081class3………………0.1193880.6363640.2448980.3111110.102823class20.1193880.6363640.1428570.3111110.102823class2………………0.0397960.7878790.0418370.4592590.056452class10.0397960.7878790.0418370.6481480.079637class1………………训练数据集的分布对网络模型的影响当我们选择随机分布在不同类型中的数据,即,训练集中的数据在这五类中的分布不均匀,大部分集中在一个类中,如class1类中,或大部分集中在某一类中的一个区域中,其他类和其他区域中的数据未被选择,如,训练集如下表4,则训练结果为,模型的正确率达100%,而测试数据不是落在这些测试范围之内时,其错误率为100%,即,正确率为0%。只有当测试数据分布在训练数据中分布密集区的数据,测试结果才是正确的,否则是错误的。实验中部分数据分布如图3和图4。图3为15000条数据基本在每个类中均有分布,图4为10000条数据主要分布在3、4、5类中。对上述两种分布下的数据集作为训练集分别建模,并采用同样的测试集进行测试。测试集数据规模大小为2000,并在每个类别中分布数量相同,实验结果如下表4。表4不同网络模型相同测试集测试结果在数据充足,在每种类别的数据基本分布均匀的数据集作为训练集,无论是测试数据分布如何,其正确率均为90%以上。对上述两种分布下的数据集作为训练集分别建模,并采用不同的测试集进行测试。测试集数据规模大小为2000,并在每个类别中分布数量相同,实验结果如下表5。表5神经网络规模与测试正确率隐含结点个数对网络模型的影响也是很大的。并不是说隐含结点越多网络越稳定,隐含结点的确定,因研究对象不同而不同,在很多文献中给出了隐含结点的计算公式,这些公式都没有普遍性和通用性。任何研究领域,均需要大量的实验,去确定隐含结点的个数。在本研究中,隐含结点的个数从2开始,逐渐变大的方式进行测试的。当数字较小时,网络模型测试正确率较低,当隐含结点数逐渐增加时,正确率逐渐增加;当增加到一定的程度时,再增加过程中,呈现出来的结果是,测试正确率逐渐下降。并不是说隐含节点数越多越好。以规模为1000的一组训练集为例,确定隐含节点的过程如下表6,随着隐含结点数的增加,误差逐渐减小到一个最小,随后又逐渐增大。表6隐含结点数与误差迭代次数过少或过多都不好,迭代次数过少,跟训练时间过短一样的结果。过早结束训练,得到的网络是不完整的,没有普遍性,迭代过久,有时会过于拟合,反而会造成的结果是测试正确率不高。本发明的数据处理方法的优点在于:其一:数据是正确的经验值,错误的数据训练出来的结论也是错误的;其二:数据必须是在整个研究领域中全面的数据,不能是片面的或局部的,局部数据只能得出局部结论,不代表普遍性;其三,数据的格式符合算法的要求,对数据做格式化处理的必要的,集体放大或集体缩小,都不会影响数据之间的联系和关系的;其四,测试数据的选择也是很重要的,全面的测试,训练出来的模型才有普遍性和泛化能力。以上显示和描述了本发明的基本原理、主要特征及优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。当前第1页1 2 3
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1