一种基于SLAM的视觉感知建图算法及移动机器人的制作方法
本发明涉及视觉感知及移动机器人领域,具体涉及一种基于slam的视觉感知建图算法及移动机器人。
背景技术:
计算机视觉作为人工智能的重要分支,已经从理论逐步走到了实际生产应用中,广泛应用在人脸识别系统、无人驾驶汽车、无人机等高科技产品中。而slam技术极大促进了机器人视觉感知技术的发展,使得机器人能够像人类一样,用眼睛探索周围环境事物并捕捉信息,从而“认识”自己所处的环境。
现有技术中提出一些slam的改进算法或定位算法,但功能不够完善,比如,在实际的机器人及空间环境内,其方案不能做出大范围的地图构建,存在较大漂移,对位姿的估计也不够准确,同时,现有方案需要在完全是静态物体的环境中才能完成地图构建。
技术实现要素:
本发明的目的是提供一种基于slam的视觉感知建图算法及移动机器人,利用slam技术实现机器人在位置环境中构造语义地图并实时定位,同时准确估算自己的位姿。
为了实现上述任务,本发明采用以下技术方案:
一种基于slam的视觉感知建图算法,包括:
利用深度相机获取待建图区域环境的图像数据,并通过编码器获取机器人驱动轮的转速数据;对所述图像数据中的彩色图像进行特征提取;
转速数据根据运动学方程计算处理后,利用通过最小化编码器和重投影误差的方法,将转速数据与所述图像数据中的深度图像一起进行融合并优化,得到机器人的当前帧位姿;
对机器人在待建图区域行走时获取的当前帧图像数据进行筛选,得到关键帧,利用关键帧的彩色图像对环境中的物体进行识别和分类,将分类出的动态物体从关键帧中进行删除,对静态物体进行稀疏化处理,并做局部回环进行校正;
利用关键帧中彩色图像与对应的深度图像的像素点作为地图点,通过八叉树存储地图点并进行建图。
进一步地,所述的转速数据根据运动学方程计算处理,具体包括:
根据机器人的中心在相邻时刻的移动距离,以及机器人相邻时刻的变化角度值,表示出任意时刻机器人的位姿;
给定机器人起始位置的初始协方差矩阵的初值,通过t时刻的协方差矩阵,计算出机器人的左、右驱动轮运动后产生的协方差矩阵,并通过传播误差定律,得出t+1时刻的位姿协方差矩阵,由此得到机器人从当前帧到关键帧的位姿变换表示形式。
进一步地,所述的利用通过最小化编码器和重投影误差的方法,将转速数据与所述图像数据中的深度图像一起进行融合并优化,得到机器人的当前帧位姿,包括:
定义不同的坐标系来表示机器人移动位姿变换,包括世界坐标系、机器人坐标系以及相机坐标系,并计算机器人坐标系中的坐标到世界坐标系中坐标的变换矩阵,由此可得到初始化的机器人位姿;
根据相机投影模型,得到投影像素点在图像中的位置表示;根据局部地图点以及其投影服从高斯分布,得到投影像素点的协方差矩阵;通过投影像素点的协方差矩阵可以得到匹配边界值,在边界值的范围内匹配到正确的2d点坐标,再利用当前帧图像数据中的深度图像中获取的深度值,将彩色图像中的2d点转换为3d点,以实现重投影过程;
将当前帧位姿的求解转化为最小化编码器误差和重投影误差,由此得到当帧的位姿。
进一步地,所述的将当前帧位姿的求解转化为最小化编码器误差和重投影误差,表示为:
其中,eenc表示编码器误差,ei,proj表示重投影误差,r指实数域,分别由以下公式计算:
其中,ρ(·)为huber鲁棒性损失函数,f(·)是将矩阵转化向量的算子,
进一步地,所述的对机器人在待建图区域行走时获取的当前帧图像数据进行筛选,得到关键帧,包括:
条件1:相机获取的当前帧与上一帧关键帧时间间隔有1秒时;
条件2:相机获取的当前帧相对上一帧关键帧移动0.2m或旋转0.5°。
满足上述条件之一的当前帧将作为关键帧保存。
进一步地,所述的利用关键帧的彩色图像对环境中的物体进行识别和分类,包括:
预先利用segnet网络进行预训练,将训练好的模型导入slam系统,利用模型,将环境中的物体进行识别,以区分动态物体和静态物体;
利用二值化对动态物体进行处理,并进行膨胀处理和开、闭运算,以精准提取目标。
进一步地,所述的对静态物体进行稀疏化处理,包括:
记最新的一个关键帧观测方程记为:
z=h(x,y)
其中,h(·)表示观测方程,x表示此时相机的位姿,即相机位姿r,t,转化为对应的李代数为ξ;y表示路标,即三维点p,三维点由彩色图像的特征点加上对应的深度值组组成,观测数据是像素坐标
e=z-h(ξ,p)
考虑不同时刻的观测量,对误差添加下标,设zij为在位姿ξi处观察路标pj产生的数据,eij为对应观测的误差,若步骤7处理后产生的所有关键帧记录有m个位姿,n个路标,则整体的代价函数为:
将上式记为eij,稀疏化问题转化为利用最小二乘法求解eij。
进一步地,对所述图像数据中的彩色图像进行特征提取,包括:
利用fast角点提取算法找到彩色图像中的角点作为特征点,利用灰度质心法为特征点加上方向,使特征点具有旋转不变性形;再通过高斯金字塔算法,对彩色图像做不同尺度的高斯模糊并对彩色图像进行降采样处理,使特征点具有尺度不变性,再以每一个特征点为中心,15个像素为半径的圆内选取256个像素点对建立描述子,比较每组点对a和b的灰度值,a大于b则为1,a小于b则为0,256个点对构成二进制编码作为描述子,从而完成图像特征提取。
一种基于slam的视觉感知移动机器人,包括机器人本体,以及:
数据采集及预处理模块,用于利用深度相机获取待建图区域环境的图像数据,并通过编码器获取机器人驱动轮的转速数据;对所述图像数据中的彩色图像进行特征提取;
数据融合模块,用于将转速数据根据运动学方程计算处理后,利用通过最小化编码器和重投影误差的方法,将转速数据与所述图像数据中的深度图像一起进行融合并优化,得到机器人的当前帧位姿;
语义模块,用于对机器人在待建图区域行走时获取的当前帧图像数据进行筛选,得到关键帧,利用关键帧的彩色图像对环境中的物体进行识别和分类,将分类出的动态物体从关键帧中进行删除,对静态物体进行稀疏化处理,并做局部回环进行校正;
建图模块,用于利用关键帧中彩色图像与对应的深度图像的像素点作为地图点,通过八叉树存储地图点并进行建图。
进一步地,所述的机器人本体,包括:
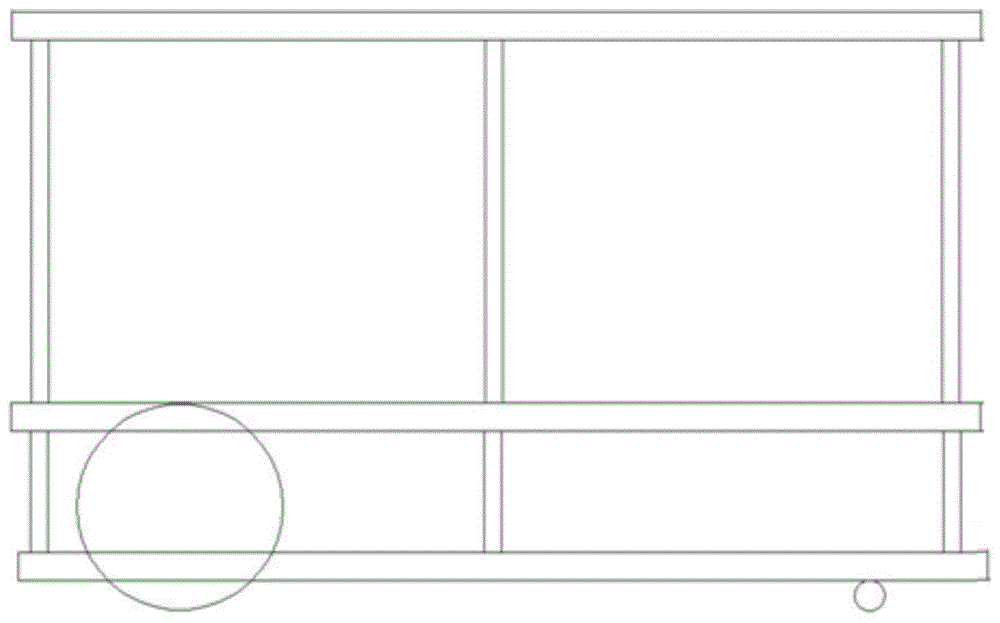
机器人骨架,机器人骨架包括在竖直方向上依次设置的三块支撑板,相邻的支撑板之间通过螺杆连接;在骨架底部前端设置两个能灵活转动的驱动轮,驱动轮通过驱动单元驱动;骨架底部后端设置两个从动轮。
本发明具有以下技术特点:
1.本发明在搭建了自己的机器人装置基础上,对算法进行了优化,所搭建的机器人具有比其他已有机器人更为出色的运算能力,能够运行、调试并修改算法。
2.本发明构建了语义slam算法及系统,结合语义信息,实现了语义slam,能够实现在有动态物体的环境中,剔除动态物体,建立三维地图,在准确构建地图的基础上,对地图中不同物体进行识别标记。
附图说明
图1为机器人结构侧视示意图;
图2为机器人模块连接图;
图3为机器人实物图;
图4为算法流程示意图;
图5为目标识别过程;
图6为语义空间地图。
具体实施方式
第一部分,算法
本发明公开了一种基于slam的视觉感知建图算法,首先将机器人上搭载的深度相机采集的图像数据与机器人驱动轮处安装的编码器采集的转速数据进行数据融合;其中,所采用的kinect2.0相机为深度相机,采集到的图像数据分为彩色图像与深度图像两部分,二者通过统一的时间戳建立对应关系,将彩色图像进行图像特征提取;转速数据根据运动学方程计算处理后,同深度图像一起进行融合并优化,通过最小化编码器和重投影误差,可以得到机器人在某一时刻的位姿,将位姿信息输出;对机器人在待建图区域行走时获取的当前帧图像数据进行筛选,得到关键帧,进行语义建图:首先对彩色图像进行识别,之后对图像整体分割,再对目标处理,即将不同的物体打上不同的标签,之后判断是否为动态物体,是动态物体则剔除,是静态物体则对静态物体稀疏化处理,并做局部回环进行校正,利用关键帧中彩色图像与对应的深度图像的像素点作为地图点,通过八叉树存储地图点并进行建图。具体步骤如下:
步骤1,数据采集
机器人位于待建图区域行走时,利用深度相机采集周围环境的图像数据,并利用编码器获取机器人驱动轮的转速数据。
本方案中采用的深度相机为kinect2.0相机,深度相机和编码器采集的数据会以ros话题的形式发布,则只需要通过监听编码器和深度相机的话题,即可得到图像数据和转速数据。通过ros通讯机制,可以获取图像数据与转速数据进行下一步计算。
步骤2,图像特征提取
对深度相机采集的图像数据(包括深度图像和彩色图像)中每一张彩色图像按照时间顺序依次保存,对每张彩色图像进行特征提取,步骤包括:
利用fast角点提取算法找到彩色图像中的角点作为特征点,利用灰度质心法为特征点加上方向,使特征点具有旋转不变性形;再通过高斯金字塔算法,对彩色图像做不同尺度的高斯模糊并对彩色图像进行降采样处理,使特征点具有尺度不变性,再以每一个特征点为中心,15个像素为半径的圆内选取256个像素点对建立描述子,比较每组点对a和b的灰度值,a大于b则为1,a小于b则为0,256个点对构成二进制编码作为描述子,从而完成图像特征提取。并将图像数据的第一帧初始化为关键帧。
步骤3,转速数据处理
对通过编码器从机器人两个驱动轮上提取的转速数据进行分析,包括:
记机器人左驱动轮处的编码器为l,右轮处编码器记为r,两驱动轮轴距记为b,以两驱动轮中点为原点,建立世界坐标系,其中机器人的正前方为x轴,水平面中垂直x轴的方向为y轴,z轴垂直于x、y轴,机器人移动时,z轴值为常量;记δs表示机器人的中心在相邻时刻的移动距离,δθ表示机器人相邻时刻变化的角度值,δsl、δsr表示机器人左驱动轮、右驱动轮的位移增量,在k时刻,机器人的位姿为ζk=[xk,yk,θk]t,xk,yk指第k时刻机器人移动到的位置在世界坐标系中的坐标,θk为不同时刻δθ的累加,表示第k时刻机器人相对初始位姿旋转了多少角度,则k+1时刻机器人的位姿表示为:
其中:
记机器人起始位置的初始协方差矩阵给定初值为∑0,假设t时刻的协方差矩阵为∑t,kl和kr分别为左轮和右轮的误差常数,对左、右驱动轮运动(δsl,δsr)后产生的协方差矩阵∑δ为:
由传播误差定律得出t+1时刻的位姿协方差矩阵∑t+1为:
∑t+1=gt∑t(gt)t+gδ∑δ(gδ)t式3
其中,gt为式1服从机器人位姿变换的雅克比矩阵,gδ为式1服从(δsl,δsr)t变换的雅克比矩阵。
假设机器人当前帧坐标为{rc},关键帧坐标为{rk},则机器人从当前帧到关键帧的位姿变换
其中,
步骤4,数据融合与优化
本步骤通过最小化编码器和重投影误差来估计机器人当前位姿。
首先需要定义不同的坐标系来表述机器人移动位姿变换,其中,{w}为步骤3建立的世界坐标系,{r}为机器人坐标系,是以机器人自身中心为原点,机器人前进方向为x轴,垂直x轴为y轴建立的坐标系,z轴值为常量;{c}为相机坐标系,是以相机光心为原点,垂直相机平面为z轴,水平方向为x轴,竖直方向为y轴。则机器人在世界坐标系下的位姿可表示为
初始化的机器人位姿
其中,初始化时将图像数据的第一帧设为关键帧,即有rk=rc=r,r表示机器人坐标系下的坐标,rk和rc分别表示此坐标系下的关键帧坐标和当前帧坐标,此时编码器开始记录数据,之后的关键帧根据机器人每前行0.2m或旋转超过0.5°不断保存,记录关键帧的时间戳对应图像数据与转速数据,则有
根据相机投影模型,一个局部地图点wp投影到当前帧,是将一个3d点投影到2d平面点的过程,则投影像素点u在图像中的位置表示为:
其中,π(·)为相机针孔模型,
其中,
其中,ge为式7服从编码器观测变化的雅克比矩阵,
有了上述投影模型的计算,能够保证局部地图点在当前帧中正确、快速的匹配,式10中的∑u可以得到一个匹配边界值,在边界值的范围内匹配到正确的2d点坐标u′,再利用当前帧图像数据中深度图像中获取的深度值,将彩色图像中的2d像素点转换为3d点,从而实现重投影过程,u′深度值为z′,则有:
上述重投影过程中,理论上正确匹配的局部地图点wp和重投影后的局部地图点wp′不会有太大偏差;而对于差距较大的点,认为其是误匹配,须将其剔除。由于局部地图点距离相机的远近不一,即在相机坐标系下的z′值不同,则判别也不同。设wp和wp′之间的距离阈值为dth,若dth<0.2+0.025*z′,则认为合理,否则视为差距较大的点并删除。
通过上述步骤的计算,当前帧位姿
其中,eenc表示编码器误差,ei,proj表示重投影误差,r指实数域,分别由以下公式计算:
其中,ρ(·)为huber鲁棒性损失函数,f(·)是将4x4的矩阵转化为3x1向量的算子,
以上数据融合的过程是将编码器采集到的关于机器人坐标系下坐标变换到世界坐标系下的坐标,与相机采集到的相机坐标系下的坐标到世界坐标系下的坐标变换融合在一起,优化(式12)是对位姿的迭代调整。最终得出机器人在世界坐标系下某时刻的位姿和可以整合出关键帧的数据,即到上一帧关键帧的距离和角度值,并将位姿在地图中标示。
步骤5,关键帧选取
除去步骤2中提到的对关键帧初始化,其余关键帧的选取需要使两帧关键帧之间需要保留足够的时间进行下一步计算,但不能间隔太大,否则导致两帧关键帧之间无法匹配。若:
条件1:相机获取的当前帧与上一帧关键帧时间间隔有1秒时;
条件2:相机获取的当前帧相对上一帧关键帧移动0.2m或旋转0.5°。
满足上述条件之一的当前帧将作为关键帧保存;第一帧关键帧初始化后,步骤3、步骤4、步骤5循环执行。关键帧保存有该帧图像数据的彩色图像、深度图像、计算得出的位姿信息等数据。
步骤6,语义识别、图像处理及目标分割
对上述步骤5得到的关键帧中的彩色图像进行进一步处理,对彩色图像所拍摄的环境中的物体进行识别并分类,主要有语义识别、图像处理、目标分割三部分。需要预先利用segnet网络,对voc2012数据集进行训练,得到收敛的训练模型。本方案中,将segnet训练好的模型导入slam系统,利用模型,将环境中的物体进行识别,可以对人、桌子、椅子等目标做到基本准确的识别。图像处理部分,利用二值化对动态物体,例如:人,进行提取,进行膨胀处理,对识别出的动态目标进行开、闭运算,进一步精准提取目标。
步骤7,动态物体的剔除
对步骤6处理过的关键帧,将已分类好的动态物体,如人等从关键帧中删除,将其他静态物体,例如椅子、桌子、背景等静态物体保留在关键帧中。
步骤8,静态物体稀疏化处理
对于步骤7处理后产生的所有关键帧,记最新的一个关键帧观测方程记为:
z=h(x,y)式15
其中,h(·)表示观测方程,x表示此时相机的位姿,即相机位姿r,t,转化为对应的李代数为ξ;y表示路标,即三维点p,此点由步骤2提取的特征点加上对应的深度值组成,观测数据是像素坐标
e=z-h(ξ,p)式16
考虑不同时刻的观测量,对误差添加下标,设zij为在位姿ξi处观察路标pj产生的数据,eij为对应观测的误差,若步骤7处理后产生的所有关键帧记录有m个位姿,n个路标,则整体的代价函数为:
将上式记为eij,稀疏化问题转化为利用最小二乘法求解eij。最小化eij的过程将不断迭代新插入关键帧的位姿ξ,将此数据优化后,所有存储的关键帧信息传入下一步骤。
步骤9,回环检测
虽然上述步骤已对机器人的位姿进行了修正,但在产生大量关键帧后,还是有可能出现位姿的累积误差,而机器人在室内不断移动,会走到之前的位姿附近,若得到的关键帧与上述模块传入的关键帧有相似的部分,此时触发回环检测,利用dbow2的词袋模型进行新插入关键帧与相似关键帧的匹配,并确定总体的位姿是否有偏移,若有,则修正。修正后的位姿等数据仍保存在关键帧中,进行下一步处理。
步骤10,语义地图构建
经过上述过程修正的关键帧数据已经满足建图要求,此时每一帧关键帧中存储的彩色图像与对应的深度图像的像素点构成世界坐标系下的地图点,即3d点。本算法采用八叉树存储3d点,将每个3d点用一个概率值来表示该像素是否被占据,同时每个3d点经过之前segnet分割后具有颜色信息,不同的颜色表示不同的物体。假设有t=1,2,...,t个时刻,观测的数据为z1,z2,...,zt,那么第n个叶子节点记录的信息的概率为:
其中,p(n)是先验概率,为一个经验值常量,设为0.5,p(n|z1:t-1)是1:t-1时刻所有关键帧对第n个叶子节点的概率累积值,p(n|zt)是t时刻新插入关键帧的第n个叶子节点的概率值,若此节点被占据则为0.61,非占据则为0.45,p(n|z1:t)是1:t时刻所有关键帧对第n个叶子节点的概率累积值,此概率大于0.5则判定此时子节点为占据,并在三维空间中标记颜色,若小于0.5则标记透明,为简化计算,对上式两边取对数可得:
l(n|z1:t)=l(n|z1:t-1)+l(n|zt)式19
经过如上计算后,所有3d点被分为被占据与非占据的状态,所有标示为被占据的3d点组成了空间地图。至此,建图完成。
本发明算法结合segnet语义网络与编码器数据,并做一系列转换,对环境中的物体实现了较好的识别,从而为地图构建提供了准确的静态数据,以对人的识别为例,如图6所示;剔除人并建立语义地图后的空间地图如图6所示;图中所示为实时构建的空间八叉树语义地图,其中,红色部分为对椅子的识别并显示在场景中,此动态场景中的人作为动态物体已被识别剔除,受传感器影响,地图不完全稠密,具有一定稀疏性。地图中处于地板位置的彩色物体为机器人的轨迹及位姿。
第二部分,移动机器人
本发明进一步提出了一种对应于上述算法的移动机器人,如图1所示,包括:
在竖直方向上由三块支撑板平行设置构成的机器人骨架,相邻的支撑板之间通过螺杆连接;在骨架底部前端两侧设置两个驱动轮,驱动轮通过驱动单元驱动,并可以灵活转动,利用两个驱动轮差速转向。骨架底部后端设置两个从动轮,从动轮仅作为支撑用。
最底部的支撑板与中间支撑板之间设置有驱动单元、opencr板、充电电池;
中间支撑板和上部支撑板之间设置微型工作站和电源;
上部支撑板上方安装深度相机及电源线。
在两个驱动轮上各设置一个编码器。
机器人装置搭载ubuntu16.04+kinetic系统,工作站搭载有无线模块,可以在配置后通过网络对机器人进行远程控制,而且可以很方便的远程修改机器人算法。
其中,驱动单元通过杜邦线连接到opencr板引脚,opencr通过可充电电池供电,同时能够使驱动单元工作。opencr板与微型工作站通过usb连接,可以实现数据传递。最顶层的深度相机需利用带有usb3.0及以上接口的数据线连接到工作站。
本实施中,所述的驱动单元采用xm430-w210-t驱动单元,微型工作站采用hpz2mini工作站,深度相机采用kinect2.0深度相机。底部支撑板与中间支撑板之间高度为35mm,中间支撑板和上部支撑板之间高度为105mm。
本装置的优势在于:目前普通的移动机器人大部分都是由树莓派等开发板作为运算主模块,但树莓派运算能力有限,在处理图像运算时,速度很慢,不能够很好的胜任视觉slam的相应运算,在进行了试验之后,发现运算模块可以用工作站来构建,这将极大提高运算能力,在进行了机器人总体架构设计、考虑机器人总体承重后设计了本发明所用的机器人装置。
本发明需要在linux的发行版:ubuntu16.04上运行,在此系统上安装ros机器人操作系统,版本为kinetic利用其通讯架构实现机器人多传感器实时协同工作,同时,本发明算法需要利用gpu加速,本发明的机器人装置中安装有nvidiap1000显卡,安装cuda10.0、cudnn7.6,利用ros通信节点,使算法程序可以利用gpu加速,提升运算速率。
上述机器人结构,在实现本发明算法时,可划分为四大模块:
数据采集及预处理模块、数据融合模块、语义模块以及建图模块,其中数据采集及预处理模块用于实现上述的步骤1至3,数据融合模块用于实现上述的步骤4和5,语义模块用于实现上述的步骤6至9,建图模块对应于上述的步骤10。
- 还没有人留言评论。精彩留言会获得点赞!