确定医保欺诈结果的方法、装置、电子设备及存储介质与流程
本申请涉及医疗数据技术领域,具体而言,本发明涉及一种确定医保欺诈结果的方法、装置、电子设备及存储介质。
背景技术:
随着社会保障制度的发展,具有医保并使用医保就诊的人员越来越多,各人员在各医疗机构使用医保就诊或购买药品时,医疗机构的医疗人员会针对就诊人员的病症信息开出相应的医疗处方或用药信息,以对就诊人员的疾病进行治疗。
由于医保特有的复杂的委托代理关系和严重的信息不对称,使医疗费用控制难度加大,在利益的驱动下就会产生一些过度医疗服务行为和违规欺诈行为,导致医保基金不合理的流失。因此,医保欺诈行为的识别在杜绝医保恶意使用方面显得尤为重要。
技术实现要素:
本申请的目的旨在至少能解决上述的技术缺陷之一。
第一方面,提供了一种确定医保欺诈结果的方法,该方法包括:
获取待预测病例数据,待预测数据包括患者的至少一个属性信息、以及各属性信息的属性值;
确定待预测病例数据所属的目标分类类别,以及目标分类类别对应的欺诈概率;
获取待预测病例数据的各属性信息的属性值所对应的占比,其中,属性值所对应的占比为包含该属性值的参考病例数据中欺诈病例数据所占比例的倒数;
根据目标分类类别对应的欺诈概率、以及各属性信息的属性值所对应的占比,确定待预测病例数据对应的欺诈概率:
基于待预测病例数据对应的欺诈概率,确定待预测病例数据的医保欺诈结果。
第一方面可选的实施例中,确定待预测病例数据所属的目标分类类别之前,还包括:
获取参考病例数据,每个参考病例数据中包括患者的各个属性信息和各属性信息的属性值,每个参考病例数据对应一个欺诈标签,欺诈标签用于表征参考病例数据是否为医保欺诈的病例数据;
对参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类,得到聚类结果,每个聚类结果中包括至少一个属性信息,每个聚类结果对应于一个分类类别;
针对每个属性值,将包含属性值的参考病例数据中属于欺诈病例的数量与包含属性的参考病例数据的数量的比值的倒数作为属性值所对应的占比。
第一方面可选的实施例中,得到聚类结果之后,还包括:
根据每个分类类别中所包括的属性信息,以及预设的分类规则将参考病例数据划分至各分类类别中,分类规则是基于属性信息配置的;
针对每一个分类类别,根据分类类别中包括的参考病例数据所对应的欺诈标签,确定分类类别对应的欺诈概率。
第一方面可选的实施例中,确定待预测病例数据所属的目标分类类别,包括:
根据待预测病例数据中包括的各属性信息、以及每个分类类别中包括的属性信息,确定待预测病例数据所属的目标分类类别。
第一方面可选的实施例中,根据待预测病例数据中包括的各属性信息、以及每个分类类别中包括的属性信息,确定待预测病例数据所属的目标分类类别,包括:
根据待预测病例数据中包括的各属性信息、以及每个分类类别中包括的属性信息,确定待预测病例数据对应于每个分类类别的属性信息交集;
将包括属性信息最多的属性信息交集所对应的分类类别作为待预测病例数据所属的目标分类类别。
第一方面可选的实施例中,对参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类,包括:
基于预设的删除规则对参考病例数据中包括的属性信息和/或属性信息的属性值进行删除,得到删除后的参考病例数据;
对删除后的参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类。
第一方面可选的实施例中,根据目标分类类别对应的欺诈概率、以及各属性信息的属性值所对应的占比,确定待预测病例数据对应的欺诈概率,包括:
将各属性信息的属性值所对应的占比进行乘法运算,得到对应的积;
将目标分类类别对应的欺诈概率与对应的积的比值,作为待预测病例数据对应的欺诈概率。
第二方面,提供了一种确定医保欺诈结果的装置,该装置包括:
数据获取模块,用待预测数据包括患者的至少一个属性信息、以及各属性信息的属性值;
目标分类类别确定模块,用于确定待预测病例数据所属的目标分类类别,以及目标分类类别对应的欺诈概率;
占比获取模块,用于获取待预测病例数据的各属性信息的属性值所对应的占比,其中,属性值所对应的占比为包含该属性值的参考病例数据中欺诈病例数据所占比例的倒数;
欺诈概率确定模块,用于根据目标分类类别对应的欺诈概率、以及各属性信息的属性值所对应的占比,确定待预测病例数据对应的欺诈概率:
欺诈结果确定模块,用于基于待预测病例数据对应的欺诈概率,确定待预测病例数据的医保欺诈结果。
第二方面可选的实施例中,该装置还包括参考病例数据处理模块,具体用于:
在确定待预测病例数据所属的目标分类类别之前,获取参考病例数据,每个参考病例数据中包括患者的各个属性信息和各属性信息的属性值,每个参考病例数据对应一个欺诈标签,欺诈标签用于表征参考病例数据是否为医保欺诈的病例数据;
对参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类,得到聚类结果,每个聚类结果中包括至少一个属性信息,每个聚类结果对应于一个分类类别;
针对每个属性值,将包含属性值的参考病例数据中属于欺诈病例的数量与包含属性的参考病例数据的数量的比值的倒数作为属性值所对应的占比。
第二方面可选的实施例中,参考病例数据处理模块,还用于:
在得到聚类结果之后,根据每个分类类别中所包括的属性信息,以及预设的分类规则将参考病例数据划分至各分类类别中,分类规则是基于属性信息配置的;
针对每一个分类类别,根据分类类别中包括的参考病例数据所对应的欺诈标签,确定分类类别对应的欺诈概率。
第二方面可选的实施例中,目标分类类别确定模块确定待预测病例数据所属的目标分类类别时,具体用于:
根据待预测病例数据中包括的各属性信息、以及每个分类类别中包括的属性信息,确定待预测病例数据所属的目标分类类别。
第二方面可选的实施例中,目标分类类别确定模块在根据待预测病例数据中包括的各属性信息、以及每个分类类别中包括的属性信息,确定待预测病例数据所属的目标分类类别时,具体用于:
根据待预测病例数据中包括的各属性信息、以及每个分类类别中包括的属性信息,确定待预测病例数据对应于每个分类类别的属性信息交集;
将包括属性信息最多的属性信息交集所对应的分类类别作为待预测病例数据所属的目标分类类别。
第二方面可选的实施例中,参考病例数据处理模块在对参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类时,具体用于:
基于预设的删除规则对参考病例数据中包括的属性信息和/或属性信息的属性值进行删除,得到删除后的参考病例数据;
对删除后的参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类。
第二方面可选的实施例中,目标分类类别确定模块在根据目标分类类别对应的欺诈概率、以及各属性信息的属性值所对应的占比,确定待预测病例数据对应的欺诈概率时,具体用于:
将各属性信息的属性值所对应的占比进行乘法运算,得到对应的积;
将目标分类类别对应的欺诈概率与对应的积的比值,作为待预测病例数据对应的欺诈概率。
第三方面,提供了一种电子设备,该电子设备包括:
处理器;以及存储器,该储器配置用于存储机器可读指令,该指令在由该处理器执行时,使得该处理器执行第一方面中的任一项方法。
第四方面,提供了一种计算机可读存储介质,存储有计算机程序,计算机存储介质用于存储计算机指令,当计算机指令在计算机上运行时,使得计算机可以执行第一方面中的任一项方法。
本申请实施例提供的技术方案带来的有益效果是:
在本申请实施例中,可以基于待预测病例数据所属的目标分类类别的欺诈概率,以及包括的各属性值所对应的占比确定出待预测病例数据对应的欺诈概率,然后基于对应的欺诈概率确定待预测病例数据的医保欺诈结果。由于目标分类类别的欺诈概率和各属性值所对应的占比是预先基于大量的数据分析确定出的,可以表征潜在的具有高欺诈概率的病例数据,因此在基于目标分类类别的欺诈概率和各属性值所对应的占比确定待预测病例数据的医保欺诈结果时,可以有效地识别出是否存在医保欺诈行为。
附图说明
为了更清楚地说明本申请实施例中的技术方案,下面将对本申请实施例描述中所需要使用的附图作简单地介绍。
图1为本申请实施例提供的一种确定医保欺诈结果的方法的流程示意图;
图2为本申请实施例提供的一种确定医保欺诈结果的装置的结构示意图;
图3为本申请实施例提供的一种电子设备的结构示意图。
具体实施方式
下面详细描述本申请的实施例,实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本申请,而不能解释为对本发明的限制。
本技术领域技术人员可以理解,除非特意声明,这里使用的单数形式“一”、“一个”、“”和“该”也可包括复数形式。应该进一步理解的是,本申请的说明书中使用的措辞“包括”是指存在特征、整数、步骤、操作、元件和/或组件,但是并不排除存在或添加一个或多个其他特征、整数、步骤、操作、元件、组件和/或它们的组。应该理解,当我们称元件被“连接”或“耦接”到另一元件时,它可以直接连接或耦接到其他元件,或者也可以存在中间元件。此外,这里使用的“连接”或“耦接”可以包括无线连接或无线耦接。这里使用的措辞“和/或”包括一个或更多个相关联的列出项的全部或任一单元和全部组合。
为使本申请的目的、技术方案和优点更加清楚,下面将结合附图对本申请实施方式作进一步地详细描述。
医疗保险欺诈包括欺诈和滥用两种行为。首先,目前的医保反欺诈方案,往往只限定于针对欺诈,而缺乏对滥用的监管。其次,目前的医保反欺诈方案的往往从单一检查来说,大量的疾病不在判断范围内,且都是针对已经有大量样本的疾病,对于小样本的疾病必须依靠医生进行判断,在没有医生的情况下,无法给出任何有参考价值的诊断选择。其次,大多数的反欺诈内容都是来自于规则的导入,但在很多场景下该规则并不能适用,且规则只能面向已经多次发生,成熟总结的情况,而大多数的欺诈方法在不断改变进步,来不及人工总结规则。
本申请提供的确定医保欺诈结果的方法、装置、电子设备及存储介质,旨在解决如上现有技术中的至少一项的技术问题。
下面以具体地实施例对本申请的技术方案以及本申请的技术方案如何解决上述技术问题进行详细说明。下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例中不再赘述。下面将结合附图,对本申请的实施例进行描述。
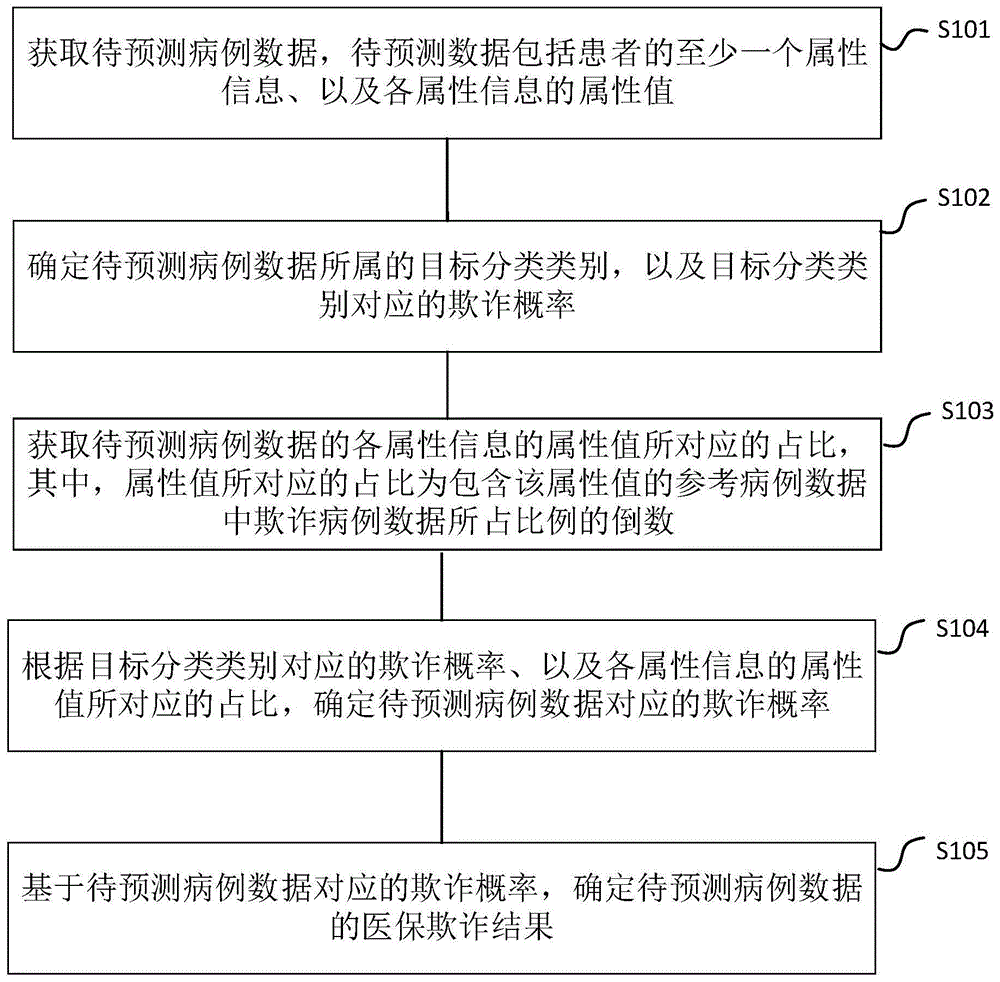
本申请实施例提供了一种确定医保欺诈结果的方法,如图1所示,该方法包括:
步骤s101,获取待预测病例数据,获取待预测病例数据,待预测数据包括患者的至少一个属性信息、以及各属性信息的属性值。
其中,待预测数据指的是需要确定是否为用于骗取医疗保险费用的病例数据。在实际应用中,待预测数据中可以包括患者的各个属性信息,以及患者对应于各属性信息的属性值。其中,患者的属性信息可以包括年龄、职业、性别、医保机构名称等信息,各属性信息的属性值是患者可能对应于每种属性信息的实际当情况,如当属性信息为性别时,对应于的属性值包括男和女,当属性信息为职业时,对应于的属性值可以包括医生、老师和学生等。
步骤s102,确定待预测病例数据所属的目标分类类别,以及目标分类类别对应的欺诈概率。
其中,欺诈概率指的是存在骗取医疗保险费用行为的可能性。在实际应用中,可以预先划分得到至少一个分类类别,并确定每一个分类类别所对应的欺诈概率。相应的,在获取到待预测数据后可以将该待预测数据划分至一个分类类别中,此时,被划分至的分类类别即为待预测病例数据所属的目标分类类别,并由每一个分类类别所对应的欺诈概率,得到目标分类类别对应的欺诈概率。
在本申请实施例中,确定待预测病例数据所属的目标分类类别,包括:
根据待预测病例数据中包括的各属性信息、以及每个分类类别中包括的属性信息,确定待预测病例数据所属的目标分类类别。
在实际应用中,依据各分类类别中所包括的属性信息和待预测病例数据中所包括的属性信息,将待预测病例数据划分至与其属性信息匹配度最高的分类类别中,将该匹配度最高的分类类别作为待预测病例数据所属的目标分类类别。
在本申请实施例中,根据待预测病例数据中包括的各属性信息、以及每个分类类别中包括的属性信息,确定待预测病例数据所属的目标分类类别,包括:
根据待预测病例数据中包括的各属性信息、以及每个分类类别中包括的属性信息,确定待预测病例数据对应于每个分类类别的属性信息交集;
将包括属性信息最多的属性信息交集所对应的分类类别作为待预测病例数据所属的目标分类类别。
在实际应用中,可以确定待预测病例数据包括的属性信息与每个分类类别包括的各属性信息的属性信息交集,该交集中包括的属性信息是待预测数据与分类类别中均包括的属性信息,然后将包括属性信息最多的属性信息交集所对应的分类类别作为待预测病例数据所属的目标分类类别,也就是说,当分类类别对应的属性信息交集中包括的属性信息越多时,该分类类别与预测病例数据的匹配度越高。
在一示例中,假如获取到的待预测病例数据包括的属性信息包括性别、职业和机构,且已知职业和机构属于第一分类类别,年龄和性别属于第二分类类别。在确定待预测病例数据所属的目标分类类别时,由于待预测数据包括的属性信息为性别、职业和机构,此时与第一分类类别中匹配的属性信息为职业和机构(即两个属性信息匹配),与第二分类类别中匹配的属性信息为性别(即一个属性信息匹配),显然,待预测病例数据中的属性信息与第一分类类别中的属性信息匹配度最高,则可以确定待预测病例数据所属的目标分类类别为第一分类类别。
步骤s103,获取待预测病例数据的各属性信息的属性值所对应的占比,其中,属性值所对应的占比为包含该属性值的参考病例数据中欺诈病例数据所占比例的倒数。
其中,属性值所对应的占比为包含该属性值的参考病例数据中欺诈病例数据所占比例的倒数。也就是说,在确定某一属性值所对应的占比时可以先确定包含该属性值的病例数据中欺诈病例数据所占比例,然后将包含该欺诈病例数据所占比例进行取倒数运算即可得到该属性值对应的占比。其中,包含该属性值的病例数据指的是如果一个病例数据中包括该属性值即可,不限定是否包含其他的属性值,如某一属性值为男,病例数据1中包括的属性值包括男、医生和年龄50,此时该病例数据1即为包含属性值为男的病例数据。在一示例中,假如待预测病例数据中包括的属性值为男和医生,此时需要分别确定属性值男所对应的占比,属性值医生所对应的占比。
步骤s104,根据目标分类类别对应的欺诈概率、以及各属性信息的属性值所对应的占比,确定待预测病例数据对应的欺诈概率。
其中,待预测病例数据对应的欺诈概率指的是该待预测数据被用于骗取医疗费用的病例数据的可能性。而在实际应用中,根据目标分类类别对应的欺诈概率、以及各属性信息的属性值所对应的占比,确定待预测病例数据对应的欺诈概率的具体实现方式,本申请实施例不做限定。
作为一种可选的实施方式,根据目标分类类别对应的欺诈概率、以及各属性信息的属性值所对应的占比,确定待预测病例数据对应的欺诈概率,包括:
将各属性信息的属性值所对应的占比进行乘法运算,得到对应的积;
将目标分类类别对应的欺诈概率与对应的积的比值,作为待预测病例数据对应的欺诈概率。
在实际应用中,可以将确定的待预测病例数据包括的各属性信息的属性值所对应的占比进行乘法运算,得到对应的积,然后将目标分类类别对应的欺诈概率与得到的积的比值作为待预测病例数据对应的欺诈概率。
在一示例中,假如获取到的待预测数据包括属性信息的为性别、职业和医保机构,且该待预测病例数据包括的患者对应于性别的属性值为男、对应于职业的属性值为医生,对应于医保机构的属性为机构a,并且待预测数据所属的目标分类类别为第一分类类别。进一步的,可以获取到第一分类类别对应的欺诈概率为pi,以及属性值男所对应的占比为α男,属性值医保机构a所对应的占比为α机构a,属性值医生对应的占比为α医生),此时,可以确定待预测病例数据对应的欺诈概率为pi’,其中pi’=pi/(α男*α机构a*α医生)。
步骤s105,基于待预测病例数据对应的欺诈概率,确定待预测病例数据的医保欺诈结果。
在实际应用中,可以根据待预测病例数据对应的欺诈概率确定待预测病例数据的医保欺诈结果,即确定该待预测病例数据是否为用于骗取医保费用的病例数据。
其中,基于待预测病例数据对应的欺诈概率确定待预测病例数据的医保欺诈结果的实现方式本申请实施例不做限定,如当待预测病例数据对应的欺诈概率超过预设阈值时,则确定该待预测病例数据为用于骗取医保费用的病例数据。
在本申请实施例中,可以基于待预测病例数据所属的目标分类类别的欺诈概率,以及包括的各属性值所对应的占比确定出待预测病例数据对应的欺诈概率,然后基于对应的欺诈概率确定待预测病例数据的医保欺诈结果。由于目标分类类别的欺诈概率和各属性值所对应的占比是预先基于大量的数据分析确定出的,可以表征潜在的具有高欺诈概率的病例数据,因此在基于目标分类类别的欺诈概率和各属性值所对应的占比确定待预测病例数据的医保欺诈结果时,可以有效地识别出是否存在医保欺诈行为。
在本申请实施例中,确定待预测病例数据所属的目标分类类别之前,还包括:
获取参考病例数据,每个参考病例数据中包括患者的各个属性信息和各属性信息的属性值,每个参考病例数据对应一个欺诈标签,欺诈标签用于表征参考病例数据是否为医保欺诈的病例数据;
对参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类,得到聚类结果,每个聚类结果中包括至少一个属性信息,每个聚类结果对应于一个分类类别;
针对每个属性值,将包含属性值的参考病例数据中属于欺诈病例的数量与包含属性的参考病例数据的数量的比值的倒作为属性值所对应的占比。
其中,参考病例数据为样本数据,用于确定各分类类别的数据,参考病例数据中可以包括患者的各个属性信息,以及患者对应于各个属性信息的属性值,并且每个参考病例数据对应一个欺诈标签,该欺诈标签用于表征参考病例数据是否被用于骗取医保费用的欺诈病例数据,也就说当某个参考病例数据是用于骗取医保费用的病例数据时,该考病例数据可以对应于一个用于表示为欺诈病例的欺诈标签。
在实际应用中,可以基于预设的聚类规则后对参考病例数据中包括的的各个属性信息进行聚类,得到聚类结果。其中,每个聚类结果对应一个分类类别,且每个聚类结果中包括至少一个属性信息。
其中,获取到的参考病例数据的数量、预设的聚类规则、以及具体的聚类方式不做限定。例如,预设的聚类规则可以预先确定每个聚类结果中所包括的属性信息共同具备的特点,然后将每个聚类结果中所包括的属性信息共同具备的特点作为聚类的参数,然后基于聚类的参数进行聚类。而聚类方式可以采用knn(k-nearestneighbor,邻近算法)进行聚类,属性信息采用中文表示时可以采用word2vector(词向量)技术进行聚类等。
在一示例中,假如获取到1000份参考病例数据,该1000份参考病例数据包括的患者的属性信息为年龄、性别、职业和医保机构这四种,此时可以基于预设的聚类规则采用knn聚类方式对年龄、性别、职业和机构这四个属性信息进行聚类,得到2种聚类结果,第一种聚类结果包括年龄和性别、第二种聚类结果包括职业和医保机构,并将每个聚类结果对应为一个分类类别,此时包括两个分类类别,即将年龄和性别划分为一个分类类别,将职业和机构划分为一个分类类别。
在实际应用中,针对每个属性值,还可以统计每个属性值对应的占比,而每个属性值对应的占比占比为包含该属性值的参考病例数据中属于欺诈病例的数量与包含该属性值的参考病例数据的数量的比值的倒数。
在一示例中,假如参考病例数据为10000份,所包括的属性信息为性别和职业。当患者的属性信息为性别时,可能包括男和女两种属性值,其中,有5000份参考病例数据中性别的属性值为男,有5000份参考病例数据中性别的属性值为为女,在包括属性值男的5000份参考病例数据中40份病例为用于骗取医保费用的病例数据(即欺诈病例数据),则包含属性值男的参考病例数据为欺诈病例数据的概率为40/5000,在包括属性值女的5000份参考病例数据中有20份病例为欺诈病例数据,则包含属性值女的参考病例数据为欺诈病例数据的概率为20/5000,此时,属性值男对应的占比为α男=5000/40,属性值女对应的占比为α女=5000/20;当患者的属性信息为职业时:包括医生和老师两种属性值,其中有8000份参考病例数据中职业的属性值为医生,2000份参考病例数据中职业的属性值为老师,在包括属性值医生的参考病例数据病例中有50份病例为欺诈病例数据,则包含属性值医生的参考病例数据为欺诈病例数据的概率为50/8000,在包括属性值老师的参考病例数据病例中有10份病例为欺诈病例数据,则包含属性值老师的参考病例数据为欺诈病例数据的概率为10/2000,此时属性值医生对应的占比为α医生=8000/50,属性值老师对应的占比为α老师=2000/10。
在实际应用中,若某一个属性信息中的某一种属性值所包括的全部参考病例数据中不存在欺诈病例数据,此时该属性值所对应的占比为包含该属性值的参考病例数据的数量。
在一示例中,假如属性信息为医保机构时,包括医保机构a和医保机构b两种属性值,其中有6000份参考病例数据包括属性值医保机构a,有4000份参考病例数据包括属性值医保机构b,在包括属性值医保机构a的参考病例数据中有50份病例为欺诈病例数据,此时包括属性值医保机构a的参考病例数据为欺诈病例数据的概率为50/6000,属性值医保机构a对应的占比为α机构a=6000/50,在包括属性值医保机构b的参考病例数据中没有欺诈病例数据,此时包括属性值医保机构b的参考病例数据为欺诈病例数据的概率为0,则属性值机构b对应的占比为α机构b=6000。
在本申请实施例中,对参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类,包括:
基于预设的删除规则对参考病例数据中包括的属性信息和/或属性信息的属性值进行删除,得到删除后的参考病例数据;
对删除后的参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类。
其中,预设的删除规则的具体内容,本申请实施例不做限定。如,在实际应用中,如对于已经存在骗取医疗费用的医保机构a(即医保机构的属性值为医保机构a),执法机关可能增强对于医保机构a的监管,该医保机构a反而未来可能下降欺诈概率,此时可以将包括属性值为医保机构a的参考病例数据中的属性值医保机构a删除,并将删除属性值医保机构a这一部分参考病例数据与不包含属性值医保机构a的参考病例数据作为删除后的参考病例数据,然后对删除后的参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类,得到聚类结果。
在实际应用中,若已经获知各属性值所对应的占比,还可以根据属性值所对应的占比确定删除规则,如当同一属性信息中包括的各属性值所对应的占比相同时,将参考病例数据中该属性信息以及患者对应的属性值删除,并将删除属性信息以及患者对应的属性值的这一部分参考病例数据与不包含该属性信息的参考病例数据作为删除后的参考病例数据,然后对删除后的参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类,得到聚类结果。
在一示例中,假如获取到1000份参考病例数,包括的属性信息为性别,且性别对应的属性值为男和女,而确定属性值男对应的占比与属性值女对应的占比也相同,且1000份参考病例数据中有500份参考病例数据中包括性别以及患者对应于性别的属性值,有500份参考病例数据中不包括性别以及患者对应于性别的属性值,此时将500份参考病例数据中关于性别和患者对应于性别的属性值删除,并将删除后的该500参考病例数据与该500份不包括性别以及患者对应于性别的属性值的参考病例数据作为删除后的参考病例数据。
本申请实施例中,得到聚类结果之后,还包括:
根据每个分类类别中所包括的属性信息,以及预设的分类规则将参考病例数据划分至各分类类别中,分类规则是基于属性信息配置的;
针对每一个分类类别,根据分类类别中包括的参考病例数据的欺诈标签,确定分类类别对应的欺诈概率。
其中,分类规则的具体内容本申请实施例不做限定,如可以依据各分类类别中所包括的属性信息和参考病例数据所包括的属性信息,将参考病例数据划分至与其属性信息匹配度最高的分类类别中。此外,每个分类类别中包括的参考病例数据各不相同,即一个参考病例数据仅能划分至一个分类类别中。
在一示例中,假如基于获取到1000份参考病例数据,且得到2种聚类结果,第一分类类别包括年龄和性别、第二分类类别包括职业和机构。其中,有300份参考病例数据中的属性信息仅包括年龄和性别,有300份参考病例数据中的属性信息仅包括职业和机构,有400份参考病例数据中的属性信息包括年龄、性别和机构,此时可以将仅包括年龄和性别的300份参考病例数据和包括年龄、性别、机构的400份参考病例数据划分至第一分类类别中,包括职业和机构的300份参考病例数据划分至第二分类类别中。
进一步的,由于每个参考病例数据对应于一个欺诈标签,在将获取到的参考病例数据划分至各分类类别中后,可以根据参考病例数据的欺诈标签,统计每个分类类别所包括的参考病例数据中为欺诈病例数据的数据与包括的所有参考病例数据的数量的比值,将该比值作为分类类别对应的欺诈概率。
在一示例中,假如分类类别包括第一分类类别和第二分类类别,获取到的参考病例数据为1000份,其中有600分参考病例数据划分至第一分类类别,400分参考病例数据划分至第二分类类别。针对第一分类类别中的600份参考病例中有50份参考病例数据的欺诈标签表征为用于骗取医保费用的病例数据,此时第一分类类别对应的欺诈概率为50/600=8.33%;针对第二分类类别中的400份参考病例中有20份参考病例数据的欺诈标签表征为用于骗取医保费用的病例数据,此时第二分类类别对应的欺诈概率为20/400=5%。
图2为本申请实施例提供的一种确定医保欺诈结果的装置的结构示意图,如图2所示,本实施例的装置可以包括:数据获取模块601、目标分类类别确定模块602、占比获取模块603、欺诈概率确定模块604和欺诈结果确定模块605,其中:
数据获取模块601,用待预测数据包括患者的至少一个属性信息、以及各属性信息的属性值;
目标分类类别确定模块602,用于确定待预测病例数据所属的目标分类类别,以及目标分类类别对应的欺诈概率;
占比获取模块603,用于获取待预测病例数据的各属性信息的属性值所对应的占比,其中,属性值所对应的占比为包含该属性值的参考病例数据中欺诈病例数据所占比例的倒数;
欺诈概率确定模块604,用于根据目标分类类别对应的欺诈概率、以及各属性信息的属性值所对应的占比,确定待预测病例数据对应的欺诈概率:
欺诈结果确定模块605,用于基于待预测病例数据对应的欺诈概率,确定待预测病例数据的医保欺诈结果。
本申请可选的实施例中,该装置还包括参考病例数据处理模块,具体用于:在确定待预测病例数据所属的目标分类类别之前,获取参考病例数据,每个参考病例数据中包括患者的各个属性信息和各属性信息的属性值,每个参考病例数据对应一个欺诈标签,欺诈标签用于表征参考病例数据是否为医保欺诈的病例数据;
对参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类,得到聚类结果,每个聚类结果中包括至少一个属性信息,每个聚类结果对应于一个分类类别;
针对每个属性值,将包含属性值的参考病例数据中属于欺诈病例的数量与包含属性的参考病例数据的数量的比值的倒数作为属性值所对应的占比。
本申请可选的实施例中,参考病例数据处理模块,还用于:
在得到聚类结果之后,根据每个分类类别中所包括的属性信息,以及预设的分类规则将参考病例数据划分至各分类类别中,分类规则是基于属性信息配置的;
针对每一个分类类别,根据分类类别中包括的参考病例数据所对应的欺诈标签,确定分类类别对应的欺诈概率。
本申请可选的实施例中,目标分类类别确定模块确定待预测病例数据所属的目标分类类别时,具体用于:
根据待预测病例数据中包括的各属性信息、以及每个分类类别中包括的属性信息,确定待预测病例数据所属的目标分类类别。
本申请可选的实施例中,目标分类类别确定模块在根据待预测病例数据中包括的各属性信息、以及每个分类类别中包括的属性信息,确定待预测病例数据所属的目标分类类别时,具体用于:
根据待预测病例数据中包括的各属性信息、以及每个分类类别中包括的属性信息,确定待预测病例数据对应于每个分类类别的属性信息交集;
将包括属性信息最多的属性信息交集所对应的分类类别作为待预测病例数据所属的目标分类类别。
本申请可选的实施例中,参考病例数据处理模块在对参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类时,具体用于:
基于预设的删除规则对参考病例数据中包括的属性信息和/或属性信息的属性值进行删除,得到删除后的参考病例数据;
对删除后的参考病例数据中包括的各个属性信息基于预设的聚类规则进行聚类。
本申请可选的实施例中,目标分类类别确定模块在根据目标分类类别对应的欺诈概率、以及各属性信息的属性值所对应的占比,确定待预测病例数据对应的欺诈概率时,具体用于:
将各属性信息的属性值所对应的占比进行乘法运算,得到对应的积;
将目标分类类别对应的欺诈概率与对应的积的比值,作为待预测病例数据对应的欺诈概率。
本实施例的确定医保欺诈结果的装置可执行本申请实施所示的确定医保欺诈结果的方法,其实现原理相类似,此处不再赘述。
本申请实施例提供了一种电子设备,如图3所示,图3所示的电子设备2000包括:处理器2001和存储器2003。其中,处理器2001和存储器2003相连,如通过总线2002相连。可选地,电子设备2000还可以包括收发器2004。需要说明的是,实际应用中收发器2004不限于一个,该电子设备2000的结构并不构成对本申请实施例的限定。
其中,处理器2001应用于本申请实施例中,用于实现图2所示的各模块的功能。
处理器2001可以是cpu,通用处理器,dsp,asic,fpga或者其他可编程逻辑器件、晶体管逻辑器件、硬件部件或者其任意组合。其可以实现或执行结合本申请公开内容所描述的各种示例性的逻辑方框,模块和电路。处理器2001也可以是实现计算功能的组合,例如包含一个或多个微处理器组合,dsp和微处理器的组合等。
总线2002可包括一通路,在上述组件之间传送信息。总线2002可以是pci总线或eisa总线等。总线2002可以分为地址总线、数据总线、控制总线等。为便于表示,图3中仅用一条粗线表示,但并不表示仅有一根总线或一种类型的总线。
存储器2003可以是rom或可存储静态信息和指令的其他类型的静态存储设备,ram或者可存储信息和指令的其他类型的动态存储设备,也可以是eeprom、cd-rom或其他光盘存储、光碟存储(包括压缩光碟、激光碟、光碟、数字通用光碟、蓝光光碟等)、磁盘存储介质或者其他磁存储设备、或者能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。
存储器2003用于存储执行本申请方案的应用程序代码,并由处理器2001来控制执行。处理器2001用于执行存储器2003中存储的应用程序代码,以实现图2所示实施例提供的确定医保欺诈结果的装置的动作。
本申请实施例提供了一种电子设备,本申请实施例中的电子设备包括:处理器;以及存储器,存储器配置用于存储机器可读指令,该指令在由该处理器执行时,使得该处理器执行的确定医保欺诈结果的方法。
本申请实施例提供了一种计算机可读存储介质,该计算机可读存储介质上用于存储计算机指令,当计算机指令在计算机上运行时,使得计算机可以执行实现确定医保欺诈结果的方法。
本申请中的一种计算机可读存储介质所涉及的名词及实现原理具体可以参照本申请实施例中的一种确定医保欺诈结果的方法,在此不再赘述。
应该理解的是,虽然附图的流程图中的各个步骤按照箭头的指示依次显示,但是这些步骤并不是必然按照箭头指示的顺序依次执行。除非本文中有明确的说明,这些步骤的执行并没有严格的顺序限制,其可以以其他的顺序执行。而且,附图的流程图中的至少一部分步骤可以包括多个子步骤或者多个阶段,这些子步骤或者阶段并不必然是在同一时刻执行完成,而是可以在不同的时刻执行,其执行顺序也不必然是依次进行,而是可以与其他步骤或者其他步骤的子步骤或者阶段的至少一部分轮流或者交替地执行。
以上仅是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!