一种大数据的同步策略的制作方法
本发明涉及数据同步处理技术领域,具体领域为一种大数据的同步策略。
背景技术:
在数据处理领域,通常需要进行数据的读取、数据筛洗,同步等过程。其中原始数据的存档通常存储在mysql、sqlserver、postgresql;
对于不同的数据源拥有者,一般是不会共享原始数据,原始数据也基本不能直接使用;
传统的大数据同步策略通常情况下,一次性将变动的数据通过接口的方式推送过来,造成数据量过大,影响现有的系统的健康运行,同时也影响现有的业务的正常运行。边同步边运行势必会造成脏数据的产生,对于业务的执行造成难以挽回的错误和损失。
技术实现要素:
本发明的目的在于提供一种大数据的同步策略,以解决现有技术中大数据处理过程中数据错误的问题。
为实现上述目的,本发明提供如下技术方案:一种大数据的同步策略,包括本方数据源和第三方数据源,第三方数据源包括有多种数据源,
数据源同步具体处理步骤为:
(1)基于分布式的计算任务分析数据分组,并与相对应的第三方数据源进行匹配;
(2)根据数据更新日期进行增量数据约定更新;
(3)针对人的操作行为分析,根据增量数据的峰谷值判断进行相应时间段内数据同步;
(4)在完成相应时间段内的数据同步后,将数据同步完成的结束时间固化传到本方数据源的数据库内;
(5)根据步骤(4)中的结束时间作为下一个时间段的开始时间;
(6)在相同时间段内同步的多种数据源的数据,进行同一份时间段内数据管理;
(7)同步的多种数据源的数据,根据预设的策略进行相应的分表数据库管理;
(8)在数据发生错误时,数据在下次同步任务时,根据该数据库中最后一次固化的结束时间进行,本次同步时间段内的开始时间。
优选的,根据步骤(3),其具体方式为:将增量的数据拆分成峰谷值连续时间段内的数据;
针对峰值的数据时间段设置为较小数据量进行同步;
针对谷值的数据时间段设置为较大数据量进行同步。
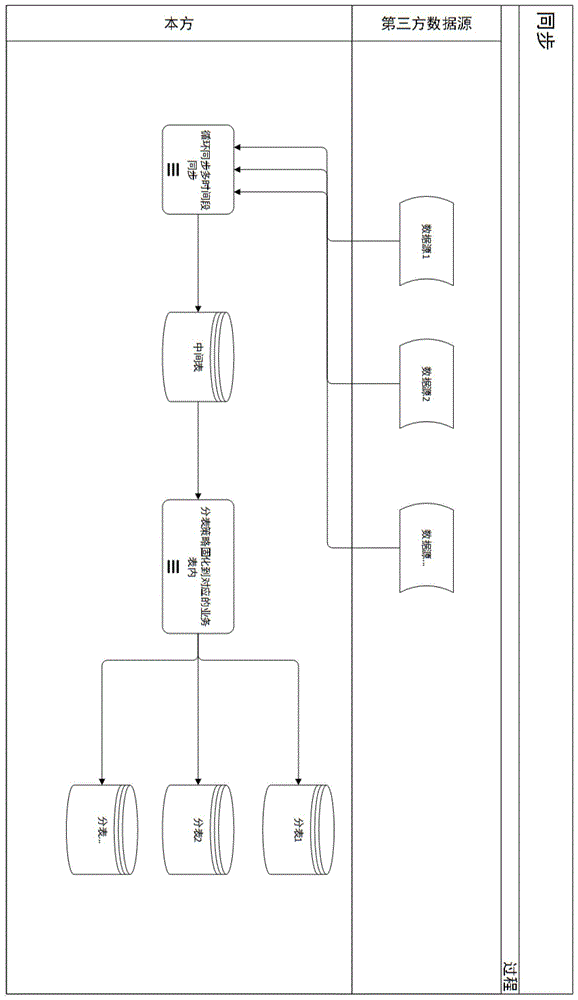
优选的,本方数据源包括循环同步和多时间段同步、中间表数据库、分表策略、分表数据库,
循环同步和多时间段同步对第三方数据源进行增量数据更新同步;
同步的数据传输到中间表数据库,通过分表策略将中间表数据库中的数据进行相应分别策略规则固化到对应的业务分表数据库内。
与现有技术相比,本发明的有益效果是:在同步大数据时做到服务的稳定性、可连续性、精准性,通过分组分次的同步策略能够保障在同步大数据时,既不影响在正常时间的业务的运行,又能把海量的数据同步过来作为业务的基础数据。
附图说明
图1为本发明的原理框图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,本发明提供一种技术方案:一种大数据的同步策略,包括本方数据源和第三方数据源,本方数据源包括循环同步和多时间段同步、中间表数据库、分表策略、分表数据库,第三方数据源包括有多种数据源,
数据源同步具体处理步骤为:
(1)基于分布式的计算任务分析数据分组,并与相对应的第三方数据源进行匹配;
(2)根据数据更新日期进行增量数据约定更新;
(3)针对人的操作行为分析,根据增量数据的峰谷值判断进行相应时间段内数据同步;
(4)在完成相应时间段内的数据同步后,将数据同步完成的结束时间固化传到本方数据源的数据库内;
(5)根据步骤(4)中的结束时间作为下一个时间段的开始时间;
每个时间段的同步完成,都会把该时间段的结束时间固化到数据库内,作为下个时间段的开始时间,对于固化的时间段是同时间段内,所有的数据源使用同一份时间段,这样便于管理实现。
(6)在相同时间段内同步的多种数据源的数据,进行同一份时间段内数据管理;
(7)同步的多种数据源的数据,根据预设的策略进行相应的分表数据库管理;
同步这些数据都是放入中间表内,通过分表的策略放入不同的对应的表内。
(8)在数据发生错误时,数据在下次同步任务时,根据该数据库中最后一次固化的结束时间进行,本次同步时间段内的开始时间。
中间任何的过程遇到任何错误或者是意外中断了,下次同步任务还能从固化的表内拿到最后一次同步的截止时间来作为本次同步时间段的开始时间。
根据步骤(3),其具体方式为:将增量的数据拆分成峰谷值连续时间段内的数据;
针对峰值的数据时间段设置为较小数据量进行同步;
针对谷值的数据时间段设置为较大数据量进行同步。
本方数据源包括循环同步和多时间段同步、中间表数据库、分表策略、分表数据库,
循环同步和多时间段同步对第三方数据源进行增量数据更新同步;
同步的数据传输到中间表数据库,通过分表策略将中间表数据库中的数据进行相应分别策略规则固化到对应的业务分表数据库内。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
技术特征:
1.一种大数据的同步策略,其特征在于:包括本方数据源和第三方数据源,第三方数据源包括有多种数据源,
数据源同步具体处理步骤为:
(1)基于分布式的计算任务分析数据分组,并与相对应的第三方数据源进行匹配;
(2)根据数据更新日期进行增量数据约定更新;
(3)针对人的操作行为分析,根据增量数据的峰谷值判断进行相应时间段内数据同步;
(4)在完成相应时间段内的数据同步后,将数据同步完成的结束时间固化传到本方数据源的数据库内;
(5)根据步骤(4)中的结束时间作为下一个时间段的开始时间;
(6)在相同时间段内同步的多种数据源的数据,进行同一份时间段内数据管理;
(7)同步的多种数据源的数据,根据预设的策略进行相应的分表数据库管理;
(8)在数据发生错误时,数据在下次同步任务时,根据该数据库中最后一次固化的结束时间进行,本次同步时间段内的开始时间。
2.根据权利要求1所述的一种大数据的同步策略,其特征在于:根据步骤(3),其具体方式为:将增量的数据拆分成峰谷值连续时间段内的数据;
针对峰值的数据时间段设置为较小数据量进行同步;
针对谷值的数据时间段设置为较大数据量进行同步。
3.根据权利要求1所述的一种大数据的同步策略,其特征在于:本方数据源包括循环同步和多时间段同步、中间表数据库、分表策略、分表数据库,
循环同步和多时间段同步对第三方数据源进行增量数据更新同步;
同步的数据传输到中间表数据库,通过分表策略将中间表数据库中的数据进行相应分别策略规则固化到对应的业务分表数据库内。
技术总结
本发明涉及数据同步处理技术领域,尤其是一种大数据的同步策略,包括本方数据源和第三方数据源,第三方数据源包括有多种数据源,具体处理步骤为:分析数据分组,并与相对应的第三方数据源进行匹配;针对人的操作行为分析,根据增量数据的峰谷值判断进行相应时间段内数据同步;在完成相应时间段内的数据同步后,数据同步完成的结束时间固化传到本方数据源的数据库内;在相同时间段内同步的多种数据源的数据,进行同一份时间段内数据管理;同步的多种数据源的数据,根据预设的策略进行相应的分表数据库管理;在数据发生错误时,数据在下次同步任务根据最后一次固化的结束时间进行本次同步的开始时间,本发明能够到服务的稳定性、可连续性、精准性。
技术研发人员:张福军;陆昕;鲍碧波;蔡永干
受保护的技术使用者:绿漫科技有限公司
技术研发日:2019.11.22
技术公布日:2020.04.28
- 还没有人留言评论。精彩留言会获得点赞!