一种基于深度学习的圆形表盘旋转矫正方法与流程
本发明涉及信息技术领域,特别涉及一种基于深度学习的圆形表盘旋转矫正方法。
背景技术:
深度学习或阶层学习是机器学习的技术和研究领域之一,通过建立具有阶层结构的人工神经网络,在计算机系统中实现人工智能。深度学习的应用领域十分广泛,其中包括了计算机视觉、自然语言处理、生物信息学、自动控制等,尤其是在计算机视觉领域,深度学习的成果十分丰富,其中,目标检测就是一个很成功的研究领域,目标检测的目的是为了检索出图像中特定物体的位置并标记该特定物体,由于这个特性,目标检测也可以应用于圆形表盘的旋转矫正中来。
文本识别是目标检测中一个重要的子领域,跟传统的ocr技术技术相比,基于深度学习的文本识别模型的抗干扰能力更强,能应对复杂的环境因素,例如光照、模糊、阴影等环境干扰因素,因此鲁棒性更强。
指针式仪表由于结构简单,价格低廉,维护方便,抗电磁干扰能力强等特点,在社会生产行业中广泛使用。目前也有较多针对表盘示数自动读取的方法,大多数示数识别的方法都是针对不带角度的正面表盘图像进行的。上述情况较为理想,在实际生产中,拍摄的图片往往都存在旋转角度上的偏差,这对读数识别带来了干扰。目前解决旋转角度问题的方法大多基于霍夫变换以及最小刻度或最大刻度来进行表盘旋转角度的矫正,这类方法存在精度不高、系统鲁棒性不强等问题。
技术实现要素:
本发明的目的是提供一种基于深度学习的圆形表盘旋转矫正方法,以解决现有技术中存在的问题。
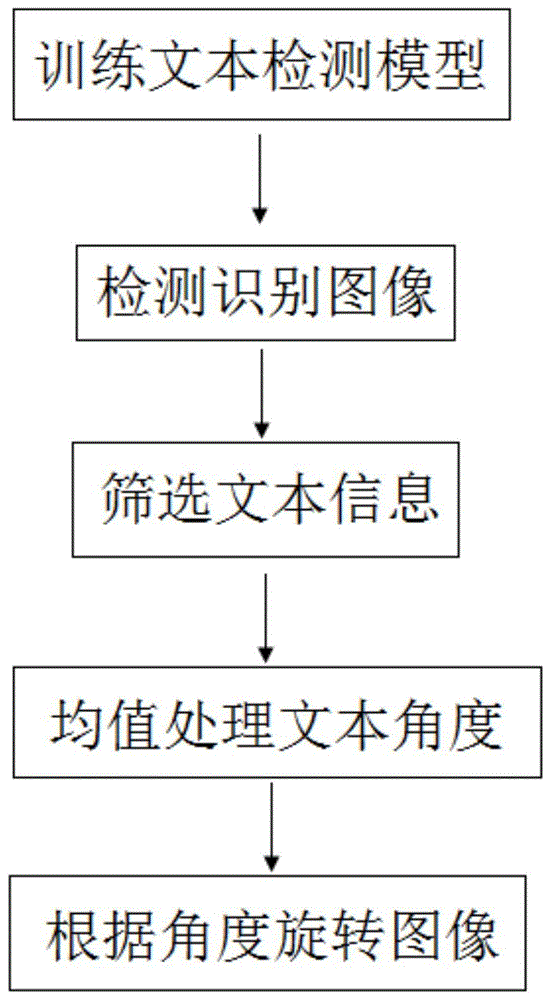
为实现本发明目的而采用的技术方案是这样的,一种基于深度学习的圆形表盘旋转矫正方法,包括以下步骤:
1)构建文本检测深度模型m。
2)基于标准数据集训练文本检测模型m。
3)利用模型m对表盘图像进行检测识别,获得文本组t。
4)对文本组t的文本进行筛选,得到文本组tnew。
5)对文本组tnew的所有角度进行均值处理,得到最终的旋转角度θ。
6)根据θ对图像进行旋转,输出最终的矫正后的图像。
进一步,步骤1)所构建的文本检测深度模型m基于cptn文本检测模型。
进一步,步骤2)中文本检测的模型的训练数据集采用ctw中文数据集。模型训练基于梯度的方式进行训练。
进一步,步骤2)将表盘图像处理成文本检测模型需要的格式,然后输入模型获取结果。
进一步,步骤3)根据文本中所含的中文数字来决定文本是否为中文文本,中文数字推荐3个以上,对于不符合要求的文本全部提出。
本发明的技术效果是毋庸置疑的:
a.能适应复杂的环境因素,实际生产中,表盘暴露在自然环境中,难免会存在一些干扰因素,例如光照,阴影等,该技术能有效地抵抗环境因素所带来的影响,具有强抗干扰能力;
b.在识别过程对识别内容进行一定条件的筛选,剔除了干扰信息,提高了角度确定的精度,进一步提升了该技术的鲁棒性。
附图说明
图1为旋转角度矫正流程图;
图2为cptn模型结构图;
图3为文本信息;
图4为筛选之后保留的文本信息;
图5旋转矫正后的图像。
具体实施方式
下面结合实施例对本发明作进一步说明,但不应该理解为本发明上述主题范围仅限于下述实施例。在不脱离本发明上述技术思想的情况下,根据本领域普通技术知识和惯用手段,做出各种替换和变更,均应包括在本发明的保护范围内。
实施例1:
参见图1,本实施例公开一种基于深度学习的圆形表盘旋转矫正方法,包括以下步骤:
1)构建文本检测深度模型m。在本实施例中,采取的模型基于cptn模型。如图2所示为cptn模型结构图。相较于传统的光学字符识别(ocr)检测技术,例如基于光学仪器设备的文本检测技术以及霍夫变换的文本检测技术等,深度模型没有设备的限制,无需专业的检测设备,且鲁棒性相较于传统ocr技术要高得多。
2)基于标准数据集训练文本检测模型m。模型训练采用的中文数据集为ctw数据集。
3)对表盘图像进行检测识别,获得文本组t。将表盘图像处理成文本检测模型需要的格式,然后输入模型获取结果。在本实施例中,图像处理为jpg格式,经过模型检测之后的图像如图3所示。
4)对文本组t的文本进行筛选,得到新的文本组tnew。根据文本中所含的中文数字来决定文本是否为中文文本,中文数字必须满足最低特定数目要求,对于不符合要求的文本全部提出。中文数字阈值设定为3,经保留文本信息处理之后的图像如图4所示。
5)对文本组tnew的所有角度进行均值处理,得到最终的旋转角度θ。对文本组tnew进行角度均值处理,公式如下:
式中,n表示的是文本组的长度,θ表示的是最终的旋转角度,θi表示的是第i个文本的角度值。本实例中,计算得到的旋转角度的值近似为25度。
6)根据步骤4)得到的θ对图像进行旋转,输出最终的矫正后的图像。最终旋转矫正的图像如图5所示。
值得说明的是,本实施例基于深度学习里面的目标检测技术来进行表盘的旋转矫正,解决了表盘旋转角度矫正精度低,鲁棒性不强等问题。本实施例可以准确地检测出表盘图像中的相关文本信息,并借助有效的文本信息计算出表盘的旋转角度进而矫正圆形表盘的角度,来为下一步识别表盘读数奠定基础。本实施例所述方法是切实有效的。
技术特征:
1.一种基于深度学习的圆形表盘旋转矫正方法,其特征在于,包括以下步骤:
1)构建文本检测深度模型m;
2)基于标准数据集训练文本检测模型m;
3)利用模型m对表盘图像进行检测识别,获得文本组t;
4)对文本组t的文本进行筛选,得到文本组tnew;
5)对文本组tnew的所有角度进行均值处理,得到最终的旋转角度θ;
6)根据θ对图像进行旋转,输出最终的矫正后的图像。
2.根据权利要求1所述的基于深度学习的圆形表盘旋转矫正方法,其特征在于:步骤1)所构建的文本检测深度模型m基于cptn文本检测模型。
3.根据权利要求2所述的基于深度学习的圆形表盘旋转矫正方法,其特征在于:步骤2)中文本检测的模型的训练数据集采用ctw中文数据集。模型训练基于梯度的方式进行训练。
4.根据权利要求1所述的基于深度学习的圆形表盘旋转矫正方法,其特征在于:步骤3)将表盘图像处理成文本检测模型需要的格式,然后输入模型获取结果。
5.根据权利要求3或5所述的基于深度学习的圆形表盘旋转矫正方法,其特征在于:步骤4)根据文本中所含的中文数字来决定文本是否为中文文本,中文数字推荐3个以上,对于不符合要求的文本全部剔除。
技术总结
发明提供一种基于深度学习的圆形表盘旋转角度矫正的方法。该方法包括检测模型的构建、训练、通过模型检测表盘图像、筛选文本信息、获取角度读数和角度旋转等步骤。该方法解决了存在角度误差的圆形表盘的旋转矫正问题,提高了圆形表盘旋转矫正的精度,矫正方法也具有较好的鲁棒性。
技术研发人员:章良杰;董俊伟;冯亮;徐新兴;刘凯
受保护的技术使用者:重庆大学
技术研发日:2019.12.12
技术公布日:2020.07.03
- 还没有人留言评论。精彩留言会获得点赞!