一种情感词语文本信息分类方法与流程
本发明涉及文本信息分类技术领域,具体为一种情感词语文本信息分类方法。
背景技术:
情感分类是自然语言处理(naturallanguageprocessing,nlp)领域中的一个典型问题,问题的描述为,给定一段文字(可以是一句话或一篇文章),判断这篇文章所表达的情感是正向、负向还是中性的。
情感分类问题本身是一个无论学术界还是工业界都广泛深入研究的话题。利用情感字典是一种解决情感分类问题的方法。首先人为设定一些情感词,如正向情感词、负向情感词,之后通过统计输入文本的正、负向情感词的占比来决定文本的情感分类。
分数绝对值低的部分样本判断准确性不算高,分类不够明确。
分析文本情感色彩时没有考虑语境和句间关系,容易误判如讽刺性文本等特殊文本。
技术实现要素:
本发明的目的在于解决现有技术方案中存在的问题。
本发明解决其技术问题所采用的技术方案是:
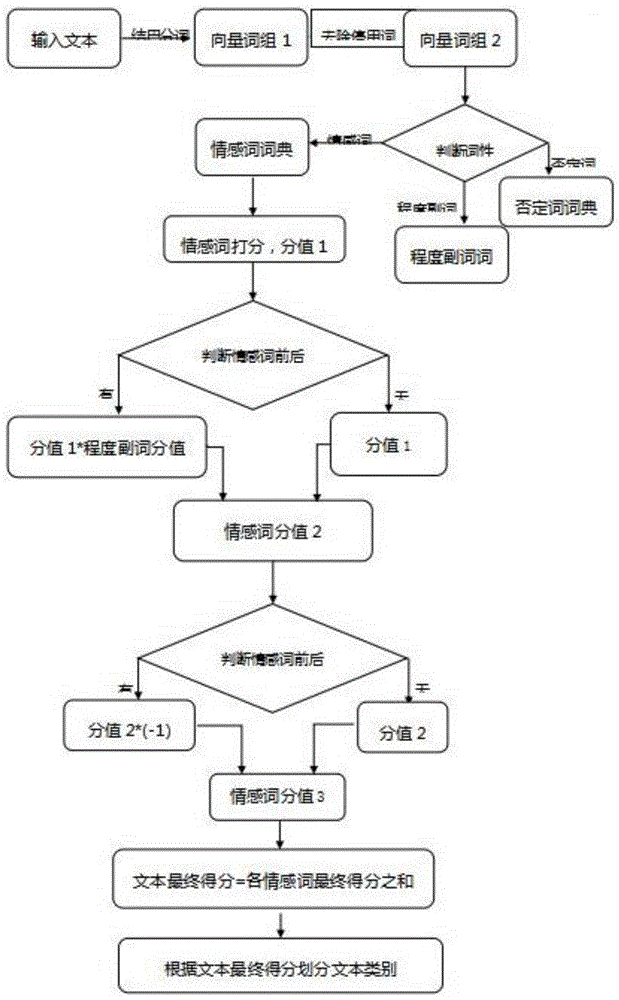
一种情感词语文本信息分类方法,包括:
获取文本信息;
输入文本词语;
判断词性,所述判断文本中词性分为情感词、否定词、程度副词;
情感词打分,情感词输入情感词词典打分,得到分值1;
判断情感词前后,判断情感词前后是否对应程度副词;
得到新的情感词分值2;
再次判断情感词前后,得到情感词分值3;
输出文本最终得分,各情感词最终得分之和;
根据文本最终得分划分文本类别。
进一步的,还包括文本词典,所述文本词典包含建立情感词典、否定词词典和程度副词词典,将每个文本对象的单词列表中的词归类,生成此个文本对象的情感词词典、否定词词典和程度副词词典。
进一步的,所述情感词典包括正向情感词和负向情感词,程度副词词典和情感词有分值,否定词没有分值。
进一步的,还包含了建立文本数据集,人工对每一个文本对象做标记,划分该文本的情感分类,分为正向、中立、负向3类,分别标记为1、0、-1,每个文本对象利用结巴分词进行处理并根据停用词词典去除停用词,得到每个文本的单词列表。
进一步的,判断情感词前后分数计算范围为两个情感词之间的否定词和程度副词与其中后一个情感词构成一个情感词组,所有情感词组的得分之和即为文本的情感极性得分。公式如下:
其中ai为第i个情感词组中的否定词词数,bi为此词组中所有程度副词的权值之积,ci为情感副词的得分。
本发明的有益效果是:本技术方案中通过对文本进行情感色彩打分,在实施过程中对文本进行情感色彩打分,进而将文本划分为正向、中立、负向三个类别,并且与文本数据集中文本对象标记对比,还可以随时补入更新后的开源性词典。
附图说明
为了更清楚地说明本发明实施方式的技术方案,下面将对实施方式中所需要使用的附图作简单地介绍,应当理解,以下附图仅示出了本发明的某些实施例,因此不应被看作是对范围的限定,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他相关的附图。
图1是本发明第一实施例分类过程流程图;
具体实施方式
下面通过具体实施例,并结合附图,对本发明的技术方案作进一步的具体说明。
实施例一,请参照附图1本发明旨在建立一种情感词语文本信息分类方法,目的是对文本进行情感色彩打分,进而将文本划分为正向、中立、负向三个类别。
1、建立词典
建立情感词典(包括正向情感词和负向情感词)、否定词词典和程度副词词典。程度副词词典和情感词有分值,否定词没有分值,词典格式如表1。(以上3个词典为网络上已发布的开源性词典)
表1词典格式
2文本分词
建立文本数据集,人工对每一个文本对象做标记,划分该文本的情感分类,分为正向、中立、负向3类,分别标记为1、0、-1。
每个文本对象利用结巴分词进行处理并根据停用词词典去除停用词,得到每个文本的单词列表。(此处所用停用词词典为网络上已发布的开源性词典)
3生成文本词典
将每个文本对象的单词列表中的词归类,生成此个文本对象的情感词词典、否定词词典和程度副词词典。
4计算情感极性得分
两个情感词之间的否定词和程度副词与其中后一个情感词构成一个情感词组,所有情感词组的得分之和即为文本的情感极性得分。公式如下:
其中ai为第i个情感词组中的否定词词数,bi为此词组中所有程度副词的权值之积,ci为情感副词的得分。
5确定分类范围
利用文本对象的得分划分该文本情感正负向性或者中立性。
观察得分,发现0分并不是合理的正负向分界线,于是将分类问题抽象成最优化问题,即寻找最优的中立分数的上下限,使所得的分类与人工标记的分类相比正确率最高。而得到这个范围之后,即可应用到其他文本的分类标准。
可行域根据样本分数确定,如根据排序后分数合理百分比的中间段数据的极差确定,此处下界可行域为(-2,4),上界可行域为(-1,6)。目标函数为分类正确率。如果新上下界的正确率高于旧上下界,则更新上下界。
得到中立上界为3.7分,中立下界为-1分,分类正确率为86.24%。即当一个文本的得分小于-1此文本情感上为负向;得分在-1与3.7之间,此文本情感上为中立;得分大于3.7,此文本情感上为正向。应用这种方法对文本进行情感分类的正确率为86.24%。
对情感词典有一定依赖性,后期可根据不同平台上的样本利用机器学习的朴素贝叶斯算法对情感词典进行优化,使之更适用于特定平台上的文本情感判断。
以上所述的实施例只是本发明的一种较佳的方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其它的变体及改型。
技术特征:
1.一种情感词语文本信息分类方法,其特征在于,包括:
获取文本信息;
输入文本词语;
判断词性,所述判断文本中词性分为情感词、否定词、程度副词;
情感词打分,情感词输入情感词词典打分,得到分值1;
判断情感词前后,判断情感词前后是否对应程度副词;
得到新的情感词分值2;
再次判断情感词前后,得到情感词分值3;
输出文本最终得分,各情感词最终得分之和;
根据文本最终得分划分文本类别。
2.根据权利要求1所述的情感词语文本信息分类方法,其特征在于:还包括文本词典,所述文本词典包含建立情感词典、否定词词典和程度副词词典,将每个文本对象的单词列表中的词归类,生成此个文本对象的情感词词典、否定词词典和程度副词词典。
3.根据权利要求2所述的情感词语文本信息分类方法,其特征在于:所述情感词典包括正向情感词和负向情感词,程度副词词典和情感词有分值,否定词没有分值。
4.根据权利要求3所述的情感词语文本信息分类方法,其特征在于:还包含了建立文本数据集,人工对每一个文本对象做标记,划分该文本的情感分类,分为正向、中立、负向3类,分别标记为1、0、-1,每个文本对象利用结巴分词进行处理并根据停用词词典去除停用词,得到每个文本的单词列表。
5.根据权利要求1-4任意一项所述的情感词语文本信息分类方法,其特征在于:判断情感词前后分数计算范围为两个情感词之间的否定词和程度副词与其中后一个情感词构成一个情感词组,所有情感词组的得分之和即为文本的情感极性得分。公式如下:
其中ai为第i个情感词组中的否定词词数,bi为此词组中所有程度副词的权值之积,ci为情感副词的得分。
技术总结
本发明公开了一种情感词语文本信息分类方法,包括:获取文本信息;输入文本词语;判断词性,所述判断文本中词性分为情感词、否定词、程度副词;情感词打分,情感词输入情感词词典打分,得到分值1;判断情感词前后,判断情感词前后是否对应程度副词;得到新的情感词分值2;再次判断情感词前后,得到情感词分值3;输出文本最终得分,各情感词最终得分之和;根据文本最终得分划分文本类别。本发明旨在建立一个文本信息分类模型,目的是对文本进行情感色彩打分,进而将文本划分为正向、中立、负向三个类别。
技术研发人员:李春燕;苏航;李松和;武传涛;刘瑞欣
受保护的技术使用者:山东众志电子有限公司
技术研发日:2019.12.24
技术公布日:2020.05.05
- 还没有人留言评论。精彩留言会获得点赞!