基于数据分布波动率的数据一致性评估方法与流程
本发明属于大数据分析处理领域,特别涉及一种对结构化数据的一致性评估技术。
背景技术:
结构化数据,简单来说就是数据库。结合到典型场景中更容易理解,比如企业erp、财务系统;医疗his数据库;教育一卡通;政府行政审批;其他核心数据库等。
基本包括高速存储应用需求、数据备份需求、数据共享需求以及数据容灾需求。
结构化数据也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。与结构化数据相对的是不适于由数据库二维表来表现的非结构化数据,包括所有格式的办公文档、xml、html、各类报表、图片和音频、视频信息等。支持非结构化数据的数据库采用多值字段、了字段和变长字段机制进行数据项的创建和管理,广泛应用于全文检索和各种多媒体信息处理领域。
随着信息技术的发展,各部门及企事业单位纷纷建设数据中心。由于数据来源的数据质量水平未知,etl(extracttransformloading,数据抽取转化装载规则)过程错误等总是会出现数据不一致的现象。数据一致性是数据质量评估的一个维度,侧重评估数据变更或变异的程度。目前市面上通常仅仅评估字段内数据格式一致性来评估数据一致性。事实上,仅仅评估字段内数据格式一致无法解决如下问题:
业务系统bug或者etl过程中出现错误导致一些数据丢失或者修改错误。通常的评估方法无法找出这样异常的数据。
技术实现要素:
为解决上述技术问题,本发明提出一种基于数据分布波动率的数据一致性评估方法,通过评估字段内值模式分布波动率来初步找到波动异常的数据。
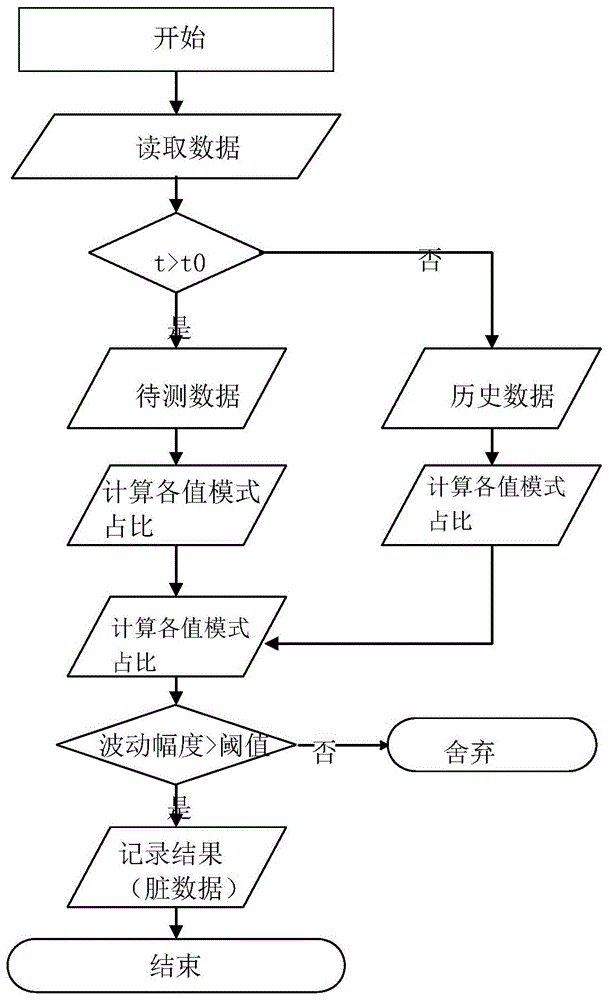
本发明采用的技术方案为:一种基于数据分布波动率的数据一致性评估方法,首先,根据时间戳字段,将待测数据分为历史数据和当前数据;然后,分析待测数据中不同的值模式当前的占比与过去的占比,并将占比的变化幅度与给定的阈值比较;如果某数据存在值模式占比变化幅度大于阈值,则认为该数据存在一致性问题;否则数据正常。
所述模式值占比计算式为:
其中,∑x=k1用于统计等于某个值的数据条数,x为自变量,k为数据值,∑1用于表示该字段数据总条数。
所述占比的变化幅度具体为待测数据当前值模式占比与历史占比的差值。
当然,在根据时间戳字段,将待测数据分为历史数据和当前数据之前,还包括:判断待测数据是否为空,若为空,则结束;否则根据时间戳字段,将待测数据分为历史数据和当前数据。
本发明的有益效果:本发明能够评估字段内某些值模式与过去相比在数量上波动变化情况,能够发现一些异常点,即当前在数量上变化幅度超出预期的值模式。通过本发明的方法,数据工程师可以评估数据是否符合历史规律,是否可能存在etl过程错误或应用系统bug引起数据不一致的情况,可以作为评估数据一致性的一种方法。
附图说明
图1为本发明的方案流程图。
具体实施方式
为便于本领域技术人员理解本发明的技术内容,下面结合附图对本发明内容进一步阐释。
首先介绍本发明使用场景,本发明可用于任何需要评估字段内数据值模式在数量上与过去相比变化幅度大小的场景。
本实施例以一张“学籍异动子类表t”,包含字段“学号f2”、“异动情况f1”、“异动时间f0”为例对本发明的内容进行详细阐述。其中,f0值的范围在[2010-9-1,2019-8-30],f1值模式包含“出国留学”、“本人申请”、“擅自离校”、“休学期满”、“学籍清理”、“成绩低劣”本发明中值模式为可在字典表查询的值,每个值模式代表一类值。如字段值只包含教授/副教授/讲师,字段有很多条数据。则教授是一个值模式,副教授也是一个值模式,讲师也是一个值模式。
处理流程如图1所示:
可以设定分割时间t=2018-8-30,将f1的值分为两段,即f0小于t的情况f11,f0大于t的情况f12,f0等于t的情况一般根据所设置分割时间来确定,归属于f11或f12;本实施例中f0等于t的情况,归属于f11。
然后对f11,f12分别分组统计字段内各个值模式的占比
假设统计结果如下:
f11中各值模式占比:
出国留学->10%、本人申请->22%、擅自离校->6%、休学期满->30%、学籍清理->20%、成绩低劣->12%
f12中各值模式占比:
出国留学->11%、本人申请->1%、擅自离校->29%、休学期满->25%、学籍清理->21%、成绩低劣->13%
给定阈值th=5%,将f11的结果数据与f12的结果数据分别对比
y(x)=|f(x1)-f(x2)|-th
发现在f12中“本人申请”与“擅自离校”两种值模式的波动率超过了阈值(即y(x)>0)。我们可以初步判定该数据存在一致性问题。然后我们进一步根据其他信息(不在本文讨论范围)分析发现,业务系统最近一次升级的版本出现bug引发了该问题:更新异动数据时,将“本人申请”和“擅自离校”设置成相同的代码,所有升级后操作为“本人申请”的数据全部改成了“擅自离校”。
由上述实例说明,本发明可以作为评估数据一致性的一种方法。
本发明中的阈值设置为3%-6%,申请人经过大量实验表明当阈值设置为5%时,所得到的数据一致性最佳。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的权利要求范围之内。
技术特征:
1.一种基于数据分布波动率的数据一致性评估方法,其特征在于,首先,根据时间戳字段,将待测数据分为历史数据和当前数据;然后,分析待测数据中不同的值模式当前的占比与过去的占比,并将占比的变化幅度与给定的阈值比较;如果某数据存在值模式占比变化幅度大于阈值,则认为该数据存在一致性问题;否则数据正常。
2.根据权利要求1所述的一种基于数据分布波动率的数据一致性评估方法,其特征在于,所述模式值占比计算式为:
其中,∑x=k1用于统计等于某个值的数据条数,x为自变量,k为数据值,∑1用于表示该字段数据总条数。
3.根据权利要求1所述的一种基于数据分布波动率的数据一致性评估方法,其特征在于,所述占比的变化幅度具体为待测数据当前值模式占比与历史占比的差值。
4.根据权利要求1所述的一种基于数据分布波动率的数据一致性评估方法,其特征在于,在根据时间戳字段,将待测数据分为历史数据和当前数据之前,还包括:判断待测数据是否为空,若为空,则结束;否则根据时间戳字段,将待测数据分为历史数据和当前数据。
技术总结
本发明公开一种基于数据分布波动率的数据一致性评估方法,应用于大数据分析处理领域,针对现有技术无法找出业务系统bug或者etl过程中出现错误导致一些数据丢失或者修改错误的问题;本发明首先,根据时间戳字段,将待测数据分为历史数据和当前数据;然后,分析待测数据中不同的值模式当前的占比与过去的占比,并将占比的变化幅度与给定的阈值比较;如果某数据存在值模式占比变化幅度大于阈值,则认为该数据存在一致性问题;否则数据正常;本发明的方法可以快速有效地找出业务系统bug或者etl过程中出现错误导致一些数据丢失或者修改错误。
技术研发人员:唐雪飞;蒲高飞;黄永鑫;王东方;胡茂秋
受保护的技术使用者:成都康赛信息技术有限公司
技术研发日:2019.12.26
技术公布日:2020.05.01
- 还没有人留言评论。精彩留言会获得点赞!