任务处理方法、装置及设备与流程
本申请涉及互联网技术领域,尤其是涉及一种任务处理方法、装置及设备。
背景技术:
随着ai(artificialintelligence,人工智能)的快速发展,ai加速器越来越多,技术更新越来越快,ai加速器在数据中心的使用量逐步增加。ai加速器也称为ai芯片或计算卡,是专门用于处理人工智能应用中的大量计算任务的模块,其它非计算任务仍由cpu(centralprocessingunit,中央处理器)负责。
在相关技术中,需要为每个用户配置独立的ai加速器,ai加速器只为该用户的人工智能应用的计算任务进行处理,存在ai加速器的利用率较低等问题。
技术实现要素:
本申请提供一种任务处理方法,所述方法包括:
接收客户端发送的加速处理请求;
对所述加速处理请求进行处理,得到加速处理参数;
根据所述加速处理参数生成待处理任务;
将所述待处理任务发送给加速器,以使所述加速器处理所述待处理任务。
本申请提供一种任务处理方法,所述方法包括:
获取应用程序的加速处理参数;
对所述加速处理参数进行封装,得到加速处理请求;
将所述加速处理请求发送给服务端,以使所述服务端根据所述加速处理参数生成待处理任务,并将所述待处理任务发送给加速器进行处理。
本申请提供一种任务处理方法,所述方法包括:
接收客户端发送的加速处理请求;
确定所述加速处理请求是否为待处理队列的目标加速处理请求,所述目标加速处理请求是待处理队列中最后一个加速处理请求的下一个加速处理请求;
如果是,则将所述加速处理请求添加到所述待处理队列;
基于所述待处理队列中的加速处理请求的顺序,对所述待处理队列中的第一个加速处理请求进行处理,得到加速处理参数;
根据所述加速处理参数生成待处理任务;
将所述待处理任务发送给加速器,以使所述加速器处理所述待处理任务。
本申请提供一种任务处理方法,所述方法包括:
获取应用程序的加速处理参数;
在得到所述加速处理参数对应的任务处理结果之前,向所述应用程序返回预测任务处理结果,由所述应用程序根据所述预测任务处理结果执行下一任务;
对所述加速处理参数进行封装,得到加速处理请求;
将所述加速处理请求添加到待处理队列;
基于所述待处理队列中的加速处理请求的顺序,依次将所述待处理队列中的加速处理请求发送给服务端,以使所述服务端根据所述加速处理请求生成待处理任务,并将所述待处理任务发送给加速器进行处理。
本申请提供一种任务处理方法,所述方法包括:
接收客户端发送的人工智能ai处理请求;
对所述ai处理请求进行处理,得到ai处理参数;
根据所述ai处理参数生成待处理ai任务;
将所述待处理ai任务发送给ai加速器,以使所述ai加速器处理所述待处理ai任务,得到所述待处理ai任务对应的任务处理结果。
本申请提供一种任务处理装置,所述装置包括:
接收模块,用于接收客户端发送的加速处理请求;
处理模块,用于对所述加速处理请求进行处理,得到加速处理参数;
生成模块,用于根据所述加速处理参数生成待处理任务;
发送模块,用于将所述待处理任务发送给加速器,以使所述加速器处理所述待处理任务。
本申请提供一种任务处理装置,所述装置包括:
获取模块,用于获取应用程序的加速处理参数;
处理模块,用于对所述加速处理参数进行封装,得到加速处理请求;
发送模块,用于将所述加速处理请求发送给服务端,以使所述服务端根据所述加速处理参数生成待处理任务,将所述待处理任务发送给加速器进行处理。
本申请提供一种服务端设备,包括:
处理器和机器可读存储介质,所述机器可读存储介质上存储有若干计算机指令,所述处理器执行所述计算机指令时进行如下处理:
接收客户端发送的加速处理请求;
对所述加速处理请求进行处理,得到加速处理参数;
根据所述加速处理参数生成待处理任务;
将所述待处理任务发送给加速器,以使所述加速器处理所述待处理任务。
本申请提供一种客户端设备,包括:
处理器和机器可读存储介质,所述机器可读存储介质上存储有若干计算机指令,所述处理器执行所述计算机指令时进行如下处理:
获取应用程序的加速处理参数;
对所述加速处理参数进行封装,得到加速处理请求;
将所述加速处理请求发送给服务端,以使所述服务端根据所述加速处理参数生成待处理任务,并将所述待处理任务发送给加速器进行处理。
基于上述技术方案,本申请实施例中,通过将加速器部署在服务端,且由服务端为多个客户端提供服务,从而使得多个用户共用同一个加速器,即每个用户均使用自身的客户端访问服务端,继而使用加速器的资源。上述方式能够提高每个加速器的利用率,非常适用于加速器利用率较低的应用场景。
附图说明
为了更加清楚地说明本申请实施例或者现有技术中的技术方案,下面将对本申请实施例或者现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本申请中记载的一些实施例,对于本领域普通技术人员来讲,还可以根据本申请实施例的这些附图获得其它的附图。
图1是本申请一种实施方式中的任务处理方法的流程示意图;
图2是本申请一种实施方式中的任务处理方法的流程示意图;
图3是本申请一种实施方式中的应用场景示意图;
图4是本申请一种实施方式中的任务处理方法的流程示意图;
图5a-图5c是本申请一撰实施方式中的时序顺序的示意图;
图6a和图6b是本申请一种实施方式中的任务处理装置的结构示意图;
图7a是本申请一种实施方式中的服务端设备的结构示意图;
图7b是本申请一种实施方式中的客户端设备的结构示意图。
具体实施方式
在本申请实施例使用的术语仅仅是出于描述特定实施例的目的,而非限制本申请。本申请和权利要求书中所使用的单数形式的“一种”、“所述”和“该”也旨在包括多数形式,除非上下文清楚地表示其它含义。还应当理解,本文中使用的术语“和/或”是指包含一个或多个相关联的列出项目的任何或所有可能组合。
应当理解,尽管在本申请实施例可能采用术语第一、第二、第三等来描述各种信息,但这些信息不应限于这些术语。这些术语仅用来将同一类型的信息彼此区分开。例如,在不脱离本申请范围的情况下,第一信息也可以被称为第二信息,类似地,第二信息也可以被称为第一信息。取决于语境,此外,所使用的词语“如果”可以被解释成为“在……时”或“当……时”或“响应于确定”。
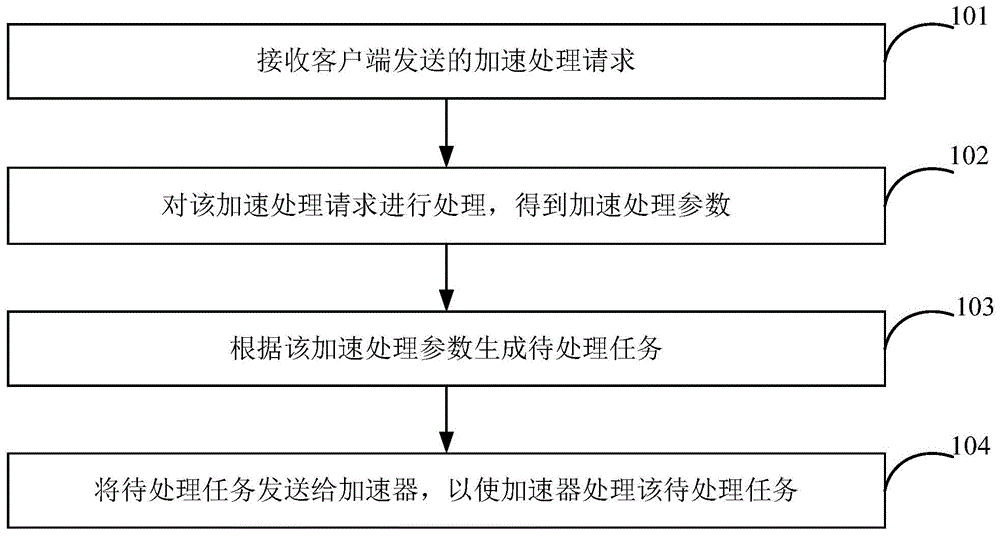
本申请实施例中提出一种任务处理方法,可以应用于服务端,该服务端可以部署加速器(也可以称为异构加速器),且加速器用于为多个客户端提供服务,参见图1所示,为该任务处理方法的流程示意图,该方法可以包括:
步骤101,接收客户端发送的加速处理请求。
步骤102,对该加速处理请求进行处理,得到加速处理参数。
示例性的,该加速处理请求可以包括但不限于api(applicationprogramminginferface,应用程序编程接口)请求,该加速处理参数可以包括但不限于api参数。基于此,可以对加速处理请求进行api解封装处理,得到加速处理参数。
步骤103,根据该加速处理参数生成待处理任务。
示例性的,可以从真实加速器库中获取应用程序的第一库文件,并根据该第一库文件以及该加速处理参数生成待处理任务。例如,将加速处理参数代入到第一库文件中的api函数,基于api函数和加速处理参数得到待处理任务。
步骤104,将待处理任务发送给加速器,以使加速器处理该待处理任务。
示例性的,加速器是能够对该待处理任务进行处理的模块,因此,在将待处理任务发送给加速器后,加速器可以对该待处理任务进行处理。
在一种可能的实施方式中,在步骤104之后,还可以获取该待处理任务对应的任务处理结果,并对该任务处理结果进行api封装处理,得到加速处理响应;然后,可以将该加速处理响应发送给客户端。
在一种可能的实施方式中,在接收到客户端发送的加速处理请求之后,还可以确定该加速处理请求是否为待处理队列的目标加速处理请求,目标加速处理请求是待处理队列中最后一个加速处理请求的下一个加速处理请求。如果是,则将该加速处理请求添加到该待处理队列。如果否,则等到该加速处理请求是待处理队列的目标加速处理请求后,将该加速处理请求添加到该待处理队列。
示例性的,基于待处理队列中的加速处理请求的顺序,可以对该待处理队列中的第一个加速处理请求进行处理,得到加速处理参数。在对该待处理队列中的第一个加速处理请求进行处理后,可以从待处理队列中删除该加速处理请求,即待处理队列中的第一个加速处理请求发生变化,并对待处理队列中的变化后的第一个加速处理请求进行处理,得到加速处理参数,以此类推。
示例性的,确定加速处理请求是否为待处理队列的目标加速处理请求,可以包括但不限于:根据加速处理请求的序号值和待处理队列的全局计数器的计数值,确定该加速处理请求是否为待处理队列的目标加速处理请求;其中,该计数值表示待处理队列中最后一个加速处理请求的序号值。
在一个例子中,上述执行顺序只是为了方便描述给出的一个示例,在实际应用中,还可以改变步骤之间的执行顺序,对此执行顺序不做限制。而且,在其它实施例中,并不一定按照本说明书示出和描述的顺序来执行相应方法的步骤,其方法所包括的步骤可以比本说明书所描述的更多或更少。此外,本说明书中所描述的单个步骤,在其它实施例中可能被分解为多个步骤进行描述;本说明书中所描述的多个步骤,在其它实施例也可能被合并为单个步骤进行描述。
基于上述技术方案,本申请实施例中,通过将加速器部署在服务端,且由服务端为多个客户端提供服务,从而使得多个用户共用同一个加速器,即每个用户均使用自身的客户端访问服务端,继而使用加速器的资源。上述方式能够提高每个加速器的利用率,非常适用于加速器利用率较低的应用场景。
本申请实施例中提出一种任务处理方法,该方法可以应用于客户端,参见图2所示,为该任务处理方法的流程示意图,该方法可以包括:
步骤201,获取应用程序的加速处理参数。
步骤202,对该加速处理参数进行封装,得到加速处理请求。
示例性的,该加速处理参数可以包括但不限于api参数,该加速处理请求可以包括但不限于api请求。基于此,对该加速处理参数进行封装,得到加速处理请求,可以包括但不限于:从函数代理库中获取应用程序的第二库文件,并根据该第二库文件对该加速处理参数进行api封装,得到加速处理请求。
示例性的,从函数代理库中获取应用程序的第二库文件之前,还可以从服务端的真实加速器库的第一库文件中解析api函数信息,根据该api函数信息生成应用程序的第二库文件,将该应用程序的第二库文件存储到函数代理库中。
步骤203,将该加速处理请求发送给服务端,以使服务端根据该加速处理参数生成待处理任务,并将该待处理任务发送给加速器进行处理。
示例性的,将该加速处理请求发送给服务端之后,还可以接收服务端针对该加速处理请求返回的加速处理响应;然后,对该加速处理响应进行api解封装处理,得到任务处理结果,并将任务处理结果返回给应用程序。
在一种可能的实施方式中,获取应用程序的加速处理参数之后,还可以在得到加速处理参数对应的任务处理结果之前,向应用程序返回预测任务处理结果,由应用程序根据预测任务处理结果执行下一任务,应用程序不用等到加速处理参数对应的任务处理结果,就可以执行下一任务,减少了等待时间。
示例性的,将加速处理请求发送给服务端,可以包括但不限于:确定待处理队列的全局计数器的计数值,该计数值表示待处理队列中最后一个加速处理请求对应的序号值。根据该计数值确定加速处理请求(即当前得到的加速处理请求)对应的序号值。然后,将该序号值添加到加速处理请求,并将该加速处理请求添加到待处理队列。基于待处理队列中的各加速处理请求的顺序,依次将每个加速处理请求发送给服务端。例如,先发送待处理队列中的第一个加速处理请求,在加速处理请求发送完成后,可以从待处理队列中删除该加速处理请求,即待处理队列中的第一个加速处理请求发生变化,并对待处理队列中的变化后的第一个加速处理请求进行发送,以此类推。
在一个例子中,上述执行顺序只是为了方便描述给出的一个示例,在实际应用中,还可以改变步骤之间的执行顺序,对此执行顺序不做限制。而且,在其它实施例中,并不一定按照本说明书示出和描述的顺序来执行相应方法的步骤,其方法所包括的步骤可以比本说明书所描述的更多或更少。此外,本说明书中所描述的单个步骤,在其它实施例中可能被分解为多个步骤进行描述;本说明书中所描述的多个步骤,在其它实施例也可能被合并为单个步骤进行描述。
基于上述技术方案,本申请实施例中,通过将加速器部署在服务端,且由服务端为多个客户端提供服务,从而使得多个用户共用同一个加速器,即每个用户均使用自身的客户端访问服务端,继而使用加速器的资源。上述方式能够提高每个加速器的利用率,非常适用于加速器利用率较低的应用场景。
基于与上述方法同样的申请构思,本申请实施例中还提出另一种任务处理方法,该方法可以应用于服务端,该方法可以包括以下步骤:
步骤a1、接收客户端发送的加速处理请求。
步骤a2、确定该加速处理请求是否为待处理队列的目标加速处理请求。示例性的,目标加速处理请求是该待处理队列中最后一个加速处理请求的下一个加速处理请求。如果是,则可以执行步骤a3。
步骤a3、将该加速处理请求添加到待处理队列。
步骤a4、基于该待处理队列中的加速处理请求的顺序,对该待处理队列中的第一个加速处理请求进行处理,得到加速处理参数。
步骤a5、根据该加速处理参数生成待处理任务。
步骤a6、将该待处理任务发送给加速器,以使加速器处理该待处理任务。
基于与上述方法同样的申请构思,本申请实施例中还提出另一种任务处理方法,该方法可以应用于客户端,该方法可以包括以下步骤:
步骤b1、获取应用程序的加速处理参数。
步骤b2、在得到该加速处理参数对应的任务处理结果之前,向应用程序返回预测任务处理结果,由应用程序根据该预测任务处理结果执行下一任务。
步骤b3、对该加速处理参数进行封装,得到加速处理请求。
步骤b4、将该加速处理请求添加到待处理队列。
步骤b5、基于该待处理队列中的加速处理请求的顺序,依次将该待处理队列中的每个加速处理请求发送给服务端,以使服务端根据该加速处理请求生成待处理任务,并将该待处理任务发送给加速器进行处理。
基于与上述方法同样的申请构思,本申请实施例中还提出另一种任务处理方法,该方法可以应用于服务端,该方法可以包括以下步骤:
步骤c1、接收客户端发送的ai处理请求。
步骤c2、对该ai处理请求进行处理,得到ai处理参数。
步骤c3、根据该ai处理参数生成待处理ai任务。
步骤c4、将该待处理ai任务发送给ai加速器,以使ai加速器处理该待处理ai任务,得到该待处理ai任务对应的任务处理结果。
以下结合具体应用场景,对本申请实施例的上述技术方案进行说明。
参见图3所示,为本申请实施例的应用场景示意图,服务端31(server)与多个客户端32(client)连接,服务端31部署的加速器311用于为多个客户端32提供服务。示例性的,可以将客户端32称为前端,将服务端31称为后端。
在ai应用场景中,加速器311可以为ai加速器(ai加速器也称为ai芯片或ai计算卡),ai加速器是专门用于处理人工智能应用中的大量计算任务的模块。其它应用场景也可以通过加速器311实现计算功能,对此不做限制。
示例性的,加速器311可以包括但不限于gpu(graphicsprocessingunit,图形处理器),或者,fpga(fieldprogrammablegatearray,现场可编程门阵列),或者,cpld(complexprogrammablelogicdevice,复杂可编程逻辑器件),或者,asic(applicationspecificintegratedcircuit,专用集成电路)。当然,上述只是加速器311的几个示例,对此加速器311的类型不做限制。
本申请实施例中,由于将加速器311部署在服务端31,且由服务端31为多个客户端32提供服务,从而使得多个用户共用同一个加速器311,提高加速器311的利用率,非常适用于加速器利用率较低的应用场景。例如,用户1在时间区间1使用加速器311的计算资源,用户2在时间区间2使用加速器311的计算资源,用户3在时间区间3使用加速器311的计算资源,以此类推。
例如,在开发场景下,用户一般需要在运行过程中去调试,修改代码,即加速器并不是一直被使用,因此,通过将加速器311部署在服务端31,可以使得多个用户共用同一个加速器311,从而能够提高加速器311的利用率。
参见图3所示,客户端32可以包括应用程序321、函数代理库322和网络通信层323。服务端31可以包括加速器311、网络通信层312、api服务模块313、真实加速器库314。从图3可以看出,加速器311和真实加速器库314部署在服务端31,应用程序321部署在客户端32,而客户端32与服务端31部署在两个不同设备,客户端32与服务端31通过网络连接,例如客户端32与服务端31通过tcp(transmissioncontrolprotocol,传输控制协议)通信,或者通过rdma(remotedirectmemoryaccess,远程直接数据存取)通信。因此,加速器311、真实加速器库314和应用程序321不是部署在同一设备,即分离加速器311与应用程序321,这样,才能够使得加速器311能够为多个应用程序321提供服务。
应用程序321是用于使用加速器311实现相关功能的程序(如applications),即应用程序321会将任务分发给加速器311进行处理,从而利用加速器311的计算资源,如应用程序321可以是用于实现人工智能应用的程序,对此不做限制。显然,由于应用程序321与加速器311不是部署在同一个设备,因此,加速器311能够为多个应用程序321提供服务,提高加速器311的利用率。
真实加速器库314用于提供包括大量api函数的库文件(为了区分方便,将真实加速器库314中的库文件称为第一库文件),即真实加速器库314包括第一库文件,且第一库文件包括大量api函数,这些api函数均是与加速器311有关的函数,也就是说,基于这些api函数生成能够被加速器311处理的任务,从而使用加速器311的资源,对此真实加速器库314的内容不做限制。
api函数是一些预先定义的函数,操作系统中除了包含负责协调应用程序的执行、内存分配、系统资源管理等功能内核外,还包含了大量的函数库,这些函数库就像一个很大的服务中心,调用这个服务中心的各种服务(每一种服务是一个函数),可以帮助应用程序达到开启视窗、描绘图形、使用周边设备的目的。例如,图形库中的一组api定义了绘制指针的方式,可于图形输出设备上显示指针。当应用程序需要指针功能时,可在引用、编译时链接到这组api,而运行时就会调用此api的实现(库)来显示指针。
库文件可以分为静态库和dll(dynamiclinklibrary,动态链接库)文件,静态库在程序的链接阶段被复制到程序中,dll文件在程序的链接阶段没有被复制到程序中,而是程序在运行时由系统动态加载到内存中供程序调用。
示例性的,真实加速器库314中的第一库文件可以是dll文件。
综上所述,可以预先定义与加速器311有关的api函数,将这些api函数存储到dll文件中,并将dll文件存储到真实加速器库314中。
函数代理库322是与加速器311相关的函数库代理层(如acceleratorlibraryproxy,即加速器库代理),函数代理库322用于提供包括大量api函数的库文件(为了区分方便,将函数代理库322中的库文件称为第二库文件),即函数代理库322包括第二库文件,且该第二库文件可以包括大量api函数,这些api函数均是与加速器311有关的函数,也就是说,基于这些api函数生成能够被加速器311处理的任务,对此函数代理库322的内容不做限制。
示例性的,第二库文件与第一库文件的定义相同,但第二库文件与第一库文件的内部实现不同,因此,从应用程序321的角度出发,无法区别第一库文件和第二库文件,也就是说,第二库文件可以替代第一库文件。
示例性的,客户端32可以从服务端31的真实加速器库314中获取第一库文件,从第一库文件中解析api函数信息,根据该api函数信息生成应用程序321的第二库文件,将第二库文件存储到函数代理库322中。例如,客户端32可以创建代码生成器,由代码生成器从第一库文件中解析api函数信息,根据该api函数信息生成第二库文件,并将第二库文件存储到函数代理库322中。
示例性的,函数代理库322的生成过程不是在运行时执行,代码生成器可以离线解析真实加速器库314来生成函数代理库322。在客户端的应用程序启动前,函数代理库322已经被加入操作系统中,取代了真实加速器库314。
由于第一库文件包括与加速器311有关的api函数,因此,代码生成器可以从第一库文件中解析出与加速器311有关的api函数信息(如api的定义等)。代码生成器根据该api函数信息生成第二库文件,第二库文件也包括与加速器311有关的api函数,对此第二库文件的生成过程不做限制。第二库文件中的api函数与第一库文件中的api函数可以相同,也就是说,第二库文件可以包含第一库文件中的所有api,且这些api定义可以相同,对此不做限制。
综上所述,通过代码生成器,自动化了函数代理库322的生成,即由代码生成器自动生成第二库文件,并将第二库文件存储到函数代理库322中。
网络通信层323位于客户端32,是与加速器311无关的网络通信层。网络通信层312位于服务端31,是与加速器311无关的网络通信层。网络通信层323和网络通信层312用于实现消息的传输。例如,网络通信层323能够将客户端32的消息发送给网络通信层312,继而将消息发送给服务端31。网络通信层312能够将服务端31的消息发送给网络通信层323,继而将消息发送给客户端32。
api服务模块313用于对api消息进行封装或者解封装。例如,api服务模块313在接收到客户端32发送的api消息时,可以对api消息进行解封装,得到与api函数有关的参数,并将与api函数有关的参数提供给真实加速器库314。api服务模块313在接收到需要发送给客户端32的任务处理结果时,将任务处理结果封装为api消息,并通过网络通信层312将api消息发送给客户端32。
在上述应用场景下,本申请实施例中提出另一种任务处理方法,参见图4所示,为该任务处理方法的流程示意图,该方法可以包括:
步骤401,客户端32获取应用程序321的加速处理参数(如api参数)。
示例性的,当应用程序321需要利用加速器311的计算资源时,可以向客户端32提供api参数,对此api参数的内容不做限制,该api参数能够促使加速器311实现相关任务,客户端32可以获取到应用程序321的加速处理参数。
示例性的,上述加速处理参数(如api参数)可以包括但不限于以下之一或者任意组合:加速函数库名称,api(即函数)名称,api属性值,客户端id,客户端进程id,客户端线程id等,对此加速处理参数的内容不做限制。
步骤402,客户端32对该api参数进行封装,得到加速处理请求(如api请求)。例如,客户端32可以对api参数进行api封装,得到api请求。
参见上述实施例,函数代理库322可以包括第二库文件,且第二库文件可以包括大量api函数,因此,客户端32可以从函数代理库322中获取第二库文件,并根据第二库文件对该api参数进行api封装,得到api请求。例如,基于第二库文件中的api函数,客户端32可以利用api函数对该api参数进行api封装,得到api请求,对此封装方式不做限制,与api函数的功能有关。
示例性的,在步骤401和步骤402中,应用程序321可以向函数代理库322提供api参数,函数代理库322对该api参数进行封装,得到加速处理请求。例如,可以根据加速函数库名称加载相应的真实加速函数库,并获取相应的api指针,根据api指针调用该api,最终根据该api得到api请求。
步骤403,客户端32将该api请求发送给服务端31。
参见上述实施例,客户端32可以包括网络通信层323,可以由客户端32的网络通信层323将该api请求发送给服务端31的网络通信层312。
步骤404,服务端31接收客户端32发送的api请求。
例如,服务端31的网络通信层312接收客户端32发送的api请求。
步骤405,服务端31对该api请求进行api解封装处理,得到api参数。
参见上述实施例,服务端31可以包括api服务模块313,可以将api请求发送给api服务模块313,api服务模块313在接收到该api消息时,可以对该api消息进行解封装,得到api参数,即步骤401的应用程序321的api参数。
步骤406,服务端31根据该api参数生成待处理任务。
示例性的,服务端31可以从真实加速器库314中获取应用程序的第一库文件,并根据第一库文件以及该api参数生成待处理任务。例如,可以将api参数提供给真实加速器库314,真实加速器库314将api参数代入到第一库文件中的api函数,从而基于api函数和api参数得到待处理任务。
示例性的,由于真实加速器库314包括第一库文件,且第一库文件包括大量api函数,这些api函数均是与加速器311有关的函数,基于这些api函数生成能够被加速器311处理的任务,因此,在将api参数代入到第一库文件中的api函数后,就可以生成能够被加速器311处理的待处理任务。
步骤407,服务端31将待处理任务发送给加速器311。
步骤408,加速器311处理该待处理任务。
示例性的,加速器311是能够对该待处理任务进行处理的模块,因此,在将待处理任务发送给加速器311后,加速器311可以对该待处理任务进行处理。
可选地,在步骤408之后,还包括包括以下步骤(在图中未示出):
步骤409,服务端31获取该待处理任务对应的任务处理结果。
步骤410,服务端31对该任务处理结果进行api封装处理,得到api响应。
参见上述实施例,服务端31可以包括api服务模块313,可以将任务处理结果发送给api服务模块313,api服务模块313在接收到该任务处理结果时,可以对该任务处理结果进行封装处理,得到api响应(即加速处理响应)。
步骤411,服务端31将该api响应发送给客户端32。
参见上述实施例,服务端31可以包括网络通信层312,可以由服务端31的网络通信层312将该api响应发送给客户端32的网络通信层323。
步骤412,客户端32接收服务端31针对api请求返回的api响应。
例如,客户端32的网络通信层323接收服务端31返回的api响应。
步骤413,客户端32对api响应进行api解封装处理,得到任务处理结果。
参见上述实施例,函数代理库322可以包括第二库文件,且第二库文件可以包括大量api函数,因此,客户端32可以从函数代理库322中获取第二库文件,并根据第二库文件对该api响应进行api解封装处理,得到任务处理结果。例如,基于第二库文件中的api函数,客户端32可以利用api函数对该api响应进行api解封装处理,得到任务处理结果,对此解封装方式不做限制。
步骤414,客户端32将任务处理结果返回给应用程序321。
在一个例子中,上述执行顺序只是为了方便描述给出的一个示例,在实际应用中,还可以改变步骤之间的执行顺序,对此执行顺序不做限制。而且,在其它实施例中,并不一定按照本说明书示出和描述的顺序来执行相应方法的步骤,其方法所包括的步骤可以比本说明书所描述的更多或更少。此外,本说明书中所描述的单个步骤,在其它实施例中可能被分解为多个步骤进行描述;本说明书中所描述的多个步骤,在其它实施例也可能被合并为单个步骤进行描述。
基于上述技术方案,本申请实施例中,通过将加速器部署在服务端,且由服务端为多个客户端提供服务,从而使得多个用户共用同一个加速器,即每个用户均使用自身的客户端访问服务端,继而使用加速器的资源。上述方式能够提高每个加速器的利用率,非常适用于加速器利用率较低的应用场景。
在一种可能的实施方式中,参见图5a所示,api请求的执行顺序可以为串行执行(即同步执行),以下结合图5a对api请求的串行执行过程进行说明。
假设客户端启动cpu线程10和cpu线程11,服务端启动cpu线程20和cpu线程21,cpu线程20与cpu线程10对应,cpu线程21与cpu线程11对应。cpu线程10生成api请求0,并将api请求0发送给服务端,服务端上与cpu线程10对应的cpu线程20可以处理该api请求0,也就是说,根据api请求0获得待处理任务k0,继而由加速器311对k0进行处理。
在k0处理完成(cpu线程20向客户端返回任务处理结果,且任务处理结果被传输给应用程序时,表示k0处理完成)后,cpu线程11可以生成api请求1,并将api请求1发送给服务端,cpu线程21根据api请求1获得待处理任务k1,由加速器311对k1进行处理。在k1处理完成后,cpu线程10可以生成api请求2,并将api请求2发送给服务端,cpu线程20根据api请求2获得待处理任务k2,由加速器311对k2进行处理。在k2处理完成后,cpu线程11可以生成api请求3,并将api请求3发送给服务端,cpu线程21根据api请求3获得待处理任务k3,由加速器311对k3进行处理,以此类推。
在上述方式中,对于每个api请求,客户端向服务端发送api请求后,会处理空闲状态,一直到待处理任务执行完成且返回任务处理结果后,才会从api调用返回,将执行权返还给用户程序,然后用户程序再调用下一个api请求。
在另一种可能的实施方式中,参见图5b所示,api请求的执行顺序可以为并行执行(即异步执行),以下结合图5b对api请求的并行执行过程进行说明。
假设客户端启动cpu线程10和cpu线程11,服务端启动cpu线程20和cpu线程21,cpu线程20与cpu线程10对应,cpu线程21与cpu线程11对应。cpu线程10生成api请求0,并将api请求0发送给服务端,服务端上与cpu线程10对应的cpu线程20可以处理该api请求0,也就是说,根据api请求0获得待处理任务k0,继而由加速器311对k0进行处理。
与图5a不同的是,cpu线程10将api请求0发送给服务端后,可以立即向应用程序返回预测的任务处理结果,为了与图5a的任务处理结果进行区分,将该任务处理结果称为预测任务处理结果,即不是由服务端返回的任务处理结果,而是cpu线程10根据自身当前状态生成的预测任务处理结果。
当cpu线程10向应用程序返回预测任务处理结果时,加速器311可能未对k0进行处理。此时,cpu线程10可以继续处理api请求2,从而减少api请求的等待时间。服务端上的cpu线程21根据api请求1获得待处理任务k1,由加速器311对k1进行处理。
cpu线程11将api请求1发送给服务端后,可以立即向应用程序返回预测任务处理结果,在向应用程序返回预测任务处理结果后,cpu线程10可以生成api请求2,并将api请求2发送给服务端。服务端上的cpu线程20可以根据api请求2获得待处理任务k2,由加速器311对k2进行处理。
cpu线程10将api请求2发送给服务端后,可以立即向应用程序返回预测任务处理结果,在向应用程序返回预测任务处理结果后,cpu线程11可以生成api请求3,并将api请求3发送给服务端。服务端上的cpu线程21可以根据api请求3获得待处理任务k3,由加速器311对k3进行处理,以此类推。
如果加速器311执行的结果与预测的结果不一致,可以通过后续的某个api返回,或者通过客户端定期查询,或者通过服务端向客户端的主动消息推送机制,来通知到客户端某处执行出错,此处通知方式不限。
在上述方式中,可以将api请求改为异步执行,客户端向服务端发送api请求后,不需要等到待处理任务执行完成且返回任务处理结果后,才从api调用返回,而是向服务端发送api请求后,直接从api调用返回,将执行权返还给用户程序,由用户程序再调用下一个api请求,避免长时间处理空闲状态。这样,可以使得客户端与服务端的执行异步化,隐藏一定的网络延时,减少整体执行时间。综上所述,当api返回时,加速器311可能还未对待处理任务进行处理,而cpu就可以继续执行下一个api请求。因此,可以将api请求改为异步执行,从而减少整体执行时间。
但是,参见图5c所示,在网络不稳定或者拥堵的情况下,多个cpu线程对应的服务端收到api请求的顺序可能会改变,从而导致加速器的执行顺序改变,导致功能错误。例如,cpu线程10将api请求0发送给服务端,cpu线程11将api请求1发送给服务端,cpu线程10将api请求2发送给服务端,cpu线程11将api请求3发送给服务端。服务端先接收到api请求0,然后接收到api请求1,接收到api请求3,最后接收到api请求2。这样,加速器311先对api请求0对应的k0进行处理,然后对api请求1对应的k1进行处理,对api请求3对应的k3进行处理,最后对api请求2对应的k2进行处理。
显然,由于api请求2与api请求3的接收顺序发生改变,即先接收到api请求3,后接收到api请求2,因此,导致加速器311先对k3进行处理,后对k2进行处理,即k2与k3的执行顺序改变,可能导致业务处理错误。
示例性的,为了解决上述问题,本申请实施例中可以采用如下方式:
方式1:客户端并行发送,服务端保证待处理队列a的正确序列化(待处理队列的数量可以为多个,后续以一个待处理队列a为例)。也就是说,客户端cpu线程10将api请求发送给服务端,经服务端cpu线程20然后添加到待处理队列a,客户端cpu线程11将api请求发送给服务端,经服务端cpu线程21添加到待处理队列a。
示例性的,客户端为待处理队列a维护一个全局计数器,该全局计数器的初始计数值可以为0(当然,也可以为其它数值,以0为例)后续过程中,每次在待处理队列a中添加1个api请求,就将全局计数器的计数值加1。每个发送给服务端的请求,都包含发送时的计数值。
cpu线程10在得到api请求0后,确定待处理队列a的全局计数器的计数值,此时,全局计数器的计数值为0。然后,以此计数值0作为api请求0对应的序号值,并将序号值0添加到api请求0中,发送给服务端。然后计数器的计数值加1,即计数值变为1。
cpu线程11在得到api请求1后,确定待处理队列a的全局计数器的计数值,此时,全局计数器的计数值为1。然后,以此计数值1作为api请求1对应的序号值,并将序号值1添加到api请求1中,发送给服务端。然后计数器的计数值加1,即计数值变为2。
cpu线程10在得到api请求2后,确定待处理队列a的全局计数器的计数值,此时,全局计数器的计数值为2。然后,以此计数值2作为api请求2对应的序号值,并将序号值2添加到api请求2中,发送给服务端。然后计数器的计数值加1,即计数值变为3。
cpu线程11在得到api请求3后,确定待处理队列a的全局计数器的计数值,此时,全局计数器的计数值为3。然后,以此计数值3作为api请求3对应的序号值,并将序号值3添加到api请求3中,发送给服务端。然后计数器的计数值加1,即计数值变为4,以此类推。
综上所述,基于待处理队列a中每个api请求的顺序,先将api请求0发送给服务端,然后将api请求1发送给服务端,然后将api请求2发送给服务端,最后将api请求3发送给服务端。进一步的,假设服务端先接收到api请求0,然后接收到api请求1,然后接收到api请求3,最后接收到api请求2。
示例性的,服务端也为待处理队列a维护一个全局计数器,该全局计数器的初始计数值可以为0(当然,也可以为其它数值,以0为例,后续过程中,每次在待处理队列a中添加1个api请求,就将全局计数器的计数值加1)。
在接收到api请求0后,先判断api请求0是否为待处理队列a的目标api请求,例如,可以根据api请求0的序号值和待处理队列a的全局计数器的计数值,确定api请求0是否为待处理队列a的目标api请求。显然,由于服务端全局计数器的计数值为0,api请求0包含的发送端序号值也为0,因此,可以确定api请求0为待处理队列a的目标api请求。然后,可以将api请求0添加到待处理队列a。
在接收到api请求1后,先判断api请求1是否为待处理队列a的目标api请求。由于全局计数器的计数值为1(该计数值表示待处理队列a中最后一个api请求的序号值),api请求1的序号值为1,因此,可以确定api请求1为待处理队列a的目标api请求。然后,可以将api请求1添加到待处理队列a。
在接收到api请求3后,先判断api请求3是否为待处理队列a的目标api请求。由于全局计数器的计数值为2,api请求3的序号值为3,即api请求3的序号值3与全局计数器的计数值2之间的差值为1,因此,可以确定api请求3不为待处理队列a的目标api请求,不将api请求3添加到待处理队列a。
在接收到api请求2后,先判断api请求2是否为待处理队列a的目标api请求。由于全局计数器的计数值为2,api请求2的序号值为2,即api请求2的序号值2与当前服务端全局计数器的计数值2相等,因此,api请求2为待处理队列a的目标api请求,可以将api请求2添加到待处理队列a。
进一步的,在将api请求2添加到待处理队列a之后,则api请求3的序号值3与全局计数器的计数值3相等,因此,确定api请求3为待处理队列a的目标api请求,并将api请求3添加到待处理队列a。
综上所述,待处理队列a中每个api请求的顺序为:api请求0、api请求1、api请求2、api请求3,也就是说,虽然先接收到api请求3,后接收到api请求2,但是,可以基于api请求2的序号值和api请求3的序号值,将api请求2排序在api请求3的前面,保证了api请求的正确顺序关系。
基于待处理队列a中每个api请求的顺序,可以根据api请求0获得待处理任务k0,根据api请求1获得待处理任务k1,根据api请求2获得待处理任务k2,根据api请求3获得待处理任务k3,综上所述,加速器311先对k0进行处理,然后对k1进行处理,然后k2进行处理,最后对k3进行处理。
综上所述,客户端可以为每个待处理队列维护一个全局计数器,多个cpu线程共享该全局计数器,实现时利用atomic(原子)实现cpu线程间的无锁同步,减少开销。服务端也可以为每个待处理队列维护一个全局计数器,多个cpu线程共享该全局计数器,同样利用atomic实现cpu线程间的无锁同步。
方式2:客户端维护待处理队列b,该处理队列对应一个全局的锁,以此来保证往队列读写一致性保护。此外还会为待处理队列b创建专属的发送线程cpu线程tx,区别于由应用程序创建的cpu线程10/11,该专属发送线程tx在函数代理层中创建。对应的,服务端也仅为待处理队列b创建一个专属的接收cpu线程tr。客户端和服务端都不会为待处理队列b创建多个cpu线程。
来自应用程序的cpu线程10/11将api请求0、api请求1、api请求2和api请求3依次添加到待处理队列b中:cpu线程10获取全局锁,将api请求0加入待处理队列b,然后释放锁。cpu线程11获取全局锁,将api请求1加入待处理队列b,然后释放锁。cpu线程10获取全局锁,将api请求2加入待处理队列b,然后释放锁。cpu线程11获取全局锁,将api请求3加入待处理队列b,然后释放锁,以此类推。
专属发送线程tx获取全局锁,从待处理队列b中取出api请求0,释放全局锁,然后将api请求0发送给服务端。专属发送线程tx获取全局锁,从待处理队列b中取出api请求1,释放全局锁,然后将api请求1发送给服务端,以此类推。
基于上述发送顺序,网络协议会保证在单个网络连接链路上的顺序一致性,因此服务端接收进程tr会以相同的顺序收到请求,然后发往真实函数库。
综上所述,客户端可以为待处理队列创建一个对应的cpu线程,这个cpu线程管理该待处理队列,当其它cpu线程要发送api请求到服务端时,不是直接发送给自身对应的服务端线程,而是发送到待处理队列,由该待处理队列专属的cpu线程去向服务端发送。显示,上述方式是在客户端完成多个cpu线程间待处理队列的合并,这样,服务端就不存在时序竞争问题了。
基于与上述方法同样的申请构思,本申请实施例还提供一种任务处理装置,应用于服务端,如图6a所示,为所述装置的结构图,所述装置包括:
接收模块611,用于接收客户端发送的加速处理请求;
处理模块612,用于对所述加速处理请求进行处理,得到加速处理参数;
生成模块613,用于根据所述加速处理参数生成待处理任务;发送模块614,用于将所述待处理任务发送给加速器,以使所述加速器处理所述待处理任务。
示例性的,所述加速处理请求包括应用程序编程接口api请求,所述加速处理参数包括api参数;所述处理模块612具体用于:对所述加速处理请求进行api解封装处理,得到所述加速处理参数。
所述生成模块613具体用于:从真实加速器库中获取应用程序的第一库文件;根据所述第一库文件以及所述加速处理参数生成待处理任务。
所述处理模块612还用于:获取所述待处理任务对应的任务处理结果;对所述任务处理结果进行api封装处理,得到加速处理响应;
所述发送模块614还用于:将所述加速处理响应发送给所述客户端。
基于与上述方法同样的申请构思,本申请实施例还提供一种任务处理装置,应用于客户端,如图6b所示,为所述装置的结构图,所述装置包括:
获取模块621,用于获取应用程序的加速处理参数;处理模块622,用于对所述加速处理参数进行封装,得到加速处理请求;发送模块623,用于将所述加速处理请求发送给服务端,以使所述服务端根据所述加速处理参数生成待处理任务,并将所述待处理任务发送给加速器进行处理。
所述加速处理参数包括api参数,所述加速处理请求包括api请求;所述处理模块622具体用于:从函数代理库中获取应用程序的第二库文件;根据第二库文件对所述加速处理参数进行api封装,得到加速处理请求。
所述处理模块622还用于:从函数代理库中获取第二库文件之前,从服务端的真实加速器库的第一库文件中解析api函数信息;根据所述api函数信息生成应用程序的第二库文件;将所述第二库文件存储到函数代理库中。
示例性的,所述处理模块622还用于:接收所述服务端针对所述加速处理请求返回的加速处理响应;对所述加速处理响应进行api解封装处理,得到任务处理结果;将所述任务处理结果返回给所述应用程序。
基于与上述方法同样的申请构思,本申请实施例还提供一种服务端设备,包括:处理器和机器可读存储介质,所述机器可读存储介质上存储有若干计算机指令,所述处理器执行所述计算机指令时进行如下处理:
接收客户端发送的加速处理请求;
对所述加速处理请求进行处理,得到加速处理参数;
根据所述加速处理参数生成待处理任务;
将所述待处理任务发送给加速器,以使所述加速器处理所述待处理任务。
进一步的,本申请实施例还提供一种机器可读存储介质,所述机器可读存储介质上存储有若干计算机指令;所述计算机指令被执行时进行如下处理:
接收客户端发送的加速处理请求;
对所述加速处理请求进行处理,得到加速处理参数;
根据所述加速处理参数生成待处理任务;
将所述待处理任务发送给加速器,以使所述加速器处理所述待处理任务。
基于与上述方法同样的申请构思,本申请实施例还提供一种客户端设备,包括:处理器和机器可读存储介质,所述机器可读存储介质上存储有若干计算机指令,所述处理器执行所述计算机指令时进行如下处理:
获取应用程序的加速处理参数;
对所述加速处理参数进行封装,得到加速处理请求;
将所述加速处理请求发送给服务端,以使所述服务端根据所述加速处理参数生成待处理任务,并将所述待处理任务发送给加速器进行处理。
进一步的,本申请实施例还提供一种机器可读存储介质,所述机器可读存储介质上存储有若干计算机指令;所述计算机指令被执行时进行如下处理:
获取应用程序的加速处理参数;
对所述加速处理参数进行封装,得到加速处理请求;
将所述加速处理请求发送给服务端,以使所述服务端根据所述加速处理参数生成待处理任务,并将所述待处理任务发送给加速器进行处理。
参见图7a所示,为本申请实施例中提出的服务端设备的结构图,所述服务端设备可以包括:处理器711,网络接口712,总线713,存储器714。存储器714可以是任何电子、磁性、光学或其它物理存储装置,可以包含或存储信息,如可执行指令、数据等等。例如,存储器714可以是:ram(radomaccessmemory,随机存取存储器)、易失存储器、非易失性存储器、闪存、存储驱动器(如硬盘驱动器)、固态硬盘、任何类型的存储盘(如光盘、dvd等)。
参见图7b所示,为本申请实施例中提出的客户端设备的结构图,所述客户端设备可以包括:处理器721,网络接口722,总线723,存储器724。存储器724可以是任何电子、磁性、光学或其它物理存储装置,可以包含或存储信息,如可执行指令、数据等等。例如,存储器724可以是:ram(radomaccessmemory,随机存取存储器)、易失存储器、非易失性存储器、闪存、存储驱动器(如硬盘驱动器)、固态硬盘、任何类型的存储盘(如光盘、dvd等)。
上述实施例阐明的系统、装置、模块或单元,具体可以由计算机芯片或实体实现,或者由具有某种功能的产品来实现。一种典型的实现设备为计算机,计算机的具体形式可以是个人计算机、膝上型计算机、蜂窝电话、相机电话、智能电话、个人数字助理、媒体播放器、导航设备、电子邮件收发设备、游戏控制台、平板计算机、可穿戴设备或者这些设备中的任意几种设备的组合。
为了描述的方便,描述以上装置时以功能分为各种单元分别描述。当然,在实施本申请时可以把各单元的功能在同一个或多个软件和/或硬件中实现。
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请实施例可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可以由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其它可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其它可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
而且,这些计算机程序指令也可以存储在能引导计算机或其它可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或者多个流程和/或方框图一个方框或者多个方框中指定的功能。
这些计算机程序指令也可装载到计算机或其它可编程数据处理设备上,使得在计算机或者其它可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其它可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
以上所述仅为本申请的实施例而已,并不用于限制本申请。对于本领域技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本申请的权利要求范围之内。
- 还没有人留言评论。精彩留言会获得点赞!