一种基于多任务卷积神经网络的细胞核中心点检测方法与流程
本发明涉及神经网络技术领域,尤其涉及一种基于多任务卷积神经网络的细胞核中心点检测方法。
背景技术:
ki67的表达与很多肿瘤疾病的发生密切相关,如乳腺癌、卵巢癌、淋巴癌等。临床上,常通过免疫组化的方法检测ki67指数,反映正常和病变组织或细胞的增殖活性,对良、恶性肿瘤进行鉴别诊断,帮助恶性肿瘤的早期诊断、治疗方法选择和疗效的评估。目前的ki67阳性表达率确定方法是病理专家在镜下检查,但这非常耗时并且伴随低一致性的风险,目前越来越多的机构在尝试构建一个计算机辅助诊断系统协助病理专家进行ki67计数,但都无法避免出现假阳性和假阴性问题。
许多密集细胞检测的工作都用高斯核来表征肿瘤细胞并训练全卷积网络去回归细胞的中心点,这在多类目标检测下存在假阴性高和收敛速度慢的问题。
另外有些工作直接标注细胞核,用一个圆形结构元来表征整个细胞,这样训练出来的模型存在一个细胞有多个中心点的假阳问题。
技术实现要素:
本发明旨在提供一种基于多任务卷积神经网络的细胞核中心点检测方法,解决了病理图像细胞核检测时直接回归高斯核或者等值结构元分割的时候存在的假阴性、假阳性、收敛速度慢问题。
为达到上述目的,本发明是采用以下技术方案实现的:
本发明公开一种基于多任务卷积神经网络的细胞核中心点检测方法,包括以下步骤,
s100、数据准备:
s110、对原始图像进行打点标注,其中使用不同的颜色的标记标注阳性、阴性,得到标记图,
s120、获取标记图中标记的中心点坐标:
s121、使用高斯核替换标记图中的中心矩形块得到单类高斯核的掩模,
s122、使用等值结构元替换标记图中的中心矩形块得到两类等值核的掩模;
s200、建立模型,模型结构包括分割模型、多任务模型;
s300、训练模型,包括:
s310、使用原始图像和两类等值核训练,得到两类分割模型,
s320、固定两类分割模型的特征提取模块参数,
s330、使用两类分割模型的特征提取模块参数初始化多任务模型的特征提取模块的参数,
s340、模型收敛时终止训练,固定模型参数;
s400、将图片输入训练后的模型,得到单类高斯核的掩模和两类等值核的掩模;
s500、将单类高斯核的掩模输入极值点寻找模块,输出所有极值点的坐标;
s600、将两类等值核的掩模输入形态学处理模块,统计连通域,输出连通域标记图像;
s700、将极值点的坐标和连通域标记图像输入极值点类别判断模块,输出最终极值点及表征的细胞核类别集合,
其中极值点类别判断模块的判断逻辑为:
a、若极值点落在连通域内,则采纳该极值点作为中心点,此连通域不再寻找中心点,
b、若极值点部分落在连通域外,且极值点的像素值大于预设的阈值,裁切极值点,计算该平均灰度值,根据平均灰度值计算极值点类别,
c、若连通域内没有极值点,则分析连通域确定中心点。
优选的,步骤s200中,分割模型使用两类等值核计算交叉熵损失,
多任务模型使用两类等值核计算交叉熵损失和单类高斯核计算huber损失的加权和作为总损失。
优选的,步骤s330步骤后设置有步骤s331、结合分割模型中两类等值核计算交叉熵损失和多任务模型的总损失调整特征提取模块的参数。
优选的,步骤s700中,极值点类别判断模块的判断逻辑的步骤b中,
在分割输出分支裁切概率图中以极值点为中心所在的矩形块,计算该矩形块的平均灰度值,
当平均灰度值<0.5时,不采纳该极值点,
当0.5<平均灰度值≤阈值b时,该极值点表征阴性细胞的中心点,
当阈值b<平均灰度值时,该极值点为表征阳性细胞的中心点。
优选的,阈值a为0.5,阈值b为1.5,在分割输出分支裁切概率图中以极值点为中心所在的矩形块边长为15个像素点。
优选的,极值点类别判断模块的判断逻辑的步骤c包括以下步骤,
c1、确定连通域的中心点,
c2、连通域的中心点15个像素点内无极值点,则以该连通域的中心点表征细胞核中心点,
c3、连通域的中心点15个像素点内有极值点,则取距离连通域的中心点最近的极值点表征细胞核中心点,对连通域的中心点不予采纳。
优选的,步骤s400中,输入的图像为rgb三通道图像。
优选的,步骤s200中,分割模型、多任务模型均为全卷积模型。
本发明的有益效果:
1、本发明解决了圆形结构元表征细胞核的一个细胞核多个中心点预测的假阳性问题;
2、本发明解决了高斯核表征细胞核的假阴性问题和模型难以收敛问题;
3、本发明在检测性能提高的同时,没有增加数据标注难度。
附图说明
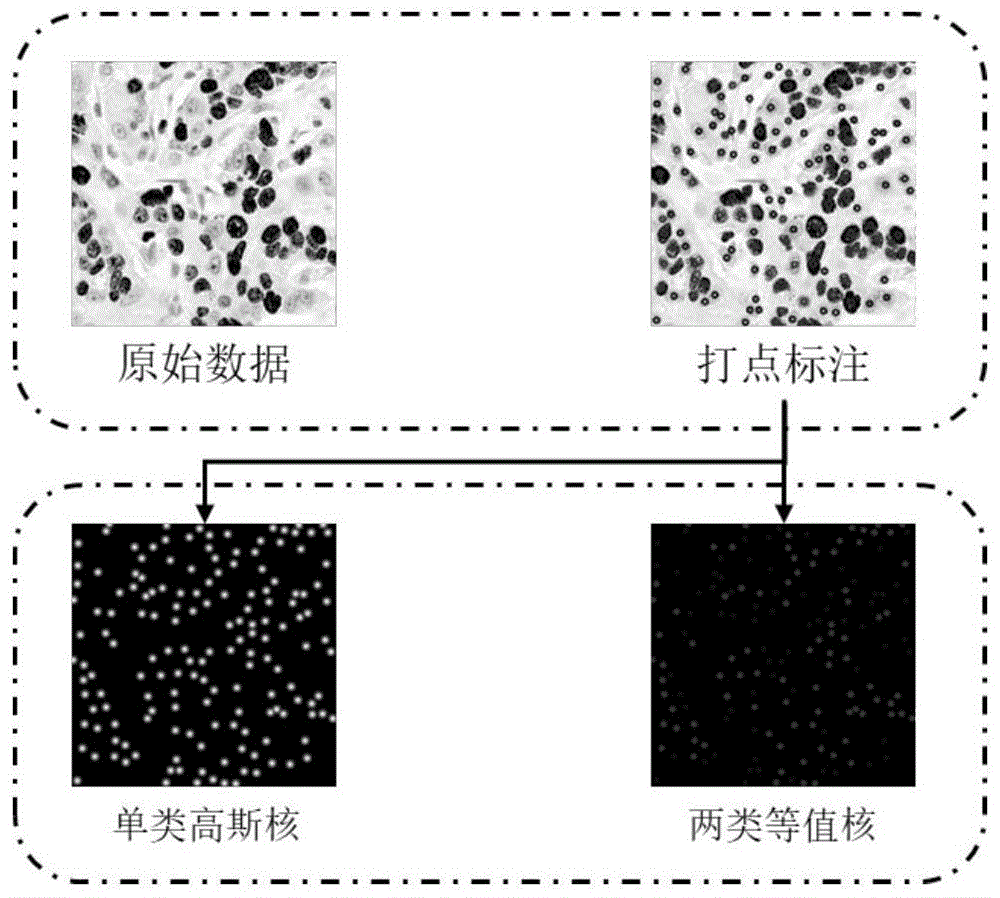
图1为步骤s100的示意图;
图2为步骤s300~s400的示意图;
图3为步骤s500~s700的示意图;
图4为recall性能评估曲线;
图5为precision性能评估曲线;
图6为f-measure性能评估曲线。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明进行进一步详细说明。
简单而言,本发明包括数据准备、模型结构设计和模型后处理。
数据准备:数据标注时直接对细胞核的中心点进行打点标注,训练时的两类掩模可直接根据打点的坐标生成,其中单类高斯核为中心点与标注的中心点重合的高斯分布二维数组,两类等值核为中心点与标注数据重合的等值圆形结构元二维数组。
模型结构设计:本方案采用的是全卷积网络结构,包括不限于经典的fcn网络结构,先使用两类等值结构掩模训练一个两类分割模型,使用分割模型的参数初始化多任务模型的参数,再联合两个任务分支的损失微调整个模型。
模型后处理:预测时输入为rgb三通道图像,模型输出为两类分割图和单类概率图,结合两个网络输出进一步确定最终细胞核的位置和类别。
如图1~3所示,本发明包括以下步骤,
s100、数据准备:
s110、对原始图像进行打点标注,其中使用不同的颜色的标记标注阳性、阴性,得到标记图,
s120、获取标记图中标记的中心点坐标:
s121、使用高斯核替换标记图中的中心矩形块得到单类高斯核的掩模,
s122、使用等值结构元替换标记图中的中心矩形块得到两类等值核的掩模,将阴性细胞标为1,阳性细胞标为2,
其中单类高斯核为中心点与标注的中心点重合的高斯分布二维数组,两类等值核为中心点与标注数据重合的等值圆形结构元二维数组;
s200、建立模型,模型结构包括分割模型、多任务模型,分割模型、多任务模型均为全卷积模型,包括不限于经典的fcn网络结构,其中分割模型使用两类等值核计算交叉熵损失,
多任务模型使用两类等值核计算交叉熵损失和单类高斯核计算huber损失的加权和作为总损失;
s300、训练模型,包括:
s310、使用原始图像和两类等值核训练,得到两类分割模型,
s320、固定两类分割模型的特征提取模块参数,
s330、使用两类分割模型的特征提取模块参数初始化多任务模型的特征提取模块的参数,
s331、结合分割模型中两类等值核计算交叉熵损失和多任务模型的总损失调整特征提取模块的参数,
s340、模型收敛时终止训练,固定模型参数;
s400、将图片输入训练后的模型,该图片为rgb三通道图像,得到单类高斯核的掩模和两类等值核的掩模;
s500、将单类高斯核的掩模输入极值点寻找模块,输出所有极值点的坐标;
s600、将两类等值核的掩模输入形态学处理模块,统计连通域,输出连通域标记图像;
s700、将极值点的坐标和连通域标记图像输入极值点类别判断模块,输出最终极值点及表征的细胞核类别集合,
其中极值点类别判断模块的判断逻辑为:
a、若极值点落在连通域内,则采纳该极值点作为中心点,此连通域不再寻找中心点,
b、若极值点部分落在连通域外,且极值点的像素值大于预设的阈值,裁切以极值点为中心,边长15个像素点的矩形块,计算矩形块的平均灰度值,结合平均灰度值和阈值,判断是否符合检出的类别,若符合则采纳,不符合则不采纳,
c、若连通域内没有极值点,则分析连通域确定中心点。
对该方法进行评估:
定义人工标记的数据为金标准,预测时我们采用匈牙利算法将单张图片上的细胞核中心与人工标记做配对计算命中情况,点之间的距离采用曼哈顿距离计算。当点与点之间的距离低于细胞核的半径才有记为命中的可能,如果一个人工标记点附近有两个预测的点,则最近的预测点记为命中tp,另外一个记为假阳性预测fp。如果人工标记的某个点周边没有任何一个预测点与它的距离低于细胞核的平均半径,则将该点记为假阴性预测fn。
综上,我们将从recall、precision、f-measure三个角度来对比算法结果。
三个指标的计算方式分别如下所示:
recall:
precision:
f1-measure:
本次实验将采集三组数据,分别为只回归等值核的实验结果,只回归高斯核的实验结果,以及按本发明实施同时回归两个任务的结果,同时从recall、precision、f-measure三个性能评估指标和收敛速度几个角度来评估算法的表现,评估结果如图4~6所示,
图4中红色线为等值核的recall结果,绿色线为高斯核的recall结果,蓝色线为多任务的recall结果,
图5中红色线为等值核的precision结果,绿色线为高斯核的precision结果,蓝色线为多任务的precision结果,
图6中红色线为等值核的f1-measure结果,绿色线为高斯核的f1-measure结果,蓝色线为多任务的f1-measure结果,
从上述三个表格展示的结果我们可以得出以下几个结论:
采用多任务学习的方式显著提升了细胞核的召回率,减少漏检的细胞核;
采用多任务学习的方式虽然precision较单任务高斯核有所下降,但是f1-measure与单任务等值核持平,且显著优于单任务高斯核;
采用多任务学习的方式从precision和f1-measure两个指标上看收敛速度稍快于单任务等值核,且显著优于单任务高斯核;
本任务更加侧重recall,多任务recall优于单任务等值核模型,且f1-measure持平,因此更优。
当然,本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,熟悉本领域的技术人员可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!