一种融合注意力机制的表情合成方法与流程
本发明涉及深度学习和图像处理技术领域,特别是一种融合注意力机制的表情合成方法。
背景技术:
人脸图像合成是计算机视觉和图形学领域一个广泛研究的课题。面部表情不仅是一种微妙的形体语言,更是人们传递情感信息的重要方式。近年来,随着计算机信息技术和服务的发展,人们越来越希望计算机的通信能够表现出拟人化的感情,在人机交互中提供一种全新的沉浸感,这也推动了表情合成的发展。面部表情合成也成为当前研究热点之一,具有广泛的应用如人机交互,虚拟现实,数字娱乐等领域。
由于不同表情之间存在人脸面部几何的非线性变化,而且不同个体的表情变化强度也是不同的,因此面部表情的合成工作具有一定的挑战性。在表情合成方面,现有的工作大部分关注于合成七种典型表情如快乐,悲伤,惊讶,愤怒等,但表情是一个变化的过程,当合成具有不同强度的表情时,会存在缺少数据标签的问题。目前关于不同强度表情合成方法大致分为两类:(1)无监督方法,利用面部几何信息进行插值拉动面部肌肉运动使人脸变形或者人工设计表情编码模块学习表情之间的变化;(2)有监督方法,使用带有表情强度标签标注的数据集进行训练。
然而,第一类方法不能很好到捕捉不同表情强度的变化过程,如面部皱纹等,导致生成的表情不自然,不够逼真;另外通过这类方法生成的图像有时候会存在缺乏精细的细节部分,往往是模糊的或者低分辨率的。第二类方法要求数据必须标注表情强度,然而在实际应用中,表情的强度是很难用一个统一的标准去定义的,这类方法虽然能实现细粒度控制,但具有局限性。
技术实现要素:
本发明的目的在于提供一种能够通过中立无表情人脸图像合成具有不同强度的人脸表情,方法直观便捷,合成的表情强度生动且人脸真实性强的表情合成方法。
实现本发明目的的技术解决方案为:一种融合注意力机制的表情合成方法,包括以下步骤:
步骤1,获取人脸表情图像的数据集;
步骤2,对表情数据集进行预处理,首先获取人脸图像的关键点信息,根据关键点位置将图像裁剪为统一大小,然后将同一类别的表情图像划分在一起,将同类表情图像划分为训练集和测试集,将训练集根据不同的表情强度手动划分成不同的类别;
步骤3,以表情强度作为条件标签,构造条件生成式对抗网络,融合通道和空间两种注意力机制,使生成的网络更关注与表情变化相关的面部部位,使用带有分类器的鉴别网络同时判别输入图像的真假和强度类别;
步骤4,在步骤3构造的网络中加入人脸图像的身份信息,使生成图像前后身份信息不变性;
步骤5,使用预处理后的表情数据集对步骤4中的网络进行训练和测试,调节网络参数,使生成图像效果达到最优;
步骤6,将测试集中的中立表情输入到训练好的条件生成对抗网络,合成带有不同强度的人脸表情图像。
本发明与现有技术相比,具有以下优点:(1)在不使用额外的表情编码等信息的辅助下,也能合成具有不同表情强度的人脸图像,方法方便直观;(2)使用了注意力机制帮助学习不同表情强度对应面部的细微变化,能合成更生动的人脸表情;(3)合成的人脸图像更加真实自然,在图像合成前后也能很好地保持身份信息。
附图说明
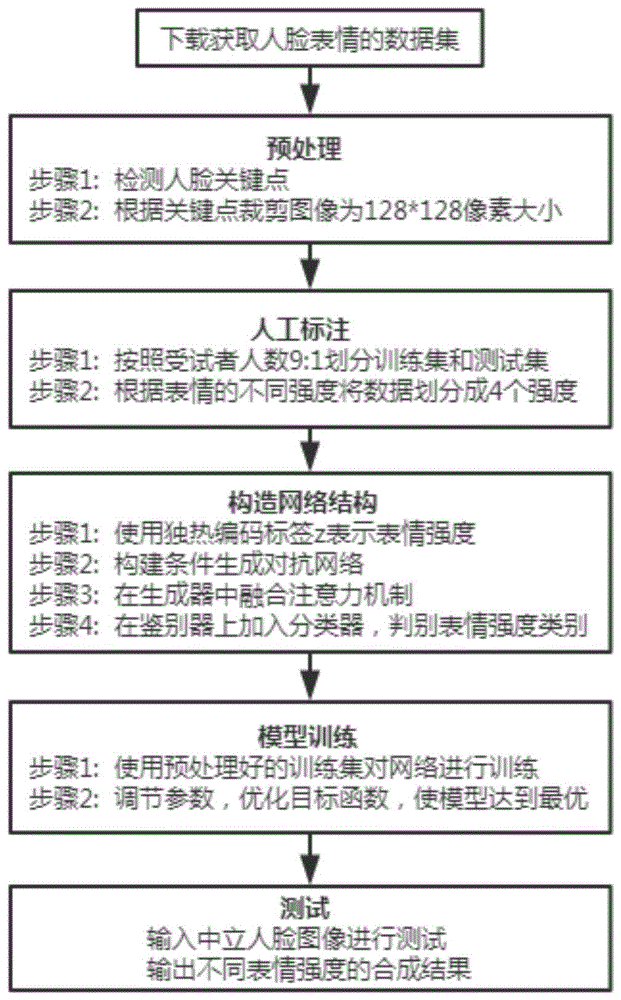
图1是本发明融合注意力机制的表情合成方法的流程示意图。
图2是本发明实施例中的人脸表情图像的合成效果图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步详细说明。
结合图1,本发明一种融合注意力机制的表情合成方法,包括以下步骤:
步骤1,获取人脸表情图像的数据集;
下载人脸表情序列的数据集,作为实验数据;
步骤2,对表情数据集进行预处理,首先获取人脸图像的关键点信息,根据关键点位置将图像裁剪为统一大小,然后将同一类别的表情图像划分在一起,将同类表情图像划分为训练集和测试集,将训练集根据不同的表情强度手动划分成不同的类别,具体操作如下:
首先进行人脸关键点检测,提取人脸图像的关键点位置并裁剪为统一大小,将不同类别的表情图像进行归类,每个类别按照受试者人数9:1的比例划分成训练集和测试集,选取中立表情作为测试输入,然后人工地将训练集按照不同的强度划分成中立,弱,中,强四个类别。
例如,得到人脸图像的68个关键点信息,计算其中5个关键点位置将图像裁剪成统一大小为128×128像素。接着受试者人数按照9:1将数据划分为训练集和测试集,然后手动地将训练集按照表情强度从弱到强依次划分成4种类别,分别是中立(无表情),弱,中,强;
步骤3,以表情强度作为条件标签,构造条件生成式对抗网络,融合通道和空间两种注意力机制,使生成的网络更关注与表情变化相关的面部部位,使用带有分类器的鉴别网络同时判别输入图像的真假和强度类别,具体如下:
构造条件生成对抗网络,在生成网络中同时融合通道和空间注意力机制,使其能更关注与表情变化相关的面部部位,在鉴别网络的输出层上额外加一个分类器,用来判别生成图像所属的表情强度类别,使其在辨别图像真假的同时还能判断表情所属的强度;
步骤3.1、使用一个独热编码向量z表示图像x的表情强度,作为条件标签,控制生成器合成带有目标表情强度的图像;
步骤3.2、在生成网络中融入注意力机制,同时结合通道和空间两种注意力机制,使生成的网络更关注与表情变化相关的面部部位;
(1)通道注意力在提取语义属性时能强调相关特征而忽略不相关特征,首先对输入图像的特征图u=[u1,u2,…,uc]进行全局平均池化,嵌入全局空间信息,用p表示通道统计量,p的第k个元素表示为:
其中,h和w分别表示图像的高度和宽度,c表示通道数,pk表示第k个通道统计量,i∈{1,2,…,h},j∈{1,2,…,w},(i,j)表示特征点的位置,uk(i,j)表示第k个通道在位置(i,j)处的特征值;
接着通过下采样和上采样层提取特征模式并使用sigmoid函数进行归一化,表示为:
其中,
最后经过通道注意力校准后的特征图为
(2)空间注意力则将注意力集中在与表情强度变化相关的面部器官位置上,忽略不相关的部分;
将输入图像按照空间位置表示为u=[u1,1,u1,2,…,ui,j,…,uh,w],其中i∈{1,2,…,h},j∈{1,2,…,w},ui,j表示在位置(i,j)处的特征值;通过一个空间挤压操作将c个通道投影到一个空间位置上,最后使用sigmoid函数进行归一化,表示为:
q=sigmoid(wsq*u)
其中,向量q表示在空间上进行投影的结果,wsq表示空间挤压操作层;
最后根据空间注意力校准后的特征图为us=[q1,1u1,1,…,qi,jui,j,…,qh,wuh,w];
步骤3.3、在鉴别网络上添加一个分类器,用以输出生成图像的表情强度类别,使鉴别网络能够同时辨别图像真假和估计图像所属的表情强度类别。
步骤4,在步骤3构造的网络中加入人脸图像的身份信息,使生成图像前后身份信息不变性,具体如下:
在表情强度合成前后需要保证输入图像和输出图像的身份一致性,使用了一个身份保留损失函数来实现,定义如下:
其中,lid是身份保留损失函数,xs表示源输入图像,zt表示目标表情强度的标签,g(xs,zt)表示生成的带有目标表情强度zt的图像,φ是一个人脸识别的特征提取器,φ(xs)和φ(g(xs,zt))分别表示输入人脸图像和生成的人脸图像的身份特征,
步骤5,使用预处理后的表情数据集对步骤4中的网络进行训练和测试,调节网络参数,使生成图像效果达到最优;
步骤6,将测试集中的中立表情输入到训练好的条件生成对抗网络,合成带有不同强度的人脸表情图像。
实施例1
本实施例以ck+,mug和oulu-casia共3个数据集为例对本发明提出的基于生成式对抗网络的人脸表情图像合成方法进行研究,具体实施步骤如下:
步骤1、分别从ck+(http://www.consortium.ri.cmu.edu/ckagree/)、mug(https://mug.ee.auth.gr/fed/)和oulu-casia(https://www.oulu.fi/cmvs/node/41316)、三个网址上下载表情数据集,作为实验数据。
步骤2、对步骤1中的表情数据集进行预处理,本实施例以高兴和惊讶这两种表情为例对提出的算法进行研究。在ck+数据集中,由于其没有明确的归类表情,首先需要根据表情类别标签对图像进行归类,然后再选取其中的高兴和惊讶两类表情进行实验,该数据集仅有部分标签,为了充分利用数据,因此需要额外的将没有标签的高兴和惊讶表情进行归类。在mug数据集中,每一个受试者的单个表情含有多个重复的序列,只保留其中一个。在oulu-casia数据集中,选择正常光照条件下的图像进行实验。在表情类别分类之后,分别将高兴和惊讶表情序列均按照不同的表情强度划分为不同类别(中立,弱,中,强),作为训练数据。
步骤3、构造条件生成对抗网络,在生成网络中融合注意力机制,同时在鉴别网络中加入对表情强度的判别信息,具体如下:
步骤3.1、使用一个独热编码向量z表示图像x的表情强度,作为条件标签,控制生成器合成带有目标表情强度的图像。
步骤3.2、在生成网络中融入注意力机制,同时结合通道和空间两种注意力机制将注意力集中在与表情强度变化相关的特征上,能使生成网络更关注于表情强度改变,捕捉不同强度的细节。
步骤3.3、在鉴别网络上额外添加一个分类器,用以输出生成图像的表情强度类别,使鉴别网络能够同时辨别图像真假和估计图像所属的表情强度类别;源输入图像的表情强度的分类损失可以表示为:
这里,dintensity(zs|xs)表示源输入图像xs在源强度标签zs上的概率分布。通过最小化该损失函数来优化鉴别器对于表情强度的判别能力。类似地,目标图像的强度分类损失函数表示为:
其中,dintensity(zt|g(xs,zt))表示生成图像在目标强度zt上的概率分布。通过优化该损失函数能使生成器尽可能合成被鉴别器分类为zt的目标强度图像。这两个强度损失函数是为了能够使鉴别器进行正确的表情强度分类,同时促进生成器的合成目标强度。
步骤4,在步骤3构造的网络中加入身份保留损失函数,以保证合成图像前后人脸身份不变性,表示如下:
其中,xs表示源输入表情图像,zt表示目标表情强度标签,
步骤5,使用预处理好的表情数据对步骤4的网络进行训练和测试,调节网络参数,使网络的合成结果达到最优。
步骤6,选择中立表情进行测试,合成带有不同表情强度的人脸图像,如图2所示。
这里以ck+,mug和oulu-casia数据集中的高兴表情和惊讶表情为例,输入一个中立表情图像,依次合成不同强度的四种人脸表情图像,随着强度增加,面部肌肉运动幅度也增大,如高兴时嘴巴逐渐张大,牙齿裸露越来越多,鼻唇沟逐渐明显;惊讶时,眉毛逐渐上扬,嘴巴张大,眼睛瞪大,额头逐渐出现横皱纹等;表1和表2是3个数据集分别在高兴和惊讶表情合成的人脸验证结果,可以看出输入图像和合成图像的人脸验证置信度都较高,表明图像合成前后身份信息没有发生大的改变。
由图2,表1和表2可以看出我们的发明不仅能捕捉到不同表情强度的面部细节,图像合成前后也保证了人身份信息不变,最终生成了清晰且具有真实感的人脸图像。
表1在高兴表情合成上的人脸验证结果
表2在惊讶表情合成上的人脸验证结果
- 还没有人留言评论。精彩留言会获得点赞!