一种基于机器学习反馈规则增强的医疗保险智能审核系统的制作方法
本申请属于医疗保险审核技术领域,具体涉及一种基于机器学习反馈规则增强的医疗保险智能审核系统。
背景技术:
人类的智能主要包括归纳总结和逻辑演绎,对应着人工智能(artificialintelligence,ai)中的符号主义ai和联结主义ai。
基于符号主义的系统需要演绎归纳、逻辑推理,以及在特定模型下求解的搜索算法。这包括专家系统(通过规则与决策树从输入数据中推导出结论),约束求解器(在一些给定可能性中求解)和规划系统(从一些初始状态值中找到一系列动作来实现给定目标)。此外,这一类系统通常还包括一些能控制不确定性与风险的变量。符号主义算法会剔除不符合特定模型的备选值,并能对符合所有约束条件的所求值做出验证,以后者而言,符号主义ai远比联结主义ai便捷。因为符号主义ai几乎或根本不包括算法训练,所以这个模型是动态的,能根据需要迅速调整。
联结主义ai取名自网络拓扑学。联结主义ai中知名度最高的是人工神经网络技术(ann)。它由多层节点(即神经元)组成,这些节点可处理输入信号,并通过权重系数实现彼此的联结,并相互挤压形成下一层。该技术的关键在于,用户无需指定模拟领域的规则,神经网络可以从训练数据中自行摸索。用户只需提供输入数据与输出数据采样(数据采样规模越大种类越多,效果则越好)。联结主义算法不断采用回归模型来调节中间变量的权重系数,直到找到最优模型为止。因为这些技术是有效的误差最小化算法,所以它们天生具有抗噪性,能消除异常值并将所得数值收敛于误差范围以内。
传统的医疗保险审核系统都是基于人工审核完成的,不仅需要大量人工开销,由于大量重复性工作而导致的失误也不少,进而影响效果。随着人工智能技术的兴起,一些基于规则的医疗保险智能审核系统出现了,这些技术都是基于符号主义的ai,这一类系统过于偏重规则本身,随着数据的爆炸性增长,真实世界获得的数据复杂性也在飞速提升,规则的更新虽然方便,但是规则制定成本的增加导致符号主义ai慢慢无法满足日益提升的需求。
技术实现要素:
本申请的目的在于提供一种基于机器学习反馈规则增强的医疗保险智能审核系统,降低了医疗保险审核系统对显示规则的依赖,显著提升医疗保险审核系统的智能化、准确性和可信度。
为实现上述目的,本申请所采取的技术方案为:
一种基于机器学习反馈规则增强的医疗保险智能审核系统,所述基于机器学习反馈规则增强的医疗保险智能审核系统,包括:
数据结构化模块,用于对待审核的医疗保险记录进行结构化处理,得到带有索引值的结构化数据;
记录分词模块,用于根据索引值从结构化数据中选取部分或全部信息,拼接形成长文本信息,并对长文本信息进行分词操作得到分词表达;
文本特征提取模块,用于根据所述分词表达,采用词向量模型将词转化为向量,得到文本特征;
神经网络模块,用于根据所述文本特征输出预测概率值,并根据预测概率值对当前的医疗保险记录进行划分,若划分为高置信度记录,则将所述结构化数据以及预测概率值输入至规则引擎模块;若划分为低置信度记录,则将结构化数据输入至专家审核模块;
专家审核模块,用于接收神经网络模块输出的为低置信度记录的结构化数据,并接收专家根据该结构化数据输入的审核结果,将当前的医疗保险记录以及接收的审核结果作为反馈数据用于神经网络模块的训练;
规则引擎模块,用于接收神经网络模块输出的为高置信度记录的结构化数据以及预测概率值,根据预定义的规则引擎输出医疗保险记录的审核结果。
作为优选,所述结构化数据的表达式为:r={c1:″t1″,c2:″t2″,…,ck:″tk″},其中r为一条医疗保险记录,ci为索引值,ti为索引值ci对应的文本信息,i∈(1,k),k是索引的条目数。
作为优选,所述词向量模型可以是word2vec模型、fasttext模型或bert模型。
作为优选,所述神经网络模块包括一个二分类神经网络,所述二分类神经网络从输入侧至输出侧包括第一卷积层、第一池化层、第二卷积层、第二池化层、第一全连接层和第二全连接层;
所述二分类神经网络输入文本特征,输出0到1之间的预测概率值。
作为优选,所述二分类神经网络在训练过程中,采用根据审核结果添加标签后的医疗保险记录作为样本数据进行训练,计算预测概率值与真实的标签值之间的误差值,通过最小化二值交叉熵损失函数对二分类神经网络进行优化,所述最小化二值交叉熵损失函数的表达式为:
其中,xn为预测概率值,yn为真实的标签值,wn为对于不同类型的样本数据的权重分配,n为样本数量。
作为优选,所述不同类型的样本数据包括两个部分:第一部分由专家审核模块产生的反馈数据生成,第二部分由各医疗机构产生的带有审核结果的医疗保险记录生成。
作为优选,所述审核结果为通过或拒绝;
根据审核结果对医疗保险记录添加标签包括:若审核结果为通过,则该医疗保险记录添加的标签的标签值为1;若审核结果为拒绝,则该医疗保险记录添加的标签的标签值为0。
作为优选,所述神经网络模块根据预测概率值对当前的医疗保险记录进行划分,执行如下操作:
设定上限阈值为thh,下限阈值为thl;
若预测概率值大于上限阈值thh,则判定当前的医疗保险记录为正样本,并划分为高置信度记录;若预测概率值小于下限阈值thl,则判定当前的医疗保险记录为负样本,并划分为高置信度记录;若预测概率值在上限阈值thh和下限阈值thl之间,则判定当前的医疗保险记录为混淆样本,并划分为低置信度记录。
作为优选,所述规则引擎基于符号主义ai实现。
本申请提供的基于机器学习反馈规则增强的医疗保险智能审核系统,结合了联结主义ai与符号主义ai的优点,通过引入神经网络降低对显式规则的依赖,借用反馈式的学习方式降低对专家审核的需求,减少人工开销,并且利用专家审核后的反馈数据既更新规则引擎,又作为训练样本优化神经网络参数学习,进一步提升系统的智能化、准确性和可信度。
附图说明
图1为本申请的基于机器学习反馈规则增强的医疗保险智能审核系统的结构示意图;
图2为本申请的二分类神经网络的一种实施例结构示意图;
图3为本申请的一种医疗保险审核的实施例流程图。
具体实施方式
下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本申请一部分实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本申请保护的范围。
除非另有定义,本文所使用的所有的技术和科学术语与属于本申请的技术领域的技术人员通常理解的含义相同。本文中在本申请的说明书中所使用的术语只是为了描述具体的实施例的目的,不是在于限制本申请。
其中一个实施例中,提供一种基于机器学习反馈规则增强的医疗保险智能审核系统,该系统极大程度上弥补了传统规则引擎的局限性,对易混淆的记录进行了先验分析,降低了规则引擎错判的概率;进一步的反馈式机器学习的引入降低了人工标注成本,同时也提高了规则引擎的更新效率,显著提升医疗保险审核系统的智能化、准确性和可信度。
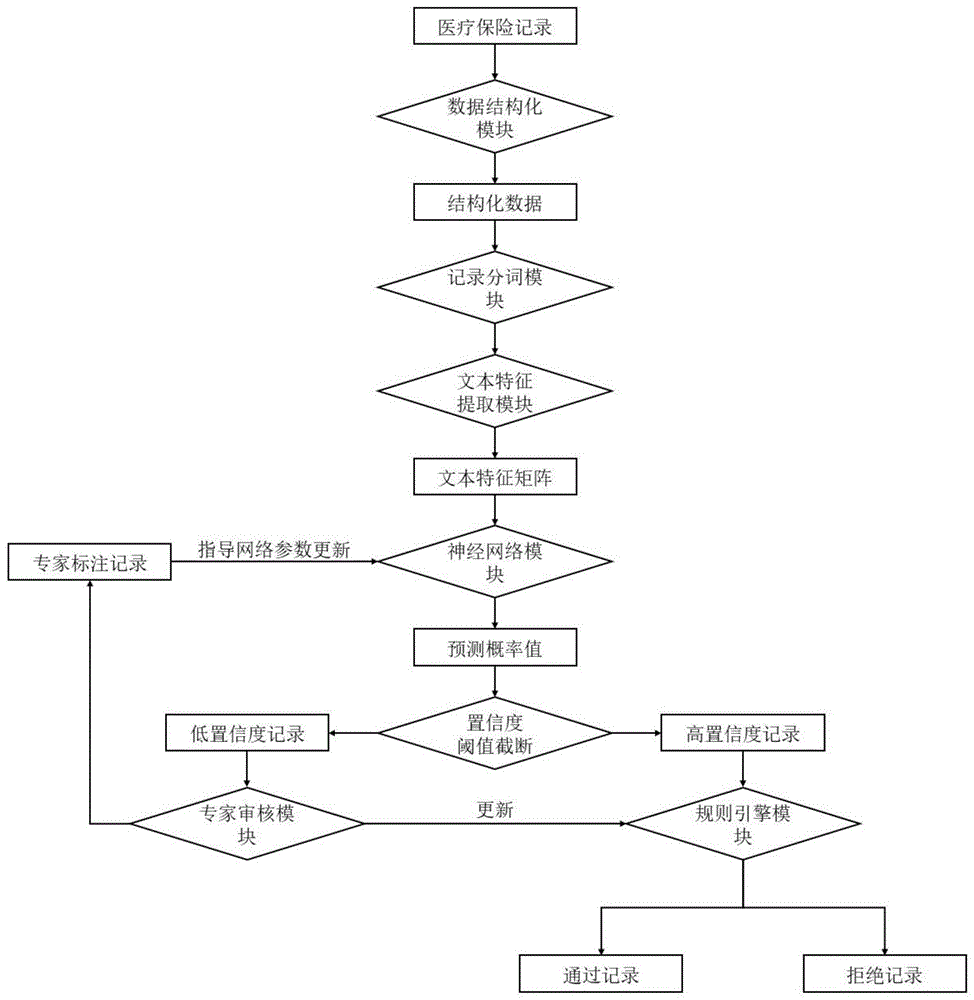
如图1所示,本实施例的基于机器学习反馈规则增强的医疗保险智能审核系统包括但不限于数据结构化模块、记录分词模块、文本特征提取模块、神经网络模块、专家审核模块、规则引擎模块,其中:
数据结构化模块,用于对待审核的医疗保险记录进行结构化处理,得到带有索引值的结构化数据。
结构化数据更加易于后续的分词,并且表示含清晰明了,在一实施例中,采用的结构化数据的表达式为:r={c1:″t1″,c2:″t2″,…,ck:″tk″},其中r为一条医疗保险记录,ci为索引值,ti为索引值ci对应的文本信息,i∈(1,k),k是索引的条目数。
记录分词模块,用于根据索引值从结构化数据中选取部分或全部信息,拼接形成长文本信息,并对长文本信息进行分词操作得到分词表达。
由于原始的医疗保险记录包含各类信息,而部分信息在进行审核是可以不作为参考属性,因此可根据需要从结构化数据中选取有价值的信息进行后续的操作,以降低系统计算压力。
在进行分词操作时,调用成熟的中文分词模型,例如jieba,pkuseg等,选择合适的停用词词典,针对医疗保险记录进行微调,使之更适应本系统的需求。分词后的分词表达可以为l={w1,w2,…,wm},其中m是长文本信息中词语的个数,wi,i∈(1,m)是分词表达。
文本特征提取模块,用于根据所述分词表达,采用词向量模型将词转化为向量,得到文本特征。
将词转换为向量,是为了使数据抽象化,适配后续的神经网络使用。在分词中针对分词后的细粒度的数据表达,利用成熟的词向量模型,完成从词到向量的转化,得到文本特征。
其中,采用的词向量模型可以是word2vec模型、fasttext模型或bert模型等。选取word2vec模型作为词向量模型时,得到的文本特征可用矩阵v表示:
其中,
神经网络模块,用于根据所述文本特征输出预测概率值,并根据预测概率值对当前的医疗保险记录进行划分,若划分为高置信度记录,则将所述结构化数据以及预测概率值输入至规则引擎模块;若划分为低置信度记录,则将结构化数据输入至专家审核模块。
为了提高本系统的自主学习能力以及准确性,在一实施例中,神经网络模块包括一个二分类神经网络,从而引入联结主义ai。
如图2所示,本实施例中的二分类神经网络从输入侧至输出侧包括第一卷积层(conv_1)、第一池化层(pooling_1)、第二卷积层(conv_2)、第二池化层(pooling_2)、第一全连接层(fc_1)和第二全连接层(fc_2)。
将文本特征中的词向量输入二分类神经网络,输出0到1之间(包括0和1)的预测概率值,即二值分类结果。
为了确保二分类神经网络输出结果的准确性,在系统正式使用前需要对二分类神经网络进行训练,二分类神经网络在训练过程中,采用根据审核结果添加标签后的医疗保险记录作为样本数据进行训练,计算预测概率值与真实的标签值之间的误差值,通过最小化二值交叉熵损失函数对二分类神经网络进行优化,所述最小化二值交叉熵损失函数的表达式为:
其中,xn为预测概率值,yn为真实的标签值,wn为对于不同类型的样本数据的权重分配,n为样本数量,n∈(1,n),表示第n个样本。
在二分类神经网络训练完成后,针对待审核的医疗保险记录,向二分类神经网络中输入该医疗保险记录对应的文本特征,二分类神经网络输出对应的预测概率值。为了保证系统工作的可信度,神经网络模块还需要根据二分类神经网络输出的预测概率值,对当前的医疗保险记录进行划分,如图3所示,图中的智能审核模块为数据结构化模块、记录分词模块、文本特征提取模块和神经网络模块的总称,智能审核时具体执行如下操作:
设定上限阈值为thh,下限阈值为thl,上限阈值和下限阈值可根据系统需要进行调整,例如设置上限阈值thh=0.7,下限阈值thl=0.3。
若预测概率值大于上限阈值thh,则判定当前的医疗保险记录为正样本,并划分为高置信度记录;若预测概率值小于下限阈值thl,则判定当前的医疗保险记录为负样本,并划分为高置信度记录;若预测概率值在上限阈值thh和下限阈值thl之间,则判定当前的医疗保险记录为混淆样本,并划分为低置信度记录。
并在划分结束后,将高置信度记录对应的结构化数据以及预测概率值输入至规则引擎模块;将低置信度记录对应的结构化数据输入至专家审核模块。
本申请得到的审核结果为通过或拒绝,并且本实施例中的正样本对应为审核通过的样本,负样本对应为审核拒绝的样本,混淆样本指规则引擎可能无法给出准确的审核结果的样本,因此需要专家进行准确的审核。
根据审核结果对医疗保险记录添加标签生成用于二分类神经网络训练的样本数据时,对审核结果为通过的医疗保险记录添加的标签的标签值为1,对审核结果为拒绝的医疗保险记录添加的标签的标签值为0。并且为了保证样本数据的准确性,一般采用人为添加标签的形式。
专家审核模块,用于接收神经网络模块输出的为低置信度记录的结构化数据,并接收专家根据该结构化数据输入的审核结果,将当前的医疗保险记录以及接收的审核结果作为反馈数据用于神经网络模块的训练。
本申请将专家审核后的医疗保险记录作为反馈数据用于训练神经网络模块,实现反馈式机器学习,降低系统对专家审核的需求,减少人工开销。并且为了提高本系统的准确度,进一步提升用于训练的样本数据的多样性,将各医疗机构产生的标注有审核结果的医疗保险记录也作为样本数据的来源,实现二分类神经网络具有不同类型的样本数据。
本实施例中不同类型的样本数据包括两个部分:第一部分由专家审核模块产生的反馈数据生成,第二部分由各医疗机构产生的带有审核结果的医疗保险记录生成。
在生成样本数据时,均为根据审核结果对医疗保险记录添加标签,即带有标签的医疗保险记录作为样本数据,与样本数据的类型无关。二分类神经网络训练时的最小化二值交叉熵损失函数对这两部分数据,赋于不同的权重参数,其中以专家审核的反馈数据的权重最高,其他数据依数据来源的不同调整权重比例,例如根据不同医疗机构的可信度赋予不同的权重比例。基于这两部分数据,可以对神经网络的参数进行微调,提高预测准确率。
同时,在专家进行审核的过程中,可在低置信度记录中发掘一些显式规则。由于数据的更新很快,一些新的诈骗手段或伪造模式在现行的规则引擎中可能没有被包含,因此,专家审核模块的引入既能够增加高置信度的训练样本,又能够对规则引擎进行更新,进一步提升系统的准确性和可信度。
规则引擎模块,用于接收神经网络模块输出的为高置信度记录的结构化数据以及预测概率值,根据预定义的规则引擎输出医疗保险记录的审核结果。
本实施例中的规则引擎基于符号主义ai实现,不包括算法训练,所以规则引擎的模型是动态的,能根据需要迅速调整。因此,专家审核模块发掘的显式规则,可以直接用于优化现有规则引擎,无需过多计算开销。
本申请的基于机器学习反馈规则增强的医疗保险智能审核系统,结合了联结主义ai与符号主义ai的优点,通过引入神经网络降低对显式规则的依赖,借用反馈式的学习方式降低对专家标注的需求,减少人工开销,利用专家标注后数据既更新规则引擎,又作为训练样本优化神经网络参数学习,进一步提升系统的准确性和可信度。该系统极大程度上弥补了传统规则引擎的局限性,对混淆记录进行了先验分析,降低了规则引擎错判的概率。
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
以上所述实施例仅表达了本申请的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。因此,本申请专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!