一种基于深度学习的视频质量诊断方法与流程
本发明涉及一种基于深度学习的视频质量诊断方法,属于视频分析技术领域。
背景技术:
监控视频系统的运行依靠人工检测和处理的方式已经变得不再现实,如何快速自动检测和定位监控系统中的问题,促使了视频质量诊断技术的发展。监控厂商已和研究机构都推出了多款视频质量诊断系统,将故障设备存在的问题清晰展现给用户,便于用户快速精确定点检修设备,保证视频监控系统的长期正常运行,减轻维护监控设备的工作量。
传统的视频质量诊断:基于图像统计信息(峰值和方差);通过比较统计量的值和设定阈值之间的大小关系,进而判断图像是否有异常。依靠人工分析有限的样本找到关键特征,再配合人为设定的判断规则判断异常类型的传统算法,都是建立在小样本的基础之上。从实践中也可得知,传统算法的泛化效果一般都比较差,通常是一套阈值或者一套规则只适用于特定的场景,改变场景时算法的准确率会受下降甚至失效。但应用场景和环境是千变万化的,传统算法实现起来会难度较大,精度不高,泛化能力不高。
技术实现要素:
本发明提供了一种基于深度学习的视频质量诊断方法,以用于通过深度学习的方法实现视频质量诊断的问题。
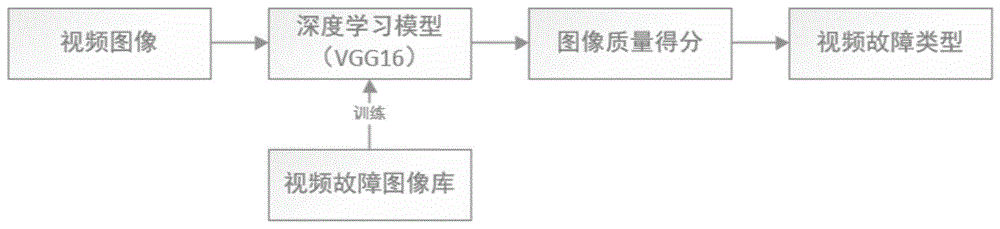
本发明的技术方案是:一种基于深度学习的视频质量诊断方法,所述方法步骤如下:
步骤一,收集全面的视频质量异常数据,接着对视频质量异常数据进行预处理,将预处理得到的图像打上异常类型的标签,再给打上标签的每张预处理得到的图像进行质量打分,对每张预处理得到的图像取多人的质量打分的平均值作为对应预处理得到的图像的质量分数;将带有质量分数的预处理得到的图像与tid2013数据库中图像组建视频质量诊断深度学习数据集,视频质量诊断深度学习数据集分为三部分:训练集、验证集、测试集;其中,全面的视频质量异常数据包括9种类型的异常视频图像:信号缺失图像、清晰度异常图像、亮度异常图像、偏色图像、噪声图像、滚屏图像,条纹干扰图像、画面冻结图像、ptz故障图像;标签包括:信号缺失、清晰度异常、亮度异常、偏色、图像噪声、滚屏、条纹干扰、画面冻结、ptz故障;
步骤二,搭建深度学习模型框架,读取训练集图像,通过深度学习模型进行网络训练,得到训练后深度学习模型;
步骤三,把验证集作为训练后深度学习模型的输入,将输出的结果与验证集中的主观评价作比较,根据比较结果调整深度学习模型参数,得到调整后的深度学习模型;
步骤四,读取调整后的深度学习模型,输入测试集图像,得到视频图像质量分数,根据质量分数得到视频故障类型。
所述预处理依次为:统一成png格式、统一大小。
所述训练集、验证集、测试集比例设置为70%训练集,10%验证集,20%测试集。
所述深度学习模型采用的vgg16,激活函数relu。
本发明的有益效果是:本发明通过对监控视频图像故障进行分析,建立前端采集故障与视频图像质量对应关系,收集制作了全面的视频质量数据集,整理了符合深度学习模型的监控视频故障图像数据集,而特定的深度学习模型的选取可以提取异常视频更多的特征,适应更为复杂的规则,更适合与实际应用结合,提高了视频诊断系统在不同场景中的泛化能力,便于人们及时有效的对待诊断视频的情况进行了解,保证了视频系统的正常运行,并在一定程度上减轻了人的劳动压力。
附图说明
图1为本发明流程图;
图2通过tfrecord文件制作自己的数据集;
图3为深度学习视频质量诊断特征提取示意图;
图4为将几种算法经非线性映射后,分别计算plcc、srcc、krcc和rmse的值。
具体实施方式
实施例1:如图1-4所示,一种基于深度学习的视频质量诊断方法,所述方法步骤如下:
步骤一,收集全面的视频质量异常数据,接着对视频质量异常数据进行预处理,将预处理得到的图像打上异常类型的标签,再给打上标签的每张预处理得到的图像进行质量打分,对每张预处理得到的图像取多人的质量打分的平均值作为对应预处理得到的图像的质量分数;将带有质量分数的预处理得到的图像与tid2013数据库中图像组建视频质量诊断深度学习数据集,视频质量诊断深度学习数据集分为三部分:训练集、验证集、测试集;数据集都存储到tfrecord文件,然后从tfrecord文件中读取样例进行解析;其中,全面的视频质量异常数据包括9种类型的异常视频图像:信号缺失图像、清晰度异常图像、亮度异常图像、偏色图像、噪声图像、滚屏图像,条纹干扰图像、画面冻结图像、ptz故障图像;标签包括:信号缺失、清晰度异常、亮度异常、偏色、图像噪声、滚屏、条纹干扰、画面冻结、ptz故障;tid2013数据库(tid2013数据库中包含失真图像、参考图像和对应的mos文件,是目前用于图像质量评估研究中较大的一个数据库。图像数据库包含25幅参考图像和3000幅失真图像。mos文件是主观质量评价分数,由971个实验观察者主观评价获得,每个质量分数数值在[0,9]内,数值越大图像质量越好);收集全面的数据可以减少目前网络上可以获得的视频质量诊断的数据很少,很难满足深度学习的需求的不足,增加训练的数据量,提高模型的泛化能力,增加噪声数据,提升模型的鲁棒性。
步骤二,在tensorflow环境下搭建深度学习模型框架,从github开源库中下载模型权重vgg16_weights.npz,通过train.py读取训练集,通过深度学习模型进行网络训练,得到训练后深度学习模型;所述的训练为:新建train.py文件,对搭建好的网络进行训练,并保存训练参数,以便下次使用。在tensorflow环境下搭建深度学习模型框架,再用准备好的数据集完成训练。通过imagenet上的训练初始化基准cnn权重,并随机初始化最后一个全连接层。搭建深度学习模型框架:vgg-16模型的网络层主要包括5个卷积层conv,1个概率层prob和1个全连接层fc;其中,卷积层conv由卷积单元conv、非线性单元relu和最大池化单元pool构成,全连接层fc由全连接单元fc、非线性单元relu和预防过拟合单元dropout构成;概率层prob由一个概率单元prob构成;5个卷积层中的第一个卷积层conv1的排列构成为conv1_1,relu1_1,conv1_2,relu1_2,pool1;第二个卷积层conv2的排列构成为conv2_1,relu2_1,conv2_2,relu2_2,pool2;第三个卷积层conv3的排列构成为conv3_1,relu3_1,conv3_2,relu3_2,conv3_3,relu3_3,pool3;第四个卷积层conv4的排列构成为conv4_1,relu4_1,conv4_2,relu4_2,conv4_3,relu4_3,pool4;第五个卷积层conv5的排列构成为conv5_1,relu5_1,conv5_2,relu5_2,conv5_3,relu5_3,pool5;全连接层fc的排列构成为fc6,relu6,dropout1,fc7,relu7,dropout2,fc8。
深度学习模型的训练主要步骤如下:
步骤1、导入卷积神经网络模型的初始权重和初始偏置的参数(vgg16_weights.npz);
步骤2、将训练数据集中的图像输入到用于视频异常图像检测的全卷积神经网络模型。
训练过程:网络开始输入(3,224,224)的图像数据,即一张宽224,高244的彩色rgb图片,同时补了一圈0,zeropadding2d((1,1)。接着是卷积层。有64个(3,3)的卷积核,激活函数relu,model.add(convolution2d(64,3,3,activation=‘relu’))一个卷积核扫完图片,生成一个新的矩阵,64个就生成64层。接着是补0,接着再来一次卷积。此时图像数据是64224224model.add(zeropadding2d((1,1)))model.add(convolution2d(64,3,3,activation=’relu’))接着是池化,小矩阵是(2,2),步长(2,2),指的是横向每次移动2格,纵向每次移动2格。model.add(maxpooling2d((2,2),strides=(2,2)))按照这样池化之后,数据变成了(64112112),矩阵的宽高由原来的224减半,变成了112再往下,同理,只不过是卷积核个数依次变成(128,256,512),而每次按照这样池化之后,矩阵都要缩小一半。13层卷积和池化之后,数据变成512*7*7然后flatten(),将数据拉平成向量,变成一维512*7*7=25088接着是3个全连接层。全连接转卷积:训练阶段,有4096个输出的全连接层fc6的输入是一个7×7×512的featuremap,因为全连接层的缘故,不需要考虑局部性,可以把7×7×512看成一个整体,25088(=7×7×512)个输入的每个元素都会与输出的每个元素(或者说是神经元)产生连接,所以每个输入都会有4096个系数对应4096个输出,所以网络的参数(也就是两层之间连线的个数,也就是每个输入元素的系数个数)规模就是7×7×512×4096。对于fc7,输入是4096个,输出是4096个,因为每个输入都会和输出相连,即每个输出都有4096条连线(系数),那么4096个输入总共有4096×4096条连线(系数),最后一个fc8计算方式一样。测试阶段,由于换成了卷积,第一个卷积后要得到4096(或者说是1×1×4096)的输出,那么就要对输入的7×7×512的featuremap的宽高(即width、height维度)进行降维,同时对深度(即channel/depth维度)进行升维。要把7×7降维到1×1,那么干脆直接一点,就用7×7的卷积核就行,另外深度层级的升维,因为7×7的卷积把宽高降到1×1,那么刚好就升高到4096就好了,最后得到了1×1×4096的featuremap。这其中卷积的参数量上,把7×7×512看做一组卷积参数,因为该层的输出是4096,那么相当于要有4096组这样7×7×512的卷积参数,那么总共的卷积参数量就是:[7×7×512]×4096。第二个卷积依旧得到1×1×4096的输出,因为输入也是1×1×4096,三个维度(宽、高、深)都没变化,可以很快计算出这层的卷积的卷积核大小也是1×1,而且,通道数也是4096,因为对于输入来说,1×1×4096是一组卷积参数,即一个完整的filter,所有4096个输出的情况下,卷积参数的规模就是[1×1×4096]×4096。第三个卷积的计算一样。实验运行过程参数变化:
→conv1_1_w(3,3,3,64)→conv1_1_b(64,)→conv1_2_w(3,3,64,64)→conv1_2_b(64,)→conv2_1_w(3,3,64,128)→conv2_1_b(128,)→conv2_2_w(3,3,128,128)→conv2_2_b(128,)→conv3_1_w(3,3,128,256)→conv3_1_b(256,)→conv3_2_w(3,3,256,256)→conv3_2_b(256,)→conv3_3_w(3,3,256,256)→conv3_3_b(256,)→conv4_1_w(3,3,256,512)→conv4_1_b(512,)→conv4_2_w(3,3,512,512)→conv4_2_b(512,)→conv4_3_w(3,3,512,512)→conv4_3_b(512,)→conv5_1_w(3,3,512,512)→conv5_1_b(512,)→conv5_2_w(3,3,512,512)→conv5_2_b(512,)→conv5_3_w(3,3,512,512)→conv5_3_b(512,)→fc6_w(25088,4096)→fc6_b(4096,)→fc7_w(4096,4096)→fc7_b(4096,)→fc8_w(4096,9)→fc8_b(9,)。9类异常视频图像分数。
步骤3利用softmax回归算法对卷积神经网络模型输出的前向输出值与对应的标注结果进行比较,利用批量随机梯度下降法将两者的误差进行反向传播,根据误差实现用于视频异常图像检测的卷积神经网络模型权重和偏置的参数更新。
步骤4重复步骤2-3,对训练数据集中的多幅图像进行多次训练,直至迭代次数达到设定值(epoch=100)。
步骤三,把验证集作为训练后深度学习模型的输入,将输出的结果与验证集中的主观评价作比较,根据比较结果调整训练后深度学习模型参数,得到调整后的深度学习模型;质量打分为主观评价,采用10分制给失真图像打分(得分范围从0到9)。为了获得总体平均分,进行了多次实验。通过验证集调整深度学习模型参数。权重和偏差设置为0.9,并且在基准网络的最后一层上应用比例为0.75的dropout。卷积层和最后全连接层的学习率分别设置为3×10-7和3×10-6。此外,在每10个训练周期之后,对所有学习率应具有衰减因子0.95的指数衰减。
步骤四,读取调整后的深度学习模型,输入测试集,得到视频图像质量分数,根据质量分数得到视频故障类型。
目前被广泛使用的衡量视频质量方法性能的指标有4个,即斯皮尔曼顺序相关系数(srcc)、肯代尔顺序相关系数(krcc)、皮尔逊线性相关系数(plcc)和均方根误差(rmse)。前两者可以测量视频质量方法预测结果的单调性,因为它们仅在数据点的等级上操作并忽略数据点之间的相对距离,plcc衡量预测质量分数的精确度,rmse用于衡量预测结果的-致性。值得注意的是,plcc、srcc和krcc取值越接近于1以及rmse越接近于0,表示方法的评估性能越好,反之越差。本申请实验方法与传统方法对比:图4将几种算法经非线性映射后,分别计算plcc,srcc,krcc和rmse的值.。相比传统算法,本申请的一种基于深度学习的视频质量诊断方法(dl-vgg-16)的plcc,srcc,krcc值比其它方法高,rmse值最低,说明本申请的深度学习的视频质量诊断方法效果更好。进一步地,可以设置所述预处理依次为:统一成png格式、统一大小(利用python中的opencv库里的接口函数完成)。
进一步地,可以设置所述训练集、验证集、测试集比例为70%训练集,10%验证集,20%测试集。
进一步地,可以设置所述深度学习模型采用的vgg16,包含:13个卷积层,5个池化层,3个全连层,激活函数relu(vgg16更利于网络运行,更适合与实际应用结合;增加深度学习模型的拟合度,从线性扩增到非线性,更有利于异常图像特征的提取)。卷积层和全连接层具有权重系数,为权重层,总数目为13+3=16,池化层不涉及权重,因此不属于权重层,不被计数。
更进一步地,给出如下数据:
实验硬件信息:gpu:geforcegtxtitanxmajor:5minor:2memoryclockrate(ghz):1.076computecapability:5.2。软件:ubuntu16.04+anaconda3-5.1.0+cuda9.0+cudnn7.0+tensorflow-r1.7。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下做出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!