一种融合多元信息的高精度视频异常事件检测方法与流程
本发明涉及视频内容分析技术,尤其涉及一种融合多元信息的高精度视频异常事件检测方法。
背景技术:
视频中的异常事件检测是指识别不符合预期行为的事件。在视频监控应用中是一项非常重要的任务,直接关乎人民群众安全、城市管理、社会稳定。因为异常事件在实际应用中是随时发生的、无法预知的,收集各种异常事件并用分类方法解决问题几乎是不可行的,因此视频人群异常事件检测是视频内容分析中最具挑战性的任务之一。相对于动作识别而言,视频中人群异常行为的定义覆盖极其的广泛,其定义至今都非常模糊。导致目前异常事件检测的处理机制,处理精度与效率都不够理想。
在传统方法中,大多通过手工设计的特征方法来检测异常事件,设计的特征用以代表每个视频,包括视频序列的特征信息和运动信息,并通过重建最小误差的方式去学习字典。对应的异常事件的特征将会具有较大的重建误差。但由于字典没有经过异常事件的训练而且通常过于完整,无法保证期望。
基于深度学习的方法,通常使用自动编码器方式学习深度神经网络,并以重建具有小的重构错误的正常事件为优化目标对神经网络进行优化。但深度神经网络的容量很高,异常事件的重建错误不一定会发生。
技术实现要素:
本发明的目的是针对视频中异常事件检测的方法,提出了一种融合多元信息的高精度视频异常事件检测方法。
为了上述目的,本发明使用目前流行的以卷积神经网络为基础的深度学习方法,对于视频中的异常行为,通常至少在亮度信息上或者运动信息上与正常行为存在差异,例如在人行道上行驶的车辆与行人显然存在着较大的不一致,通过融合目标的运动信息和光谱亮度信息,提高异常事件的检测精度,包括如下步骤:
步骤1:通过无异常事件视频得到多帧视频图像,多帧视频图像通过分组得到多组视频图像数据集,根据多组视频图像数据集构建视频图像训练集,将多帧视频图像通过光流提方法得到多帧光流图像,将多帧光流图像通过分组得到多组光流图像数据集,根据多组光流图像数据集构建光流图像训练集;
步骤2:构建视频光流深度学习网络;
步骤3:随机选择视频图像样本中视频图像数据集以及对应的光流图像样本中光流图像数据集,构建视频光流误差损失模型,视频光流误差损失模型输出最小为优化目标,优化训练视频光流深度学习网络,得到训练后视频光流深度学习网络;
步骤4:将待检测视频图像通过训练后视频光流深度学习网络,通过视频光流误差计算得到待检测视频图像的误差,进一步通过与误差阈值比较从而判断视频图像是否存在异常事件;
作为优选,步骤1所述多帧视频图像为:
ii,1,ii,2,...,ii,n
i∈[1,m]
其中,m为无异常事件视频的数量,n为无异常事件视频中视频图像的帧的数量,ii,j为第i个无异常事件视频中第j帧图像,j∈[1,n];
ii,j具体定义为第i个无异常事件视频中第j帧图像:
步骤1所述通过分组得到多组视频图像数据集为:
datai,k={ii,(k-1)*l+1,ii,(k-1)*l+2,...,ii,(k-1)*l+l}
k∈[1,n/l]
其中,datai,k为第i个无异常事件视频中第k组视频图像数据集,l为每组图像数据集中视频图像的帧的数量,n为无异常事件视频中视频图像的帧的数量,ii,(k-1)*l+l为第i个无异常事件视频中第k组视频图像数据集中第l个图像,ii,(k-1)*l+l为第i个无异常事件视频中第(k-1)*l+l帧图像,l∈[1,l];
步骤1所述构建视频图像训练集为:
构建视频图像样本为:
testai=(datai,1,datai,1,...,datai,n/l)
其中,datai,k为第i个无异常事件视频中第k组视频图像数据集;
所述视频图像训练集为:
traina=(testa1,testa2,...,testam)
其中,testai为第i个视频图像样本,i∈[1,m];
步骤1所述多帧视频图像通过lucas-kanade光流提方法得到多帧光流图像,具体为:
步骤1所述通过分组得到多组光流图像数据集为:
oi,1,oi,2,...,oi,n
i∈[1,m]
其中,m为无异常事件视频的数量,n为无异常事件视频中视频图像的帧的数量,oi,j为第i个无异常事件视频中第j帧光流图像,j∈[1,n];
步骤1所述通过分组得到多组视频光流图像数据集为:
其中,
步骤1所述构建光流图像训练集为:
构建视频图像样本为:
其中,
所述视频图像训练集为:
trainb=(testb1,testb2,...,testbm)
其中,testbi为第i个视频光流图像样本,i∈[1,m];
作为优选,步骤2所述视频光流深度学习网络包括:视频图像特征提取模块、视频图像特征重构模块、光流图像特征提取模块、光流图像特征重构模块;
所述视频图像特征提取模块与所述视频图像特征重构模块串联连接;
所述光流图像特征提取模块与所述光流图像特征重构模块串联连接;
所述视频图像特征提取模块用于输入步骤1所述视频图像样本中视频图像数据集,所述视频图像特征提取模块的输出为视频图像样本中视频图像数据集特征;
所述光流图像特征提取模块用于输入步骤1所述光流图像样本中光流图像数据集,所述视频图像特征提取模块的输出为光流图像样本中光流图像数据集特征;
所述视频图像特征重构模块将特征通过重构,得到重构后视频图像数据集;
所述光流图像特征重构模块将光流图像样本中光流图像数据集特征通过重构,得到重构后光流图像数据集;
所述视频图像特征提取模块由多个视频提取模块依次级联构成;
所述视频提取模块由第一视频提取器、第二视频提取器、第三视频提取器依次级联构成;
每个视频提取器由视频提取卷积层、视频提取隐含层构成;
所述第一视频提取器包括:卷积核大小为a1的卷积层
所述第二视频提取器包括:卷积核大小为a2的卷积层
所述第三视频提取器包括:卷积核大小为a3的卷积层
所述视频图像特征重构模块由多个视频重构模块依次级联构成;
所述视频重构模块由第一视频重构器、第二视频重构器、第三视频重构器依次级联构成;
每个视频重构器由视频重构卷积层、视频重构隐含层构成;
所述第一视频重构器包括:卷积核大小为a4的卷积层
所述第二视频重构器包括:卷积核大小为a5的卷积层
所述第三视频重构器包括:卷积核大小为a6的卷积层
所述光流图像特征提取模块由多个光流提取模块依次级联构成;
所述光流提取模块由第一光流提取器、第二光流提取器、第三光流提取器依次级联构成;
每个光流提取器由光流提取卷积层、光流提取隐含层构成;
所述第一光流提取器包括:卷积核大小为b1的卷积层
所述第二光流提取器包括:卷积核大小为b2的卷积层
所述第三光流提取器包括:卷积核大小为b3的卷积层
所述光流图像特征重构模块由多个光流重构模块依次级联构成;
所述光流重构模块由第一光流重构器、第二光流重构器、第三光流重构器依次级联构成;
每个光流重构器由光流重构卷积层、光流重构隐含层构成;
所述第一光流重构器包括:卷积核大小为b4的卷积层
所述第二光流重构器包括:卷积核大小为b5的卷积层
所述第三光流重构器包括:卷积核大小为b6的卷积层
作为优选,步骤3中所述随机选择视频图像样本中视频图像数据集以及对应的光流图像样本中光流图像数据集为:
在traina数据集和trainb数据集中随机选择同一视频时刻的视频图像和视频光流图像,(testak,testbk),k∈[1,m]
步骤3所述构建视频光流误差损失模型为:
通过计算输入的视频图像ii,j和视频光流图像oi,j与重建的视频图像
其中,datai,k表示第i个待检测视频中第k组视频图像数据集,
步骤3所述优化训练视频光流深度学习网络为:使用随机梯度下降优化方法优化网络参数,所述优化后网络参数为:
第一视频提取器卷积层优化后参数
步骤3所述训练后视频光流深度学习网络为:
通过优化后网络参数构建的训练后视频光流深度学习网络;
作为优选,步骤4所述将待检测视频图像通过训练后视频深度学习网络为:
计算输入的视频图像与重建的视频图像的均方误差li:
其中datai,k表示第i个待检测视频中第k组视频图像数据集,
步骤4所述通过视频光流误差计算得到待检测视频光流图像的误差:
计算输入的视频光流图像与重建视频光流图像的均方误差lo:
其中
步骤4所述进一步通过与误差阈值t比较从而判断视频图像是否存在异常事件为:
联合视频图像的重建误差和视频光流图像的重建误差:
其中,datai,k表示第i个待检测视频中第k组视频图像数据集,
判断是否存在异常事件,li,k大于阈值t的表示为第i个待检测视频中第k组视频中有异常事件,li,k小于阈值t的表示为第i个待检测视频中第k组视频中没有异常事件;
本发明优点在于,使用以卷积神经网络为基础的深度学习方法,对于视频中的异常事件,通过融合目标的运动信息和光谱亮度信息进行异常事件检测,提高了异常事件的检测精度。
附图说明
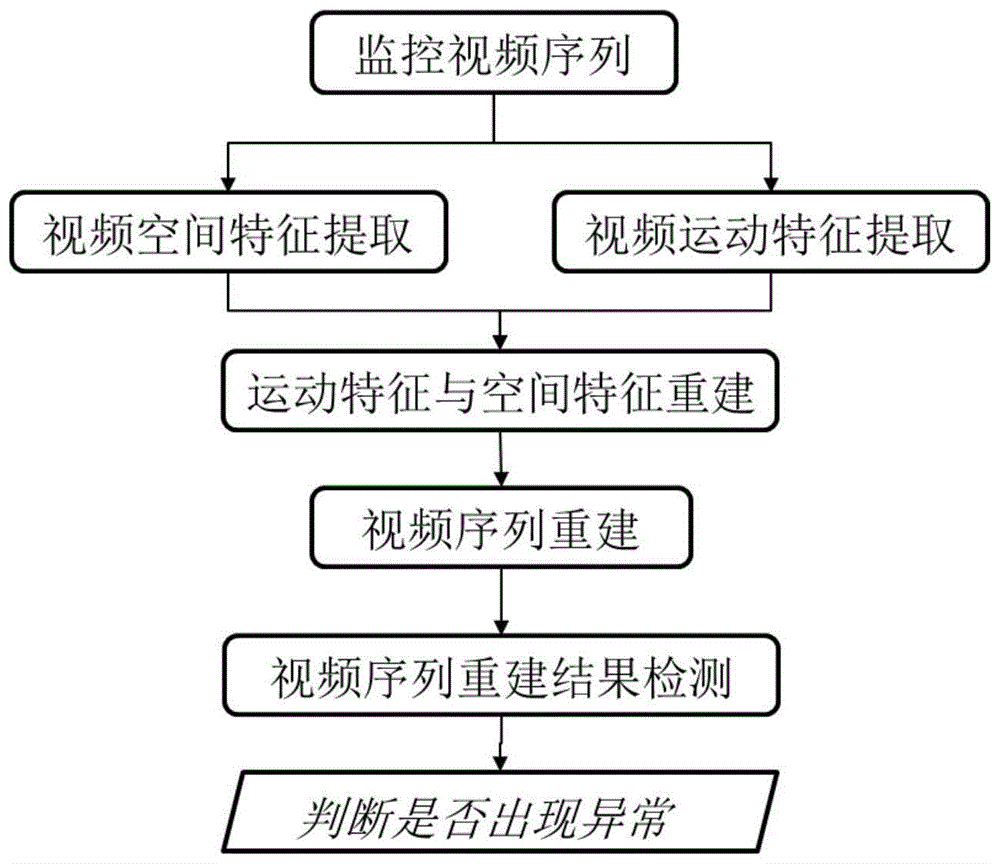
图1:是本发明方法流程图;
图2:是本发明的视频图像特征提取模块和视频图像特征重构模块;
图3:是本发明的视频光流图像特征提取模块和视频光流图像特征重构模块;
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及到的技术特征只要彼此之间未构成冲突就可以相互组合。
图1为本发明方法流程图。本发明方法包括:视频空间特征提取、视频运动特征提取、运动特征与空间特征融合以及视频序列重建。
下面结合图1至图3介绍本发明的具体实施方式为一种融合多元信息的高精度视频异常事件检测方法,具体包括以下步骤:
步骤1:通过无异常事件视频得到多帧视频图像,多帧视频图像通过分组得到多组视频图像数据集,根据多组视频图像数据集构建视频图像训练集,将多帧视频图像通过光流提方法得到多帧光流图像,将多帧光流图像通过分组得到多组光流图像数据集,根据多组光流图像数据集构建光流图像训练集;
步骤1所述多帧视频图像为:
ii,1,ii,2,...,ii,n
i∈[1,m]
其中,m为无异常事件视频的数量,n为无异常事件视频中视频图像的帧的数量,ii,j为第i个无异常事件视频中第j帧图像,j∈[1,n];
ii,j具体定义为第i个无异常事件视频中第j帧图像:
步骤1所述通过分组得到多组视频图像数据集为:
datai,k={ii,(k-1)*l+1,ii,(k-1)*l+2,...,ii,(k-1)*l+l}
k∈[1,n/l]
其中,tatai,k为第i个无异常事件视频中第k组视频图像数据集,l为每组图像数据集中视频图像的帧的数量,n为无异常事件视频中视频图像的帧的数量,ii,(k-)*l+l为第i个无异常事件视频中第k组视频图像数据集中第l个图像,ii,(k-1)*l+l为第i个无异常事件视频中第(k-1)*l+l帧图像,l∈[1,l];
步骤1所述构建视频图像训练集为:
构建视频图像样本为:
testai=(datai,1,datai,1,...,datai,n/l)
其中,datai,k为第i个无异常事件视频中第k组视频图像数据集;
所述视频图像训练集为:
traina=(testa1,testa2,...,testam)
其中,testai为第i个视频图像样本,i∈[1,m];
步骤1所述多帧视频图像通过lucas-kanade光流提方法得到多帧光流图像,具体为:
步骤1所述通过分组得到多组光流图像数据集为:
oi,1,oi,2,...,oi,n
i∈[1,m]
其中,m为无异常事件视频的数量,n为无异常事件视频中视频图像的帧的数量,oi,j为第i个无异常事件视频中第j帧光流图像,j∈[1,n];
步骤1所述通过分组得到多组视频光流图像数据集为:
其中,
步骤1所述构建光流图像训练集为:
构建视频图像样本为:
其中,
所述视频图像训练集为:
trainb=(testb1,testb2,...,testbm)
其中,testbi为第i个视频光流图像样本,i∈[1,m];
步骤2:构建视频光流深度学习网络;
步骤2所述视频光流深度学习网络包括:视频图像特征提取模块、视频图像特征重构模块、光流图像特征提取模块、光流图像特征重构模块;
所述视频图像特征提取模块与所述视频图像特征重构模块串联连接;
所述光流图像特征提取模块与所述光流图像特征重构模块串联连接;
所述视频图像特征提取模块用于输入步骤1所述视频图像样本中视频图像数据集,所述视频图像特征提取模块的输出为视频图像样本中视频图像数据集特征;
所述光流图像特征提取模块用于输入步骤1所述光流图像样本中光流图像数据集,所述视频图像特征提取模块的输出为光流图像样本中光流图像数据集特征;
所述视频图像特征重构模块将特征通过重构,得到重构后视频图像数据集;
所述光流图像特征重构模块将光流图像样本中光流图像数据集特征通过重构,得到重构后光流图像数据集;
所述视频图像特征提取模块由多个视频提取模块依次级联构成;
所述视频提取模块由第一视频提取器、第二视频提取器、第三视频提取器依次级联构成;
每个视频提取器由视频提取卷积层、视频提取隐含层构成;
所述第一视频提取器包括:卷积核大小为a1,a1=3*3*3*64的卷积层
所述第二视频提取器包括:卷积核大小为a2,a2=3*3*3*128的卷积层
所述第三视频提取器包括:卷积核大小为a3,a3=3*3*3*256的卷积层
所述视频图像特征重构模块由多个视频重构模块依次级联构成;
所述视频重构模块由第一视频重构器、第二视频重构器、第三视频重构器依次级联构成;
每个视频重构器由视频重构卷积层、视频重构隐含层构成;
所述第一视频重构器包括:卷积核大小为a4,a4=3*3*3*128的卷积层
所述第二视频重构器包括:卷积核大小为a5,a5=3*3*3*64的卷积层
所述第三视频重构器包括:卷积核大小为a6,a6=3*3*3*1的卷积层
所述光流图像特征提取模块由多个光流提取模块依次级联构成;
所述光流提取模块由第一光流提取器、第二光流提取器、第三光流提取器依次级联构成;
每个光流提取器由光流提取卷积层、光流提取隐含层构成;
所述第一光流提取器包括:卷积核大小为b1,b1=3*3*3*64的卷积层
所述第二光流提取器包括:卷积核大小为b2,b2=3*3*3*128的卷积层
所述第三光流提取器包括:卷积核大小为b3,b3=3*3*3*256的卷积层
所述光流图像特征重构模块由多个光流重构模块依次级联构成;
所述光流重构模块由第一光流重构器、第二光流重构器、第三光流重构器依次级联构成;
每个光流重构器由光流重构卷积层、光流重构隐含层构成;
所述第一光流重构器包括:卷积核大小为b4,b4=3*3*3*128的卷积层
所述第二光流重构器包括:卷积核大小为b5,b5=3*3*3*64的卷积层
所述第三光流重构器包括:卷积核大小为b6,b6=3*3*3*2的卷积层
步骤3:随机选择视频图像样本中视频图像数据集以及对应的光流图像样本中光流图像数据集,构建视频光流误差损失模型,视频光流误差损失模型输出最小为优化目标,优化训练视频光流深度学习网络,得到训练后视频光流深度学习网络;
步骤3中所述随机选择视频图像样本中视频图像数据集以及对应的光流图像样本中光流图像数据集为:
在traina数据集和trainb数据集中随机选择同一视频时刻的视频图像和视频光流图像,(testak,testbk),k∈[1,m]
步骤3所述构建视频光流误差损失模型为:
通过计算输入的视频图像ii,j和视频光流图像oi,j与重建的视频图像
其中,datai,k表示第i个待检测视频中第k组视频图像数据集,
步骤3所述优化训练视频光流深度学习网络为:使用随机梯度下降优化方法优化网络参数,所述优化后网络参数为:
第一视频提取器卷积层优化后参数
步骤3所述训练后视频光流深度学习网络为:
通过优化后网络参数构建的训练后视频光流深度学习网络;
步骤4:将待检测视频图像通过训练后视频光流深度学习网络,通过视频光流误差计算得到待检测视频图像的误差,进一步通过与误差阈值比较从而判断视频图像是否存在异常事件;
步骤4所述将待检测视频图像通过训练后视频深度学习网络为:
计算输入的视频图像与重建的视频图像的均方误差li:
其中datai,k表示第i个待检测视频中第k组视频图像数据集,
步骤4所述通过视频光流误差计算得到待检测视频光流图像的误差:
计算输入的视频光流图像与重建视频光流图像的均方误差lo:
其中
步骤4所述进一步通过与误差阈值t比较从而判断视频图像是否存在异常事件为:
联合视频图像的重建误差和视频光流图像的重建误差:
其中,datai,k表示第i个待检测视频中第k组视频图像数据集,
判断是否存在异常事件,li,k大于阈值t的表示为第i个待检测视频中第k组视频中有异常事件,li,k小于阈值t的表示为第i个待检测视频中第k组视频中没有异常事件;
图2是视频图像特征提取模块和视频图像特征重构模块。将视频序列重采样到256*256大小,输入到空间自编码器中,通过三个3d卷积模块提取输入视频序列的空间特征,和三个3d逆卷积模块将提取到的视频空间特征还原成视频序列。六个卷积模块的参数如下:
frames-f1:f1维度为256*256*64,当前模块中共2个3d卷积层,卷积核分别为3*3*3*64和3*3*3*64,3d卷积的采样间隔都为(1,1,1),并使用残差连接的f1中的第一个卷积层和第二个卷积层输出。
f1-f2:f2的维度为128*128*128,当前模块中共2个3d卷积层,卷积核分别为3*3*3*128和3*3*3*128,卷积的采样间隔分别为(2,2,2)和(1,1,1),并使用残差连接的f2中的第一个卷积层和第二个卷积层输出。
f2-f3:f3的维度为64*64*256,当前模块中共2个3d卷积层,卷积核分别为3*3*3*256和3*3*3*256,卷积的采样间隔分别为(2,2,2)和(1,1,1),并使用残差连接的f3中的第一个卷积层和第二个卷积层输出。当前模块获取的卷积特征将作为视频的空间特征与视频的运动特征进行融合。
f3-f4:f4的维度为128*128*128,当前模块中共2个3d逆卷积层,卷积核分别为3*3*3*128和3*3*3*128,逆卷积的重采样间隔分别为(2,2,2)和(1,1,1),并使用残差连接的f4中的第一个逆卷积层和第逆二个卷积层输出。
f4-f5:f5的维度为256*256*64,当前模块中共2个3d逆卷积层,卷积核分别为3*3*3*64和3*3*3*64,逆卷积的重采样间隔分别为(2,2,2)和(1,1,1),并使用残差连接的f4中的第一个逆卷积层和第逆二个卷积层输出。
f5-重建frames:重建frames的维度为256*256*1,当前模块中共2个3d逆卷积层,卷积核分别为3*3*3*32和3*3*3*1,逆卷积的重采样间隔都为(1,1,1)。
图3是是本发明的视频光流图像特征提取模块和视频光流图像特征重构模块。将光流序列重采样到256*256大小,输入到运动自编码器中,通过三个3d卷积模块提取输入光流序列的运动特征,和三个3d逆卷积模块将提取到的视频运动特征还原成光流序列。六个卷积模块的参数如下:
opticalflows-of1:of1维度为256*256*32,当前模块中共2个3d卷积层,卷积核分别为3*3*3*32和3*3*3*32,3d卷积的采样间隔都为(1,1,1),并使用残差连接的of1中的第一个卷积层和第二个卷积层输出。
of1-of2:of2的维度为128*128*64,当前模块中共2个3d卷积层,卷积核分别为3*3*3*64和3*3*3*64,卷积的采样间隔分别为(2,2,2)和(1,1,1),并使用残差连接的of2中的第一个卷积层和第二个卷积层输出。
of2-of3:of3的维度为64*64*128,当前模块中共2个3d卷积层,卷积核分别为3*3*3*128和3*3*3*128,卷积的采样间隔分别为(2,2,2)和(1,1,1),并使用残差连接的of3中的第一个卷积层和第二个卷积层输出。当前模块获取的卷积特征将作为视频的运动特征与视频的空间特征进行融合。
of3-of4:of4的维度为128*128*64,当前模块中共2个3d逆卷积层,卷积核分别为3*3*3*64和3*3*3*64,逆卷积的重采样间隔分别为(2,2,2)和(1,1,1),并使用残差连接的of4中的第一个逆卷积层和第逆二个卷积层输出。
of4-of5:of5的维度为256*256*32,当前模块中共2个3d逆卷积层,卷积核分别为3*3*3*64和3*3*3*64,逆卷积的重采样间隔分别为(2,2,2)和(1,1,1),并使用残差连接的of4中的第一个逆卷积层和第逆二个卷积层输出。
of5-重建opticalflows:重建opticalflows的维度为256*256*1,当前模块中共2个3d逆卷积层,卷积核分别为3*3*16和3*3*2,逆卷积的重采样间隔都为(1,1,1)。
以上所述实施例仅表达了本发明的实施方式,其描述较为具体和详细,但并不能因此而理解为对本发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
- 还没有人留言评论。精彩留言会获得点赞!