基于非支配排序和猫头鹰搜索的多工作流调度方法
本发明属于云计算技术领域,具体涉及基于非支配排序和猫头鹰搜索的多工作流调度方法。
背景技术:
近年来,随着云计算的普及和应用的不断深入,越来越多的科学应用被部署到云平台上运行。这样,用户便无需购置和维护任何服务器等硬件和软件资源,即可通过远程访问可配置的共享计算资源池,按需获取计算能力、存储空间和信息服务,全身心地投入到自己的科学研究工作中。
云环境下的多工作流调度是旨在寻找合适的云资源来同时执行多个工作流应用,即来自各个不同工作流的任务穿插执行,并同时满足多个用户的服务质量需求。合适的多工作流调度算法,应该能在保证多个用户服务质量qos需求的同时,提高云服务提供商的利益。因此,云环境下的多工作流调度是一个带约束的多目标优化问题。
目前流行的多目标工作流调度方法,以多目标进化调度方法和多目标群智能优化调度算法为主。具体来说,多目标进化调度方法,具有全局搜索优势以及避免陷入局部最优的能力,但是其搜索时间过长,影响了算法的实时性;多目标群智能优化算法,本质上是一种迭代算法,通过反复迭代来寻找最优解,具有较好的全局搜索能力与快速收敛性,并且能够在较短时间内找到全局最优解,不足之处是缺乏有效的局部搜索机制。
技术实现要素:
有鉴于此,本发明提供了基于非支配排序和猫头鹰搜索的多工作流调度方法,能够实现混合云环境下多工作流的调度。
本发明提供的基于非支配排序和猫头鹰搜索的多工作流调度方法,包括以下步骤:
步骤1、获取具有截止期限和预算约束的多个工作流,根据工作流的截止期限为该工作流所属的任务分配子截止期限,按照所述子截止期限将所有任务排序,形成任务调度序列,采用所述任务调度序列初始化种群形成待处理种群;初始化迭代次数;
步骤2、计算所述待处理种群中粒子对应的调度方案的适应度,所述适应度由工作流的总完工时间、执行成本及能耗表示;采用非支配排序遗传nsga-ii算法,计算种群中所有粒子的密度,并根据所述适应度和密度对待处理种群中所有粒子进行非支配排序得到不同的非支配层,其中最高非支配层即为非支配前沿解集;
步骤3、当所述迭代次数为1时,由所述非支配前沿解集内所有满足所述截止期限和预算约束的非支配前沿解构成外部档案集;否则,利用待处理种群的所述非支配前沿解集与外部档案集中的所有粒子进行比较,更新外部档案集;当所述外部档案集不为空时,选择所述外部档案集中密度最高的解作为全局最优引导解;当所述外部档案集为空时,则选择所述非支配前沿解集中密度最高的解作为全局最优引导解;
步骤4、当所述迭代次数达到设定阈值时,输出所述外部档案集中所有粒子对应的调度方案;否则,采用nsga-ii算法的精英解保留策略,遍历所述非支配层,形成大小相同的较优种群及较差种群,采用nsga-ii算法更新所述较优种群,采用猫头鹰搜索算法根据所述全局最优引导解更新所述较差种群;
步骤5、将所述较优种群与较差种群合并形成整合种群,以所述整合种群更新所述待处理种群;所述迭代次数自加1,执行步骤2。
进一步地,所述步骤2中根据所述适应度将种群中所有粒子进行非支配排序得到不同的非支配层,所述非支配排序采用粒子间两两比较的方式,比较过程中,如果两个粒子中仅有一个为可行解,则选择为可行解的粒子;如果两个粒子均为可行解或非可行解,则选择非支配粒子;
所述非支配粒子为不被其他粒子支配的粒子,即若粒子xi支配粒子xj则粒子xi为非支配粒子;所述粒子xi支配粒子xj需要至少满足下列情况之一:
粒子xi的总完工时间、执行成本和能耗均分别优于粒子xj的总完工时间、执行成本和能耗;粒子xi的总完工时间、执行成本和能耗三个指标中存在一个指标与粒子xj的相应指标的取值相同,另外两个指标则分别优于粒子xj的相应指标;粒子xi的总完工时间、执行成本和能耗三个指标中存在两个指标均与粒子xj的相应指标的取值相同,另外一个指标则优于粒子xj的相应指标。
进一步地,所述步骤4中的猫头鹰搜索算法为基于混沌序列的猫头鹰搜索算法,采用所述基于混沌序列的猫头鹰搜索算法根据所述全局最优引导解更新所述较差种群的过程包括以下步骤:
步骤4.1、对较差种群p2中的每个粒子
步骤4.2、根据强度变化量,更新较差种群p2中的每个粒子
其中,βmin和βmax分别表示步长参数β取值的上、下界;
步骤4.3、对更新后的较差种群p2进行非支配排序得到非支配前沿解集,在非支配前沿解集的每个粒子xs附近区域进行局部搜索,寻找更优解,具体步骤如下:
步骤4.3.1、初始化混沌局部搜索循环次数k为1;
步骤4.3.2、初始化混沌局部搜索的维度值d为随机整数,且0≤d<|t|,其中t为前粒子的任务集合;
步骤4.3.3、根据任务td的可用资源数量,采用公式(2)计算当前粒子中任务td所对应的第d维元素xd的新混沌变量值xdnew:
其中,|ard|为任务td的可用资源集合ard中总的资源数,将新的混沌变量值xdnew对应的调度方案保存为新粒子cxk;
步骤4.3.4、若循环次数k小于设定的阈值,则k自加1,执行步骤4.3.2;若循环次数k大于或等于设定的阈值,则分别计算所有新粒子的适应度,并求出其中的最优解cx*,选择cx*与原粒子xs中的非支配粒子更新原粒子xs。
进一步地,所述步骤2中计算所述待处理种群中粒子对应的调度方案的适应度,所述适应度中的总完工时间计算过程包括以下步骤:
步骤2.1、采用公式(3)计算粒子中任务的开始执行时间:
其中,ti为粒子的任务集合t中的第i个任务,tentry为工作流入口子任务;
步骤2.2、采用公式(4)计算粒子中任务的完工时间:
ft(ti)=st(ti)+et(ti)+tt(ti)+soft(ti)(4)
其中,et(ti)为任务ti的执行时间,tt(ti)为任务ti的输入文件的读取时间,soft(ti)为任务ti执行所需软件的加载时间;
步骤2.3、粒子的总完工时间makespan的计算公式为:
有益效果:
1、本发明采用同时引入非支配排序遗传算法及猫头鹰搜索算法来计算多工作流调度方案的方法,利用非支配排序遗传算法的多样性生成和保持优点,对种群的50%较优个体进行更新,以保证优良个体的多样性,降低了算法非支配解搜索陷入局部最优的可能性;利用猫头鹰搜索算法的计算简单及收敛速度快的优点,有效缩短了搜索时间,提高了搜索效率;同时通过搜索流程的设置,提高了搜索解的质量,寻找满足用户截止期限和预算约束的非支配调度方案集合,降低了所有工作流的执行能耗;
2、本发明通过改进基本猫头鹰搜索算法,用混沌序列替换基本猫头鹰搜索算法的参数,并引入参数随机性和遍历性以增强算法的全局搜索能力;同时,在猫头鹰搜索算法找到的当前非支配前沿解附近,利用混沌序列进行混沌局部搜索,进一步提高了算法的局部搜索能力;将改进的猫头鹰搜索算法用于解决绿色混合云环境下的多工作流调度问题,以期同时优化工作流的完工时间、执行成本和能耗,为双约束多目标优化问题提供了一条新的解决途径,并通过动态电压频率调整的方式,实现降低执行能耗的目标。
附图说明
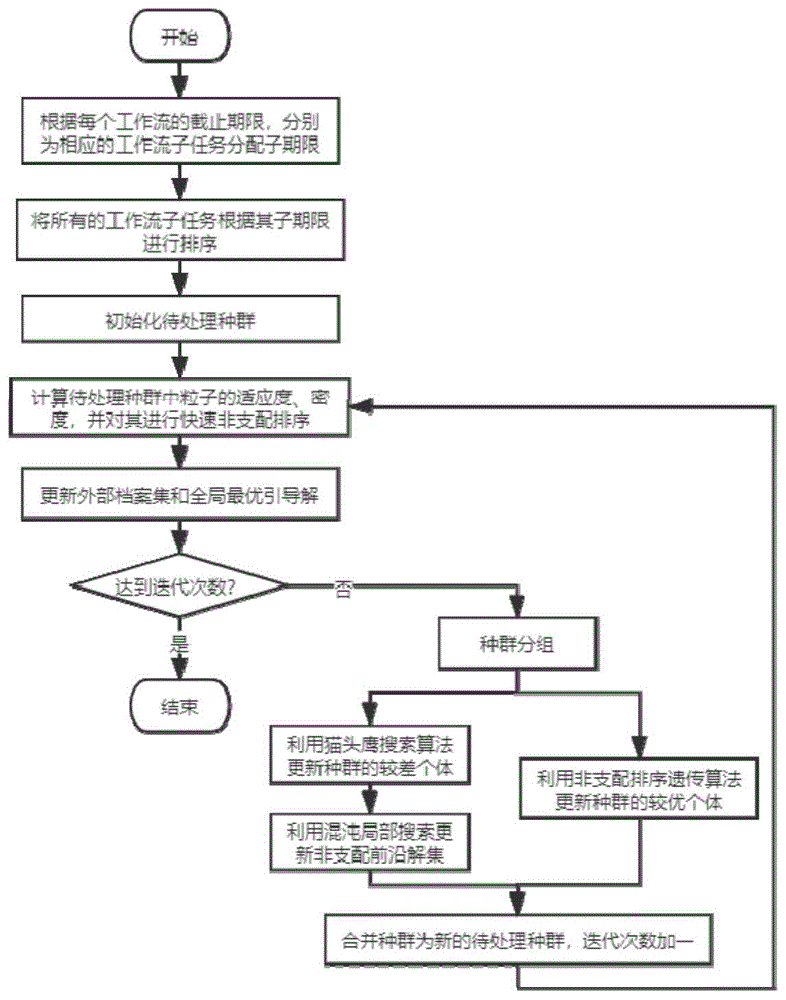
图1为本发明提供的基于非支配排序和猫头鹰搜索的多工作流调度方法的流程图。
图2为本发明提供的基于非支配排序和猫头鹰搜索的多工作流调度方法与其它算法在约束因子为0.25条件下的实验结果对比图。
图3为本发明提供的基于非支配排序和猫头鹰搜索的多工作流调度方法与其它算法在约束因子为0.5条件下的实验结果对比图。
图4为本发明提供的基于非支配排序和猫头鹰搜索的多工作流调度方法与其它算法在约束因子为0.75条件下的实验结果对比图。
图5为本发明提供的基于非支配排序和猫头鹰搜索的多工作流调度方法与其它算法在三个约束因子下得到的非支配前沿解数量对比图。
图6为本发明提供的基于非支配排序和猫头鹰搜索的多工作流调度方法与其它算法的超体积指标对比图。
图7为本发明提供的基于非支配排序和猫头鹰搜索的多工作流调度方法与其它算法的平均运行时间对比图。
具体实施方式
下面结合附图并举实施例,对本发明进行详细描述。
本发明提供的基于非支配排序和猫头鹰搜索的多工作流调度方法,其基本思想是采用猫头鹰搜索机制和非支配排序遗传机制,在混合公有云和私有云的资源环境中,同时处理多个工作流的调度问题,在满足多个用户指定的工作流截止期限和预算约束的同时,优化多工作流的总完工时间和执行成本,并进一步降低私有云资源的能耗。
本发明所引入的猫头鹰搜索算法是一种基于种群行为的新型智能优化算法,具有计算简单、收敛速度快的优点,但算法易陷入局部最优。猫头鹰搜索算法主要步骤包括:1、根据实际问题采用均匀分布随机初始化一组解决方案作为初始种群;2、使用问题的目标函数评估每个个体的适应度,进而筛选当前最优解;3、利用每个个体的归一化目标值以及个体与当前最优解之间的欧式距离来计算其强度变化量;4、根据声强平方反比定律和每个个体的强度变化量更新种群中的每个个体;5、根据迭代次数线性降低步长参数;6、判断是否达到预设的迭代条件,如果已达到,则结束循环,输出最优解;否则,转到步骤2,继续循环。
本发明提供的基于非支配排序和猫头鹰搜索的多工作流调度方法,流程如图1所示,具体包括以下步骤:
步骤1、获取具有截止期限和预算约束的多个工作流,根据工作流的截止期限为该工作流所属的任务分配子截止期限,按照子截止期限将所有任务排序,形成任务调度序列,采用任务调度序列初始化种群形成待处理种群;初始化迭代次数。
本发明中种群初始化是根据私有云资源和已租赁的公有云资源对每个粒子进行初始化形成初始种群的过程。本发明中,每个粒子对应多个工作流的一个调度方案,粒子的每一维代表工作流的任务,每一维的元素为执行此任务的资源(例如,虚拟机)在其可用资源列表中的编号(或序号)。所有粒子采用相同的任务调度序列,不同粒子的区别在于粒子中每个维度的数值的不同,即粒子中各任务所选的资源不同。粒子的初始化过程为,利用多个工作流的总任务数、每个工作流中各个任务可用的资源(例如,虚拟机)的数目以及设定的种群大小,对粒子进行随机初始化,即在可选范围内随机设定粒子的每一维度的数值。
步骤2、计算待处理种群中粒子对应的调度方案的适应度,适应度由工作流的总完工时间、执行成本及能耗表示;采用非支配排序遗传算法(nsga-ii算法),计算种群中所有粒子的密度,并根据适应度和密度对待处理种群中所有粒子进行非支配排序得到不同的非支配层,其中最高非支配层即为非支配前沿解集。
根据步骤1中得到的任务调度序列,依次计算任务的完工时间、执行成本、能耗等,每个粒子对应的多工作流总完工时间makespan、执行成本cost、能耗energy,可分别按如下公式计算计算:
式中,t表示多工作流的子任务集合,ti表示集合t中的第i个任务,ft(ti)和st(ti)分别表示任务ti的完工时间和开始执行时间;
本发明中,针对多工作流的特点,为了提高任务开始执行和完工时间计算的准确性,将工作流入口任务与其它任务进行区分计算,具体可采用如下公式进行计算:
ft(ti)=st(ti)+et(ti)+tt(ti)+soft(ti)(5)
其中,tentry为工作流入口子任务;
式中,length(ti)表示任务ti的指令长度,
本发明中,根据计算得到的粒子适应度来定义粒子是否为可行解,即若粒子中每个工作流的完工时间均满足其用户设定的截止期限,且每个工作流的执行成本均满足其用户设定的预算约束时,称该粒子为可行解;否则,只要其中任一个约束条件不能被满足,称该粒子为非可行解。若两个粒子中只有一个粒子为可行解,则选择为可行解的粒子;如果两个粒子都是可行解或非可行解,则根据下面定义的个体适应度支配关系,选择非支配粒子。
设粒子xi对应的完工时间、执行成本和能耗分别为teti、teci和energyi,粒子xj的相应参数分别为:tetj、tecj和energyj。非支配粒子为不被其他粒子支配的粒子,即若粒子xi支配粒子xj则粒子xi为非支配粒子;粒子xi支配粒子xj需要至少满足下列情况之一:
(1)粒子xi对应的总完工时间、执行成本和能耗都优于xj,即:
teti<tetjandteci<tecjandenergyi<energyj
(2)粒子xi对应的总完工时间、执行成本和能耗中有一个目标值与xj相同,另外两个目标分别优于xj,即:
teti=tetjandteci<tecjandenergyi<energyj
teti<tetjandteci=tecjandenergyi<energyj
teti<tetjandteci<tecjandenergyi=energyj
(3)粒子xi对应的总完工时间、执行成本和能耗中有两个目标值都与xj相同,另外一个目标优于xj,即:
teti=tetjandteci=tecjandenergyi<energyj
teti=tetjandteci<tecjandenergyi=energyj
teti<tetjandteci=tecjandenergyi=energyj
步骤3、当迭代次数为1时,由非支配前沿解集内所有满足截止期限和预算约束的非支配前沿解构成外部档案集;否则,利用待处理种群的非支配前沿解集与外部档案集中的所有粒子进行比较,更新外部档案集;当外部档案集不为空时,选择外部档案集中密度最高的解作为全局最优引导解;当外部档案集为空时,则选择非支配前沿解集中密度最高的解作为全局最优引导解。
其中,外部档案集的更新过程采用现有技术的方式,即通过将每个新产生的可行非支配解xg与外部档案集中的所有个体进行比较,实现对外部档案集的更新:
(1)若xg支配外部档案集中的某个个体,则从外部档案集中移除被xg支配的个体,并将xg添加进外部档案集中;
(2)若xg被外部档案集中某个个体所支配,则不添加xg至外部档案集中;
(3)若xg既不支配外部档案集中的任何一个个体,也不被外部档案集中任何一个个体所支配,则将xg添加进外部档案集中。
步骤4、当迭代次数达到设定阈值时,输出外部档案集中所有粒子对应的调度方案;否则,采用nsga-ii算法的精英解保留策略,遍历非支配层,形成大小相同的较优种群及较差种群,采用nsga-ii算法更新较优种群,采用猫头鹰搜索算法根据全局最优引导解更新较差种群。
种群的分组过程为:采用nsga-ii算法的精英解保留策略,根据快速非支配排序机制和个体解的密度值对种群个体进行分组。也就是说,从高到低遍历种群的非支配层,将非支配层越高或者一个非支配层中密度值越大的个体组成的集合定义为较优种群p1,而剩余个体自动构成较差种群p2,且p1和p2两个子种群的大小相同。种群的更新过程为:采用非支配排序遗传机制对较优种群p1进行更新,采用猫头鹰搜索机制对较差种群p2进行更新。
为了克服现有猫头鹰搜索算法存在易于陷入局部最优的缺陷,本发明改进了基本猫头鹰搜索算法,提出了基于混沌序列的猫头鹰搜索算法,利用混沌序列和非支配排序遗传算法对已有猫头鹰搜索算法进行改进,一是用混沌序列替换基本猫头鹰搜索算法的参数,并引入参数随机性和遍历性以增强算法的全局搜索能力;二是在猫头鹰搜索算法获得的当前非支配前沿解附近区域,利用混沌序列进行局部搜索,以提高算法的局部搜索能力;三是针对群智能优化算法容易陷入局部最优的问题,通过非支配排序遗传算法模拟染色体交叉变异的多样性生成和保持机制,来更新种群中的部分较优个体,在保证个体多样性的同时,避免搜索非支配解时陷入局部最优;四是通过动态电压频率调整方式,达到降低工作流执行能耗的目的。
采用基于混沌序列的猫头鹰搜索算法根据全局最优引导解更新较差种群的过程包括以下步骤:
步骤4.1、对较差种群p2中的每个粒子
式中,
步骤4.2、根据强度变化量
其中,βt表示第t代的步长参数,根据混沌系统的规律计算新的步长参数值βt+1:
式中,βmin和βmax分别表示步长参数β取值的上、下界。
步骤4.3、对更新后的种群进行适应度评价和快速非支配排序,在非支配前沿解集的每个调度方案附近区域进行局部搜索,以寻找更优的解。也就是说,对非支配前沿解集中的每个粒子
步骤4.3.1、初始化混沌局部搜索循环次数k(1≤k≤k)为1,并初始化维度参数d,即在[0,|t|)内,产生一个均匀分布的随机整数d,作为混沌局部搜索的维度值;
步骤4.3.2、根据任务td的可用虚拟机数量,按(14)式计算当前粒子第d维元素xd的新混沌变量值xdnew:
式中,|ard|为粒子第d维元素对应任务td的可用虚拟机集合ard的总的资源数,将新的混沌变量值xdnew对应的调度方案保存为新粒子cxk;
步骤4.3.3、判断循环次数k是否小于预设的k次。若循环次数k小于k,则k=k+1,然后转步骤4.3.1;若循环次数k大于或等于k,则分别计算新个体cx1,cx2,...,cxk的适应度,并找出其中的最优解cx*,将其与原粒子xs对应的调度方案进行比较,若cx*优于原粒子xs,则用cx*替换xs。
步骤5、将较优种群与较差种群合并形成整合种群,以整合种群更新待处理种群;迭代次数自加1,执行步骤2。
实施例:
为了检验本发明提出的利用基于混沌序列和非支配排序的猫头鹰搜索算法(hcnsg-osa)进行绿色云环境下多工作流调度的效果,本专利使用云工作流仿真模拟工具workflowsim来模拟混合云,并优化了相应的参数设置接口,以针对不同用户提交的工作流设置相应的截止期限和预算约束。实验选取了基于混沌序列的猫头鹰搜索算法(chaotic-osa)和几个流行的多目标智能优化算法作对比,如混合粒子群算法(hpso)、多目标差分进化算法(mode)、非支配排序遗传算法(nsga-ii)。
针对随机生成的5个小规模工作流,并使用13个不同处理能力的虚拟机,在3个约束因子(例如:0.25,0.5,0.75)下进行调度仿真实验。所有上述算法都是随机搜索算法,所以每个实验运行15次以进行统计分析。选取多工作流的总完工时间、执行成本和能耗,以及非支配前沿解的数量、超体积和算法平均运行时间作为评价指标,对算法的调度性能进行评估比较,其实验对比结果如图2至图6所示。
由图2、图3、图4可知,在紧约束下,即约束因子为0.25时,mode算法不能找到同时满足截止期限和预算约束的调度方案。此外,在不同的约束因子下,本专利提出的算法均能找到较好的非支配前沿解集。虽然,在所找到的非支配前沿解集中,存在一部分个体被mode算法支配的情况,但总体上看,其给出的非支配前沿解集具有更好的多样性。从图5可以看出,在大多数情况下,本发明提出的算法均可以获得较多的非支配前沿解,且在15次实验中,本算法所搜索到的总体非支配解数目占较大优势。也就是说,本发明提出的算法可以产生更多的优化调度方案供用户选择。由图6可知,在松约束条件下,osa算法的超体积较小;在约束因子为0.25和0.5时,本发明提出的算法表现最好,能得到较大的超体积。由图7可以看出,mode算法的执行时间开销较大,是本专利提出算法的2倍以上。
综上,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!