一种基于骨架姿态的人物识别方法与流程
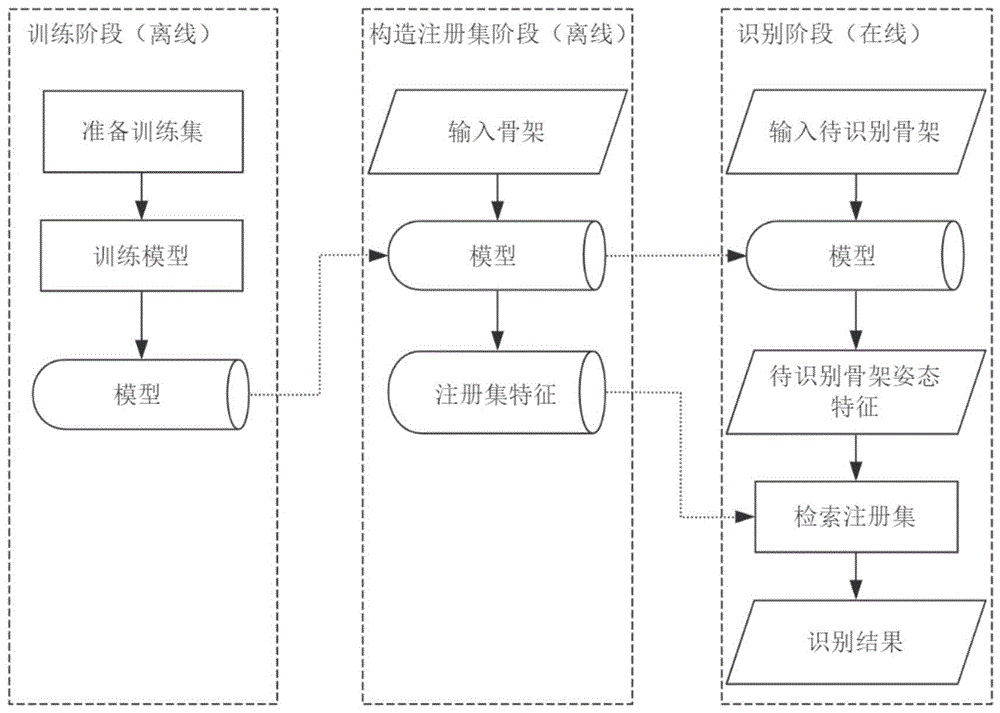
本发明属于统计模式识别与图像处理
技术领域:
,具体涉及一种基于骨架姿态的人物识别模型。
背景技术:
:近年来,智能视频监控的应用场景越来越广泛。如何判断视频中人物的身份,即人物识别,是智能视频监控领域中一个重要问题。人物识别的一个实现方法是利用行人再识别技术进行人物身份跟踪。行人再识别的目标是将不同摄像机中拍摄到的同一个人物识别出来,它的实现方法是使用深度学习网络学习人物的深度特征,并设计损失函数增加特征对类内变化的鲁棒性,以准确识别不同环境下的同一人物。技术实现要素:本发明的目的在于提供一种基于骨架姿态的人物识别方法,该方法应用于智能视频监控,能有效解决视频中的人物识别问题。本发明提供一种基于骨架姿态的人物识别方法,分为三个阶段:离线训练阶段,离线构造注册集阶段和在线识别阶段;(一)离线训练阶段,首先准备模型训练集,将openpose格式的骨架关键点坐标经过归一化后转化为36维向量作为模型输入,然后对模型进行训练;模型的网络结构包括生成模块和判别模块;所述生成模块包括姿态编码器es、动作编码器ea、生成器g和判别器d四个子模块,每个子模块都各自由输入层、隐藏层和输出层组成;其中,姿态编码器es和动作编码器ea的输入层分别输入36维的骨架数据,输出层分别输出16维的姿态特征和196维的动作特征;生成器g的输入层的输入为一个212维向量,其第0到第15维为姿态特征,第16到第211维为动作特征,输出层输出36维的合成骨架;判别器d的输入层输入合成骨架,输出层输出36维的判别结果;所述判别模块,其与生成模块共用姿态编码器es,给定输入骨架,将es输出的16维姿态特征作为该骨架的表示特征,在在线识别阶段中作为骨架数据所属人物的标识符id检索的依据;判别模块在es输出层后加入一个长度为n的全连接层得到id概率分布向量,其中n为训练集中id类别的个数;id概率分布向量中最大分量的维数即为人物骨架的id;(二)离线构造注册集阶段,首先将用于构造注册集的骨架输入训练好的模型,得到骨架姿态特征,再将特征归一化得到注册集特征;(三)在线识别阶段,首先将待识别骨架输入训练好的模型,得到待识别的骨架姿态特征,并对特征进行归一化,然后计算待识别的骨架姿态特征和各注册集特征之间的相似度,最后取相似度最大的注册集特征的人物id作为检索结果.本发明中,步骤(一)中,离线训练阶段的每个训练集样本包括骨架数据和骨架数据所属人物的标识符id,id是由一个0到n-1之间整数表示,其中n为训练集中id类别的个数;准备骨架数据的步骤如下所示:第一步:采用openpose训练使用的骨架格式组织骨架数据,每个骨架包含18个人体关键点坐标,将18个关键点坐标由0到17编号,每个关键点所表示的人体位置如下所示:0-鼻子,1-脖子,2-右肩,3-右肘,4-右手腕,5-左肩,6-左肘,7-左手腕,8-右臀,9-右膝盖,10-右脚踝,11-左臀,12-左膝盖,13-左脚踝,14-右眼,15-左眼,16-右耳,17-左耳;第二步:将第一步得到的18个关键点坐标逐个进行归一化,归一化的公式如下所示:其中,(x,y)表示归一化前的坐标,w表示提取骨架关键点的图像的宽,h表示提取骨架关键点的图像的高,(x′,y′)表示归一化后的坐标;第三步:将第二步得到的18个关键点坐标(x0,y0),(x1,y1),…,(x17,y17)转化为36维的向量(x0,y0,x1,y1,…,x17,y17)。本发明中,步骤(一)中,模型中的生成模块损失函数如下所示:ladv(xp,g(sp,aq))=e[logd(xp)+log(1-d(g(sp,aq))][式7]判别模块损失函数如下所示:其中,xp表示第p个样本中的骨架,sp和ap分别表示由骨架xp提取的姿态特征和动作特征。姿态特征表示骨架的长度、形态等与人物身份特征相关的信息,动作特征表示骨架的动作等与人物身份特征无关的信息。g(sp,aq)表示由骨架xp的姿态特征sp和骨架xq的动作特征aq合成的骨架,es(g(sp,aq))和ea(g(sp,aq))分别表示由g(sp,aq)提取的姿态和动作特征,d(xp)表示判别器d对骨架xp的输出;在模型训练的每次迭代中,从训练集中随机取出四个骨架xi,xj,xm,xn,其中xi与xj属于不同id,xi与xm,xj与xn分别属于同一id;首先进行生成模块的训练,更新所有生成模块中的参数,再进行判别模块的训练,更新所有判别模块的参数;其中:生成模块的训练步骤如下所述:第一步:分别通过es与ea提取xi的姿态特征si与动作特征ai,分别对xj,xm,xn进行与xi相同的操作,得到sj,aj,sm,am,sn,an;第二步:将si与ai进行拼接,输入生成器g,得到g(si,ai),分别对xj,xm,xn进行相同的操作,得到g(sj,aj),g(sm,am),g(sn,an);根据式2,计算第三步:将sm和ai进行拼接,输入生成器g,得到g(sm,ai),将sn和aj进行拼接,输入生成器g,得到g(sn,aj);根据式3,计算和第四步:由g(si,aj)提取姿态特征es(g(si,aj))和动作特征ea(g(si,aj)),由g(sj,ai)提取姿态特征es(g(sj,ai))和动作特征ea(g(sj,ai));根据式4,计算根据式5,计算第五步:将es(g(si,aj))和ea(g(sj,ai))输入生成器g,得到g(es(g(si,aj)),ea(g(sj,ai))),将es(g(sj,ai))和ea(g(si,aj))输入生成器g,得到g(es(g(sj,ai)),ea(g(si,aj)));根据式6,计算和第六步:将g(si,aj)和xi分别输入判别器d,输出d(g(si,aj))和d(xi),将g(sj,ai)和xj分别输入判别器d,输出d(g(sj,ai))和d(xj);根据式7,计算ladv(xi,g(si,aj))和ladv(xj,g(sj,ai));判断模块的训练步骤如下所述:将xi,xj,g(si,aj),g(sj,ai)分别输入姿态编码器es,es输出姿态特征后通过全连接层得到id概率分布向量;根据式8,计算根据式9,计算本发明中,所述步骤(二)中的离线构建注册集阶段,注册集由骨架姿态特征构成,且每个姿态对应一个人物id;注册集特征称为在库特征,是在线识别阶段中待识别特征的检索对象,由姿态编码器es输出16维的姿态特征,按照式1对特征进行归一化,获得注册集姿态特征。本发明中,所述步骤(三)中的在线识别阶段的具体步骤为:(1)获取待识别骨架姿态特征将待识别骨架输入训练好的模型,得到待识别的骨架姿态特征,对特征按照式1进行归一化;(2)检索在库骨架特征计算待识别的骨架姿态特征和各注册集姿态特征之间的相似度,相似度公式如下所示:其中,sim(x,y)表示特征x与特征y之间的相似度,用余弦距离来衡量。向量是特征x,y对应的向量,和表示向量的模长,当与的模长为1时,余弦距离等于与的点积。(3)获取id识别结果将上一步中得到的相似度由大到小排序,取相似度最大的注册集特征的id作为当前骨架的识别结果。与现有的基于深度学习的人物识别方法通过对图像提取深度特征进行人物识别相比,本发明的有益效果在于:通过提取人体骨架关键点并基于骨架进行人物识别,能够有效地避免复杂环境下人物难以用包围盒区分、人物识别易受到衣服颜色等外观因素的干扰的问题。此外,在实际应用过程中,人体骨架关键点提取过程将在边缘计算设备上处理(如微软kinect),仅需将关键点数据发送至远端服务器进行人物识别,所需传输的数据体积远小于基于图像的方法(传输整幅图像),对网络的带宽要求极低。本发明基于骨架关键点进行人物识别,扩展了人物识别的方法,在智能视频监控领域有广阔的应用可能。附图说明图1是基于骨架姿态的人物识别方法的流程图。图2是基于骨架姿态的人物识别模型网络结构图。具体实施方式下面结合附图和实施例对本发明的技术方案进行详细介绍。如图1所示,本发明提供一种基于骨架姿态的人物识别方法包括离线训练阶段、离线构造注册集阶段和在线识别阶段;在离线训练阶段,首先准备模型训练集,将openpose格式的骨架关键点坐标经过归一化后转化为36维向量作为模型输入,然后对模型进行训练。在离线构造注册集阶段,首先将用于构造注册集的骨架输入训练好的模型,得到骨架姿态特征,再将特征归一化得到注册集特征。在在线识别阶段,首先将待识别骨架输入训练好的模型,得到待识别的骨架姿态特征,并对特征进行归一化,然后计算待识别的骨架姿态特征和各注册集特征之间的相似度,最后取相似度最大的注册集特征的人物id作为检索结果。具体的流程如下。一、离线训练阶段,具体步骤为:(1)准备训练集。每个训练集样本包括骨架数据和id。id是骨架数据所属人物的标识符,由一个0到n-1之间整数表示,其中n为训练集中id类别的个数。准备骨架数据的步骤如下所示:第一步:采用openpose[1]训练使用的骨架格式组织骨架数据。每个骨架包含18个人体关键点坐标。将18个关键点坐标由0到17编号,每个关键点所表示的人体位置如下所示:0-鼻子,1-脖子,2-右肩,3-右肘,4-右手腕,5-左肩,6-左肘,7-左手腕,8-右臀,9-右膝盖,10-右脚踝,11-左臀,12-左膝盖,13-左脚踝,14-右眼,15-左眼,16-右耳,17-左耳第二步:将第一步得到的18个关键点坐标逐个进行归一化。归一化的公式如下所示:其中,(x,y)表示归一化前的坐标,w表示提取骨架关键点的图像的宽,h表示提取骨架关键点的图像的高,(x′,y′)表示归一化后的坐标。第三步:将第二步得到的18个关键点坐标(x0,y0),(x1,y1),…,(x17,y17)转化为36维的向量(x0,y0,x1,y1,…,x17,y17)(2)训练模型1、模型网络结构基于骨架姿态的人物识别模型分生成模块和判别模块两部分,模型的网络结构如图2所示,网络参数如表1所示。生成模块主要由四个子模块组成:姿态编码器es、动作编码器ea、生成器g和判别器d。姿态和动作编码器的输入为36维的骨架数据,输出分别为16维的姿态特征和196维的动作特征。生成器g的输入为一个212维向量,其第0到第15维为姿态特征,第16到第211维为动作特征,输出为36维的合成骨架。最后,将合成骨架输入判别器d,判别器d输出36维的判别结果。判别模块与生成模块共用姿态编码器es。给定输入骨架,将es输出的16维姿态特征作为该骨架的表示特征,在在线识别阶段中作为id检索的依据。判别模块在es输出层后加入一个长度为n的全连接层得到id概率分布向量,其中n为训练集中id类的总数。id概率分布向量中最大分量的维数即为人物骨架的id。2、模型损失函数生成模块损失函数如下所示:ladv(xp,g(sp,aq))=e[logd(xp)+log(1-d(g(sp,aq))][式7]判别模块损失函数如下所示:其中,xp表示第p个样本中的骨架,sp和ap表示由xp提取的姿态和动作特征,g(sp,aq)表示由xp的姿态特征sp和xq的动作特征ap合成的骨架,es(g(sp,aq))和ea(g(sp,aq))分别表示由g(sp,aq)提取的姿态和动作特征。d(xp)表示判别器d对xp的输出。3、模型训练过程在模型训练的每次迭代中,从训练集中随机取出四个骨架xi,xj,xm,xn,其中xi与xj属于不同id,xi与xm,xj与xn分别属于同一id。首先进行生成模块的训练,更新所有生成模块中的参数,再进行判别模块的训练,更新所有判别模块的参数。生成模块的训练步骤如下所述:第一步:分别通过es与ea提取xi的姿态特征si与动作特征ai。分别对xj,xm,xn进行与xi相同的操作,得到sj,aj,sm,am,sn,an。第二步:将si与ai进行拼接,输入生成器g,得到g(si,ai),分别对xj,xm,xn进行相同的操作,得到g(sj,aj),g(sm,am),g(sn,an)。根据式2,计算第三步:将sm和ai进行拼接,输入生成器g,得到g(sm,ai)。将sn和aj进行拼接,输入生成器g,得到g(sn,aj)。根据式3,计算和第四步:由g(si,aj)提取姿态特征es(g(si,aj))和动作特征ea(g(si,aj)),由g(sj,ai)提取姿态特征es(g(sj,ai))和动作特征ea(g(sj,ai))。根据式4,计算根据式5,计算第五步:将es(g(si,aj))和ea(g(sj,ai))输入生成器g,得到g(es(g(si,aj)),ea(g(sj,ai))),将es(g(sj,ai))和ea(g(si,aj))输入生成器g,得到g(es(g(sj,ai)),ea(g(si,aj)))。根据式6,计算和第六步:将g(si,aj)和xi分别输入判别器d,输出d(g(si,aj))和d(xi),将g(sj,ai)和xj分别输入判别器d,输出d(g(sj,ai))和d(xj)。根据式7,计算ladv(xi,g(si,aj))和ladv(xj,g(sj,ai))判断模块的训练步骤如下所述:将xi,xj,g(si,aj),g(sj,ai)分别输入姿态编码器es,es输出姿态特征后通过全连接层得到id概率分布向量。根据式8,计算根据式9,计算二、离线构建注册集阶段:注册集由骨架姿态特征构成,且每个姿态对应一个人物id。注册集特征称为在库特征,是在线识别阶段中待识别特征的检索对象。离线构建注册集阶段的具体步骤为:将用于生成注册集特征的骨架输入训练好的模型,由姿态编码器es输出16维的姿态特征,按照式1对特征进行归一化,获得注册集姿态特征。三、在线识别阶段,具体步骤为:(1)获取待识别骨架姿态特征。将待识别骨架输入训练好的模型,得到待识别的骨架姿态特征,对特征按照式1进行归一化。(2)检索在库骨架特征。计算待识别的骨架姿态特征和各注册集姿态特征之间的相似度,相似度公式如下所示:其中,sim(x,y)表示特征x与特征y之间的相似度,用余弦距离来衡量。向量是特征x,y对应的向量,和表示向量的模长,当与的模长为1时,余弦距离等于与的点积。(3)获取id识别结果。将上一步中得到的相似度由大到小排序,取相似度最大的注册集特征的id作为当前骨架的识别结果。下面结合具体实施例对本发明的技术方案进行详细阐述。实施例1一、训练模型训练数据集采用主流数据集msmt17,生成器g和判别器d的学习率设置为0.00001,姿态编码器es输出层后的全连接层的学习率设置为0.002,网络其他部分的学习率设置为0.0002,训练的batchsize设置为8,总共进行10万次迭代。二、实验结果实验查询集采用主流数据集msmt17。本次实验在实验数据集上的结果如表2所示,作为对照的算法是dgnet[2](cvpr2019上提出,当时最优的算法),实验结果表明,本发明的方法在准确率方面优于dgnet,模型的查询准确已经能满足一般人物检索的需求,具备在实际场景中应用的可能性。表2实验结果rank-1准确率rank-5准确率rank-10准确率mapdgnet方法77.2%87.4%90.5%52.3%本发明的方法78.1%88.9%92.2%59.7%以下为map和rank-n指标的计算方法:假设查询集包含n个骨架,qi表示查询集中第i个骨架,则将查询集记作:q={q1,q2,…,qi,…,qn}。假设注册集包含m个骨架姿态特征,gi表示注册集中第i个特征,则注册集记作:g={g1,g2,…,gi,…,gm}。对qi提取特征,得到qi,qi的id在g中出现的次数记为对每个查询集骨架的特征进行以下检索过程:将qi依次与g中每个骨架姿态特征计算相似度,按照相似度从大到小对g进行排列,排序后的注册集记作注册集中与qi拥有相同id的特征组成的数据集记为是的子集。设在中的排位为rj,在中的排位为得到map计算公式如下:rank-n的计算方法为:若中前n个特征的id中出现了qi的id,则称qi满足前n位命中。q中所有满足前n位命中的特征数记为则参考文献[1]zhecao,gineshidalgo,tomassimon,shih-enwei,andyasersheikh.openpose:realtimemulti-person3dposeestimationusingpartaffinityfields.inarxivpreprintarxiv:1812.08008,2018.[2]zhedongzheng,xiaodongyang,zhidingyu,liangzheng,yiyang,andjankautz.jointdiscriminativeandgenerativelearningforpersonre-identification.inproc.cvpr,2019.当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1