一种基于AttGan模型生成家族字体的方法与流程
本发明涉及一种家族字体插值生成的方法,具体说是一种基于attgan模型生成家族字体的方法,属于计算机图形处理技术领域。
背景技术:
目前,在汉字识别(chinesecharacterrecognition)上国内的研究很多,而且随着深度学习的应用已经达到了很高的效果。但是在汉字生成方面,国内外的研究就少了许多,而且这方面的研究具有相当大的挑战,因为中国的汉字字体风格形式变化多端,字体结构复杂,而且汉字的数目巨大。也因此很多关于字体生成的算法研究文献都集中在英语和拉丁文字符上。因为英文和拉丁文等的数量比汉字的数量要小了很多倍,而且它们的字体风格变化也要比汉字少了很多。字体生成一直是一个比较活跃的研究方向,汉字由于复杂的结构和众多的数量,汉字字体的生成相较于英文字体生成难度和复杂度都更高。
近年来,参数模型基于生成性对抗性网络(gans)一直很受欢迎,并取得了令人瞩目的成绩。但是,gans模型整个生成过程是无法控制和不可预测的,细节识别处理得不好,在生成的字体中通常包含模糊和重影的伪图像。受到gans在生成任务方面的成功的启发,“pix2pix”框架使用了条件生成学习从输入到输出图像的映射。特别是,在人脸生成方面,利用基于gans的模型来通过控制参数来生成新图像,例如头发颜色可控的面部图像,年龄、性别等。attgan模型主要是研究了人面部属性编辑任务,其目的是通过操作单个或多个感兴趣的属性(如头发颜色、表情、胡须和年龄)来生成新图像。对于传统的人脸识别和大规模标记数据集、人脸属性预测任务取得了显著进步。
字体家族设计门槛较高,虽然部分有能力的设计师可以独立的完成一套字体的设计,但是如果要完成一套完整的字体家族设计是较为困难的,字体家族是为了排版而诞生的产物,在排版中版面有大标、副标、内文、强调、引用、批注等不同区块。而这些文字的样貌各自要有区隔、体现出层级,才能达到不错的页面排版。如何利用计算机技术实现快速辅助地生成字体家族成为了一个亟待解决的问题。
技术实现要素:
为解决现有技术存在的上述问题,本申请提出一种基于attgan模型生成家族字体的方法。通过对字体家族中不同字体图像的编码之间,加入相应的参数进行插值控制字体样式的生成,从而获得中间字体图像。输入多个样本,包括细体数据集、粗体数据集样本不同样式的字体,模型训练完成后通过控制字体的属性标签如字重、字高、字宽、中宫等,利用属性标签去监督性的去编辑字体图像,在训练阶段利用重构误差、标签分类误差、对抗损失实现了标签对应字体属性的再编辑,使参数属性值决定字体生成样式,由此构建完整的字体家族。
本发明采用的技术方案是:一种基于attgan模型生成家族字体的方法,包括以下步骤:
步骤1,数据集的准备和预处理:将目标字体的细体数据集样本和粗体数据集样本进行处理,生成细体数据集样本图片和粗体数据集样本图片,并归一化到256*256的尺寸。
步骤2,标注所述细体数据集样本图片和粗体数据集样本图片的部分参数属性值,采用半监督学习方式,标注剩余的参数属性值,构建属性分类器c。
步骤3,采用编码器genc和解码器gdec两个基本的子网络,配合属性分类器c和判别器d,用adversarialloss和reconstructionloss作为损失函数,构建基于attgan网络的训练模型。
步骤4,将所述细体数据集样本图片和粗体数据集样本图片依次输入到基于attgan网络的训练模型中,对模型进行训练、优化和调参,通过修改图片中字体的参数属性值,插值生成目标字体样式的过渡字形图像。
步骤5,通过余弦相似度计算目标字体原始图像与插值后生成图像的相似度,进一步说明字体家族的统一性。
步骤6,将步骤4生成的过渡字形图像和原始图像结合,得到gb2312字库完整的家族字体图像集合,对家族字体图像集合进行矢量化操作,生成计算机字库文件。
步骤4中将所述的细体数据集样本图片和粗体数据集样本图片依次输入到编码器genc中,编码器genc包含5个向下采样层,每层经过卷积、批归一化、leakyrelu激活,编码得到向量;将编码得到的向量与字体参数属性值嵌入向量进行连接得到一个64维的嵌入向量,送到解码器gdec,解码器gdec包含5个向上采样层,每层经过反卷积、批归一化、relu激活,最终输出目标字体样式的过渡字形图像。所述编码器genc和解码器gdec之间使用u-net的对称跳跃连接。
所述判别器d采用卷积神经网络结构,判别器d输入的是真实的目标字体图像和解码器gdec输出的插值后生成的图像,判别器d采用5个级联的conv-ln/in-leakyrelu网络和两层全连接神经网络结构。
所述属性分类器c和判别器d共享所有的卷积层。
在字体参数属性值嵌入部分,使用一个cnn风格的编码器来转换选定的字形图像到64维的参数属性值嵌入向量,所有图像沿深度全连接,输入到风格编码器,对训练模型进行训练,通过预测属性值合成字形图像,实现不同字体之间的平滑插值,生成目标字体样式的过渡字形图像。采用adam优化器对所述的训练模型进行优化,其中,adam的参数设置为β1=0.5,β2=0.999,lr=0.0002。
所述参数属性值是指字体的常用属性,优选地,参数属性值包含字体的serif、cursive、display、italic、strong、thin和wide。
进一步的,为了验证本申请中的模型在字体家族生成上的性能。将输入的细体数据集样本、粗体数据集样本转化为图片,并且进行归一化,调整到大小为:256*256,并将图像转换为二值图像,保证最终汉字在原始分布与特定分布中的位置与大小一致。在向神经网络输入字体图像时,为了消除奇异样本数据导致的不良影响,首先对输入的图像进行归一化处理,将图片数据灰度值0-255映射到0-1范围内,将归一化处理后的数据加入一定量的噪声,然后输入到模型中。
进一步的,在步骤2中,属性编辑的问题可以定义为编码器和解码器的学习过程。根据已标注的图片,学习给未标注的图片打标签,这个过程是非监督的,目的就是在原图
进一步的,一个具有n个属性的图片
进一步将
在属性分类器部分生成图应该预测正确获得新属性b。因此,部署属性分类器来限制它获得所期待的属性,带标签的风格嵌入向量θ和其关系如下:
进一步的,在步骤3中,训练模型中,采用编码器和解码器架构作为生成器,编码器输入的是多个不同样式的字体图片,大小为256*256,所述编码器genc包含5个向下采样层,每层经过卷积、批归一化、leakyrelu激活,编码得到向量;将编码得到的向量与步骤二里带标签的字体风格嵌入向量进行连接,每个属性的标签是一个标量,相当于把这个标量扩展成一个张量,在这里则是扩展成和解码器gdec中每层的特征图一样大的尺寸64维的,每一张图片参数属性值包括了serif、cursive、display、italic、strong、thin和wide等,使得网络在训练时能够更好的预测字体与目标参数风格结合生成新字体。之后将向量送到解码器gdec,解码器gdec包含5个向上采样层,每层经过反卷积、批归一化、relu激活,最终得到输出字体图像。在训练过程中,优化器采用adam,参数设置为β1=0.5,β2=0.999,lr=0.0002。
进一步的,为了减少神经网络参数,属性分类器和判别器共享所有的卷积层;为了减少编码过程中的字体特征损失,在encoder和decoder之间使用了u-net的对称跳跃连接。在步骤3中判别器与步骤二中构建的属性分类器,采用卷积神经网络结构,采用5个级联的conv-ln/in-leakyrelu网络结构,最后采用两层全连接神经网络。判别器输入的是真实的字体图像以及预测更改参数后生成的字体图像,分辨其差异性,用adversarialloss衡量如公式1
更进一步的,假设参考字体服从分布,通过与判别器d的博弈,生成器将噪声生成,在模型的训练阶段,生成器尝试生成真实的结果去欺骗判别器,而判别器的目标是分辨生成结果与真实结果间的区别;
更进一步的,为了准确描述生成图像与真实图像的像素空间的相似程度,引入像素匹配损失函数,如公式2所示:
进一步的,在步骤5中,数字图像包含的较多的特征,这正是余弦相似度算法应用的范围,因此采用余弦相似度对生成的字体图像进行简单的对比,余弦相似度公式如公式3,其中u和v分别代表物品a、b,n(u)表示u正反馈的特征属性集合,n(v)为v正反馈的特征属性集合。
也进一步说明通过插值的方法生成的家族字体的有效性,通过余弦相似度计算原始图像与插值后生成图像的相似度,对于流形向量可采取n维的向量公式表示,如公式4所示,给定的图片特征向量为
本发明的有益效果是:这种基于attgan模型生成家族字体的方法,基于编码器-解码器结构,合理使用属性分类约束、重构及对抗学习,最终能够利用一个模型较好地修改多个感兴趣的属性并且保持其它区域不变,通过attgan网络模型,加入属性分类约束层,修改家族字体中不同的字重、字高等参数属性值,实现了不同字体之间的平滑插值,生成控制字体样式的过渡字形图像。通过参数属性值决定字体生成样式,由此构建完整的字体家族。该家族字体生成方法可以极大减轻设计师的负担,减少了设计的周期时间,帮助设计师解决大量重复性工作的问题,提升工作效率。
附图说明
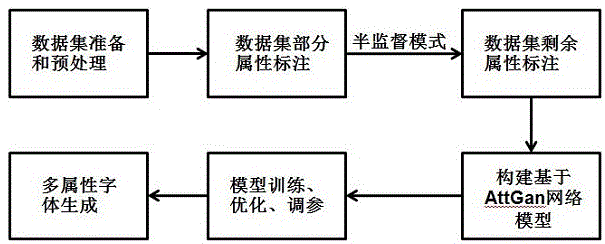
图1是一种基于attgan模型生成家族字体的方法的流程图。
图2是一种基于attgan模型生成家族字体的方法的网络结构图。
图3是实施例中英文字体的生成效果图。
图4是实施例中中文字体的生成效果图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施中的技术方案进行清楚、完整的描述,可以理解的是,所描述的实例仅仅是本发明的一部分实例,而不是全部的实施例。基于本发明的实施例,本领域的技术人员在没有做出创造性劳动的前提下所获得的所有其他实施例,都属于本发明的保护范围。
图1示出了一种基于attgan模型生成家族字体的方法的流程图,图2示出了一种基于attgan模型生成家族字体的方法的网络结构图,这种生成家族字体的方法具体实施步骤如下:
首先对设计师提供的目标字体的粗体数据集和细体数据集,转化为图片格式,并调整大小,统一缩放到256*256尺寸,将归一化处理后的数据加入一定量的噪声,输入到编码器genc中。
构建基于attgan网络的训练模型(如图2所示)。在训练神经网络过程中,将字体图像输入到编码器genc中,生成具有目标字体风格的图像y,同时将目标字体图像与生成字体图像输入到判别器中,判别真伪,并计算损失函数。如公式(1)所示。对于判别器而言,希望网络生成的字体图像被判别出假的可能性越大越好。而生成网络希望生成的字体图像被判别为真的可能性越大越好。所以生成网络最小化损失函数,而判别网络最大化损失函数,调整网络参数。
计算判别器对于生成图像与真实图像之间的判别损失,如下式所示:
计算像素匹配损失函数,计算y与目标字体l1距离,如下式所示:
计算字体重构损失函数,通过sigmoid交叉熵损失函数,如下式所示:
最后将3种误差进行加权求和,总损失函数l为:
l=λ1lrec+λ2lpixel+ladvd
其中,λ1=100,λ2=10。
网络训练完成之后,将不同数据集与加入带标签的风格嵌入向量一起输入到网络的生成器中,训练过程不断迭代,预测更改参数后生成的字体图像,经过属性分类器,判别器与源图像判别差异,生成最终的图像。
进一步地,验证部分选用相同的一百个字符集作为神经网络的输入,将字符集生成为细体和粗体两种字体图像,首先将细体字体图像输入至训练好的模型中生成粗体风格的字体图像,在通过插值生成常规字体图像,将生成的图像与原始字体图像的余弦相似度的平均值作为最终的相似度。
本实施例分别做了英文字符数据集实验和中文字符数据集实验,将英文字符数据集生成细体和粗体两种字体图像,归一化为256*256的尺寸,依次输入到基于attgan网络的训练模型中,经过1000次迭代后,生成较为清晰的英文字体图像(如图3所示),同样的,将中文字符数据集处理为细体和粗体两种字体图像,依次输入到训练模型中,得到中文字符集的生成效果图(如图4所示)。
本发明提供的这种基于attgan模型的家族字体生成的方法,基于编码器-解码器结构,合理使用属性分类约束、重构及对抗学习,最终能够利用一个模型较好地修改多个感兴趣的属性并且保持其它区域不变,通过attgan网络模型,加入属性分类约束层,通过修改家族字体中不同的字重、字高等参数属性值,实现了不同字体之间的平滑插值,生成控制字体样式的过渡字形图像,从而使参数属性值决定字体生成样式,由此构建完整的字体家族。
- 还没有人留言评论。精彩留言会获得点赞!