地理语义关联约束的多视频事件盲区变化过程推演方法与流程
本发明涉及一种地理语义关联约束的多相机视频事件信息盲区变化过程推演方法,属于地理空间数据处理技术领域。
背景技术:
单摄像机获取的地理视频内容受成像窗口时空局域性的影响,记录的是特征对象在特定地点或区域的短时行为过程,基于单摄像机的地理视频内容因而仅局限于解析局部异常变化对应的局域小尺度事件;网络监控环境下全局关联的多地理视频虽然有效扩展了监控时空窗口的整体范围,提供了记录多尺度复杂事件信息的地理视频数据集,但数据内容中的事件知识仍受到监控设备作用域普遍的离散和无重叠分布影响而存在大量信息盲区。为了支持对复杂事件发生发展过程的完整认知并为面向不同层次事件信息的地理视频数据组织检索提供丰富的检索入口和正确的约束条件,发展面向事件信息盲区的地理视频关联语义增强方法,成为继“实现多摄像机离散地理视频数据层次定性、作用定向和特征定量的关联聚集”之后,“支持关联约束检索的地理视频组织研究”亟需解决的又一关键问题。
支持应急处置任务决策的事件认知需要从“是什么”和“在哪里”的现象认知,进化到能回答“是怎样”的过程认知。相对于盲区变化过程信息的缺失,地理视频内容中的变化过程是可知的信息集。根据逻辑学研究思路,基于对象自身各组成部分的相互关系规律,从部分数据中推理无法获取的某类事物的全部对象信息是思维的基本形式。由此,如何充分利用已知的内容变化信息合理推演盲区中的变化过程成为实现地理视频关联语义增强的核心问题。
技术实现要素:
本发明的目的在于提供一种地理语义关联约束的多相机视频事件信息盲区变化过程推演方法。具体针对面向事件过程关联聚类的地理视频镜头组中因监控设备作用域离散分布影响而普遍存在的事件信息盲区问题,提出一种地理语义关联约束的多相机视频事件信息盲区变化过程推演方法。创新了从“面向单一视频图像空间”到“联合地理视频内外场景空间”的地理视频内容解析机制与从“局部特征相似性约束”到“全局地理相关性约束”的地理视频gis分析机制。
本发明为实现上述目的所采用的技术方案是:地理语义关联约束的多视频事件盲区变化过程推演方法,包括以下步骤:
步骤1,地理位置的条件约束构建:获取监控区域专题语义信息,解析其中的地理位置语义,提取地理位置对象和对象关系;面向位置关系构建纵向语义位置层次结构和横向语义位置联通网络,表达监控场景区间统一定位区间划分下的地理位置语义关联;
步骤2,运动模式的趋势约束解析:在三维建筑模型构成元素几何形体表达维度和语义概念描述粒度的基础上,分类归纳、解析并利用三维建筑模型中的特征语义关系,提取完整表达三维建筑物模型且正则形体化的位置边界特征用于基于位置特征的运动模式判别;
步骤3,时空距离的代价约束估计:利用轨迹的统计特征,在有序组织的地理视频镜头组间,通过逐相邻行为过程的轨迹对分析行为过程间信息盲区的行为运动特征,建立映射时空距离迁移代价的盲区行为过程特征参数;
步骤4,多约束监控盲区行为过程推演:联合场景的地理位置关系网、视频内容中行为过程的地理运动模式,以及基于时空距离和轨迹特征定量求解的路径判别指标,进行监控盲区地理实体移动行为过程语义路径推演,以增强实现地理视频镜头组语义元数据中监控盲区的关联语义增强。
所述地理位置的条件约束构建包括以下步骤:
步骤1.1,提取监控场景区域的专题地理位置对象集:
首先,面向监控场景区域地理视频镜头组,提取各地理视频镜头包含的地理视频帧对象的元数据,通过元数据中的成像特征项获取各地理视频镜头的三维监控场景成像区间,构成成像区间集;
然后,基于成像区间集的整体空间区域,得到能完整覆盖多地理视频内容中离散变化过程的监控场景区间,作为统一基准的地理位置基本表达范围;
之后,利用地理位置基本表达范围作为空间检索条件,获取包括位置相关的几何、拓扑、语义、属性及功能的目标位置信息描述,保存每个目标位置信息描述为一个地理位置对象,构成专题地理位置对象集;
步骤1.2,构建纵向语义位置层次结构:
根据专题地理位置对象集中地理位置对象几何要素的空间包含关系,构建地理位置对象纵向层次结构,即父位置—子位置逐层嵌套的层次结构;对层次组织的地理位置对象,逐地理位置对象检查其区域内的定位空间划分的位置名称表达,以保证区域内位置对象名称的规范性与唯一性;将规范表达的位置名称作为地理位置对象的唯一标识码;
步骤1.3,构建横向语义位置联通网络:
在构建了纵向语义位置层次结构的基础上,利用与地理位置对象同步提取的对象间拓扑、语义、属性及功能关系信息,根据地理位置对象的语义联通关系,判别两两地理位置对象间支持特征对象迁移的以位置接口为条件载体的联通性,保存支持位置间联通性的条件约束信息项为条件约束的位置联通关系;其中,条件约束信息项划分并保存为空间约束、时间约束和功能属性约束,作为构建联通网络时各联通关系查询接口条件;
完成构建纵向语义位置层次结构和横向语义位置联通网络后,即得到地理位置语义关联表达的监控场景区间;构建的层次关系和联通关系在用于存储数据的数据模型中通过类对象记录;专题地理位置对象集中的联通关系形成条件约束的联通网络,作为多约束路径规划解析的数据基础。
步骤1.4,计算-描述语义层次分离的地理位置联通逻辑简化:
在地理位置语义关联表达的监控场景区间中,采用计算-描述分层组织方法进行逻辑简化,具体为对于计算与描述分层映射的位置关联表达,其中描述层用于记录和表达完整的位置对象和关系;计算层用于位置关联增强推演计算,将原有不同语义层次的位置节点和联通关系简化为同一语义层次的位置节点和联通关系;
步骤1.5,条件约束的计算层地理位置联通网络简化:
在构建了计算层的位置节点及其联通关系后,根据设置的条件约束信息项以及参数,在计算层提取面向表示几何、语义、拓扑的参数条件约减的地理位置联通网络,得到简化后的地理位置联通网络。
所述运动模式的趋势约束解析,包括以下步骤:
步骤2.1,统一几何形体表达维度和语义概念描述粒度的模型表面剖分:
根据地理场景模型中表面对象的几何形态类型和所关联的最低层次语义粒度特征划分为三种处理类型:关联语义面的网格平面;关联语义面且边界开放的网格曲面;关联语义实体且构成有限封闭空间的网格曲面;
根据上述三种处理类型,对基于多地理视频镜头范围提取的三维建筑物模型,在提取模型构成中关联多层次语义信息的表面对象集后,逐对象剖分多形态类型表面对象为统一几何数据结构、统一表面形态类型和统一基本语义粒度的语义对象集合;
步骤2.2,进行语义关系约束的原子语义位置自动提取与位置边界修正,包括以下子步骤:
步骤2.2a,提取语义对象集合中对象间的语义关系:
提取结构剖分后的表面对象集关联的语义信息,根据语义对象的包含关系在内存中建立语义对象的树形层次结构;判断并分类提取相邻层次语义对象间的语义关系;自底向上依次提取的语义关系包括语义面对象和语义体对象之间的语义组合关系、以及语义体对象之间的语义聚合关系;保存以上提取的语义关系类型作为为步骤2.2b中原子语义位置自动提取所利用的参考信息;
步骤2.2b,基于语义关系解析原子语义位置对象:
利用语义体对象之间的语义聚合关系,逐个提取最低聚合层次的语义实体,得到完整且无重叠地覆盖地理场景模型空间范围的原子语义位置集;
步骤2.3c,修正原子语义位置对象的位置边界:
利用语义面对象和语义体对象之间的语义组合关系,从剖分得到的三角格网化且平面离散化的语义表面对象集中提取每个原子语义位置对象的实体边界,并根据表面特征,进行分类修正;
步骤2.2d,检查并修正原子语义位置的空间覆盖完备性:
基于正则形体边界体素化原子语义实体的空间覆盖范围,根据体素集的空间关系,从以下方案中选择修正操作:
对两两原子语义实体对象,通过体素局部边界收缩消除对象间的空间重叠;
对两两相邻原子语义位置,通过体素局部边界膨胀填充原子语义实体间的空隙。
所述分类修正,包括以下步骤:
①对具有语义聚合关系的两两原子语义位置,通过插入虚拟边修正几何表面间拓扑关系有误的拓扑连接,具体步骤为:
i)提取两两原子语义位置的几何表面集合;
ii)通过图形学多边形矢量求交,依次计算表面集合间两两表面对象的交线段,分别保存交线段到相交表面;
iii)遍历两原子语义实体对象的每个表面,通过图形学中特征约束的三角剖分,以交线段为约束特征,依次进行三角剖分计算,将新插入的交边保存为原子语义位置虚拟边边界;
②对每个原子语义位置,通过插入虚拟面修正几何表面间的开放边界,具体步骤为:
i)提取原子语义位置几何表面集合;
ii)提取每个几何平面的边界轮廓线,保存为线段数组;
iii)遍历每个线段数组,提取只出现一次的线段集合;
iv)在只出现一次的线段集合中搜索封闭多边形,直到集合中所有线段被使用;
v)三角平面化每一个封闭多边形,将三角平面化的多边形网格作为原子语义位置虚拟面边界。
时空距离的代价约束估计,包括以下子步骤:
步骤3.1,从地理视频数据自身特征信息相关性角度,提出如下假设和推论:
假设:特征对象在监控场景的变化过程具有对象自身参数取值的总体连续变化特征;
推论:基于上述假设,某监控盲区中特征对象的行为过程与临接盲区的地理视频镜头中的行为过程具有对象自身参数取值可拟合的相关性特征;
步骤3.2,基于上述推论,当令ob(x)为某盲区行为过程,oob(a),oob(b)分别为临接盲区的地理视频镜头中的行为过程,x表示某个连续过程,a、b表示x所包含并展示在既有视频中行为过程片段,则有:
3)每个行为过程对象描述为:描述对象个体特征的内容语义项cse、描述各状态在统一时空框架基准下地理位置的地理语义项gse、描述行为动作类型的内容语义项csb、和描述统一时空基准下位置关系变化运动模式的地理语义项gsb,则oob(x)和oob(a)和oob(b)分别表达为:
oob(x)={cse(x),gse(x),csb(x),gsb(x)}
oob(a)={cse(a),gse(a),csb(a),gsb(a)}
oob(b)={cse(b),gse(b),csb(b),gsb(b)}
cse(x),gse(x),csb(x),gsb(x)作为盲区行为过程特征参数;
4)根据推论:oob(x)和oob(a)和oob(b)的特征参数基于相关性特征建立函数拟合关系f,从而实现利用已知的oob(a)和oob(b)估计盲区oob(x)的变化特征,形式化表示为:{cse(x),gse(x),csb(x),gsb(x)}=f({cse(a),gse(a),csb(a),gsb(a)},{cse(b),gse(b),csb(b),gsb(b)})
当将上式简化表达为cgeb(x)=f(cgeb(a),cgeb(b)),则利用可解析与建模的行为过程的自身的特征cgeb(a),cgeb(b),与行为过程间的时空距离dmin(oob(a),oob(b)),定义两行为间盲区位置迁移变化最优方案的约束指标coi计算方式如下:
coi(oob(a),oob(b))=f(d(oob(a),oob(b)),cgeb(x))
=f(d(oob(a),oob(b)),f(cgeb(a),cgeb(b))
具体地,在以轨迹数据对象为载体的行为过程表达中,f为参数项d(oob(a),oob(b))和cgeb(a),cgeb(b)的函数运算关系,参数项d(oob(a),oob(b))表达为通过地理视频镜头时空元数据求解的轨迹时空区间间隔;cgeb(a),cgeb(b)则具体表达为行为轨迹的局部方位、转角、速度、加速度各结构特征和结构特征的全局最值、均值、方差统计特征项。
所述多约束监控盲区行为过程推演,包括以下子步骤:
步骤4.1,地理视频镜头语义元数据的轨迹语义表达,执行以下子步骤:
步骤4.1a,轨迹序列点的语义位置定位判别:
结合位置场景中的地理视频镜头语义元数据的离散轨迹,将其映射到统一地理框架划分的专题地理位置对象集合场景中;
步骤4.2b,轨迹数据对象的地理运动模式判别:
以序列点描述的轨迹数据对象为整体,基于监控场景中位置边界修正的各地理位置对象,根据轨迹与位置关系的变化特征,依据设定的运动模式判别规则并以单位置参照模式优先为原则,利用逐行为对象轨迹结构特征项中的局部方位和转角信息项,解析判别其基于地理位置表达的地理语义运动模式;
步骤4.2,盲区移动行为过程的语义路径推演,执行以下子步骤:
步骤4.2a,多层次语义位置及其关联关系的计算层映射:
对于两两相邻地理视频镜头对应的行为轨迹,基于上一步判别的地理语义运动模式,将模式中涉及的地理位置根据计算-描述分层组织方法,统一映射到监控场景中以原子语义位置表达的计算层,并记录映射路径用于在得到估计的轨迹数据对象后还原相应层次的语义路径描述;
步骤4.2b,计算盲区路径规划:
采用顾及约束的估值函数e’(n),通过现有a*算法估值函数e(n)和约束指标coi差值绝对值求解:e’(n)=|e(n)-coi|
n为纵向语义位置层次结构和横向语义位置联通网络中的经由节点,所述节点表示原子语义位置或聚合语义位置;约束指标coi表示根据条件约束信息项中的一种进行约束的指标;
步骤4.2c,盲区轨迹的多层次语义路径表达:
对于解析获取的盲区行为过程的几何轨迹,通过步骤4.1,在多层次地理位置关联表达的监控场景中,以语义位置图的节点和边为参照,描述语义路径;实现盲区变化过程推演。
所述步骤4.2b中,以空间距离为指标,则ogs1和ogs2的coi计算如下:
coi(ogs1,ogs2)=δtmin(ogs1,ogs2)*average(v(ogs1),v(ogs2))
其中,ogs1和ogs2分别为一个地理视频镜头组中两个地理视频镜头语义对象的离散轨迹,地理视频内容中的行为过程参数cgeb(a),cgeb(b)具体表达为轨迹各序列点的速度特征v(ogs1),v(ogs2);同时v(ogs1),v(ogs2)的拟合函数f为均值函数average(a,b);行为过程间的时空条件参数d(ogs1,ogs2)具体表达为轨迹的最小时间差δtmin(ogs1,ogs2);函数运算关系f具体通过数乘*实现。
本发明具有以下有益效果及优点:
1.建立了从“面向单一视频图像空间”到“联合地理视频内外场景空间”的地理视频内容解析机制:突破了传统地理视频内容解析受成像窗口时空的局域性限制,充分利用地理视频内外场景空间的可定位映射关系,实现了结合地理视频内外场景统一的地理视频内容表达与解析机制;该机制建立了地理视频内外场景空间基于统一地理位置的紧密映射,为多地理视频内容中离散行为过程提供了一种全局统一的地理关联基础。
2.建立了从“局部特征相似性约束”到“全局地理相关性约束”的地理视频gis分析机制:突破了传统视频数据基于信号编码相似性、图像特征相似性和内容语义相似性的关联分析受视频成像窗口时空局域性的局限,通过监控场景和地理环境的语义映射,表达出面向地理位置趋势外推的行为过程特征,为离散地理视频内容盲区的变化过程推演提供核心支撑条件,实现了基于地理迁移代价的视频场景相关性可量化解析,支持跨时空区域多地理视频内容的地理相关性与相关过程分析,在地理视频关联关系的基础上增强了地理视频的关联语义,提高了地理视频数据的知识表征能力。
附图说明
图1本发明方法原理示意图;
图2本发明方法步骤流程图;
图3本发明方法实施例处理过程示意图。
具体实施方式
下面结合附图及实施例对本发明做进一步的详细说明。
本发明涉及一种地理语义关联约束的多相机视频事件信息盲区变化过程推演方法,属于地理空间数据处理技术领域,技术方案包括以下步骤:a)面向地理位置构建多地理视频间约束推演的地理环境条件约束推演的地理环境条件约束,通过提取增强的语义地理位置的纵向层次结构和横向拓扑网络,实现监控场景区间统一定位划分基准下的地理位置语义关联表达;b)构建面向运动模式的推演趋势约束,在增强待分析监控场景区域的地理位置定位判断特征的基础上,利用局域地理视频内容中行为过程片段的轨迹结构特征,基于轨迹与地理位置的关系变化特征,判别逐行为过程的地理运动模式;c)利用轨迹的统计特征,在有序组织的地理视频镜头组间,通过逐相邻行为过程的轨迹对分析行为过程间信息盲区的行为运动特征,建立映射时空距离迁移代价的盲区行为过程特征参数;d)通过联合地理位置场景、地理运动模式和时空距离约束的监控盲区地理实体语义路径规划,实现盲区行为过程推演,并将推演的语义路径保存为地理视频镜头组关联语义增强的元数据。本发明的核心是基于地理视频内外场景空间的可定位映射关系,结合外部场景地理空间信息统一基准的gis建模表达,实现视频内容离散变化过程地理相关的开放式规则描述;进而基于变化过程的地理环境依赖性,利用gis分析方法完成离散变化过程盲区信息的地理约束推演,实现面向监控区域连续变化过程的地理语义增强,支持不同层次中完整事件变化过程信息的理解。
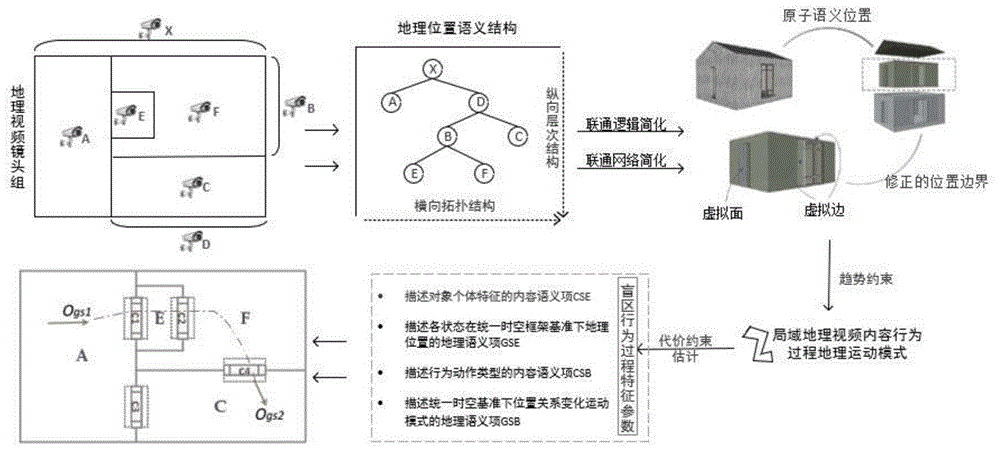
如图1所示,地理视频镜头组采集视频图像,首先获取监控区域地理视频镜头组区域的专题语义信息,解析其中的地理位置语义,提取地理位置对象和对象关系;其次构建镜头组区域的纵向位置层次结构和横向位置拓扑网络;然后提取完整表达复杂三维建筑物模型且正则形体化的位置边界特征用于基于位置特征的运动模式判别;再则利用区域地理视频内容行为过程的运动轨迹特征通过逐相邻行为过程的轨迹对分析行为过程间信息盲区的行为运动特征,建立映射时空距离迁移代价的盲区行为过程特征参数。最终利用离散轨迹ogs1和ogs2的运动轨迹模式和基于时空距离和轨迹特征定量求解的最优路径判别指标进行监控盲区内的枯井推演。
如图1、图2所示,本发明包括以下步骤:
步骤1,地理位置的条件约束构建:获取监控区域专题语义信息,解析其中的地理位置语义,提取地理位置对象和对象关系;面向位置关系构建纵向位置层次结构和横向位置拓扑网络,表达监控场景区间统一定位区间划分下的地理位置语义关联。
步骤2,运动模式的趋势约束解析:在统一模型构成元素几何形体表达维度和语义概念描述粒度的基础上,分类归纳、解析并充分利用模型中的特征语义关系,提取完整表达复杂三维建筑物模型且正则形体化的位置边界特征用于基于位置特征的运动模式判别。
步骤3,时空距离的代价约束估计:利用轨迹的统计特征,在有序组织的地理视频镜头组间,通过逐相邻行为过程的轨迹对分析行为过程间信息盲区的行为运动特征,建立映射时空距离迁移代价的盲区行为过程特征参数。
步骤4,多约束监控盲区行为过程推演:联合场景的地理位置关系网、视屏内容中行为过程的地理运动模式,以及基于时空距离和轨迹特征定量求解的最优路径判别指标,提出监控盲区地理实体移动行为过程语义路径推演方法,增强实现地理视频镜头组语义元数据中监控盲区的关联语义增强。
而且,所述步骤1中,地理位置的条件约束构建包括以下子步骤:
步骤1.1,提取监控场景区域的专题地理位置对象集。数字地球研究背景下日益丰富和完善的地理空间信息基础框架建设,为丰富地理位置信息的获取和解析提供了数据基础。现有各相关领域的多种主题数据库均可以作为地理位置对象的信息源,其中可服务于公共安全监控需求的室内外位置信息源主要包括以下三类:
①类型一:警用数据管理与服务领域的地名库、地址库等基础地理信息数据;其中的位置概念以国家标准地名为依据,按照一定分层、分段、分级规律,包含行政区划、街道、门牌(小区、建筑物)、单元室号、所在邮编、所在段道号以及小区、楼房的性质、类型等最基本的地址信息;
②类型二:交通管理领域的各级道路网模型数据;其中,现有主要使用的网路网络模型包括:(a)面向二维导航基于几何-拓扑双层特征结构的道路网络模型;(b)面向车道几何及车道横向与纵向连通性的车道模型;以及(c)面向多尺度位置参考包含几何、拓扑、属性数据的三维道路网络模型;
③类型三:智慧城市领域的基础三维城市语义模型数据;其中,主要使用的语义规范包括:开放地理空间信息联盟(opengisconsortium,ogc)建模标准(a)城市地理标识语言ogccitygml,和(b)室内多维位置信息标识语言ogcindoorgml;以及(c)建筑信息模型(buildinginformationmodeling,bim)领域广泛使用的ifc数据模型标准等国际建模标准规范。
基于以上地理空间信息主题数据集,地理视频相关的专题位置信息提取具体可通过以下方法流程实现:首先,面向事件聚类层次中的地理视频镜头组,提取各地理视频镜头包含的地理视频帧对象增强的元数据信息,具体通过元数据中的成像特征项获取三维监控场景成像区间集;然后,基于成像区间集的整体空间区域,计算能完整覆盖多地理视频内容中离散变化过程的监控场景区间,作为统一基准的地理位置基本表达范围;之后,利用上述区间范围作为空间检索条件,从现有主题数据库中获取专题位置信息,包括位置相关的几何、拓扑、语义、属性及功能等信息的详尽描述,保存每个位置概念为一个地理位置对象,在数据模型中通过类对象表达。
步骤1.2,构建纵向语义位置层次结构。在提取了监控场景区间的专题地理位置对象集之后,可根据集合中位置对象几何要素的空间包含关系,构建位置对象纵向“父位置—子位置”逐层嵌套的层次结构。对层次组织的地理位置对象,逐对象检查其区域内基于统一的定位空间划分的位置名称表达:保证局域内位置对象名称规范性与唯一性;将规范表达的位置名称作为描述位置概念和使用位置对象的唯一标识码。
步骤1.3,构建横向语义位置联通网络。在构建了纵向语义位置层次结构的基础上,利用与位置对象同步提取的对象间拓扑、语义、属性及功能关系(例如会议室的开放特征为建立语义条件提供支持)信息,以“位置语义联通关系”的定义为依据,判别两两位置间支持特征对象迁移的以位置接口为条件载体的联通性,其中,特征对象的行为量化为轨迹表达;保存支持位置间联通性的各项条件为条件约束的位置联通关系;其中,条件约束信息项划分并保存为“空间约束(t)”、“时间约束(s)”和“功能属性约束(a)”三类,作为具体构建联通网络时各联通关系查询接口条件。
在通过提取基于统一定位空间划分的地理位置对象,并构建位置对象间纵向层次结构和横向联通网络构建后,即得到地理位置语义关联表达的监控场景区间。构建的层次关系和联通关系在数据模型中通过类对象记录。位置集合中的联通关系形成条件约束的联通网络,作为多约束路径规划解析的数据基础。
步骤1.4,计算-描述语义层次分离的地理位置联通逻辑简化。为了在兼顾监控场景行为过程地理运动模式对多层次位置概念及其多层次联通关系的表达需要的同时,简化监控场景中服务于高性能联通路径分析计算的地理位置的语义联通网,提出计算与描述分层映射的位置关联表达结构。计算与描述分层映射的位置关联表达在保留对基于多层次位置概念运动模式描述适应性的同时,将纵向语义位置层次结构和横向语义位置联通网络中原有不同语义层次的位置节点和纵向层次结构中叶子节点的联通关系简化为同一语义层次的位置节点和联通关系,该分层形式在有助于简化用于路径分析计算的位置概念间逻辑关系的复杂性从而实现计算信息的降维。
步骤1.5,条件约束的计算层地理位置联通网络简化。在构建了计算层的位置及其联通关系后,可进一步根据设置的“空间约束(t)”、“时间约束(s)”和“功能属性约束(a)”三类联通条件,通过设置具体的条件参数,在计算层进一步提取面向特定参数条件约减的地理位置联通网络,其中,参数条件指几何、语义、拓扑条件,如:大门几点到几点关闭,那这段时间内的这个通路就可以约减掉。不同的理视频镜头数据内容中的行为实例对应了不同条件参数组,因此可得到不同的约减结果。
经过上述处理流程构建的地理位置关联表达能支持基于位置的视频内容离散变化过程联合地理监控场景的开放式描述,为利用gis方法求解监控盲区事件信息提供基于地理位置的基础条件约束信息。
而且,所述步骤2中,运动模式的趋势约束解析包括以下子步骤:
步骤2.1,统一几何形体表达维度和语义概念描述粒度的模型表面剖分。
构成一个复杂三维建筑物模型的基本几何要素可抽象为由以下三类几何对象混合表达的多表面形态类型:①独立平面,②边界开放的规则网格曲面,和③构成有限封闭空间正则几何形体且可参数化的网格曲面。
同时,可将在现有描述室内精细场景的三维建筑模型的主流行业标准ifc、indoorgml和citygml中的语义对象根据其语义描述粒度划分为:①语义面对象,②语义体对象两大类;其中,语义体对象是模型中构成场景中地理位置概念的语义粒度。进一步地,根据与语义面对象的直接构成关系可将语义体对象划分为:①占据连续几何空间且在语义概念上不能再细分的语义体对象,称之为“原子语义位置”对象,和②由原子语义体对象组合构成的语义体对象,称之为“聚合语义位置”对象;其中“原子语义体”对象是本方法引入虚拟边界进行位置边界自动完备化修正处理的位置语义粒度。
基于以上几何与语义要素的类型划分,根据模型中表面对象的几何形态类型和所关联的最低层次语义粒度特征划分为三种处理类型:
①关联语义面的网格平面;
②关联语义面且边界开放的网格曲面;
③关联语义实体且构成有限封闭空间的网格曲面;
统一几何形体表达维度和语义概念描述粒度的模型表面剖分,即分别根据上述三种处理类型,对基于多地理视频镜头范围提取的复杂三维建筑物模型,在提取模型构成中关联多层次语义信息的表面对象集后;逐对象剖分多形态类型表面对象为统一几何数据结构、统一表面形态类型和统一基本语义粒度的语义对象集合。
步骤2.2,语义关系约束的原子语义位置自动提取与位置边界修正包括以下子步骤:
步骤2.2a,提取对象间的语义关系。提取结构剖分后的表面对象集关联的语义信息,根据语义对象的包含关系在内存中建立语义对象的树形层次结构。具体通过判断并分类提取相邻层次语义对象间的语义关系;自底向上依次提取的语义关系包括“语义面对象和语义体对象之间的语义组合关系”以及“语义体对象之间的语义聚合关系”。保存语义关系类型原子语义位置自动提取利用的参考信息。
步骤2.2b,基于语义关系解析原子语义位置对象。具体利用“语义体对象之间的语义聚合关系”,逐个提取最低聚合层次的语义实体,得到完整且无重叠地覆盖原模型空间范围的“原子语义位置集”。
步骤2.3c,修正原子语义位置对象的位置边界。具体首先利用“语义面对象和语义体对象之间的语义组合关系”,从剖分得到的三角格网化且平面离散化的语义表面对象集中提取每个原子语义位置对象的“实体边界”。并根据表面特征,进行分类修正:
①对具有语义聚合关系的两两原子语义位置,通过插入“虚拟边”修正几何表面间不完备(几何上的拓扑关系错漏)的拓扑连接,具体步骤为:
i)提取两两原子语义位置的几何表面集合;
ii)采用图形学多边形矢量求交通用技术的一种或多种组合,依次计算表面集合间两两表面对象的交线段,分别保存交线段到相交表面;
iii)遍历两原子语义实体对象的每个表面,采用图形学中特征约束的三角剖分通用技术的一种或多种组合,以交线段为约束特征,依次进行三角剖分计算,将新插入的交边保存为原子语义位置“虚拟边”边界。
②对每个原子语义位置,通过插入“虚拟面”修正几何表面间的开放边界,具体步骤为:
i)提取原子语义位置几何表面集合;
ii)提取每个几何平面的边界轮廓线,保存为线段数组;
iii)遍历每个线段数组,提取只出现一次的线段集合;
iv)在只出现一次的线段集合中搜索封闭多边形,直到集合中所有线段被使用;
v)三角平面化每一个封闭多边形,将三角平面化的多边形网格作为原子语义位置“虚拟面”边界。
步骤2.2d,检查并修正原子语义位置的空间覆盖完备性。基于正则形体边界体素化原子语义实体的空间覆盖范围,根据体素集的空间关系,从以下方案中选择具体的修正操作:
①对两两原子语义实体对象,通过体素局部边界收缩消除对象间的空间重叠;
②对两两相邻原子语义位置,通过体素局部边界膨胀填充原子语义实体间的空隙。
基于上述处理流程,可得到修正边界的各地理位置对象。并根据基于增强位置特征的轨迹运动模式判别原则,以位置边界、基于位置变化划分的位置内外空间和求解的定位点、以及依附位置边界的位置接口为增强的位置特征,依据单位置参照模式优先的原则,根据逐行为对象轨迹结构特征项中的“局部方位”和“转角”信息,解析判别其基于地理位置表达的地理语义运动模式。由于地理语义运动模式的描述形式突破了地理视频成像时空窗口内容信息的局限,且表达出面向地理位置趋势外推的行为过程特征,因而形成对盲区移动行为推演的趋势约束作用。
而且,所述步骤3中,时空距离的代价约束估计包括以下子步骤:
步骤3.1,从地理视频数据自身特征信息相关性角度,提出如下假设和推论:
假设:特征对象在监控场景的变化过程具有各参数(对象自身参数,如人就是移动速度等)取值的总体平稳连续变化特征;
推论:基于上述假设,某监控盲区中特征对象的行为过程与临接盲区的地理视频镜头中的行为过程具有参数取值可拟合的相关性特征。
步骤3.2,基于上述推论,当令ob(x)为某盲区行为过程,oob(a),oob(a)分别为临接盲区的地理视频镜头中的行为过程,则有:
1)根据地理视频内容变化特征的语义元数据参数分类表达(详见3.4.3节):每个行为过程对象可描述为由:①描述“对象个体特征”的内容语义项(cse);②描述各状态在统一时空框架基准下“地理位置”的地理语义项(gse);③描述行为动作类型的内容语义项(csb);和④描述统一时空基准下位置关系变化运动模式的地理语义项(gsb),则oob(x)和oob(a)和oob(b)可分别表达为:
oob(x)={cse(x),gse(x),csb(x),gsb(x)}
oob(a)={cse(a),gse(a),csb(a),gsb(a)}
oob(b)={cse(b),gse(b),csb(b),gsb(b)}
2)根据推论:oob(x)和oob(a)和oob(b)的特征参数可基于相关性特征建立函数拟合关系f,从而实现利用已知的oob(a)和oob(b)估计盲区oob(x)的变化特征,形式化表示为:{cse(x),gse(x),csb(x),gsb(x)}=
f({cse(a),gse(a),csb(a),gsb(a)},{cse(b),gse(b),csb(b),gsb(b)})
当将上式简化表达为cgeb(x)=f(cgeb(a),cgeb(b)),则利用可解析与建模的①行为过程的自身的特征cgeb(a),cgeb(b),与②行为过程间的时空距离dmin(oob(a),oob(b)),可定义两行为间盲区位置迁移变化最优方案的约束指标(constrainedoptimalindex,coi)计算方式如下:
coi(oob(a),oob(b))=f(d(oob(a),oob(b)),cgeb(x))
=f(d(oob(a),oob(b)),f(cgeb(a),cgeb(b))
具体地,在以轨迹数据对象为载体的行为过程表达中,f为参数项d(oob(a),oob(b))和cgeb(a),cgeb(b)的函数运算关系,参数项d(oob(a),oob(b))具体表达为通过地理视频镜头时空元数据求解的轨迹时空区间间隔;cgeb(a),cgeb(b)则具体表达为行为轨迹的局部方位、转角、速度、加速度等各结构特征和结构特征的全局最值、均值、方差统计特征项。
而且,所述步骤4中,多约束监控盲区行为过程推演包括以下子步骤:
步骤4.1,地理视频镜头语义元数据的轨迹语义表达,执行以下子步骤:
步骤4.1a,轨迹序列点的语义位置定位判别。结合位置场景中的地理视频镜头语义元数据的示意性离散轨迹,将其映射到统一地理框架划分的地理位置集合场景中。
步骤4.2b,轨迹数据对象的地理运动模式判别。以序列点描述的轨迹数据对象为整体,基于监控场景中位置边界修正的各地理位置对象,根据轨迹与位置关系的变化特征,依据运动模式判别规则并以单位置参照模式优先为原则,利用逐行为对象轨迹结构特征项中的“局部方位”和“转角”信息项,解析判别其基于地理位置表达的地理语义运动模式。基于监控场景地理位置网络开放式表达的地理语义运动模式描述形式突破了地理视频成像时空窗口内容信息的局限,因而表达出轨迹对象面向地理位置趋势外推的行为过程特征,形成对盲区移动行为推演的趋势约束作用。
步骤4.2,盲区移动行为过程的语义路径推演,执行以下子步骤:
步骤4.2a,多层次语义位置及其关联关系的计算层映射。对于两两相邻地理视频镜头对应的行为轨迹,基于上一步判别的地理运动模式:将模式中涉及的地理位置根据计算-描述分层组织方法,统一映射到监控场景中以原子地理位置表达的计算层,并记录映射路径用于在得到估计的轨迹数据对象后还原相应层次的语义路径描述。
步骤4.2b,计算盲区路径规划。本发明基于面向静态网络求解的a*算法实现盲区几何路径规划,在现有a*算法估值函数选取的基础上,顾及本发明所定义的最优方案约束指标coi的参数影响;当前现有a*算法估值函数表达为e(n),n为网络中的经由节点时,方法采用顾及约束的估值函数e’(n),取代原算法函数e(n)执行最优路径求解,e’(n)通过e(n)和约束指标coi差值绝对值求解,函数表示为:
e’(n)=|e(n)-coi|
如示例中,以空间距离为指标,则ogs1和ogs2的coi计算可具体实例化为:
coi(ogs1,ogs2)=δtmin(ogs1,ogs2)*average(v(ogs1),v(ogs2))
其中,地理视频内容中的行为过程参数cgeb(a),cgeb(b)具体表达为轨迹各序列点的速度特征v(ogs1),v(ogs2);同时v(ogs1),v(ogs2)的拟合函数f简单具体化为均值函数average(a,b);行为过程间的时空条件参数d(ogs1,ogs2)具体表达为轨迹的最小时间差δtmin(ogs1,ogs2);函数运算关系f具体通过数乘*实现。该组示例化参数为以空间距离为指标的一组可行的参数,当需要更高精度轨迹表达时,可通过进一步改进函数f和f实现。
如图3所示,对左侧离散轨迹示意性示例进行地理语义关联约束的多视频事件盲区变化过程推演得到右侧监控场景的盲区轨迹。
步骤4.2c,盲区轨迹的多层次语义路径表达。对于解析获取的盲区行为过程的几何轨迹,利用上文“地理视频镜头语义元数据的轨迹语义表达”方法,在多层次地理位置关联表达的监控场景中,以语义位置图的节点和边为参照,描述语义路径;特别地,为了支持对地理视频内容和盲区连续行为过程的语义理解,对盲区的语义表达需满足和地理视频镜头语义元数据的轨迹语义在地理位置上的逻辑衔接。最后,保存可解析的多层次语义路径为相应地理视频镜头组关联语义增强的语义元数据。
- 还没有人留言评论。精彩留言会获得点赞!