一种高铁全网络站点延误传播的识别方法、设备及介质与流程
本发明属于交通技术领域,具体涉及一种基于贝叶斯网络的高铁全网络站点延误传播的识别方法、设备及介质。
背景技术:
高速列车作为一种中长距离的出行方式,具有速度快、安全性高、正点率高、能耗小、运输能力大等优点。但是高速列车在实际运营的过程中,受到多种因素(极端天气、设备故障、交通事故、运营管理不当等)的影响,经常发生列车到站延误事件。高速列车发生延误不仅会打乱列车运行计划,影响高速列车到站的运营管理;而且会使乘客的出行受到影响,降低乘客的乘车舒适度。研究理解高速列车延误传播机理,识别高速列车在站点间的延误传播,对管理者制定列车运行计划,提高车站的运营管理水平具有十分重要的现实意义。但是,现有识别高速列车在站点间的延误传播的方法存在以下问题:
(1)通过专家的领域知识手动建立高速列车在站点间的延误传播关系不具备客观性,且此方法只能识别两个站点之间是否具有传播关系,难以获得站点间延误传播的强弱关系。
(2)现在只具有识别某条高铁单线的延误传播关系的方法,但是识别高铁单线站点之间的延误传播关系的方法并不能识别延误在整个网络中的传播情况,因为整个高铁网络的延误传播较某条高铁单线的延误传播更为复杂。
综上所述,现在识别高铁全网络站点延误传播的方法仍有不足,因为高铁网络规模巨大,结构复杂,如果采用上述方法,很难有效识别高铁全网络的站点延误传播。为了更好的理解高速列车在延误传播机理,制定列车到站计划,提高车站的运营管理水平,迫切需要一种基于贝叶斯网络的高铁全网络站点延误传播的识别方法。
技术实现要素:
本发明解决的技术问题是,针对现有技术的不足,提供了一种基于贝叶斯网络的高铁全网络站点延误传播的识别方法、设备及介质,通过采取数据驱动的方式,有效地识别所发生的站点延误在高铁全网络中传播情况,具有较高的精度和广度,适用于列车延误传播和预测研究,有利于后续列车到站计划的制定与调整。
为了实现上述技术目的,本发明提供的技术方案为:
一种基于贝叶斯网络的高铁全网络站点延误传播的识别方法,包括:
步骤1,将高铁历史每天的运行时段平均划分为若干时间窗;
步骤2,根据高铁列车的历史运行情况,计算高铁全网络的每个站点在每个时间窗内所有延误列车的平均延误时长;
步骤3,根据高铁全网列车时刻表中每两个站点之间的运行时长,确定贝叶斯网络的候选边;
步骤4,基于步骤2得到的平均延误时长和步骤3得到的候选边,使用notears算法构建初始的高铁全网络站点延误传播贝叶斯网络结构;
步骤5,对初始的高铁全网络站点延误传播贝叶斯网络结构,删除其中边权重小于预设权重阈值的边,得到最终的高铁全网络站点延误传播贝叶斯网络结构;
步骤6,当高铁全网络的某个站点发生延误时,根据最终的高铁全网络站点延误传播贝叶斯网络结构,判断高铁全网络中受到该延误站点影响的站点以及影响强度。。
进一步的,所述步骤2的具体步骤为:
步骤2.1,将每个延误列车分配至对应的站点和时间窗内;
步骤2.2,通过以下公式计算每个站点分别在每个时间窗内所有延误列车的平均延误时长:
其中,tij为i站点在j时间窗的所有延误列车的平均延误时长,nij为i站点在j时间窗的所有延误列车数量,
进一步的,所述步骤3的具体步骤为:
步骤3.1,在高铁全网列车时刻表中,查找任意两个站点之间是否有列车运行:如果有,按照步骤3.2进行判断;如果没有,则该两个站点相连接的边不能成为候选边;
步骤3.2,选择该两个站点之间列车运行时间最短的时长:如果该时长小于时间窗的时长,则该两个站点相连接的边可以成为候选边;否则,该两个站点相连接的边不能成为候选边。
进一步的,所述步骤4的具体步骤为:
步骤4.1,初始化贝叶斯网络的网络结构:将每一个站点作为贝叶斯网络的节点,以步骤3得到的候选边作为贝叶斯网络的候选边;
步骤4.2,将步骤2得到的平均延误时长,整理为m行n列的站点平均延误时长矩阵,其中每行对应一个时间窗,每列对应一个站点;
步骤4.3,根据站点平均延误时长矩阵和初始化得到的贝叶斯网络的网络结构,采用notears算法进行贝叶斯网络结构学习,得到初始的高铁全网络站点延误传播贝叶斯网络结构。
进一步的,步骤5中的预设权重阈值,设置为初始的高铁全网络站点延误传播贝叶斯网络结构中渗流相变点对应的权重值。
进一步的,每个时间窗的时长为1h。
本发明还提供一种电子设备,包括存储器及处理器,所述存储器中存储有计算机程序,其特征在于,所述计算机程序被所述处理器执行时,使得所述处理器实现上述任一项所述的方法。
本发明还提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述任一项所述的方法。
有益效果
本发明通过构建高铁全网络站点延误传播贝叶斯网络,当某一站点的高速列车发生延误时,即可得知因此站点延误导致其他发生延误的站点,从而提前通知相关高铁站点的乘客和工作人员做好准备,通过车站站内即将到站的列车进行调度调整,可以对未发生延误的列车降低列车发生延误的概率,对已经发生延误的列车降低列车延误时长,同时可以为高速列车运行图的制定与调整提供参考。根据高铁全网络站点延误传播贝叶斯网络,可以判断某个站点的高速列车延误之后,通过网络中边的权重判断网络中其他站点受到延误影响的强度,进而关注网络中影响其他站点的关键车站以及受到较大延误影响的站点。这对于整个高速列车网络的站点拓扑关系的改进有着重大的指引意义。
本发明和现有技术相比,有以下优点:
(1)传统通过专家的领域知识手动建立高速列车在站点间的延误传播关系不具备客观性,且传统方法只能识别两个站点之间是否具有传播关系,难以获得站点间延误传播的强弱关系。本发明方法通过数据驱动的方式,更能精准反应网络中延误传播的实际情况,且可以识别受到延误传播重大影响的车站。
(2)本方法通过notears算法构建得到高铁全网络站点延误传播贝叶斯网络,解决了以往只能识别高铁单线站点之间的延误传播关系而不能识别大型综合网络中站点之间的延误传播关系的问题,为研究全网络的延误传播以及延误预测提供指导意义。
附图说明
图1为本发明实施例所述方法的流程图;
图2为本发明实施例所运用的高铁站点地理位置示意图;
图3为本发明实施例采用渗流相变点预设权重阈值时,最大团簇和第二大团簇大小随权重阈值的变化图;
图4为本发明实施例最终的高铁全网络站点延误传播贝叶斯网络。
具体实施方式
本实施例以本发明的技术方案为依据开展,给出了详细的实施方式和具体的操作过程,对本发明的技术方案作进一步解释说明。
实施例1:
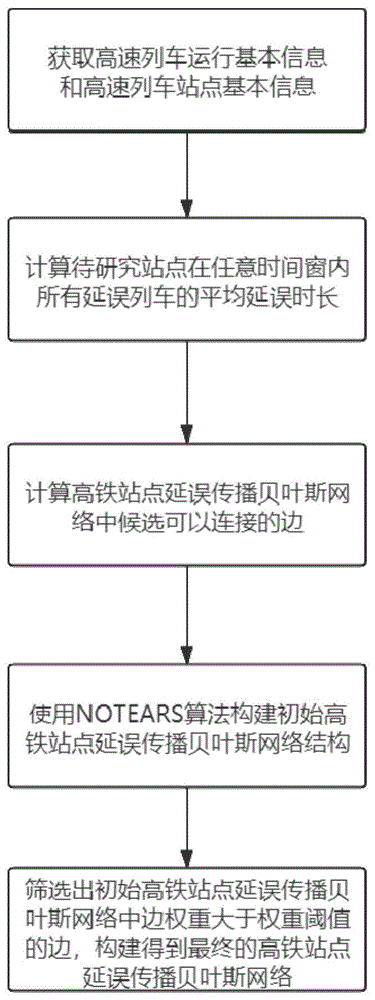
本实施例提供一种基于贝叶斯网络的高铁全网络站点延误传播的识别方法,如图1所示,包括:
步骤0,获取高速列车运行基本信息和高速列车站点基本信息;
本实施例采集的高速列车运行基本信息包括列车时刻表信息和列车运行实绩数据信息,采集的时间段为2018年1月20日至3月20日。高速列车站点基本信息包括高速列车站点名信息和高速列车站点经纬度信息。其中,高铁列车运行时刻表信息在中国铁路总公司12306官方网站上获得,列车时刻表中记录了4079辆开行的高速列车;列车运行实绩数据信息来源于我们使用python开发的爬虫工具对中国铁路总公司12306官方网站公布的列车实时到站情况,包含了高速列车车次、到达站、图定到站时间、实际到站时间、延误时长、日期等信息;高速列车站点基本信息数据来源于腾讯地图,其中包括站点名和站点经纬度信息,除去有数据缺失的高铁站点,一共有562个高铁站点,如图2所示。
步骤1,将高铁一天的运行时段平均划分为若干时间窗;
本实施例中,基于中国高速列车一天主要运行时段6:00-24:00,将18个小时分割为18个时间间隔为1h的时间窗。本实施例的历史运行时段包括2018年1月20日至3月20日共60天,共有1080个时间窗。
步骤2,根据高铁列车的历史运行情况,计算高铁全网络的每个站点分别在每个时间窗内所有延误列车的平均延误时长;具体步骤为:
步骤2.1,将每个延误列车分配至对应的站点和时间窗内;
步骤2.2,通过以下公式计算每个站点分别在每个时间窗内所有延误列车的平均延误时长:
其中,tij为i站点在j时间窗的所有延误列车的平均延误时长,nij为i站点在j时间窗的所有延误列车数量,
步骤3,根据高铁全网列车时刻表中每两个站点之间的运行时长,确定高铁全网络站点延误传播贝叶斯网络的候选边;具体步骤为:
步骤3.1,在高铁全网列车时刻表中,查找任意两个站点之间是否有列车运行:如果有,按照步骤3.2进行判断;如果没有,则该两个站点相连接的边不能成为候选边;
步骤3.2,选择该两个站点之间列车运行时间最短的时长:如果该时长小于时间窗的时长,则该两个站点相连接的边可以成为候选边;否则,该两个站点相连接的边不能成为候选边。
步骤4,基于步骤2得到的平均延误时长和步骤3得到的候选边,使用notears算法构建初始的高铁全网络站点延误传播贝叶斯网络结构;具体步骤为:
步骤4.1,初始化贝叶斯网络的网络结构:将每一个站点作为贝叶斯网络的节点,以步骤3得到的候选边作为贝叶斯网络的候选边;
步骤4.2,将步骤2得到的平均延误时长,整理为m行n列的站点平均延误时长矩阵,其中每行对应一个时间窗,每列对应一个站点;
步骤4.3,根据站点平均延误时长矩阵和初始化得到的贝叶斯网络的网络结构,采用notears算法进行贝叶斯网络结构学习,得到初始的高铁全网络站点延误传播贝叶斯网络结构。本实施例中,初始高铁全网络站点延误传播贝叶斯网络中共有548个节点,1168条边。
步骤5,对初始的高铁全网络站点延误传播贝叶斯网络结构,删除其中边权重小于预设权重阈值的边,得到最终的高铁全网络站点延误传播贝叶斯网络结构;
其中的预设权重阈值,设置为初始的高铁全网络站点延误传播贝叶斯网络结构中渗流相变点对应的权重值(相变点,是指初始的高铁全网络站点延误传播贝叶斯网络发生相变的临界点,代表着网络前后不同状态的临界点,且相变点位置的确定是通过绘制图3所示的最大团簇和第二大团簇随权重的变化规律而得到的,相变点对应的权重值为第二大团簇有最大的大小时(纵坐标的值最大)所对应的权重)。本实施例最后得到具有472个节点,463条边的网络结构,如图4所示。初始的高铁全网络站点延误传播贝叶斯网络结构中,每条边都有对应的权重大小,权重越大的边对网络来说就越重要。如果不断调整权重阈值,在网络中留下大于权重阈值的边,网络中存在的边会越来越少,同时网络也因此而瓦解,瓜分为了多个团簇。本实施例中渗流概念中相变点的确定,是根据图3中第二大团簇中团簇最大时进行确定。
步骤6,当高铁全网络的某个站点发生延误时,根据最终的高铁全网络站点延误传播贝叶斯网络结构,判断高铁全网络中受到该延误站点影响的站点以及影响强度。
实施例2:
本实施例提供一种电子设备,包括存储器及处理器,所述存储器中存储有计算机程序,其特征在于,所述计算机程序被所述处理器执行时,使得所述处理器实现实施例1所述的方法。
实施例3:
本实施例提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现实施例1所述的方法。
以上实施例为本申请的优选实施例,本领域的普通技术人员还可以在此基础上进行各种变换或改进,在不脱离本申请总的构思的前提下,这些变换或改进都应当属于本申请要求保护的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!