一种基于跨域光谱信息的农产品品质无损检测方法及可泛化系统
1.本发明涉及光谱分析技术领域,特别是一种基于跨域光谱信息的农产品品质无损检测方法及可泛化系统。
背景技术:
2.在农产品加工过程中,农产品品质在实时变化,不同工序的工艺参数必须与农产品品质相匹配,这样才能保证最后农产品的质量。光谱技术由于其快速、无损等特点,在农产品品质无损检测中被普遍应用。
3.由于仪器的差异、周围环境的影响和样品本身品质的差异,不同批次农产品的光谱数据建立的多元校正模型,在另一批次的样本下预测结果会发生较大的偏差,甚至会出现校正模型完全不适用的情况,很难实现跨域光谱信息的回归建模与预测分析,模型没有泛化性。传统的跨域光谱分析方法能够解决不同仪器间的模型传递,不过还需要不同仪器的标准化样品进行校正;并且传统的跨域光谱分析方法目前没有能够有效解决不同批次和不同环境条件下数据分布差异问题的方法,另外目前已有的光谱回归模型缺少泛化性。
技术实现要素:
4.有鉴于此,本发明的目的是提出一种基于跨域光谱信息的农产品品质无损检测方法及可泛化系统,同时提升了模型在源域和目标域数据上的泛化性能,较大幅度提升了模型的预测准确率。
5.本发明采用以下方案实现:一种基于跨域光谱信息的农产品品质无损检测方法,具体包括以下步骤:
6.获取源域光谱数据与目标域光谱数据,并构建训练数据集;
7.构建aug
‑
tradaboost.r2模型,所述aug
‑
tradaboost.r2模型包括三个子模型,分别为回归预测模型、源域结果校正模型以及目标域结果校正模型;
8.训练所述aug
‑
tradaboost.r2模型,并利用训练好的模型对源域光谱数据与目标域光谱数据进行预测。
9.进一步地,还包括步骤:对所述源域光谱数据与目标域光谱数据进行预处理。
10.进一步地,所述预处理包括平滑处理、多元散射校正处理、标准正态变量处理、去趋势处理、标准化处理、基线偏移处理、二阶或一阶求导处理中的任意一种或多种的组合。
11.进一步地,所述训练所述aug
‑
tradaboost.r2模型具体包括以下步骤:
12.首先对回归预测模型基于全部训练数据进行训练建模;
13.将训练数据集中的源域光谱数据x
source_train
输入回归预测模型,得到对应的源域光谱数据的品质参数预测值y’source_train
,将y’source_train
作为自变量,将x
source_train
对应的真值标签y
source_train
作为因变量,带入源域结果校正模型进行训练建模;
14.将训练数据集中的目标域光谱数据x
target_train
输入回归预测模型,得到对应的目
标域光谱数据的品质参数预测值y’target_train
,将y’target_train
作为自变量,将x
target_train
对应的真值标签y
target_train
作为因变量,带入目标域结果校正模型进行训练建模。
15.进一步地,所述利用训练好的模型对源域光谱数据与目标域光谱数据进行预测具体为:
16.若输入的数据为源域光谱数据,则将源域光谱数据x
source_test
输入回归预测模型,得到的对应x
source_test
的结果y’source_test
,将y’source_test
输入源域结果校正模型,最终得到预测值输出y
source_test_predicted
;
17.若样本为目标域数据,则将光谱数据x
target_test
输入回归预测模型,得到对应x
target_test
的结果y’target_test
,将y’target_test
输入目标域结果校正模型,最终得到预测值输出y
target_test_predicted
。
18.进一步地,所述回归预测模型采用两阶段的tradaboost.r2。
19.进一步地,所述源域结果校正模型为线性回归、岭回归、拉索回归、偏最小二乘回归、决策树回归、k近邻回归、神经网络中的任意一种。
20.进一步地,所述目标域结果校正模型为线性回归、岭回归、拉索回归、偏最小二乘回归、决策树回归、k近邻回归、神经网络中的任意一种。
21.进一步地,所述光谱数据为近红外光谱、中红外光谱、拉曼光谱、及紫外
‑
可见光谱中的任意一种。
22.本发明还提供了一种基于跨域光谱信息的农产品品质无损检测可泛化系统,包括存储器、处理器以及存储在存储器上并能够被处理器运行的计算机程序指令,当处理器运行该计算机程序指令时,实现如上文所述的方法步骤。
23.与现有技术相比,本发明有以下有益效果:本发明通过将结果校正的思想与模型集成的方法相结合,来创新传统的迁移学习模型,原创地提出了基于跨域光谱信息的农产品品质无损检测可泛化模型aug
‑
tradaboost.r2;该模型在光谱建模领域有很强的适应性,并且在农产品光谱分析领域,将跨域光谱建模的前提从跨设备(ds算法等)拓展到了跨检测环境、跨农产品批次、跨农产品品种与跨农产品类别,实现了不同数据分布的农产品光谱数据之间的跨域联合建模,在源域和目标域都达到较高的预测准确率。
附图说明
24.图1为本发明实施例的aug
‑
tradaboost.r2模型训练建模示意图。
25.图2为本发明实施例的aug
‑
tradaboost.r2模型预测推理示意图。
26.图3为本发明实施例的aug
‑
tradaboost.r2与传统跨域分析方法s/b算法(模型传递方法的一种)通过绿茶数据集建模预测红茶数据集的预测值与实测值比较。
具体实施方式
27.下面结合附图及实施例对本发明做进一步说明。
28.应该指出,以下详细说明都是示例性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
29.需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根
据本申请的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
30.本实施例提供了一种基于跨域光谱信息的农产品品质无损检测方法,具体包括以下步骤:
31.获取源域光谱数据与目标域光谱数据,并构建训练数据集;
32.构建aug
‑
tradaboost.r2模型,所述aug
‑
tradaboost.r2模型包括三个子模型,分别为回归预测模型、源域结果校正模型以及目标域结果校正模型;该aug
‑
tradaboost.r2(augmented tradaboost.r2)可以实现高准确率、高鲁棒性、高泛化性的农产品光谱跨域建模与品质参数预测分析;
33.训练所述aug
‑
tradaboost.r2模型,并利用训练好的模型对源域光谱数据与目标域光谱数据进行预测。
34.在本实施例中,还包括步骤:对所述源域光谱数据与目标域光谱数据进行预处理。
35.在本实施例中,所述预处理包括平滑处理、多元散射校正处理、标准正态变量处理、去趋势处理、标准化处理、基线偏移处理、二阶或一阶求导处理中的任意一种或多种的组合。
36.如图1所示,在本实施例中,所述训练所述aug
‑
tradaboost.r2模型具体包括以下步骤:
37.首先对回归预测模型基于全部训练数据进行训练建模;
38.将训练数据集中的源域光谱数据x
source_train
输入回归预测模型,得到对应的源域光谱数据的品质参数预测值y’source_train
,将y’source_train
作为自变量,将x
source_train
对应的真值标签y
source_train
作为因变量,带入源域结果校正模型进行训练建模;
39.将训练数据集中的目标域光谱数据x
target_train
输入回归预测模型,得到对应的目标域光谱数据的品质参数预测值y’target_train
,将y’target_train
作为自变量,将x
target_train
对应的真值标签y
target_train
作为因变量,带入目标域结果校正模型进行训练建模。
40.如图2所示,在本实施例中,所述利用训练好的模型对源域光谱数据与目标域光谱数据进行预测具体为:
41.若输入的数据为源域光谱数据,则将源域光谱数据x
source_test
输入回归预测模型,得到的对应x
source_test
的结果y’source_test
,将y’source_test
输入源域结果校正模型,最终得到预测值输出y
source_test_predicted
;
42.若样本为目标域数据,则将光谱数据x
target_test
输入回归预测模型,得到对应x
target_test
的结果y’target_test
,将y’target_test
输入目标域结果校正模型,最终得到预测值输出y
target_test_predicted
。
43.较佳的,所述的品质参数为具体某种农产品的一种品质参数,例如茶叶产品的含水率。
44.在本实施例中,所述回归预测模型采用两阶段的tradaboost.r2。
45.在本实施例中,所述源域结果校正模型为线性回归、岭回归、拉索回归、偏最小二乘回归、决策树回归、k近邻回归、神经网络中的任意一种。
46.在本实施例中,所述目标域结果校正模型为线性回归、岭回归、拉索回归、偏最小
二乘回归、决策树回归、k近邻回归、神经网络中的任意一种。
47.在本实施例中,所述光谱数据为近红外光谱、中红外光谱、拉曼光谱、及紫外
‑
可见光谱中的任意一种。
48.较佳的,本实施例中的源域和目标域光谱数据的分布差异包括但不仅限于:不同光谱测量仪器带来的差异、不同光谱测量环境带来的差异、不同批次农产品样本的化学与生物特性的差异带来的光谱差异、不同农产品品种的化学与生物特性的差异带来的光谱差异、不同农产品类别的化学与生物特性的差异带来的光谱差异。
49.较佳的,所述的源域样本数据是拥有较多已知预测值的源域农产品光谱数据,所述的目标域样本数据是只有较少已知预测值的目标域农产品光谱数据,已知预测值的源域和目标域样本数据用于原创模型aug
‑
tradaboost.r2的训练建模,能够同时达到在源域和目标域数据集上的较高预测准确率,具有较好的泛化性。
50.具体实施过程中,所述的源域数据集为充分测量了品质参数真值的农产品样本数据,多为在实验室里采集的,数量较多;所述的目标域数据通常为农产品在线加工检测时待测品质参数的农产品样本数据,只拥有少量有品质参数真值的农产品样本数据,光谱数据由生产线上在线无损检测得到。本发明通过跨域的可泛化模型,让农产品品质参数的在线无损检测成为可能,打破了不同仪器、不同环境、不同批次下光谱数据不能建模互通的壁垒,实现了较高的模型泛化性和数据利用率。
51.本实施例还提供了一种基于跨域光谱信息的农产品品质无损检测可泛化系统,包括存储器、处理器以及存储在存储器上并能够被处理器运行的计算机程序指令,当处理器运行该计算机程序指令时,实现如上文所述的方法步骤。
52.接下来本实施例结合具体实验数据对上述内容的有效性进行验证说明。
53.本实施例的数据来源:本实施例选取的实验材料共有四批,光谱数据构成了四个独立的数据集,分别取自不同的茶叶品种或茶叶品类。其中前三批样本的茶类都属于绿茶,但是属于不同的品种,分别为安吉白茶、龙井群体种和槠叶齐(数据集1
‑
3)。第四批样本的茶类属于红茶(数据集4)。茶叶的光谱采集设备为基于qe65000型号光谱仪的仪器系统图,采用光谱的范围是450
‑
1000nm,每一个样本采集了712个光谱数据点。每个样本扫完光谱之后,再立即对每个样品进行称重,并进行记录,之后再放进烘箱对其烘干,然后再进行干重测量,并记录每个样本的数据。本实施例的品质参数为含水率,含水率真值的测量方法为:(原重量
‑
干重量)/原重量
×
100%。绿茶和红茶的制作工艺有很大的不同,红茶属于发酵茶而绿茶属于未发酵茶,即红茶的制作工序里面有单独的发酵环节而绿茶没有。因此,在对不同工序的茶叶进行采样,用光谱预测其含水率的时候,红茶的光谱和含水率数据应该会与绿茶有很大的不同。当然,安吉白茶、龙井群体种与槠叶齐虽然都是绿茶,由于其不同品种间的生物特性差异与测量光谱时的实验环境等因素,他们的光谱和含水率分布也会有所不同。
54.本实施例的数据处理与建模过程:本实施例的数据处理与建模部分都是在python环境下进行,具体的实施例过程如下:
55.1)对源域样本光谱数据和目标域样本光谱数据进行snv预处理:
56.2)选取较多的已知预测值的源域数据与少量的已知预测值的目标域数据代入aug
‑
tradaboost.r2模型进行训练建模;
57.3)预测推理,采用决定系数r2与均方根误差rmse作为评价指标,检测模型对于陌生样本的预测准确率。
58.此外,为了对比显示本发明的突出表现,本实施例进行了对照实验,有以下几种情况:
59.①
不做预处理的岭回归模型,在与上述实验等数量的源域数据上建模,在与上述实验等数量的目标域数据上测试;
60.②
snv预处理的岭回归模型,在与上述实验等数量的源域数据与目标域数据上建模,在与上述实验等数量的目标域数据上测试;
61.③
不做预处理,使用s/b模型传递方法的岭回归模型,在与上述实验等数量的源域数据与目标域数据上建模,在与上述实验等数量的目标域数据上测试;
62.④
snv预处理,使用s/b模型传递方法的岭回归模型,在与上述实验等数量的源域数据与目标域数据上建模,在与上述实验等数量的目标域数据上测试。
63.⑤
本实施例方法。
64.用于训练建模的已知预测值的源域数据样本数为40,用于训练建模的已知预测值的目标域数据样本数为20或10,用于测试集的目标域数据样本数为40,用于交叉验证测试的源域数据样本数为20。
65.结果分析:
66.1)数据集1
‑
3分别为源域和目标域,用于训练建模的已知预测值的目标域数据样本数为20,有6种“源域
‑
目标域”的组合,预测目标域,最后结果取6种情况的平均值,得到表1:
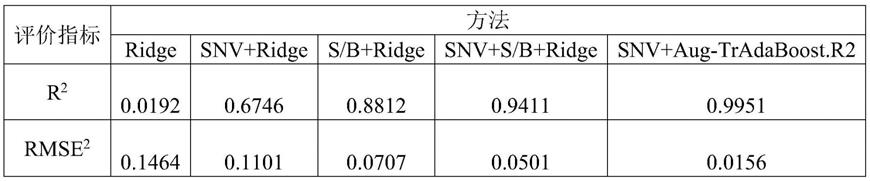
67.表1
[0068][0069]
其中:
[0070]
①
不做预处理的岭回归模型在目标域测试集上的r2为0.0192,rmse为0.1464;
[0071]
②
snv预处理的岭回归模型在目标域测试集上的r2为0.6746,rmse为0.1101;
[0072]
③
不做预处理,使用s/b模型传递方法的岭回归模型在目标域测试集上的r2为0.8812,rmse为0.0707;
[0073]
④
snv预处理,使用s/b模型传递方法的岭回归模型在目标域测试集上的r2为0.9411,rmse为0.0501;
[0074]
⑤
snv预处理情况下,aug
‑
tradaboost.r2模型在目标域测试集上的r2为0.9951,rmse为0.0156。可见,本实施例的预测结果更为准确。
[0075]
另外,与普通的tradaboost.r2模型相比,aug
‑
tradaboost.r2模型在源域数据上的预测性能有较大幅度提升,在snv预处理下,tradaboost.r2模型的r
2cv
为0.7489,rmse
2cv
为0.0683,aug
‑
tradaboost.r2模型的r
2cv
为0.9311,rmse
2cv
为0.0469;
[0076]
2)数据集1
‑
3分别为源域,数据集4为目标域,用于训练建模的已知预测值的目标
域数据样本数为10,共有4种“源域
‑
目标域”的组合,预测目标域,最后结果取4种情况的平均值,得到表2:
[0077]
表2
[0078][0079]
其中:
[0080]
①
snv预处理的岭回归模型在目标域测试集上的r2为
‑
2.0369,rmse为0.4592;
[0081]
②
snv预处理,使用s/b模型传递方法的岭回归模型在目标域测试集上的r2为0.8193,rmse为0.1156;
[0082]
③
snv预处理情况下,aug
‑
tradaboost.r2模型在目标域测试集上的r2为0.9901,rmse为0.0271。
[0083]
如图3所示,将
①
、
②
、
③
的预测拟合结果进行可视化,横坐标为含水率真值,纵坐标为预测值,如果散点大多集中在y=x这条直线上说明该算法能够很好的预测拟合数据,由图3可知,本实施例的aug
‑
tradaboost模型除了一个数据点以外,其余的各个数据点都十分接近y=x直线上,说明其预测准确率很高;而s/b算法的数据点则较为离散,与y=x直线距离也较远;由此可见aug
‑
tradaboost模型的泛化性能显著。
[0084]
由以上的实施例结果可以看出,本发明的aug
‑
tradaboost.r2模型能够在光谱建模预测茶叶含水率问题中较大幅度提升模型的泛化性能,能提高数据的利用率,在光谱无损检测农产品品质的应用中,有着广泛的应用前景。
[0085]
本领域内的技术人员应明白,本申请的实施例可提供为方法、系统、或计算机程序产品。因此,本申请可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本申请可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd
‑
rom、光学存储器等)上实施的计算机程序产品的形式。
[0086]
本申请是参照根据本申请实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0087]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0088]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计
算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0089]
以上所述,仅是本发明的较佳实施例而已,并非是对本发明作其它形式的限制,任何熟悉本专业的技术人员可能利用上述揭示的技术内容加以变更或改型为等同变化的等效实施例。但是凡是未脱离本发明技术方案内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化与改型,仍属于本发明技术方案的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1