一种剔除重叠框的目标检测后处理方法与流程
本发明属于目标检测技术领域,尤其是一种剔除重叠框的目标检测后处理方法。
背景技术:
计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,计算机视觉研究相关的理论和技术,试图建立能够从图像或者多维数据中获取‘信息’的人工智能系统。这里所指的信息指shannon定义的,可以用来帮助做一个“决定”的信息。因为感知可以看作是从感官信号中提取信息,所以计算机视觉也可以看作是研究如何使人工系统从图像或多维数据中“感知”的科学。
随着计算机视觉技术的快速发展,目标检测算法在越来越多的场景中得到了应用。现有的目标检测算法在执行前向推断时,大多使用非极大值抑制(nms)剔除掉重叠度高且预测类别相同的边界框。而一些目标检测算法(如centernet)在执行推断时会预测出重叠度高且类别不同的边界框,目前还没有能够有效剔除重叠度高且类别不同的边界框的解决方案。
技术实现要素:
本发明的发明目的是提供一种剔除重叠框的目标检测后处理方法,其能够通过计算不同类别的预测框之间的交并比,结合置信度可以有效剔除重叠度高且类别不同的边界框。
为达到上述目的,本发明所采用的技术方案是:
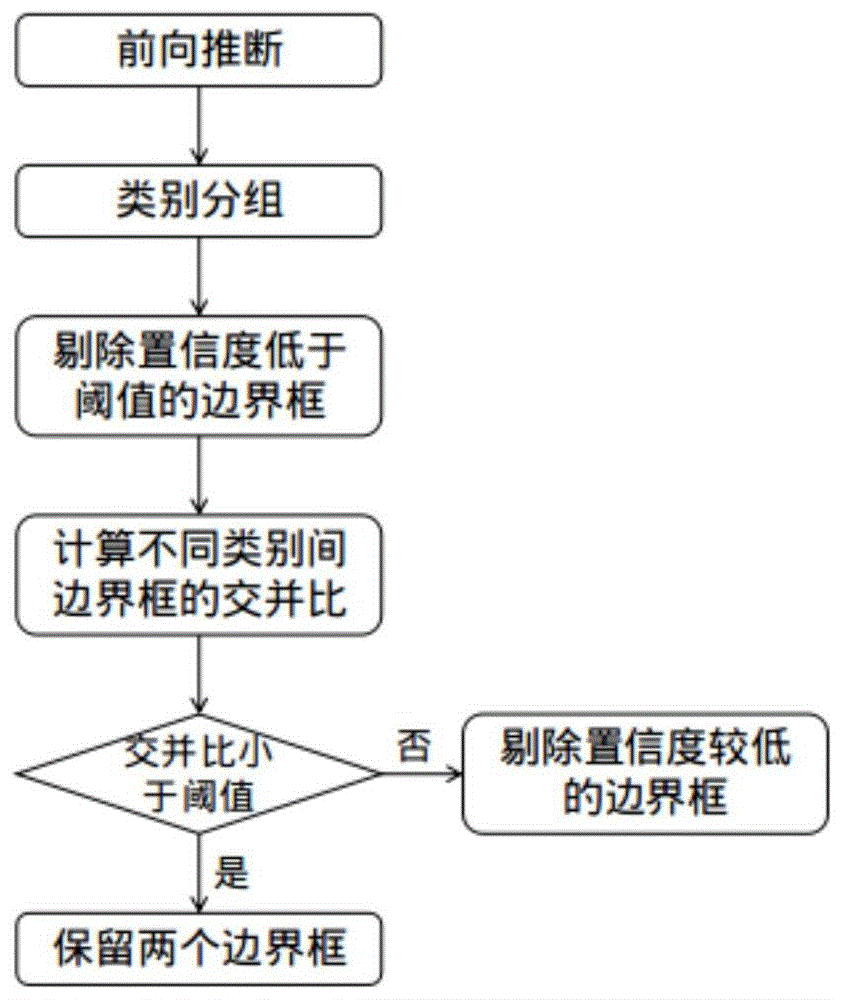
一种剔除重叠框的目标检测后处理方法,包括如下步骤:
步骤1:使用目标检测算法在测试集上执行推断;
步骤2:将网络预测的边界框按照不同类别进行分组;
步骤3:计算每一类别与其他类别所有边界框的交并比,根据交并比与置信度剔除掉重叠度高且类别不同的边界框。
进一步的,所述步骤1的推断方法包括:搭建深度学习开发环境,加载目标检测算法训练好的模型;在测试集上执行推断,输出所有边界框的置信度、类别、位置坐标。
进一步的,所述步骤2的分组方法包括:记类别总数为n,则将边界框分为a1,a2,a3...an共n组,a1内的所有边界框可以表示为:{a11,a12,a13...},a2内的所有边界框可以表示为:{a21,a22,a23...},依次类推。
进一步的,所述步骤3的剔除方法包括:对于ai(i<=n-1),计算组内所有边界框{ai1,ai2,ai3...}与其后类别(从ai+1到ai)所有边界框{a(i+1)1,a(i+1)2,a(i+1)3...ai1,ai2,ai3...}的交并比,若某对边界框的交并比大于阈值,则比较两个边界框的置信度,剔除置信度较小的边界框,依次对ai到ai-1执行上述操作,最后剔除掉所有重叠度高且类别不同的边界框。
由于采用上述技术方案,本发明具有以下有益效果:
以往的目标检测后处理方法多采用非极大值抑制(nms)剔除掉重合度高且预测类别相同的边界框,但是某些网络(例如centernet)在前向推断过程不需要nms,其会预测出重合度高且类别不同的边界框,本发明能够通过计算不同类别的预测框之间的交并比,结合置信度可以有效剔除重叠度高且类别不同的边界框,提高识别效率。
附图说明
图1是本发明的流程图。
具体实施方式
下面结合附图,对本发明的具体实施方式进行详细描述,但应当理解本发明的保护范围并不受具体实施方式的限制。
除非另有其它明确表示,否则在整个说明书和权利要求书中,术语“包括”或其变换如“包含”或“包括有”等等将被理解为包括所陈述的元件或组成部分,而并未排除其它元件或其它组成部分。
在本发明的描述中,需要理解的是,术语“中心”、“长度”、“宽度”、“上”、“下”、“竖直”、“水平”、“顶”、“底”、“内”等指示的方位或位置关系为基于附图所示的方位或位置关系,仅是为了便于描述本发明和简化描述,而不是指示或暗示所指的装置或元件必须具有特定的方位、以特定的方位构造和操作,因此不能理解为对本发明的限制。
在本发明中,除非另有明确的规定和限定,术语“安装”、“相连”、“连接”、“固定”等术语应做广义理解,例如,可以是固定连接,也可以是可拆卸连接,或成一体;可以是直接相连,也可以通过中间媒介间接相连,可以是两个元件内部的连通或两个元件的相互作用关系。对于本领域的普通技术人员而言,可以根据具体情况理解上述术语在本发明中的具体含义。
在本发明中,除非另有明确的规定和限定,第一特征在第二特征之“上”或之“下”可以包括第一和第二特征直接接触,也可以包括第一和第二特征不是直接接触而是通过它们之间的另外的特征接触。而且,第一特征在第二特征“之上”、“上方”和“上面”包括第一特征在第二特征正上方和斜上方,或仅仅表示第一特征水平高度高于第二特征。第一特征在第二特征“之下”、“下方”和“下面”包括第一特征在第二特征正下方和斜下方,或仅仅表示第一特征水平高度小于第二特征。
如图1所示,一种剔除重叠框的目标检测后处理方法,包括如下步骤:
步骤1:使用目标检测算法centernet(objectsaspoints)在测试集上执行推断;(本实施例中的目标检测算法可以替换为其他算法);搭建深度学习开发环境,cpu为i7-9700,gpu为gtx1060,ubuntu16.04lt,cuda9.0,pytorch0.4.1。加载centernet网络的训练好的模型,在测试集上执行推断,输出所有边界框的置信度、类别、位置坐标。
步骤2:将网络预测的边界框按照不同类别进行分组;记类别总数为n,则将边界框分为a1,a2,a3...an共n组,a1内的所有边界框可以表示为:{a11,a12,a13...},a2内的所有边界框可以表示为:{a21,a22,a23...},依次类推。
步骤3:计算每一类别与其他类别所有边界框的交并比,根据交并比与置信度剔除掉重叠度高且类别不同的边界框。对于ai(i<=n-1),计算组内所有边界框{ai1,ai2,ai3...}与其后类别(从ai+1到ai)所有边界框{a(i+1)1,a(i+1)2,a(i+1)3...ai1,ai2,ai3...}的交并比,若某对边界框的交并比大于阈值,则比较两个边界框的置信度,剔除置信度较小的边界框,依次对ai到ai-1执行上述操作,最后剔除掉所有重叠度高且类别不同的边界框。
以往的目标检测后处理方法多采用非极大值抑制(nms)剔除掉重合度高且预测类别相同的边界框,但是某些网络(例如centernet)在前向推断过程不需要nms,其会预测出重合度高且类别不同的边界框,本发明能够通过计算不同类别的预测框之间的交并比,结合置信度可以有效剔除重叠度高且类别不同的边界框,从而提高图片的识别效率。
上述说明是针对本发明较佳实施例的详细说明,但实施例并非用以限定本发明的专利申请范围,凡本发明所提示的技术精神下所完成的同等变化或修饰变更,均应属于本发明所涵盖专利范围。
技术特征:
1.一种剔除重叠框的目标检测后处理方法,其特征在于,包括如下步骤:
步骤1:使用目标检测算法在测试集上执行推断;
步骤2:将网络预测的边界框按照不同类别进行分组;
步骤3:计算每一类别与其他类别所有边界框的交并比,根据交并比与置信度剔除掉重叠度高且类别不同的边界框。
2.一种如权利要求1的剔除重叠框的目标检测后处理方法的实现方法,其特征在于,所述步骤1的推断方法包括:搭建深度学习开发环境,加载目标检测算法训练好的模型;在测试集上执行推断,输出所有边界框的置信度、类别、位置坐标。
3.如权利要求2所述的剔除重叠框的目标检测后处理方法的实现方法,其特征在于,所述步骤2的分组方法包括:记类别总数为n,则将边界框分为a1,a2,a3...an共n组,a1内的所有边界框可以表示为:{a11,a12,a13...},a2内的所有边界框可以表示为:{a21,a22,a23...},依次类推。
4.如权利要求3所述的剔除重叠框的目标检测后处理方法的实现方法,其特征在于,所述步骤3的剔除方法包括:对于ai(i<=n-1),计算组内所有边界框{ai1,ai2,ai3...}与其后类别(从ai+1到ai)所有边界框{a(i+1)1,a(i+1)2,a(i+1)3...ai1,ai2,ai3...}的交并比,若某对边界框的交并比大于阈值,则比较两个边界框的置信度,剔除置信度较小的边界框,依次对ai到ai-1执行上述操作,最后剔除掉所有重叠度高且类别不同的边界框。
技术总结
本发明公开了一种剔除重叠框的目标检测后处理方法,属于目标检测技术领域。包括如下步骤:使用目标检测算法在测试集上执行推断;将网络预测的边界框按照不同类别进行分组;计算每一类别与其他类别所有边界框的交并比,根据交并比与置信度剔除掉重叠度高且类别不同的边界框。本发明能够通过计算不同类别的预测框之间的交并比,结合置信度可以有效剔除重叠度高且类别不同的边界框。
技术研发人员:廖呈玮;林建就;秦卓奕
受保护的技术使用者:桂林汉璟智能仪器有限公司
技术研发日:2020.12.25
技术公布日:2021.04.06
- 还没有人留言评论。精彩留言会获得点赞!