一种端到端的视频动作检测定位系统的制作方法
本发明涉及人体动作识别领域,具体涉及一种端到端的视频动作检测定位系统。
背景技术:
行为识别将给定得一段视频片段进行连续得多帧分析,能够实现识别视频中得内容,通常为识别人的动作,如打架、倒地等等,在实际应用场景中能够识别出场景内发生得危险行为,应用场景广泛,是计算机视觉一直研究的热点问题,目前基于深度学习的行为识别算法不仅能够识别动作发生的类型,还能定位动作发生的空间位置,在多目标,复杂场景下取得了较高的准确度。
dutran等人在论文《learningspatiotemporalfeatureswith3dconvolutionalnetworks》中提出了一个简单有效的方法,在大规模有监督视频数据集上使用深度3维卷积网络(3dconvnets),该方法相比于2dconvnets更适用于时空特征的学习,更能表达帧与帧之间的连续信息,在ucf101数据集上用更少的维度与当时最好的方法精度相当,采用简单的3d卷积架构,计算效率高,前向传播速度快,更易于训练和使用,该方法的不足之处在于识别目标为单人简单场景,在复杂场景下应用识别精度低误报率高,基本无泛化能力,无法在实际复杂环境下推广应用,而且无法对画面中动作发生的位置进行定位。
论文《two-streamconvolutionalnetworksforactionrecognitioninvideos》针对动作分类提出了一种双流网络检测方法,该方法采用并行网络spatialstreamconvnet和temporalstreamconvnet,前者是一个分类网络,输入的是静态图像,得到图像信息,后者输入的连续多帧的稠密光流,得到运动信息,两个网络最后经过softmax做分类分数的融合,通过该方法计算准确度高,能够应用于复杂多人场景,但是该方法的不足之处在于需要预先得到待检测视频片段的光流信息,无法达到实时检测,同样无法定位动作发生的位置。
专利号为201810292563的中国专利,公开了专利一种视频动作分类模型训练方法、装置及视频动作分类方法,优点在于可以获取多个带有标签的训练视频中的训练图像帧,能够在学习到训练难度较小的训练视频帧特征的基础上,学习训练难度较大的训练图像帧与其他训练难度较小的训练图像帧之间的差异性特征,能够为训练视频进行更准确的分类,但是该方法仍然存在无法定位画面中动作发生得空间位置和起始时间。
专利号为201810707711的中国专利专利,公开了一种基于视频的行为识别方法、行为识别装置及终端设备,创新点在于利用卷积神经网络和长短记忆网络lstm进行时序建模,增加帧与帧之间的时序信息,有效解决现有行为识别方法存在背景信息复杂、对时序建模能力不够强等问题,但是该方法不能实现端到端的训练,对单张rgb图像帧单独检测,在背景复杂场景下识别精度较低。
专利号为201210345589.x的中国专利,公开了一种基于动作子空间与权重化行为识别模型的行为识别方法优势在于输入为待检测得视频序列,提取了动作的时间信息,利用减背景的方法去除背景噪声对于前景的影响,不仅能够准确地识别随时间、区域内外人员变化的人类行为,而且对噪声和其它影响因素鲁棒性强,但是该方法对同一场景下多种存在多种行为时无法准确的做出判断。
技术实现要素:
本发明的目的是针对上述不足,提出了一种当输入待检测视频序列后能够定位动作发生的空间位置的端到端的视频动作检测定位系统。
本发明具体采用如下技术方案:
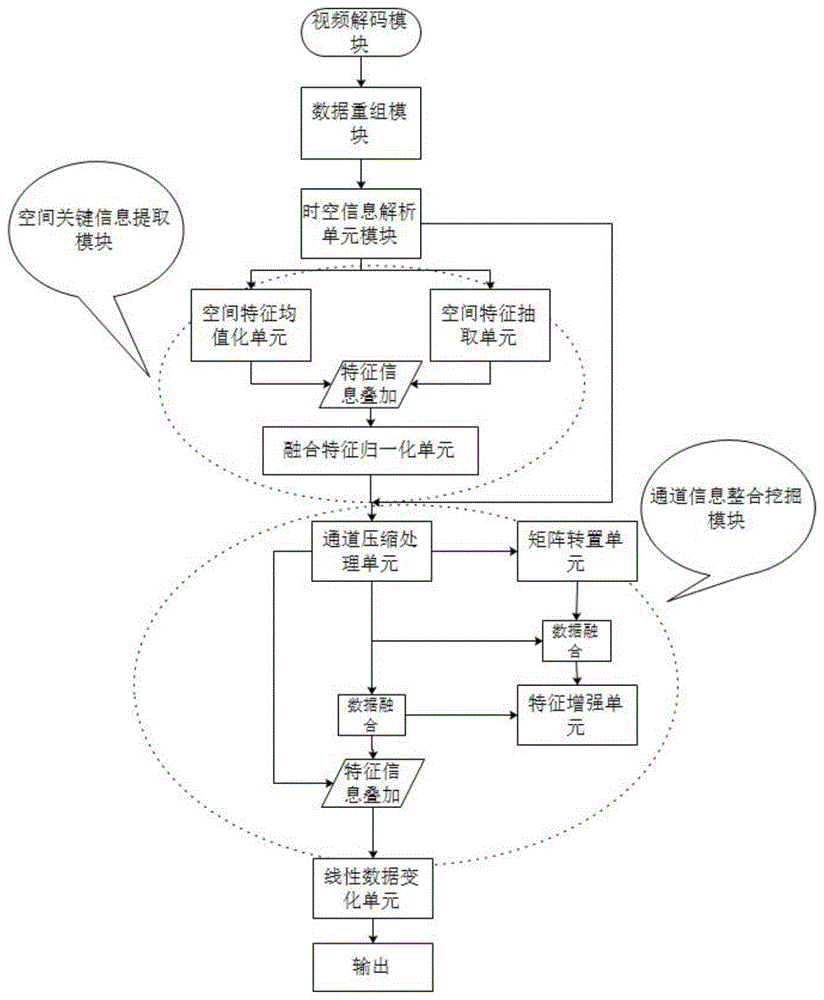
一种端到端的视频动作检测定位系统,包括视频解码模块和数据重组模块,定位过程包括以下步骤:
(1)视频解码;视频解码模块将网络视频流通过网络线路输入到视频解码单元,通过soc片上系统将视频流解码为一帧帧的rgb图像,然后输入到数据重组模块,进行数据的预处理操作;
(2)数据重组;设定数据采样频率,读取固定长度的视频片段,将数据重新组合为可输入数据模式输入到下一模块;
(3)对输入数据进行计算操作;
(4)空间关键信息提取;将时空信息解析单元模块提取的特征信息进行处理,使网络提取的特征更能关注图像中更加有用空间信息,滤除背景信息,对图像中动作发生的位置特征进行增强;
(5)通道信息整合挖掘;将时空信息解析单元模块得到的数据特征进行通道级别的信息整合,挖掘运动信息,关注帧之间运动信息挖掘,关注行为动作发生的类型;
(6)预测结果输出;采用1x1卷积输出对应的通道数量的特征图。
优选地,数据重组具体的过程为:
预测开始取固定长度n的视频片段处理后组成单元数据ydst输入到时空信息解析单元模块,n等于8或者16,输入到时空信息解析单元模块之前需要将单元数据ydst每张rgb图像的尺寸调整成固定尺寸大小;
假定源视频片段单张图片用xsrc表示,输入到时空信息解析单元模块的固定尺寸的图片用xdst表示,尺寸缩放后对于xdst中的每个像素的计算方法如下:
(1)对于xdst中的每个像素,设置坐标通过反向变换得到的浮点坐标为(i+u,j+v),其中i、j均为浮点坐标的整数部分,u、v为浮点坐标的小数部分,是取值[0,1)区间的浮点数;
(2)这个像素值f(i+u,j+v)可由原来图像中坐标为(i,j)、(i+1,j)、(i,j+1)、(i+1,j+1)所对应的周围四个像素值决定,即
f(i+u,j+v)=(1-u)(1-v)f(i,j)+(1-u)vf(i,j+1)+u(1-v)f(i+1,j)+uvf(i+1,j+1)
其中f(i,j)表示源图像(i,j)处的像素值。
优选地,对输入数据进行计算操作包括以下过程:
(1)将视频单元数据ydst输入到时空信息解析单元模块中,将一系列的rgb图像帧rcxdxhxw输入到该模块,c=3代表每一张rgb图像帧的通道数,d表示每组单元数据ydst的图片的数量,最大为16,h和w代表该组单元数据ydst的每张图片的宽和高;时空信息解析单元模块输出特征图
(2)采用增加空间关键信息提取模块,使网络更加关注行为发生的对象的特征,该模块的输入为
优选地,空间关键信息提取包括以下过程:
(1)设定时空信息解析单元模块输出特征图尺寸为
其中f1()表示对特征矩阵均值化操作,f2()表示对矩阵的特征抽取操作;
(2)将rf1和rf2按照第一个维度进行相加的处理,获取合并后的空间特征信息
rf=rf1+rf2
(3)将rf进行空间特征融合,将rf输入到融合特征归一化单元,该单元可以将空间特征增强化,对增强化后的特征进行归一化处理后计算效率更加高效:
x=ffuse(rf)
xout=fnormalize(x)
x表示融合后的特征图,融合函数ffuse()将特征rf的信息整合,通过归一化函数fnormalize()将增强后的特征归一化到0~1之间。
优选地,通道信息整合挖掘包括以下步骤:
(1)空间关键信息提取模块得到的数据特征表示为
(2)用通道压缩单元将特征图y向量化为z,函数fvector()表示向量化函数,特征图z表示对特征图的向量化符号表示,其中c3表示通道标量的相加和,其数值c3=c1+c2,n表示对每张特征图向量化的数值表示,其数值为n=h1*w1;
通过将特征向量z与z的转置特征矩阵zt,t表示矩阵的转置,生成特征矩阵,该矩阵中的每个元素均为z与zt的内积的值,其中矩阵i的生成维度为c3*c3,矩阵i生成计算的公式为:
其中参数i,j是对矩阵z行列的索引表示,n从零开始计算最大值为n,对该矩阵进行如下运算操作,生成特征图
特征图
(3)为了进一步说明特征图e对原始特征图z的影响,需要计算出z′,首先讲矩阵e进行矩阵的转置操作,其计算公式为:
z’=et*z
将z’进行维度变换还原为3维的输出:
其中函数freshape()主要对维度进行了展开的操作,最后特征图的输出为
计算公为o=z”+xout。
优选地,预测结果输出包括以下步骤:
对于图片中的每个特征点生成3个预测框,设计整个网络模为是四层输出,因此在网络训练之前需要对数据集利用聚类算法对所有的bbox进行聚类生成12个预置框,坐标的回归主要根据预测种类的数量生成了模型的每一层最后的输出尺寸大小[(3×(numclass+5))×h×w],其中numclass是预测的种类个数,训练中为了适应当前数据集中的类别,对于类别预测我们采用了如下损失函数,其损失值losscoord计算公式为:
lossc=-∑a′*lna
其中y表示标签中的真实值,a表示模型预测的类别输出值,坐标损失函数损失值losscoord计算公式:
losscoord=y′*log(y)-(1-y′)*log(1-y)
其中y′表示标签中真实的坐标值,y表示模型预测坐标的输出值。
本发明具有如下有益效果:
采用了空间关键信息提取模块和通道信息整合挖掘模块提高了对行为识别的准确率,适应在复杂场景下的可以同时识别多种行为。
将目标检测网络中的边框回归的思想与视频分类相结合增加了模型的泛化能力,提高了对不同场景下识别的鲁棒性。
附图说明
图1端到端的视频动作检测定位系统的结构图。
具体实施方式
下面结合附图和具体实施例对本发明的具体实施方式做进一步说明:
结合图1,一种端到端的视频动作检测定位系统,包括视频解码模块和数据重组模块,定位过程包括以下步骤:
(1)视频解码;视频解码模块将网络视频流通过网络线路输入到视频解码单元,通过soc片上系统将视频流解码为一帧帧的rgb图像,然后输入到数据重组模块,进行数据的预处理操作。
(2)数据重组;设定数据采样频率,读取固定长度的视频片段,将数据重新组合为可输入数据模式输入到下一模块。
(3)对输入数据进行计算操作。
(4)空间关键信息提取;将时空信息解析单元模块提取的特征信息进行处理,使网络提取的特征更能关注图像中更加有用空间信息,滤除背景信息,对图像中动作发生的位置特征进行增强。
(5)通道信息整合挖掘;将时空信息解析单元模块得到的数据特征进行通道级别的信息整合,挖掘运动信息,关注帧之间运动信息挖掘,关注行为动作发生的类型。
(6)预测结果输出;采用1x1卷积输出对应的通道数量的特征图。
数据重组具体的过程为:
预测开始取固定长度n的视频片段处理后组成单元数据ydst输入到时空信息解析单元模块,n等于8或者16,输入到时空信息解析单元模块之前需要将单元数据ydst每张rgb图像的尺寸调整成固定尺寸大小;
假定源视频片段单张图片用xsrc表示,输入到时空信息解析单元模块的固定尺寸的图片用xdst表示,尺寸缩放后对于xdst中的每个像素的计算方法如下:
(1)对于xdst中的每个像素,设置坐标通过反向变换得到的浮点坐标为(i+u,j+v),其中i、j均为浮点坐标的整数部分,u、v为浮点坐标的小数部分,是取值[0,1)区间的浮点数;
(2)这个像素值f(i+u,j+v)可由原来图像中坐标为(i,j)、(i+1,j)、(i,j+1)、(i+1,j+1)所对应的周围四个像素值决定,即
f(i+u,,j+v)=(1-u)(1-v)f(i,j)+(1-u)vf(i,j+1)+u(1-v)f(i+1,j)+uvf(i+1,j+1)
其中f(i,j)表示源图像(i,j)处的像素值。
优选地,对输入数据进行计算操作包括以下过程:
(1)将视频单元数据ydst输入到时空信息解析单元模块中,将一系列的rgb图像帧rcxdxhxw输入到该模块,c=3代表每一张rgb图像帧的通道数,d表示每组单元数据ydst的图片的数量,最大为16,h和w代表该组单元数据ydst的每张图片的宽和高;时空信息解析单元模块输出特征图
(2)采用增加空间关键信息提取模块,使网络更加关注行为发生的对象的特征,该模块的输入为
空间关键信息提取包括以下过程:
(1)设定时空信息解析单元模块输出特征图尺寸为
其中f1()表示对特征矩阵均值化操作,f2()表示对矩阵的特征抽取操作;
(2)将rf1和rf2按照第一个维度进行相加的处理,获取合并后的空间特征信息
rf=rf1+rf2
(3)将rf进行空间特征融合,将rf输入到融合特征归一化单元,该单元可以将空间特征增强化,对增强化后的特征进行归一化处理后计算效率更加高效:
x=ffuse(rf)
xout=fnormalize(x)
x表示融合后的特征图,融合函数ffuse()将特征rf的信息整合,通过归一化函数fnormalize()将增强后的特征归一化到0~1之间。
通道信息整合挖掘包括以下步骤:
(1)空间关键信息提取模块得到的数据特征表示为
(2)用通道压缩单元将特征图y向量化为z,函数fvector()表示向量化函数,特征图z表示对特征图的向量化符号表示,其中c3表示通道标量的相加和,其数值c3=c1+c2,n表示对每张特征图向量化的数值表示,其数值为n=h1*w1;
通过将特征向量z与z的转置特征矩阵zt,t表示矩阵的转置,生成特征矩阵,该矩阵中的每个元素均为z与zt的内积的值,其中矩阵i的生成维度为c3*c3,矩阵i生成计算的公式为:
其中参数i,j是对矩阵z行列的索引表示,n从零开始计算最大值为n,对该矩阵进行如下运算操作,生成特征图
特征图
(3)为了进一步说明特征图e对原始特征图z的影响,需要计算出z′,首先讲矩阵e进行矩阵的转置操作,其计算公式为:
z’=et*z
将z’进行维度变换还原为3维的输出:
其中函数freshape()主要对维度进行了展开的操作,最后特征图的输出为
计算公为o=z”+xout。
预测结果输出包括以下步骤:
对于图片中的每个特征点生成3个预测框,设计整个网络模为是四层输出,因此在网络训练之前需要对数据集利用聚类算法对所有的bbox进行聚类生成12个预置框,坐标的回归主要根据预测种类的数量生成了模型的每一层最后的输出尺寸大小[(3×(numclass+5))×h×w],其中numclass是预测的种类个数,训练中为了适应当前数据集中的类别,对于类别预测我们采用了如下损失函数,其损失值losscoord计算公式为:
lossc=-∑a′*lna
其中y表示标签中的真实值,a表示模型预测的类别输出值,坐标损失函数损失值losscoord计算公式:
losscoord=-y′*log(y)-(1-y′)*log(1-y)
其中y′表示标签中真实的坐标值,y表示模型预测坐标的输出值。
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!