一种基于区块链的自动合成新闻的检测方法及系统
本发明涉及区块链和机器学习领域,具体涉及一种基于区块链的自动合成新闻的检测方法及系统。
背景技术:
目前,检测自动合成新闻的方法主要分为两种:事实核查以及机器学习。事实核查通过参考可信赖的网站进行比对。基于机器学习方法需要人工构造特征,通过对人工标注的数据集进行特征提取和学习来构建分类模型。然而,深度预训练语言模型能力的提高颠覆了过往的假设,自动合成新闻在“风格”和“结构”上与真实新闻越发相似。
因此,对于机器学习模型而言,自动合成新闻的特征提取和选择是十分困难的,这决定机器学习模型的上限。并且,当模型被部署到平台上并实际使用后,若不及时获取足够多的最新数据并重新训练,它们将很快会过时。此外,目前自动合成新闻的数量远小于真实新闻的数量,所以构建分类模型时存在正负样本不均衡的问题,这将严重降低模型的泛化能力,从而导致模型失效。
技术实现要素:
为了解决上述技术问题,本发明提供一种基于区块链的自动合成新闻的检测方法及系统。
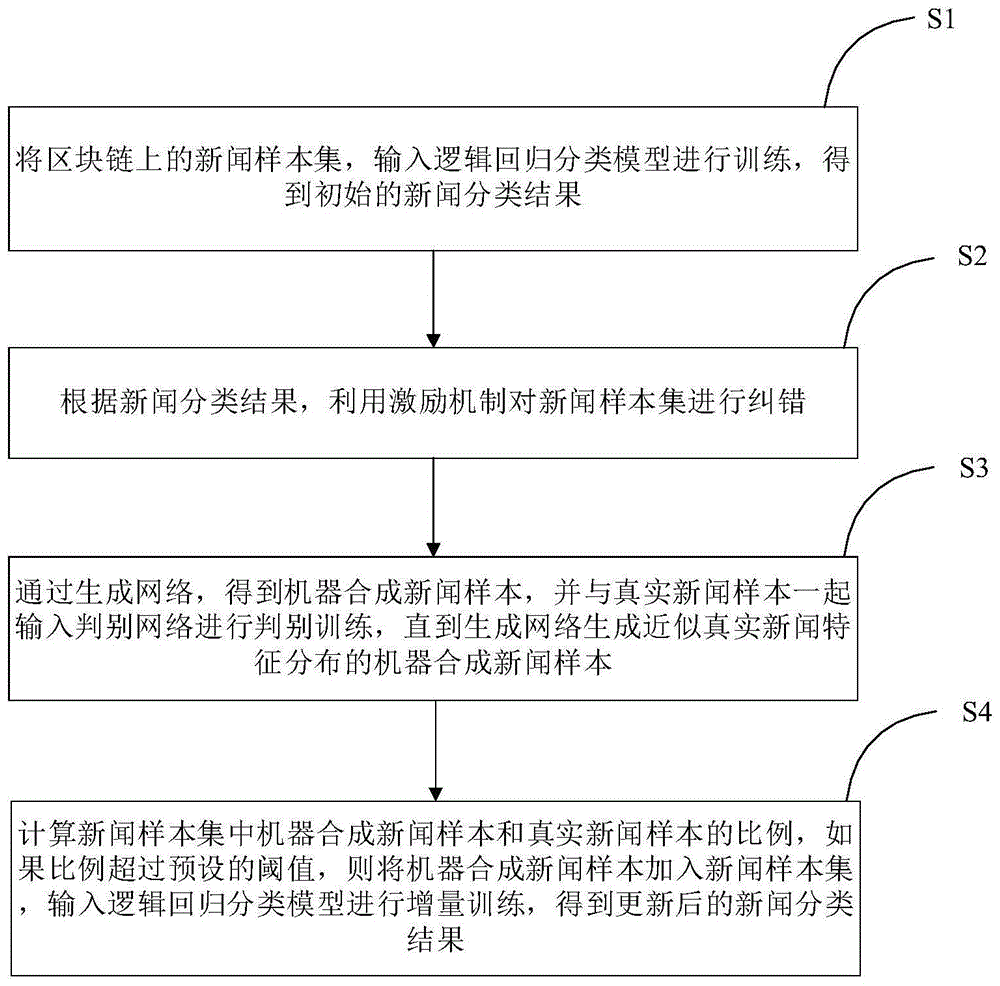
本发明技术解决方案为:一种基于区块链的自动合成新闻的检测方法,包括:
步骤s1:将区块链上的新闻样本集,输入逻辑回归分类模型进行训练,得到初始的新闻分类结果;
步骤s2:根据所述新闻分类结果,利用激励机制对所述新闻样本集进行纠错;
步骤s3:通过生成网络,得到机器合成新闻样本,并与真实新闻样本一起输入判别网络进行判别训练,直到所述生成网络生成近似真实新闻特征分布的机器合成新闻样本;
步骤s4:计算新闻样本集中所述机器合成新闻样本和所述真实新闻样本的比例,如果所述比例超过预设的阈值,则将所述机器合成新闻样本加入所述新闻样本集,输入所述逻辑回归分类模型进行增量训练,得到更新后的新闻分类结果。
本发明与现有技术相比,具有以下优点:
1、本发明公开了一种基于区块链的自动合成新闻的检测方法,利用n-gram特征和tf-idf算法对逻辑回归分类模型进行改进,使该模型能获得到部分时序信息缓解时间序列预测问题,从而捕捉自动合成新闻过程中的抽样方案留下的“伪影”。
2、本发明利用区块链技术对新闻样本集进行纠错,供参与者协作构建新闻样本集。通过激励机制惩罚提交不良数据的贡献者,鼓励贡献者提交能够提高逻辑回归分类模型准确性的新闻样本,以提高样本集的质量。
3、本发明利用生成网络和判别网络进行博弈训练,从而生成机器合成新闻样本,使得新闻样本集的正负样本均衡,防止比例过大的样本造成过拟合,即预测偏向样本数较多的分类,从而实现大幅度提高增量式分类模型的泛化能力。同时,使用智能合约来增量训练逻辑回归分类模型,解决已发布的逻辑回归分类模型若不获取更多数据并对其进行重新训练将很快变得过时的问题。
附图说明
图1为本发明实施例中一种基于区块链的自动合成新闻的检测方法的流程图;
图2为本发明实施例中一种基于区块链的自动合成新闻的检测方法的结构示意图;
图3为本发明实施例中一种基于区块链的自动合成新闻的检测方法中步骤s1:将区块链上的新闻样本集,输入逻辑回归分类模型进行训练,得到初始的新闻分类结果的流程图;
图4本发明实施例中一种基于区块链的自动合成新闻的检测方法中步骤s2:根据新闻分类结果,利用激励机制对新闻样本集进行纠错的流程图;
图5本发明实施例中激励机制的流程图;
图6本发明实施例中一种基于区块链的自动合成新闻的检测方法中步骤s3:通过生成网络,得到机器合成新闻样本,并与真实新闻样本一起输入判别网络进行判别训练,直到生成网络生成近似真实新闻特征分布的机器合成新闻样本的流程图;
图7本发明实施例中生成式对抗网络的结构示意图;
图8本发明实施例中一种基于区块链的自动合成新闻的检测方法中步骤s4:计算新闻样本集中机器合成新闻样本和真实新闻样本的比例,如果所述比例超过预设的阈值,则将机器合成新闻样本加入新闻样本集,输入所述逻辑回归分类模型进行增量训练,得到更新后的新闻分类结果的流程图;
图9本发明实施例中一种智能排序候选框的目标跟踪系统的结构框图。
具体实施方式
本发明提供了一种基于区块链的自动合成新闻的检测方法及系统,通过对逻辑回归分类模型进行改进,提高样本集的质量,以及通过生成机器合成新闻样本,使得新闻样本集的正负样本均衡,防止比例过大的样本造成过拟合,即预测偏向样本数较多的分类,从而实现大幅度提高增量式分类模型的泛化能力。同时,使用智能合约来增量训练逻辑回归分类模型,解决已发布的逻辑回归分类模型若不获取更多数据并对其进行重新训练将很快变得过时的问题。
为了使本发明的目的、技术方案及优点更加清楚,以下通过具体实施,并结合附图,对本发明进一步详细说明。
实施例一
如图1、图2所示,在一个实施例中,本发明实施例提供的一种基于区块链的自动合成新闻的检测方法,包括下述步骤:
步骤s1:将区块链上的新闻样本集,输入逻辑回归分类模型进行训练,得到初始的新闻分类结果;
步骤s2:根据新闻分类结果,利用激励机制对新闻样本集进行纠错;
步骤s3:通过生成网络,得到机器合成新闻样本,并与真实新闻样本一起输入判别网络进行判别训练,直到生成网络生成近似真实新闻特征分布的机器合成新闻样本;
步骤s4:计算新闻样本集中机器合成新闻样本和真实新闻样本的比例,如果比例超过预设的阈值,则将机器合成新闻样本加入新闻样本集,输入逻辑回归分类模型进行增量训练,得到更新后的新闻分类结果。
如图3所示,在一个实施例中,上述步骤s1:将区块链上的新闻样本集,输入逻辑回归分类模型进行训练,得到初始的新闻分类结果,具体包括;
步骤s11:按照下述公式(1),在新闻样本集中加入n-gram特征;
其中,p(w1,w2,···,wm)表示为长度为m的语句出现概率;p(wi|wi-n-1,···,wi-1)表示词wi与前面n个词相关。本发明实施例中采用了unigram和bigram,即一元模型和二元模型。
步骤s12:按照下述公式(2),利用tf-idf算法对新闻样本集进行过滤;
其中,count(w)为词w的出现次数,|di|为新闻di中所有词的数量,n为所有的新闻样本的总数,i(w,di)表示新闻di是否包含词w。
步骤s13:将过滤后的新闻样本集,输入逻辑回归分类模型进行训练,得到新闻的初始分类结果。
本发明实施例通过上述步骤s11和s12分别利用unigram、bigram特征和tf-idf算法对现有的逻辑回归分类模型进行改进,并使用智能合约来训练逻辑回归分类模型,使得该模型能获得到部分时序信息缓解时间序列预测问题,从而捕捉自动合成新闻过程中的抽样方案留下的“伪影”。
如图4所示,在一个实施例中,上述步骤s2:根据新闻分类结果,利用激励机制对新闻样本集进行纠错,包括:
步骤s21:在区块链中,每个贡献者提交新闻数据(x,y)时,需要支付押金d;其中,x为新闻数据,y为该新闻数据的标签;
步骤s22:经过预设时间t后,如果逻辑回归分类模型h的分类结果还是h(x)==y,则退还全部押金d;如果h(x)≠y,且其他贡献者提交(x,y′),其中,y′是正确的标签,则对该纠正样本的贡献者按照下述公式(3)退还部分押金:
其中,r(cr,d)为纠正样本的贡献者的退还押金,n(c)为原始的贡献者c提交的不正确或无效新闻样本的数量,n(cr)为更正数据的贡献者cr的数量;
如图5所示,在本步骤中,每个贡献者向区块链提交带有数据x和标签y的新闻样本数据(x,y)时,需要支付押金d。假设(x,y)是带有正确标签的数据,当一定时间t过后,若逻辑回归分类模型h仍然同意最初提交的分类h(x)==y,那么该贡献者就可以被退还全部押金d。如果提交的样本(x,y)不正确或无效,那么在时间t内其他贡献者应该提交(x,y′),其中y′是正确的标签。在退款阶段已经更正数据的其他贡献者可以找出满足h(x)==y的数据点(x,y),并请求获取最初在提交(x,y)时提交的一部分押金,可通过上述公式(3)计算可退还的部分押金。
步骤s23:将纠错后的新闻样本更新至新闻样本集。
本发明利用区块链技术对新闻样本集进行纠错,供参与者协作构建新闻样本集。通过激励机制惩罚提交不良数据的贡献者,鼓励贡献者提交能够提高逻辑回归分类模型准确性的新闻样本,以提高样本集的质量。
但是,由于此时新闻样本集中自动合成新闻的数量远小于真实新闻的数量,所以训练逻辑回归分类模型时存在正负样本严重不均衡的问题,这将严重降低模型的泛化能力,从而导致模型失效。因此,通过下述步骤,可以生成近似真实新闻的机器合成新闻,添加到新闻样本集供逻辑回归分类模型进行增量训练。
如图6所示,在一个实施例中,上述步骤s3:通过生成网络,得到机器合成新闻样本,并与真实新闻样本一起输入判别网络进行判别训练,直到生成网络生成近似真实新闻特征分布的机器合成新闻样本,包括:
步骤s31:将随机的噪声样本输入生成网络g,得到机器合成新闻样本;
在本步骤中,将随机的噪声样本,即随机生成的样本,输入生成网络g,由生成网络g根据真实新闻的特征分布,将该随机样本生成机器合成新闻。
步骤s32:将机器合成新闻样本和真实新闻样本一起输入判别网络d,进行判别训练;生成网络g和判别网络d按照下述gan公式(4),进行判别训练;直到生成网络g生成近似真实新闻特征分布的机器合成新闻样本,判别训练结束;
其中,gan的目标优化函数为mingmaxdv(d,g);x为真实新闻样本;z为随机样本;pdata(x)为真实新闻样本服从的分布;pz(z)为随机样本服从的分布;g(z)为由生成网络g生成的尽可能服从真实新闻样本分布pdata(x)的样本,即机器合成新闻样本;e为计算期望值。
如图7所述,在本发明实施例中,生成网络g和判别网络d构成了生成式对抗网络,在整个训练过程中生成网络g和判别网络d为“博弈”的双方。生成网络g捕捉真实新闻样本的数据的分布,并生成机器合成新闻样本。判别网络d是一个二分类器,用于判断输入的样本来自于生成网络g的概率。生成网络g和判别网络d均为非线性映射函数,是多层感知机或神经网络。在训练过程中,生成网络g的目标是尽量生成与真实新闻样本接近的结果去欺骗判别网络d;而判别网络d的目标是尽量把生成网络g生成的机器合成新闻样本和真实新闻样本区分开来,因此,生成网络g和判别网络d形成了一个动态的“博弈过程”。举例来说,判别网络d判断输入的样本是来自于生成网络g的概率为0.9,那么说明判别网络d很容易将输入样本识别为机器合成新闻样本,则由生成网络g继续生成机器合成新闻样本,并由判别网络d继续进行判断。直到生成网络g生成近似真实新闻特征分布的机器合成新闻样本,使得判别网络d无法区分输入样本是机器合成新闻样本和真实新闻样本,比如,此时判别网络d判断输入样本是来自于生成网络g的概率为0.5,说明判别网络d无法判断输入样本是否为合成新闻样本,则训练结束。
本发明利用生成网络和判别网络进行博弈训练,从而生成机器合成新闻样本,使得新闻样本集中的正负样本均衡,防止比例过大的样本造成过拟合,即预测偏向样本数较多的分类,从而实现大幅度提高增量式分类模型的泛化能力。
如图8所示,在一个实施例中,上述步骤s4:计算新闻样本集中机器合成新闻样本和真实新闻样本的比例,如果所述比例超过预设的阈值,则将机器合成新闻样本加入新闻样本集,输入所述逻辑回归分类模型进行增量训练,得到更新后的新闻分类结果,包括:
步骤s41:计算区块链上新闻样本集中机器合成新闻样本和真实新闻样本的比例,若二者比例超过预设的阈值,则将步骤s32中生成的机器合成新闻样本加入区块链中新闻样本集;
在本步骤中,计算区块链上新闻样本集中机器合成新闻样本和真实新闻样本的比例,若二者数量不均衡,比例超过预设的阈值,则将步骤s32中由生成网络g生成的机器合成新闻样本附加“合成”标签后,加入区块链中新闻样本集。
步骤s42:将更新后的新闻样本集输入所述逻辑回归分类模型进行增量训练,得到更新后的新闻分类结果。
本发明实施例采用随机梯度下降算法对逻辑回归分类模型进行增量更新,即通过小批量的数据迭代更新模型的权重。增量学习定义和sgd算法如下述公式(5)和(6):
hi=hi-1(si,si-1,…,si-p)(5)
其中,si为带标签的训练数据si=(xi,yi),hi是仅取决于hi-1和最近p个例子si,si-1,…,si-p的模型函数。其中η是学习率,j(θ)为最小化可微目标函数,选取数据样本i,计算
本发明使用智能合约来增量训练逻辑回归分类模型,可解决已发布的逻辑回归分类模型若不获取更多数据并对其进行重新训练将很快变得过时的问题。
实施例二
如图9所示,本发明实施例提供了一种基于区块链的自动合成新闻的检测系统,包括下述模块:
初始新闻分类模块41,用于将区块链上的新闻样本集,输入逻辑回归分类模型进行训练,得到初始的新闻分类结果;
新闻样本纠错模块42,用于根据新闻分类结果,利用激励机制对新闻样本集进行纠错;
机器合成新闻样本生成模块,用于通过生成网络,得到机器合成新闻样本,并与真实新闻样本一起输入判别网络进行判别训练,直到生成网络生成近似真实新闻特征分布的机器合成新闻样本;
更新新闻分类模块,用于计算新闻样本集中机器合成新闻样本和真实新闻样本的比例,如果比例超过预设的阈值,则将机器合成新闻样本加入新闻样本集,输入逻辑回归分类模型进行增量训练,得到更新后的新闻分类结果。
提供以上实施例仅仅是为了描述本发明的目的,而并非要限制本发明的范围。本发明的范围由所附权利要求限定。不脱离本发明的精神和原理而做出的各种等同替换和修改,均应涵盖在本发明的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!