一种手部检测追踪与乐器检测的结合交互方法及系统与流程
本发明涉及ar交互的技术领域,特别是一种手部检测追踪与乐器检测的结合交互方法及系统。
背景技术:
随着科技与娱乐内容的结合度提升,观众对于娱乐体验方式的需求逐渐由单一内容、低频交互向更多个性化、更高品质以及更多互动体验过渡,因此涌现互动式视频,观众可点击视频中出现的互动组件,选择自己想观看的分支剧情或者视角。比起传统的,观众可被动式的观看视频,互动式视频给予观众的沉浸感、互动性更强。
ar是一项综合集成技术,涉及计算机图形学、人机交互技术、传感技术、人工智能等领域,它用计算机生成逼真的三维视、听、嗅觉等感觉,使人作为参与者通过适当装置,自然地对虚拟世界进行体验和交互。使用者进行位置移动时,电脑可以立即进行复杂的运算,将精确的3d世界影像传回产生临场感。该技术集成了计算机图形(cg)技术、计算机仿真技术、人工智能、传感技术、显示技术、网络并行处理等技术的最新发展成果,是一种由计算机技术辅助生成的高技术模拟系统。
在现有的ar技术当中,需要使用者佩戴ar眼镜。然而,人都是通过五感来感知世界,ar技术只能通过视觉和听觉来帮助人进行感知,虽然可以通过手握交互设备来获取触觉,但是毕竟和真实的实物触觉还有很大的区别,不能给人带来最好的ar互动体验。
公开号为109358748a的发明专利申请公开了《一种用手与手机ar虚拟物体交互的设备和方法》,包括手机以及与手机配套的手势追踪装置,所述手势追踪装置设置于手机背面,手势追踪装置与手机通讯连接;所述手机包括能支持arcore技术的安卓系统,手机安装有与手势追踪装置匹配的arcore手机app;所述手势追踪装置包括软件api,用于在工作范围内捕捉用户的手的动作、手的位置以及手的位移数据信息,并将这些数据信息实时传送到arcore手机app中;手机的显示屏用于显示ar场景。该方法的缺点是无法识别乐器弹奏区域,无法提供手部关键点参数
技术实现要素:
为了解决上述的技术问题,本发明提出的一种手部检测追踪与乐器检测的结合交互方法及系统,检测手部关键点和乐器关键区域,判断手部关键点是否在乐器关键区域中,然后根据判断结果系统发出相应声音。
本发明的第一目的是提供一种手部检测追踪与乐器检测的结合交互方法,包括使用采集装置采集视频和/或图像,还包括以下步骤:
生成手部识别模型和乐器检测模型;
将采集到的视频分别输入所述手部识别模型和所述乐器检测模型进行检测;
使用判断规则判断手部关键检点位置是否在所要识别的乐器位置当中。
优选的是,所述手部识别模型的生成方法包括以下子步骤:
配置相机参数并批量采集乐器数据,并进行标注,标注方式为根据图像中手部的位置对手部的n个关键点标注x、y值,其中,n为关键点数量;
对采集到的图像进行处理并生成估算x、y值;
计算所述估算x、y值与采集数据得到的x、y值的欧几里得距离;
当所述欧几里得距离小于指定阈值时,保存参数生成手部识别模型。
在上述任一方案中优选的是,所述对采集到的图像进行处理并生成估算x、y值的方法包括以下子步骤:
将批量的采集图像进行压缩,对压缩后的图像进行归一化操作;
使用mobilenet深度卷积神经网络的进行特征提取生成特征图;
使用平均池化层对特征图进行池化操作,利用对平均池化层生成值进行回归估算x、y值。
在上述任一方案中优选的是,所述乐器识别模型的生成方法包括以下子步骤:
配置相机参数并批量采集乐器数据,并进行标注,标注方式为采用矩形框表示物体位置,记录矩形框左上角xmin、ymin值和右下角xmax、ymax值;
对标注的所述左上角xtl、ytl值与右下角xbr、ybr值分别利用x/width和y/height公式进行转换,生成左上角归一化值(xt1w、ytlh)与右下角归一化值(xbrw、ybrh),其中,width代表照片的宽,height代表照片的高;
使用神经网络学习图像数据并生成估算(xmin、ymin)与(xmax、ymax)的向量值;
计算所述估算(xmin、ymin)与(xmax、ymax)的向量与采集数据得到的(xt1w、ytlh)与(xbrw、ybrh)的向量值的交叉熵;
当所述交叉熵小于指定阈值时,保存权重生成模型。
在上述任一方案中优选的是,所述使用神经网络学习图像数据并生成估算(xmin、ymin)与(xmax、ymax)的向量值的方法包括以下子步骤:
将批量的采集图像进行压缩,对压缩后的图像进行归一化操作;
使用mobilenet深度卷积神经网络的进行特征提取生成特征图;
使用平均池化层对特征图进行池化操作,利用对平均池化层生成值进行回归估算x、y值。
在上述任一方案中优选的是,所述将采集到的视频分别输入所述手部识别模型和所述乐器检测模型进行检测的方法包括启动所述采集装置,同时加载所述手部识别模型和所述乐器识别模型,将所述采集装置采集到的视频帧分别传输给所述手部识别模型和所述乐器识别模型。
在上述任一方案中优选的是,所述判断规则为判断以下公式是否为逻辑真值,如果是,则能够弹奏相应音符;如果不是,则不能够弹奏相应音符,其中,公式为[xmin≤xandx≤xmaxandymin≤yandy≤ymax]。
本发明的第二目的是提供一种手部检测追踪与乐器检测的结合交互系统,包括用于采集视频和/或图像的采集装置,还包括以下模块:
训练模块:用于生成手部识别模型和乐器检测模型;
检测模块:用于将采集到的视频分别输入所述手部识别模型和所述乐器检测模型进行检测,并使用判断规则判断手部关键检点位置是否在所要识别的乐器位置当中;
所述系统按照如权利要求1的方法进行手部检测追踪与乐器检测的结合交互。
优选的是,所述手部识别模型的生成方法包括以下子步骤:
配置相机参数并批量采集乐器数据,并进行标注,标注方式为根据图像中手部的位置对手部的n个关键点标注x、y值,其中,n为关键点数量;
对采集到的图像进行处理并生成估算x、y值;
计算所述估算x、y值与采集数据得到的x、y值的欧几里得距离;
当所述欧几里得距离小于指定阈值时,保存参数生成手部识别模型。
在上述任一方案中优选的是,所述对采集到的图像进行处理并生成估算x、y值的方法包括以下子步骤:
将批量的采集图像进行压缩,对压缩后的图像进行归一化操作;
使用mobilenet深度卷积神经网络的进行特征提取生成特征图;
使用平均池化层对特征图进行池化操作,利用对平均池化层生成值进行回归估算x、y值。
在上述任一方案中优选的是,所述乐器识别模型的生成方法包括以下子步骤:
配置相机参数并批量采集乐器数据,并进行标注,标注方式为采用矩形框表示物体位置,记录矩形框左上角xmin、ymin值和右下角xmax、ymax值;
对标注的所述左上角xtl、ytl值与右下角xbr、ybr值分别利用x/width和y/height公式进行转换,生成左上角归一化值(xt1w、ytlh)与右下角归一化值(xbrw、ybrh),其中,width代表照片的宽,height代表照片的高;
使用神经网络学习图像数据,生成估算(xmin、ymin)与(xmax、ymax)的向量值;
计算所述估算(xmin、ymin)与(xmax、ymax)的向量值与采集数据得到的(xt1w、ytlh)与(xbrw、ybrh)的向量值的交叉熵;
当所述交叉熵小于指定阈值时,保存权重生成模型。
在上述任一方案中优选的是,所述使用神经网络学习图像数据并生成估算(xmin、ymin)与(xmax、ymax)的向量值的方法包括以下子步骤:
将批量的采集图像进行压缩,对压缩后的图像进行归一化操作;
使用mobilenet深度卷积神经网络的进行特征提取生成特征图;
使用平均池化层对特征图进行池化操作,利用对平均池化层生成值进行回归估算x、y值。
在上述任一方案中优选的是,所述检测模块还用于启动所述采集装置,同时加载所述手部识别模型和所述乐器识别模型,将所述采集装置采集到的视频帧分别传输给所述手部识别模型和所述乐器识别模型。
在上述任一方案中优选的是,所述判断规则为判断以下公式是否为逻辑真值,如果是,则能够弹奏相应音符;如果不是,则不能够弹奏相应音符,其中,公式为[xmin≤xandx≤xmaxandymin≤yandy≤ymax]。
本发明提出了一种手部检测追踪与乐器检测的结合交互方法及系统,能够在ar的场景中,实现手部可以和实际的物体进行交互,并发出声音、动画等互动效果。
附图说明
图1为按照本发明的手部检测追踪与乐器检测的结合交互方法的一优选实施例的流程图。
图2为按照本发明的手部检测追踪与乐器检测的结合交互系统的一优选实施例的模块图。
图3为按照本发明的手部检测追踪与乐器检测的结合交互方法的程序启动识别的一实施例的流程图。
图4为按照本发明的手部检测追踪与乐器检测的结合交互方法的手部关键点训练的一实施例的流程图。
图5为按照本发明的手部检测追踪与乐器检测的结合交互方法的乐器识别训练的一实施例的流程图。
图6为按照本发明的手部检测追踪与乐器检测的结合交互方法手部与纸板乐器接触识别的一实施例的示意图。
具体实施方式
下面结合附图和具体的实施例对本发明做进一步的阐述。
实施例一
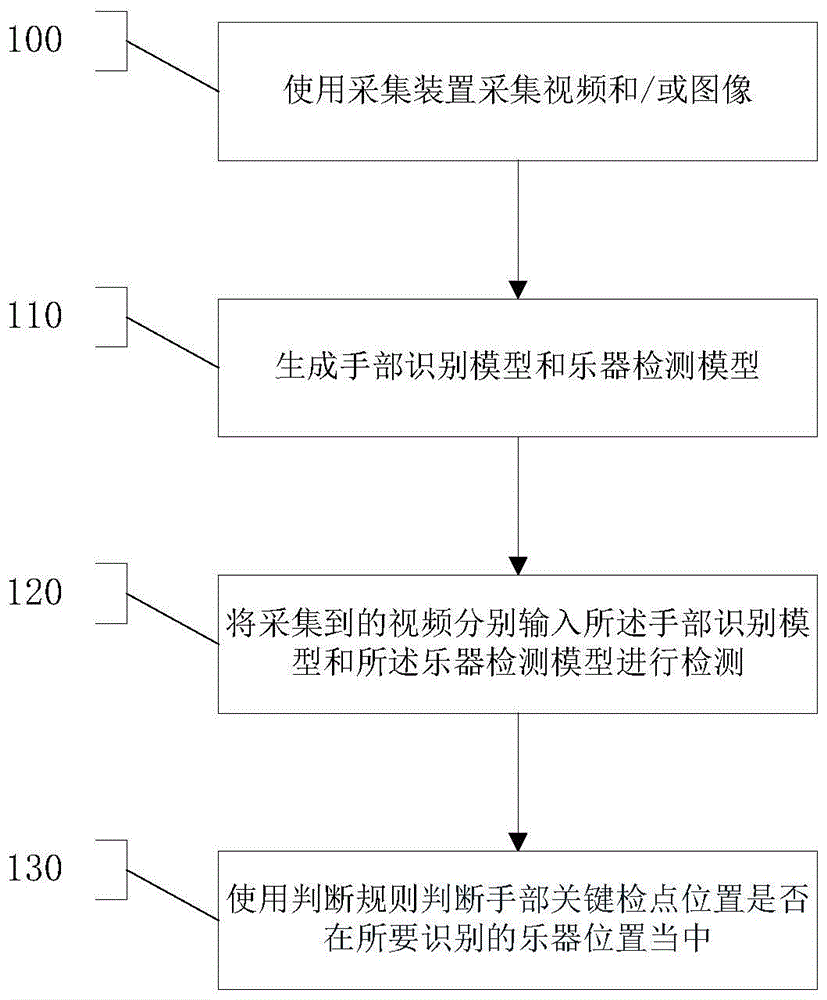
如图1所示,执行步骤100,使用采集装置采集视频和/或图像。
执行步骤110,生成手部识别模型和乐器检测模型。所述手部识别模型的生成方法包括以下子步骤:
步骤101:配置相机参数并批量采集乐器数据,并进行标注,标注方式为根据图像中手部的位置对手部的n个关键点标注x、y值,其中,n为关键点数量。
步骤102:对采集到的图像进行处理,生成估算x、y值。将批量的采集图像进行压缩,对压缩后的图像进行归一化操作,使用mobilenet深度卷积神经网络的进行特征提取生成特征图,使用平均池化层对特征图进行池化操作,利用对平均池化层生成值进行回归估算x、y值。
步骤103:计算所述估算x、y值与采集数据得到的x、y值的欧几里得距离。
步骤104:判断欧几里得距离是否小于指定阈值(在本实施例中,指定阈值设定为0.1)。如果欧几里得距离是否大于指定阈值,则顺序执行步骤105和步骤103,将把深度卷积神经网络的初始化参数减去缩小阈值(在本实施例中,缩小阈值设定为0.01),并重新计算欧几里得距离。如果所述欧几里得距离小于指定阈值,则执行步骤106,保存参数生成手部识别模型。
所述乐器识别模型的生成方法包括以下子步骤:
步骤111:配置相机参数并批量采集乐器数据,并进行标注,标注方式为采用矩形框表示物体位置,记录矩形框左上角xmin、ymin值和右下角xmax、ymax值。
步骤112:对标注的所述左上角xtl、ytl值与右下角xbr、ybr值分别利用x/width和y/height公式进行转换,生成左上角归一化值(xt1w、ytlh)与右下角归一化值(xbrw、ybrh),其中,width代表照片的宽,height代表照片的高。
步骤113:使用神经网络学习图像数据,生成估算(xmin、ymin)与(xmax、ymax)的向量值。将批量的采集图像进行压缩,对压缩后的图像进行归一化操作,使用mobilenet深度卷积神经网络的进行特征提取生成特征图,使用平均池化层对特征图进行池化操作,利用对平均池化层生成值进行回归向量值。
步骤114:计算所述估算(xmin、ymin)与(xmax、ymax)的向量值与采集数据得到的(xt1w、ytlh)与(xbrw、ybrh)的向量值的交叉熵。
步骤115:判断交叉熵是否小于指定阈值(在本实施例中,指定阈值设定为0.1)。如果交叉熵是否大于指定阈值,则顺序执行步骤105和步骤103,将把深度卷积神经网络的初始化参数减去缩小阈值(在本实施例中,缩小阈值设定为0.01),并重新计算交叉熵。如果交叉熵小于指定阈值,则执行步骤106,保存权重生成模型。
执行步骤120,将采集到的视频分别输入所述手部识别模型和所述乐器检测模型进行检测。启动所述采集装置,同时加载所述手部识别模型和所述乐器识别模型,将所述采集装置采集到的视频帧分别传输给所述手部识别模型和所述乐器识别模型。
执行步骤130,使用判断规则判断手部关键检点位置是否在所要识别的乐器位置当中。所述判断规则为判断以下公式是否为逻辑真值,如果是,则能够弹奏相应音符;如果不是,则不能够弹奏相应音符,其中,公式为[xmin≤xandx≤xmaxandymin≤yandy≤ymax]。
实施例二
如图2所示,一种手部检测追踪与乐器检测的结合交互系统,包括采集装置200、训练模块210和检测模块220。
采集装置200:用于采集视频和/或图像。
训练模块210:用于生成手部识别模型和乐器检测模型。所述手部识别模型的生成方法包括以下子步骤:
步骤101:配置相机参数并批量采集乐器数据,并进行标注,标注方式为根据图像中手部的位置对手部的n个关键点标注x、y值,其中,n为关键点数量。
步骤102:对采集到的图像进行处理,生成估算x、y值。将批量的采集图像进行压缩,对压缩后的图像进行归一化操作,使用mobilenet深度卷积神经网络的进行特征提取生成特征图,使用平均池化层对特征图进行池化操作,利用对平均池化层生成值进行回归估算x、y值。
步骤103:计算所述估算x、y值与采集数据得到的x、y值的欧几里得距离。
步骤104:当所述欧几里得距离小于指定阈值时(在本实施例中,指定阈值设定为0.1),保存参数生成手部识别模型。
所述乐器识别模型的生成方法包括以下子步骤:
步骤111:配置相机参数并批量采集乐器数据,并进行标注,标注方式为采用矩形框表示物体位置,记录矩形框左上角xmin、ymin值和右下角xmax、ymax值。
步骤112:对标注的所述左上角xtl、ytl值与右下角xbr、ybr值分别利用x/width和y/height公式进行转换,生成左上角归一化值(xt1w、ytlh)与右下角归一化值(xbrw、ybrh),其中,width代表照片的宽,height代表照片的高。
步骤113:使用神经网络学习图像数据,并生成估算(xmin、ymin)与(xmax、ymax)的向量值。将批量的采集图像进行压缩,对压缩后的图像进行归一化操作,使用mobilenet深度卷积神经网络的进行特征提取生成特征图,使用平均池化层对特征图进行池化操作,利用对平均池化层生成值进行回归估算(xmin、ymin)与(xmax、ymax)的向量值。步骤114:计算所述估算(xmin、ymin)与(xmax、ymax)的向量值与采集数据得到的(xt1w、ytlh)与(xbrw、ybrh)的向量值的交叉熵。
步骤115:当所述交叉熵小于指定阈值时(在本实施例中,指定阈值设定为0.1),保存权重生成模型。
检测模块220:用于将采集到的视频分别输入所述手部识别模型和所述乐器检测模型进行检测,并使用判断规则判断手部关键检点位置是否在所要识别的乐器位置当中。
检测模块220还用于启动所述采集装置,同时加载所述手部识别模型和所述乐器识别模型,将所述采集装置采集到的视频帧分别传输给所述手部识别模型和所述乐器识别模型。所述判断规则为判断以下公式是否为逻辑真值,如果是,则能够弹奏相应音符;如果不是,则不能够弹奏相应音符,其中,公式为[xmin≤xandx≤xmaxandymin≤yandy≤ymax]。
实施例三
本发明能够在ar的场景中,实现手部可以和实际的物体进行交互,并发出声音、动画等互动效果。实现方法如图3所示,技术方案如下:
一、手部检测方法(如图4所示)
1.手部检测和追踪;
2.手部与物体的检测和追踪。
3.配置相机参数保证采集照片大小480*480,批量采集乐器数据,并且进行标注。标注方式根据图像中手的位置对手21个关键点标注x、y值。
4.将批量采集图像压缩到256*256的尺寸,对压缩后的图像进行归一化操作,然后使用mobilenet深度卷积神经网络的进行特征提取生成特征图,然后使用平均池化层对特征图进行池化操作,利用对平均池化层生成值进行回归估算x、y值,然后对估算x、y值与采集数据的到的x、y欧几里得距离。
5.如果计算得到的欧几里得距离大于0.1,则把深度卷积神经网络的初始化参数减去0.01,不断的重复步骤4,直到欧几里得距离小于0.1则停止训练。
二、乐器检测方法(如图5所示)
6.配置相机参数保证采集照片大小640*640,批量采集乐器数据,并且进行标注。标注方式采用矩形框表示物体位置,左上角x、y值与右下角x、y值。
7.对标注的左上角x、y值与右下角x、y值利用x/width、y/height公式转换,其中width、height分别代表照片的宽、高。
8.将批量采集的图像缩放到320*320的尺寸,对压缩后的图像进行归一化操作,然后使用mobilenet深度卷积神经网络的进行特征提取生成特征图,然后使用平均池化层对特征图进行池化操作,利用对平均池化层生成值进行回归估算x、y值,然后对估算x、y值与采集数据的到的x、y交叉熵。
9.如果计算得到的交叉熵大于0.1,则把深度卷积神经网络的初始化参数减去0.01,不断的重复步骤8,直到交叉熵小于0.1则停止训练,保存权重生成模型文件。
10.app程序启动camera,同时加载手部识别模型和乐器检测模型,并且对camera采集的视频帧分别传输给手部检测和乐器检测。
11.利用返回的结果计算手部关键检点位置是否在所要识别的乐器位置当中。使用公式[xmin<=xandx<=xmaxandymin<=yandy<=ymax],其中(xmin、ymin、xmax、ymax分别表示乐器识别结果左上角x、y值和右下角x、y值),(x、y表示手部关键点x、y值)。如果手部关键点在所要识别的乐器位置当中,公式为逻辑真值,则认为可以弹相应音符。如果手部关键点不在所要识别的乐器位置当中,公式为逻辑假值,则认为不可以弹奏相应音符。
实施例四
如图6所示,手部和纸板乐器接触,通过乐器检测方法和手部检测方法将手部检测到的点位和纸板的点位融合,手部的点位在纸板乐器相应的区域里面时触发对应的音效,可以达到弹奏音乐的效果。
为了更好地理解本发明,以上结合本发明的具体实施例做了详细描述,但并非是对本发明的限制。凡是依据本发明的技术实质对以上实施例所做的任何简单修改,均仍属于本发明技术方案的范围。本说明书中每个实施例重点说明的都是与其它实施例的不同之处,各个实施例之间相同或相似的部分相互参见即可。对于系统实施例而言,由于其与方法实施例基本对应,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
- 还没有人留言评论。精彩留言会获得点赞!