确定模拟电路参数的处理方法、装置、设备及存储介质
本发明涉及集成电路设计技术领域,尤其涉及一种确定模拟电路参数的处理方法、装置、设备及存储介质。
背景技术:
目前大部分的模拟集成电路(简称模拟电路)由模拟集成电路工程师人工设计完成,人工设计模拟电路依赖于工程师的经验和直觉来选择合适的电路拓扑结构和器件参数、使用仿真器对模拟电路进行反复模拟和修正、手工绘制其物理版图等全部流程。随着集成电路技术的不断发展,电路器件特征尺寸在不断减小,对高性能、低功耗电路的需求也在不断增加,传统人工设计电路的方式变得越来越困难和低效,无法适应微电子工业的迅速发展,而模拟电路参数的设计对电路性能有着极其重要的影响,模拟电路参数设计的自动化将大大方便工程师的工作,提高设计生产率和设计精度,缩短产品的上市时间。
现有技术中,模拟电路参数自动化设计通常基于学习的方法来实现,主要是基于机器学习中的监督学习实现,通过建立电路性能指标(即输入)及对应的设计参数(即电路参数标签值)的数据集来训练网络,最后基于给定的电路性能指标对模拟电路参数进行预测,来确定模拟电路的参数。
但是,由于电路模拟速度慢,生成大规模的训练数据集非常耗时,因此,基于监督学习实现模拟电路参数自动化效率非常低。
技术实现要素:
本发明实施例提供一种确定模拟电路参数的处理方法、装置、设备及存储介质,以解决现有技术模拟电路参数自动化效率低的问题。
第一个方面,本发明实施例提供一种确定模拟电路参数的处理方法,包括:
获取目标模拟电路对应的目标指标;
根据所述目标指标,采用预先训练好的目标神经网络模型,确定所述目标模拟电路对应的目标设计参数,所述目标神经网络模型是基于强化学习的模型。
第二个方面,本发明实施例提供一种确定模拟电路参数的处理装置,包括:
获取模块,用于获取目标模拟电路对应的目标指标;
处理模块,用于根据所述目标指标,采用预先训练好的目标神经网络模型,确定所述目标模拟电路对应的目标设计参数,所述目标神经网络模型是基于强化学习的模型。
第三个方面,本发明实施例提供一种电子设备,包括:存储器、收发器及至少一个处理器;
所述处理器、所述存储器与所述收发器通过电路互联;
所述存储器存储计算机执行指令;所述收发器,用于接收输入设备发送的电路仿真输入文件;
所述至少一个处理器执行所述存储器存储的计算机执行指令,使得所述至少一个处理器执行如上第一个方面以及第一个方面各种可能的设计所述的方法。
第四个方面,本发明实施例提供一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机执行指令,当处理器执行所述计算机执行指令时,实现如上第一个方面以及第一个方面各种可能的设计所述的方法。
本发明实施例提供的确定模拟电路参数的处理方法、装置、设备及存储介质,采用基于强化学习框架的训练好的目标神经网络模型来确定模拟电路的设计参数,强化学习可以从零数据开始学习,与仿真器自动博弈,不断优化神经网络参数,获得新的训练数据逐步进行训练,获得训练好的目标神经网络模型,从而有效提高模拟电路参数自动化设计效率,解决现有技术训练数据集采集困难、耗时较长的问题。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一实施例提供的确定模拟电路参数的处理方法的流程示意图;
图2为本发明一实施例提供的内在奖励函数的实现结构示意图;
图3为本发明一实施例提供的确定模拟电路参数的处理装置的结构示意图;
图4为本发明一实施例提供的确定模拟电路参数的处理装置的一种示例性结构示意图;
图5为本发明一实施例提供的ocean脚本的部分代码的示例性示意图;
图6为本发明一实施例提供的电子设备的结构示意图。
通过上述附图,已示出本发明明确的实施例,后文中将有更详细的描述。这些附图和文字描述并不是为了通过任何方式限制本发明构思的范围,而是通过参考特定实施例为本领域技术人员说明本发明的概念。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
首先对本发明所涉及的名词进行解释:
skill语言:skill语言是cadence软件平台使用的一种语言,由lisp(listprocessinglanguage)发展而来,在cadence软件平台中,用户在图形界面做的任何操作,在底层都是通过调用相应的skill函数或者程序实现功能的,可以认为cadence软件平台上凡是可以通过图形界面实现的功能都可以使用相应的skill代码实现,对于图形界面不方便完成的操作也可以通过编写skill脚本完成。
ocean脚本:是基于字符界面的skill语言脚本,本发明中采用仿真器对模拟电路进行仿真,仿真器对动作值(即模拟电路的设计参数)的自动读取、自动仿真以及自动输出仿真结果均采用skill语言写成ocean脚本文件,在ocean脚本中可以直接通过仿真语句的命令行进行直流仿真、交流仿真、瞬态分析、参数扫描等操作,并把感兴趣的仿真结果写入文件中,形成闭合的联动过程。
ddgp算法:deepdeterministicpolicygradient,深度确定性策略梯度算法,在深度行为值神经网络的基础之上进行了扩展,由之前的离散动作空间扩展到现在的连续动作空间,这样在电路复杂度上升导致动作维度线性增加的情况下,动作的搜索空间不会指数型增加。
此外,术语“第一”、“第二”等仅用于描述目的,而不能理解为指示或暗示相对重要性或者隐含指明所指示的技术特征的数量。在以下各实施例的描述中,“多个”的含义是两个及两个以上,除非另有明确具体的限定。
下面这几个具体的实施例可以相互结合,对于相同或相似的概念或过程可能在某些实施例中不再赘述。下面将结合附图,对本发明的实施例进行描述。
本发明一实施例提供一种确定模拟电路参数的处理方法,用于自动化确定模拟电路的设计参数。本实施例的执行主体为确定模拟电路参数的处理装置,该装置可以设置在电子设备中,该电子设备可以是服务器或者其他可实现的计算机设备。
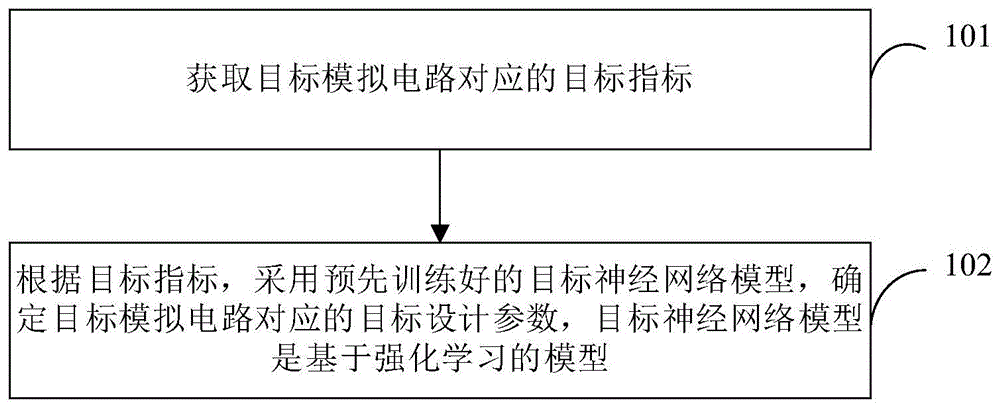
如图1所示,为本实施例提供的确定模拟电路参数的处理方法的流程示意图,该方法包括:
步骤101,获取目标模拟电路对应的目标指标。
具体的,目标模拟电路是具有给定拓扑结构的电路,目标指标是给定的电路性能指标,目的是在给定拓扑结构和电路性能指标的情况下,快速精确地确定目标模拟电路的电路器件参数(即目标设计参数),要确定目标模拟电路对应的目标设计参数,需要基于目标指标实现,因此要先获取目标模拟电路对应的目标指标。
目标指标可以是预先写入相应的输入文件中,在需要确定目标模拟电路对应的目标设计参数时,从相应的输入文件中读取获得,也可以是实时通过输入设备输入获得,具体可以根据实际需求设置,本实施例不做限定。
目标指标可以包括给定的目标直流工作点、目标功耗、目标增益、目标截止频率、目标相位裕度、目标输入噪声、目标建立时间等指标中的一种或多种,具体可以根据实际需求设置。
步骤102,根据目标指标,采用预先训练好的目标神经网络模型,确定目标模拟电路对应的目标设计参数,目标神经网络模型是基于强化学习的模型。
具体的,目标神经网络模型是基于强化学习的模型,可以从零数据开始学习,与仿真器自动博弈,不断优化神经网络参数,获得新的训练数据逐步进行训练,获得训练好的目标神经网络模型。
获得目标神经网络模型后,则可基于目标神经网络模型及给定的目标模拟电路的目标指标预测目标模拟电路的设计参数(即目标设计参数)。
目标设计参数可以包括获得的mos管的目标沟道宽度、目标沟道长度、目标电阻值、目标电容值、目标偏置电压等参数中的一种或多种,具体可以根据实际需求设置。
可选地,目标神经网络模型可以基于深度确定性策略梯度算法训练获得,也可以是基于其他算法训练获得,具体可以根据实际需求设置,本实施例不做限定。
示例性的,基于深度确定性策略梯度算法进行训练,可以对预先建立的神经网络进行初始化,清空经验回放池,并随机生成初始状态值,基于初始状态值及初始化后的神经网络,采用深度确定性策略梯度算法进行步数迭代训练,获得第一神经网络模型作为目标神经网络模型。
深度确定性策略梯度算法使用了经验回放池模块,该模块存储着每一步的学习数据,供后续的采样利用,在学习过程中,可以随机抽取一些之前的经验进行学习,经验回放池模块可以打乱经验之间的相关性,也使得神经网络的更新更有效率,有利于跳出局部最优点,加快整个算法的收敛性;深度确定性策略梯度算法使用了actor-critic的神经网络架构,共有4个网络,分别为actor当前网络、actor目标网络、critic当前网络及critic目标网络,其中,actor当前网络是策略网络,负责策略网络参数的迭代更新,根据当前时刻的状态值(本发明中即仿真获得的指标值)计算最优的当前时刻动作值(即预测的当前时刻的电路参数),actor目标网络的参数则基于actor当前网络参数进行软更新获得,根据经验回放池中采样的下一时刻状态值选择最优的下一时刻动作值;critic当前网络为价值网络,负责价值网络参数的迭代更新,根据当前时刻的状态值和当前时刻的动作值计算当前时刻的行为函数值;critic目标网络的参数则基于critic当前网络参数软更新获得,根据经验回放池中采样的下一时刻状态以及由actor目标网络得到的动作值,来计算目标行为函数值;深度确定性策略梯度算法采用的双actor神经网络和双critic神经网络架构,在实现单步更新,提高学习效率的同时,解决了actor-critic难收敛的问题。
本实施例提供的确定模拟电路参数的处理方法,采用基于强化学习框架的训练好的目标神经网络模型来确定模拟电路的设计参数,强化学习可以从零数据开始学习,与仿真器自动博弈,不断优化神经网络参数,获得新的训练数据逐步进行训练,获得训练好的目标神经网络模型,从而有效提高模拟电路参数自动化设计效率,解决现有技术训练数据集采集困难、耗时较长的问题。
为了使本发明的技术方案更加清楚,本发明另一实施例对上述实施例提供的方法做进一步补充说明。
为了提高强化学习的学习效率,作为一种可实施的方式,在上述实施例的基础上,可选地,在根据目标指标,采用预先训练好的目标神经网络模型,确定目标模拟电路对应的目标设计参数之前,该方法还包括:
对预先建立的神经网络进行初始化,清空经验回放池,并随机生成初始状态值,神经网络包括actor当前网络、critic当前网络、actor目标网络和critic目标网络;基于初始状态值及初始化后的神经网络,采用深度确定性策略梯度算法进行步数迭代训练,获得第一神经网络模型;将第一神经网络模型作为目标神经网络模型。
具体的,目标神经网络模型需要预先训练获得,为了提高强化学习的学习效率,本发明采用深度确定性策略梯度ddgp算法进行步数迭代训练,实现从零数据开始学习,不断优化神经网络参数,获得最终的目标神经网络模型。
由于ddgp算法采用了经验回放池,在初始化神经网络时,除了对预先建立的神经网络参数进行初始化,还要清空经验回放池,在步数迭代时,需要初始化状态值,作为actor当前网络最初的输入,从而进入步数迭代过程。
可选地,初始状态值可以由reset模块随机生成。
通过采用深度确定性策略梯度算法进行训练,在实现单步更新,提高学习效率的同时,还可以解决actor-critic难收敛的问题。
可选地,对预先建立的神经网络进行初始化,包括:采用预设随机函数初始化actor当前网络的参数θ和critic当前网络的参数ω,令actor目标网络的参数θtarget等于θ,critic目标网络的参数θtarget等于ω。
相应地,基于初始状态值及初始化后的神经网络,采用深度确定性策略梯度算法进行步数迭代训练,获得第一神经网络模型,包括:
针对第t步,执行以下步骤:
(1)将当前t时刻状态值st输入actor当前网络,获得预测的t时刻最优动作值at,初始状态值作为t=1时刻状态值;(2)将t时刻最优动作值at作为目标模拟电路的参数值进行仿真,获得t+1时刻状态值st+1;(3)基于t+1时刻状态值st+1及预设奖励函数确定t时刻最优动作值at对应的即刻奖励值rt;(4)基于即刻奖励值rt确定终止状态值is_endt;(4)将五元组(st,at,rt,st+1,is_endt)存入到经验回放池;(5)从经验回放池随机采样n个五元组(sj,aj,rj,sj+1,is_endj),j=1,2,…,n;(6)基于预设l损失函数将critic当前网络的参数ω更新为ω′,并基于预设j损失函数将actor当前网络的参数θ更新为θ′,获得更新后的critic当前网络和更新后的actor当前网络;(7)基于θ′对actor目标网络的参数θtarget进行软更新,并基于ω′对critic目标网络的参数ωtarget进行软更新,获得更新后的actor目标网络和更新后的critic目标网络;(8)根据预设条件判断是否结束迭代,若否,则进入t+1步,若是,则结束迭代,获得第一神经网络模型。
具体的,强化学习部分可以通过强化学习智能体实现,奖励函数部分通过奖励函数生成模块实现,强化学习智能体及奖励函数生成模块为分别与仿真器互相通信的功能模块,强化学习智能体与奖励函数生成模块之间也相互通信,具体的功能模块划分还可以根据实际需求按其他划分方式进行划分,这里以强化学习智能体、奖励函数生成模块及仿真器为例进行说明,奖励函数生成模块、仿真器、上述的reset模块等,组成强化学习的环境,强化学习的智能体与环境交互,通过与仿真器的自动博弈实现不断的迭代学习,优化网络参数。
针对第t步,也即在t时刻,强化学习智能体将t时刻状态值输入到神经网络(初始状态值作为t=1时刻状态值),作为actor当前网络的输入,actor当前网络根据t时刻状态值获得t时刻最优动作值,发送给仿真器,仿真器将t时刻最优动作值作为目标模拟电路的参数进行仿真,获得t+1时刻状态值st+1,并发送给奖励函数生成模块及强化学习智能体,奖励函数生成模块基于t+1时刻状态值st+1及预设奖励函数确定t时刻最优动作值at对应的即刻奖励值rt,并发送给强化学习智能体,强化学习智能体根据即刻奖励值确定终止状态值is_endt,并将五元组(st,at,rt,st+1,is_endt)存入到经验回放池,强化学习智能体从经验回放池随机采样n个五元组(sj,aj,rj,sj+1,is_endj),j=1,2,…,n,根据这n个五元组(sj,aj,rj,sj+1,is_endj)及预设损失函数对critic当前网络和actor当前网络的参数进行更新,获得更新后的critic当前网络和更新后的actor当前网络,进一步基于更新后的critic当前网络的参数对critic目标网络的参数进行软更新,获得更新后的critic目标网络,基于更新后的actor当前网络的参数对actor目标网络的参数进行软更新,获得更新后的actor目标网络;根据预设条件判断是否结束迭代具体为基于最大步数t及终止状态值is_endt判断是否结束步数迭代,具体的,若当前迭代步数达到最大步数限制(即t>t)或者终止状态值is_endt=1,则确定结束迭代步数,终止状态值可以根据即刻奖励值来确定,若即刻奖励值rt大于奖励阈值r,则is_endt=1,否则is_endt=0,若判断不结束步数迭代,则进入t+1步,按照上述步骤执行,以此类推,直至结束步数迭代,获得第一神经网络模型。
可选地,奖励函数可以采用任意可实施的函数,本实施例不做限定。
示例性的,奖励函数可以采用ki*xi的加总形式,
为了解决因电路仿真无结果导致奖励函数稀疏性的问题,作为另一种可实施的方式,可选地,基于t+1时刻状态值st+1及预设奖励函数确定t时刻最优动作值at对应的即刻奖励值rt,包括:
基于t+1时刻状态值st+1及外在奖励函数,确定外在奖励值rtw;基于t+1时刻状态值st+1、t时刻最优动作值at、t时刻状态值st及内在奖励函数,确定内在奖励值rtn;基于外在奖励值rtw和内在奖励值rtn确定即刻奖励值rt。
具体的,为了解决因电路仿真无结果导致奖励函数稀疏性的问题,引入内在奖励函数机制,将上述的
外在奖励值结合内在奖励值rtn,获得最终的即刻奖励值,内在奖励值基于t+1时刻状态值st+1、t时刻最优动作值at、t时刻状态值st获得。
通过采用外在奖励与内在奖励结合的奖励机制共同引导学习过程,减少了稀疏奖励现象,从而加快收敛速度。
可选地,为了进一步加快收敛速度,基于t+1时刻状态值st+1、t时刻最优动作值at、t时刻状态值st及内在奖励函数,确定内在奖励值rtn,包括:
将t时刻最优动作值at及t时刻状态值st输入到第一神经网络,获得t+1时刻预测状态值
具体的,内在奖励采用内在好奇心模块实现,内在好奇心模块主要由一个神经网络(为了区分称为第一神经网络)构成,如图2所示,为本实施例提供的内在奖励函数的实现结构示意图,其中,
可选地,基于外在奖励值rtw和内在奖励值rtn确定即刻奖励值rt,包括:
将外在奖励值和内在奖励值之和作为即刻奖励值rt,即:
rt=rtw+rtn
为了进一步提高目标神经网络模型的预测效果,在一种实施方式中,在基于初始状态值及初始化后的神经网络,进行步数迭代训练,获得第一神经网络模型之后,该方法还包括:对第一神经网络模型再次进行至少一轮的步数迭代训练,获得第二神经网络模型。
相应的,将第一神经网络模型作为目标神经网络模型,包括:将第二神经网络模型作为目标神经网络模型。
具体的,为了避免一轮的步数迭代得到的神经网络模型效果较差的情况出现,保证获得的目标神经网络效果,可以进行多轮的步数迭代,每轮进行多步的更新优化,在完成第一轮的优化,结束步数迭代后,获得第一神经网络模型,第二轮在第一神经网络模型的基础上继续进行优化,从初始化状态值开始新一轮的步数迭代,具体步数迭代过程与第一轮一致,在此不再赘述,以此类推,后一轮在前一轮获得的神经网络模型的基础上继续进行步数迭代优化训练,直至达到最大轮数限制。
通过多轮的训练优化,每一轮经过多步迭代,提高训练获得的目标神经网络模型的预测效果,从而提高确定的电路设计参数的准确性。
可选地,在训练获得目标神经网络模型后,对于同一拓扑结构的模拟电路,若目标指标变化,仍可以采用该目标神经网络模型经过少量步数迭代即可获得最终预测的设计参数。
为了更加清楚地说明本发明的技术方案,下面以一示例性的实施方式对本发明的整体流程进行详细说明,整体流程具体如下:
1、采用随机函数初始化actor当前网络的参数θ和critic当前网络的参数ω,同时令actor目标网络的参数θtarget等于θ,critic目标网络的参数ωtarget等于ω,并清空经验回放池;
2、在每一个轮回m(即一轮)开始后,先由环境的reset模块随机生成初始状态值s1,状态值可以包括直流工作点、功耗、增益、截止频率、相位裕度、输入噪声、建立时间等中的至少一个。
3、进入每个轮回的步数迭代,针对第t(t=1,2,…,t,t为最大步数)步具体如下:
(1)获取第t状态值st作为actor当前网络的输入,得到actor当前网络预测的最优动作值at,动作值可以包括mos管的沟道宽度、沟道长度和电阻值、电容值、偏置电压等中的至少一种。
(2)读取最优动作值at,作为电路需要设计的参数值进行仿真,获得下一时刻新的状态值st+1;并通过外在奖励函数和内在奖励函数得到动作值at对应的即刻奖励值rt;
其中,外在奖励函数为:
其中,i=1,2,…,n,n为指标个数,ki为(0,1)区间的值,即表示第i个指标对应的权重系数,ki可以根据实际需求设置,speci表示第i个指标的目标值(即第i个目标指标),outi表示第i个指标对应的仿真结果,也即outi为仿真获得的st+1中第i个元素,也即st+1=[out1,…,outn];对于第i个指标,若希望该指标的仿真结果比目标值越大越好(比如增益),则
内在奖励函数采用内在好奇心模块实现,具体为根据t时刻动作值at、t时刻状态值st及仿真器获得的t+1时刻状态值st+1获得内在奖励值rtn:
具体的,内在好奇心模块将t时刻动作值at、t时刻状态值st作为第一神经网络的输入,获得第一神经网络预测的输出值
基于即刻奖励值rt确定终止状态值is_endt,终止状态值可以根据即刻奖励值来确定,若即刻奖励值rt大于奖励阈值r,则is_endt=1,否则is_endt=0,奖励阈值r可以根据实际需求设置。
(3)将获取到的(st,at,rt,st+1,is_endt)五元组存入到经验回放池的存储集合d。
(4)从经验回放池的存储集合d中采样n个五元组(sj,aj,rj,sj+1,is_endj),j=1,2,…,n。
(5)基于采样的n个五元组,采用预设l损失函数对critic当前网络的参数ω求梯度,l损失函数如下:
其中,
其中,γ为衰减因子,atarget(sj+1|θtarget)表示actor目标网络基于第j组采样(五元组)的下一时刻状态值sj+1做出的最优动作值的预测值,q()为critic当前网络的输出行为函数,q(sj,aj|ω)表示critic当前网络根据输入(sj,aj)在参数ω状态下获得的输出结果,qtarget(sj+1,atarget(sj+1|θtarget)|ωtarget)表示critic目标网络根据输入sj+1,atarget(sj+1|θtarget)在参数ωtarget状态下的输出结果,atarget(sj+1|θtarget)表示actor目标网络根据输入sj+1在参数θtarget状态下获得的输出结果(即actor目标网络根据j+1时刻状态值sj+1获得的最优动作值)。
(6)基于步骤(5)获得的梯度通过神经网络的梯度反向传播来更新critic当前网络的参数ω,获得更新后的参数ω′。
(7)基于采样的n个五元组,采用预设j损失函数对actor当前网络的参数θ求梯度,j损失函数如下:
其中,q(sj,aj(sj|θ)|ω′)表示critic当前网络根据输入(sj,aj(sj|θ))在参数ω′状态下获得的输出结果,aj(sj|θ)表示actor当前网络根据输入sj在参数θ状态下获得的输出结果。
(8)基于步骤(7)的梯度通过神经网络的梯度反向传播来更新actor当前网络的参数θ,获得更新后的参数θ′。
需要说明的是,在实际应用中,对θ的更新过程与对ω的更新过程可以不分先后顺序,也即上述步骤(5)-(6)与步骤(7)-(8)不分先后顺序,既可以先执行(5)-(6),也可以先执行(7)-(8),还可以同时执行,具体可以根据实际需求设置,那么,在先执行(7)-(8)时,j损失函数中用到的critic当前网络的参数为ω。
(9)对actor目标网络的参数θtarget和critic目标网络的参数ωtarget进行软更新:
θtarget′=τ*θ′+(1-τ)*θtarget
ωtarget′=τ*ω′+(1-τ)*ωtarget
其中,τ为软更新系数,可以根据实际需求设置。
(10)基于最大步数t及终止状态值is_endt判断是否跳出步数迭代,若是,则结束本轮步数迭代,否则进入t+1步,循环上述步骤(1)-(9),以此类推,直至迭代步数达到最大步数限制t或者is_endt满足要求,结束步数迭代,在t+1步,将t步更新后的网络参数作为t+1步的当前网络参数,即将t步更新获得的θ′作为t+1步的θ,将t步更新获得的ω′作为t+1步的ω,将t步更新获得的θtarget′作为t+1步的θtarget,将t步更新获得的ωtarget′作为t+1步的ωtarget。
4、判断当前轮数m是否大于最大轮回数m,若是,则结束轮回循环,否则当前轮回数m加1进入下一轮,返回迭代步骤2-3,以此类推,直至轮回数达到最大轮回数m限制,获得最终的目标神经网络模型。
5、将给定的目标模拟电路的目标指标作为目标神经网络模型的输入,获得目标模拟电路的目标设计参数,采用目标设计参数获得设计好的目标模拟电路。
需要说明的是,本实施例中各可实施的方式可以单独实施,也可以在不冲突的情况下以任意组合方式结合实施本发明不做限定。
本实施例提供的确定模拟电路参数的处理方法,通过采用深度确定性策略梯度算法进行训练,在实现单步更新,提高学习效率的同时,还可以解决actor-critic难收敛的问题;还通过采用外在奖励与内在奖励结合的奖励机制共同引导学习过程,减少了稀疏奖励现象,从而加快收敛速度;还通过多轮的训练优化,每一轮经过多步迭代,提高训练获得的目标神经网络模型的预测效果,从而提高确定的电路设计参数的准确性。
本发明再一实施例提供一种确定模拟电路参数的处理装置,用于执行上述实施例的方法。
如图3所示,为本实施例提供的确定模拟电路参数的处理装置的结构示意图。该装置30包括:获取模块31和处理模块32。
其中,获取模块,用于获取目标模拟电路对应的目标指标;处理模块,用于根据目标指标,采用预先训练好的目标神经网络模型,确定目标模拟电路对应的目标设计参数,目标神经网络模型是基于强化学习的模型。
具体的,获取模块可以从预先存储的输入文件中或者相应的存储区域获取目标模拟电路对应的目标指标,也可以是相关人员通过输入设备实施输入,获取模块通过输入设备获取目标指标,具体可以根据实际需求设置。获取模块获取到目标指标后,发送给处理模块,处理模块将目标指标输入到目标神经网络模型,获得目标模拟电路对应的目标设计参数。
可选地,该装置模块的划分还可以根据其他方式划分,具体可以根据实际需求设置,比如上述的强化学习智能体、仿真器、奖励函数生成模块、reset模块等,各模块的具体功能参见前述内容,在此不再赘述。
关于本实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,且能够达到相同的技术效果,此处将不做详细阐述说明。
为了使本发明的装置更加清楚,本发明又一实施例对上述实施例提供的装置做进一步补充说明。
为了提高强化学习的学习效率,作为一种可实施的方式,在上述实施例的基础上,可选地,处理模块,还用于:
对预先建立的神经网络进行初始化,清空经验回放池,并随机生成初始状态值,神经网络包括actor当前网络、critic当前网络、actor目标网络和critic目标网络;基于初始状态值及初始化后的神经网络,采用深度确定性策略梯度算法进行步数迭代训练,获得第一神经网络模型;将第一神经网络模型作为目标神经网络模型。
可选地,处理模块具体还可以包括初始化子模块和训练子模块,初始化子模块用于对预先建立的神经网络进行初始化,清空经验回放池,并随机生成初始状态值,初始化子模块将初始化后的神经网络及初始状态值发送给训练子模块,训练子模块用于基于初始状态值及初始化后的神经网络,采用深度确定性策略梯度算法进行步数迭代训练,获得第一神经网络模型,将第一神经网络模型作为目标神经网络模型。
可选地,初始化子模块具体用于:采用预设随机函数初始化actor当前网络的参数θ和critic当前网络的参数ω,令actor目标网络的参数θtarget等于θ,critic目标网络的参数ωtarget等于ω。
相应地,训练子模块具体用于:针对第t步,执行以下步骤:
将当前t时刻状态值st输入actor当前网络,获得预测的t时刻最优动作值at,初始状态值作为t=1时刻状态值;将t时刻最优动作值at作为目标模拟电路的参数值进行仿真,获得t+1时刻状态值st+1;基于t+1时刻状态值st+1及预设奖励函数确定t时刻最优动作值at对应的即刻奖励值rt;基于即刻奖励值rt确定终止状态值is_endt;将五元组(st,at,rt,st+1,is_endt)存入到经验回放池;从经验回放池随机采样n个五元组(sj,aj,rj,sj+1,is_endj),j=1,2,…,n;基于预设l损失函数将critic当前网络的参数ω更新为ω′,并基于预设j损失函数将actor当前网络的参数θ更新为θ′,获得更新后的critic当前网络和更新后的actor当前网络;基于θ′对actor目标网络的参数θtarget进行软更新,并基于ω′对critic目标网络的参数ωtarget进行软更新,获得更新后的actor目标网络和更新后的critic目标网络;根据预设条件判断是否结束迭代,若否,则进入t+1步,若是,则结束迭代,获得第一神经网络模型。
为了解决因电路仿真无结果导致奖励函数稀疏性的问题,训练子模块具体用于:
基于t+1时刻状态值st+1及外在奖励函数,确定外在奖励值rtw;基于t+1时刻状态值st+1、t时刻最优动作值at、t时刻状态值st及内在奖励函数,确定内在奖励值rtn;基于外在奖励值rtw和内在奖励值rtn确定即刻奖励值rt。
可选地,训练子模块,具体用于:
将t时刻最优动作值at及t时刻状态值st输入到第一神经网络,获得t+1时刻预测状态值
可选地,训练子模块,具体用于:将外在奖励值和内在奖励值之和作为即刻奖励值rt。
为了进一步提高目标神经网络模型的预测效果,在一种实施方式中,处理模块,还用于:对第一神经网络模型再次进行至少一轮的步数迭代训练,获得第二神经网络模型;将第二神经网络模型作为目标神经网络模型。
如图4所示,为本实施例提供的确定模拟电路参数的处理装置的一种示例性结构示意图,该确定模拟电路参数的处理装置包括强化学习智能体和奖励函数生成模块,还可以包括仿真器。
其中,actor中的优化器用于求解对actor当前网络参数θ的梯度及对actor当前网络参数θ的更新,critic中的优化器用于求解对critic当前网络的参数ω的梯度及对critic当前网络参数ω的更新,actor当前网络根据输入的t时刻状态值st获得预测的t时刻最优动作值at,并发送给仿真器,仿真器将t时刻最优动作值at作为目标模拟电路的参数值进行仿真,获得t+1时刻状态值st+1,并发送给奖励函数生成模块及强化学习智能体,奖励函数生成模块基于t+1时刻状态值st+1及预设奖励函数确定t时刻最优动作值at对应的即刻奖励值rt,并发送给强化学习智能体,强化学习智能体根据即刻奖励值确定终止状态值is_endt,并将五元组(st,at,rt,st+1,is_endt)存入到经验回放池,强化学习智能体从经验回放池随机采样n个五元组(sj,aj,rj,sj+1,is_endj),j=1,2,…,n,根据这n个五元组(sj,aj,rj,sj+1,is_endj)及预设损失函数对critic当前网络和actor当前网络的参数进行更新,获得更新后的critic当前网络和更新后的actor当前网络,进一步基于更新后的critic当前网络的参数对critic目标网络的参数进行软更新,获得更新后的critic目标网络,基于更新后的actor当前网络的参数对actor目标网络的参数进行软更新,获得更新后的actor目标网络;基于最大步数t及终止状态值is_endt判断是否结束步数迭代。
其中,仿真器对动作值(即模拟电路的设计参数)的自动读取、自动仿真以及自动输出仿真结果均采用skill语言写成ocean脚本文件,在ocean脚本中可以直接通过仿真语句的命令行进行直流仿真、交流仿真、瞬态分析、参数扫描等操作,并把感兴趣的仿真结果写入文件中,形成闭合的联动过程。
示例性的,如图5所示,为本实施例提供的ocean脚本的部分代码的示例性示意图。
需要说明的是,本实施例中各可实施的方式可以单独实施,也可以在不冲突的情况下以任意组合方式结合实施本发明不做限定。
关于本实施例中的装置,其中各个模块执行操作的具体方式已经在有关该方法的实施例中进行了详细描述,且能够达到相同的技术效果,此处将不做详细阐述说明。
本发明再一实施例提供一种电子设备,用于执行上述实施例提供的方法。该电子设备可以是服务器或其他可实现的计算机设备。
如图6所示,为本实施例提供的电子设备的结构示意图。该电子设备50包括:存储器51、收发器52及至少一个处理器53。
其中,处理器、存储器与收发器通过电路互联;存储器存储计算机执行指令;收发器,用于接收输入设备发送的电路仿真输入文件;至少一个处理器执行存储器存储的计算机执行指令,使得至少一个处理器执行如上任一实施例提供的方法。
具体的,针对给定的电路拓扑结构,预先准备对应的电路仿真输入文件,该电路仿真输入文件用于描述需要仿真的目标模拟电路的拓扑结构及其他相关信息,用于训练过程中的仿真。篡改电路仿真输入文件可以是通过输入设备发送给电子设备进行存储备用,在进行电路参数自动化设计时,处理器从存储器读取并执行相应的计算机执行指令,基于电路仿真输入文件,实现如上任一实施例提供的方法。
本发明是电子设备可以应用于任意给定电路拓扑结构及目标指标的模拟电路参数设计场景。
需要说明的是,本实施例的电子设备能够实现上述任一实施例提供的方法,且能够达到相同的技术效果,在此不再赘述。
本发明又一实施例提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机执行指令,当处理器执行计算机执行指令时,实现如上任一实施例提供的方法。
需要说明的是,本实施例的计算机可读存储介质能够实现上述任一实施例提供的方法,且能够达到相同的技术效果,在此不再赘述。
在本发明所提供的几个实施例中,应该理解到,所揭露的装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,所述单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。
本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本发明旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本发明未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由下面的权利要求书指出。
应当理解的是,本发明并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求书来限制。
- 还没有人留言评论。精彩留言会获得点赞!