一种SAR图像目标检测方法与流程
本发明属于图像处理
技术领域:
,特别是指一种sar图像目标检测方法。
背景技术:
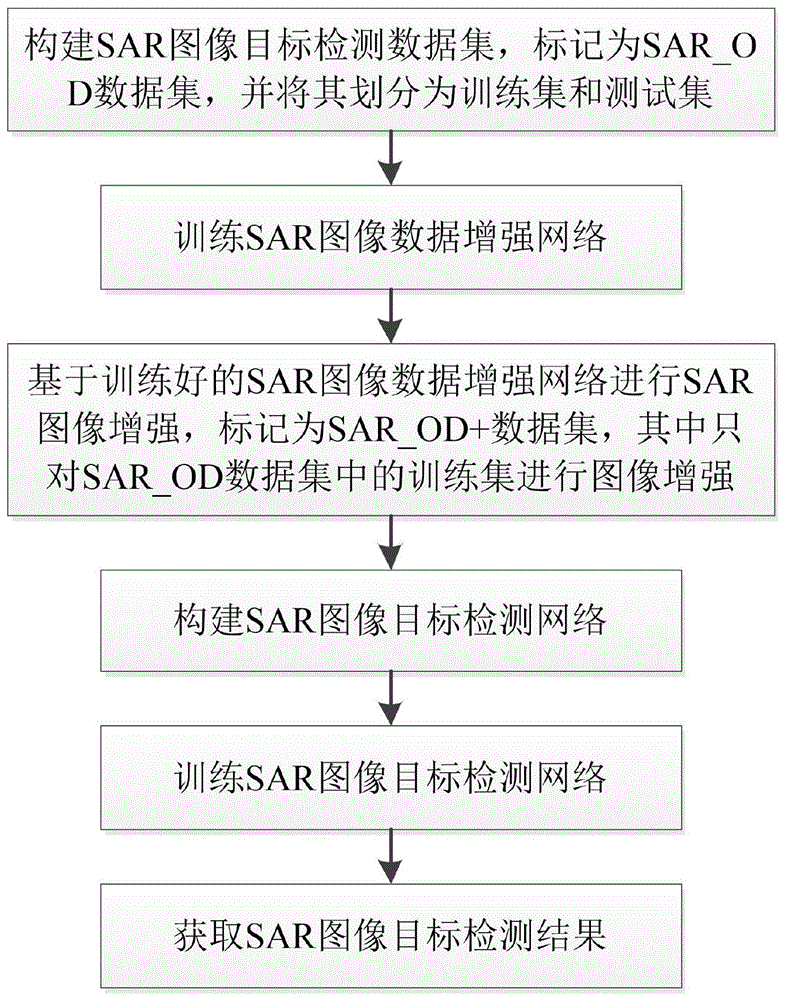
:常见的卷积神经网络拥有数以百万计体量的参数,训练这些参数使得模型有更好的评价效果,是需要数量庞大的训练数据来支撑的。而在实际情况中,遥感图像的数据量有限,获取新的图像数据并人工标注又需要大量的成本。所以通常情况下,利用数据增强技术,即利用已经存在的数据通过各种方法创造出更多的数据成为首要选择。常规的数据增强方法有:(1)平移:将图像中的所有像素点沿着水平方向或者垂直方向移动,也可以两个方向都移动。需要注意的是平移后图像会空出一部分区域,应该按照数据的实际情况选择填充方式;(2)裁剪:随机选中图像中的某一部分进行裁剪,通常将这一部分放大至原图大小;(3)旋转:将图像进行顺时针或逆时针旋转,当旋转任意角度(非180度)时需要将空出的位置进行填充;(4)翻转:将图像进行水平翻转或者垂直翻转;(5)缩放:将图像放大或缩小一定比例,图像放大后通常需要裁减至原尺寸,缩小后选择适当方式进行填充;(6)添加噪声:在图片中随机加入噪声,常见的有高斯噪声等;(7)颜色变换:在图片上增加或者减少某些颜色的分量等。除了上述常规方法外,一些学者也致力于通过合成图像的方式进行数据增强,例如smote,samplepairing,mixup等。其中samplepairing是随机将训练集中的两张图片经过常规的数据增强(翻转、裁剪、旋转等)后像素以取平均值的形式合成一个新的样本,标签为原始图片的标签之一,该方法对于医学图像的分类任务较为常用。mixup方法为将训练图片与随机选定的图片按照一定的比例融合,生成新的图片。此外,也有研究人员通过生成对抗网络(generativeadversarialnetworks,gan)来生成新样本以扩充数据集。在图像分类研究中,数据增强使用很常见,在目标检测领域,由于有目标位置的限制,通常采用常规的数据增强方式,也有学者通过将真实的分割对象粘贴到图像中进行数据增强。进行数据增强时需要注意增强后的图片应与原图片类似,否则会影响训练效果。技术实现要素:本发明在现有技术的基础上,提出了一种sar图像目标检测方法,能够得到更好的目标检测结果。为实现上述目的,本发明采用的技术方案为:一种sar图像目标检测方法,其特征在于,包括如下步骤:步骤1,构建sar图像目标检测数据集sar_od,并将其划分为训练集和测试集;步骤2,训练sar图像数据增强网络;步骤3,基于训练好的sar图像数据增强网络对sar_od中的训练集进行增强,增强后的sar图像目标检测数据集为sar_od+;步骤4,构建sar图像目标检测网络;步骤5,使用sar_od+训练sar图像目标检测网络;步骤6,基于训练好的sar图像目标检测网络进行sar图像目标检测。进一步的,步骤1的具体方式为:1a)选取sar数据集中的多类目标,目标大小为n×n像素;1b)从包含目标的各sar图片中提取目标,提取时将阴影的信息一并提取出来并单独保存;1c)对于从sar数据集中的训练集图片中所提取出的目标,将其与场景图像合成,合成后的图像划入sar_od的训练集中;对于从sar数据集中的测试集图片中所提取出的目标,将其与场景图像合成,合成后的图像划入sar_od的测试集中。进一步的,步骤2的具体方式为:2a)将sar_od数据集中不同场景下的图片进行切片,得到切片图像,切片图像的大小为n×n像素;2b)对切片图像进行划分,若切片图像中没有目标和其他物体,则将该切片图像作为可以放置新目标的背景图,否则作为无法放置新目标的背景图;2c)将切片图像及其划分结果作为训练集输入到cnn模型进行训练,得到用于判断切片图像能否放置新目标的判别模型。进一步的,步骤3的具体方式为:3a)在每一待增强图像上以滑窗方式生成90~120个不重叠的候选框,候选框大小为n×n像素;3b)对于每一待增强图像,将候选框部分的图像送到步骤2c)中训练好的判别模型中,获得该候选框区域可放置新目标的置信度;3c)对于每一待增强图像,按照置信度对候选框进行排序,选择置信度高于0.95的候选框,并在其中放置步骤1a)中所选取的目标,每个候选框中放置目标的类别随机选择,每张图像中最多放置5个目标;3d)将增强后的图像与原训练集中的图像合并,得到sar_od+的训练集,sar_od+的测试集与sar_od的测试集相同。进一步的,所述步骤4中的sar图像目标检测网络为fasterr-cnn网络,其包括锚框生成层、区域生成层、roi池化层以及分类层。本发明与现有技术相比具有如下优点:1、本发明基于数据增强网络对sar图像进行数据增强,基于fasterr-cnn对sar图像进行目标检测,经过数据增强的数据有助于得到更好的目标检测结果。2、本发明利用场景分类数据集构建了目标检测数据集,有助于构建更多的目标检测数据集。3、本发明提出的数据增强方法简单、高效,可以使数据集数量直接扩充一倍,而且目标丰富度显著提高。附图说明图1是本发明实施例中目标检测方法的流程图。图2是mstar数据集8类目标提取后图像。图3是sar_od数据集部分图像与真实标记图像对比图。图4是基于卷积神经网络的sar图像数据增强原理示意图。图5是sar_od数据集部分图像数据增强前后对比图。图6是部分sar图像目标检测与识别结果图。具体实施方式以下结合附图对本发明的技术方案作进一步的详细描述。参照图1,一种sar图像目标检测方法,其具体实现步骤如下:步骤1,构建sar图像目标检测数据集,标记为sar_od数据集,并将其划分为训练集和测试集,具体步骤如下:1a)如图2所示,选取mstar数据集中的8类目标进行数据集制作,分别为装甲运输车(btr70_snc71、btr60),步兵战车(bmp2_sn9563),坦克(t62、t72_sn132),装甲侦察车(brdm2),自行榴弹炮(2s1),推土机(d7)。1b)将每张含有目标的大小128×128像素图片的目标提取出来,因为目标检测过程中,每个目标的阴影部分也会包含一定的信息,所以要将阴影的信息一并提取出来单独保存;1c)将提取出来的mstar数据集中的训练集与测试集的目标分别与场景图像合成,其中由mstar训练集的目标与场景图像合成的图像划分为sar_od数据集中的训练集,由mstar测试集的目标与场景图像合成的图像划分为sar_od数据集中的测试集,由于场景图像中可能含有树林、湖泊、建筑物等,检测的目标出现在这些位置是不合理的,所以合成过程中避开了这些位置;步骤2,训练sar图像数据增强网络,网络原理如图4所示,具体操作方式为:将sar_od数据集中不同场景下的图片进行切片,根据mstar数据集中车辆目标的大小选择切片大小为128×128像素,将切片图像分类成可以放置新目标的背景图和无法放置新目标的背景图(有目标、树木等其他物体的切片图像),将这些切片图像作为训练集输入到cnn模型(vgg19模型)进行训练得到判别模型,图4中较粗的矩形框代表可以放置新目标的背景图区域,较细的矩形框代表无法放置新目标的背景图区域,在可以放置新目标的背景图区域放置了新目标,在最终得到的数据增强图像中可以体现。步骤3,基于训练好的sar图像数据增强网络进行sar图像增强,标记为sar_od+数据集,其中只对sar_od数据集中的训练集进行图像增强,sar图像增强可以分为候选框选取、特征提取判别和生成图像三部分,具体操作方式如下:3a)候选框选取:生成约100个候选框,候选框的选取通过滑动窗口的方式。根据提取出来的sar图像军事车辆目标的大小,选取候选框大小为128×128像素,选取的候选框不能有重叠,这样可以避免生成新的图片时目标重叠。3b)特征提取判别:将选定的候选框送到训练好的卷积神经网络模型中,进行特征提取与判别,判断候选区域是否可以放置新的目标。3c)生成图像:对于可以放置新目标的候选框,将其分类的置信度按由大到小的顺序排序。依次选取置信度高于0.95的候选框放置步骤1a)中所述的目标,其中放置目标的类别随机选择,最多放置5个。由于mstar数据集中的目标大小比较固定,放置目标时不进行缩放,将目标放置到候选框的中心位置。步骤4,构建sar图像目标检测网络,其中,目标检测网络为fasterr-cnn网络,其包括锚框生成层、区域生成层、roi池化层以及分类层。步骤5,训练sar图像目标检测网络,按照如下方式进行:5a)使用sar_od数据集的训练集对目标检测网络进行训练,并将训练好的模型标记为fasterr-cnn1;5b)使用sar_od+数据集的训练集对目标检测网络进行训练,并将训练好的模型标记为fasterr-cnn2。步骤6,获取sar图像目标检测结果,按照如下方式进行:6a)使用fasterr-cnn1模型对sar_od数据集的测试集进行测试,并将测试结果保存为result1;6b)使用fasterr-cnn2模型对sar_od+数据集的测试集进行测试,并将测试结果保存为result2;sar_od数据集与sar_od+数据集的测试集是一致的,因此两个测试结果可以直接比较。目标检测与识别任务中常用的评价指标为平均精度(averageprecision,ap)与均值平均精度(meanaverageprecision,map)。map为各类目标的检测的平均精度的均值。计算平均精度需要交并比(intersectionoverunion,iou),精确率(precision),召回率(recall)等指标。iou计算的是模型预测出来的边框与真实边框之间的交集与并集之间的比值,如公式所示,代表预测边框,代表真实边框。当预测边框与真实的边框完全重合时iou=1,完全不重合时iou=0,iou代表了预测边框与真实边框的重合程度。计算精度和召回率的时候,需要用到几个评价指标:真正例(truepositive,tp)、真反例(truenegative,tn)、假正例(falsepositive,fp)、假反例(falsenegative,fn)。tp代表正确地被分为正样本,fp代表错误地被分为正样本,tn表示正确地被分为负样本,fn表示错误地被分为负样本,所有的预测框的总数计为s,则tp+fp+tn+fn=s。通过iou计算出预测框与真实框的重合程度,设定阈值(通常为0.5),当iou大于阈值的时候,认定该预测框为正样本。精确率代表的是所有正样本之中分类正确的比例,召回率指的是所有实际是正样本中被检测出来的正样本的比例。公式如下:精确率越高代表检测出来的正样本更准确,召回率越高代表更多的正样本被检测出来,精确率和召回率是一个相互矛盾的指标,用单一的精确率或召回率都无法真正代表目标检测与识别模型的质量。通过改变识别到目标置信度的阈值,会得出不同的精确率和召回率,阈值越高,精确率增高同时召回率降低,通过这种方式可以画出p-r(precision-recall)曲线。用p-r曲线的面积代表目标检测与识别中的平均精度。如果一个目标检测与识别的模型效果好,就会在召回率增高的时候,精确率依然保持在一个较高的水平,这时模型的ap和map就会较高。以下为一个更具体的实施例:本实施例采用的深度学习框架为keras,sar图像目标检测与识别算法采用的深度学习框架为pytorch,程序运行的操作系统为ubuntu18.04lts,显卡为nvidia公司的geforcegtx1080。mstar数据集8类目标提取后图像如图2所示。sar_od数据集中每张图片含有的目标数量统计如表1所示,其中num_train、num_test分别代表训练集、测试集中含有相应目标数量的图片数量。共合成了220张训练图像,200张测试图像,大部分sar图像上的目标个数为9~12个,当场景图片较为复杂的时候目标数量较少,部分场景图片可重复利用。训练集所有sar图像总计有2149个目标,测试集所有sar图像总计有1877个目标。sar_od数据集部分图像与真实标记图像对比图如图3所示。表1sar_od数据集图片目标数量统计sar_od数据集部分图像数据增强前后对比图如图5所示,进行数据增强后的sar_od+训练集和sar_od训练集每张图片含有的目标数量统计如表2所示,通过数据增强后将训练数据集图片数量扩充了一倍,数据增强后的sar_od+训练集中所有sar目标个数总计为5330个,有效地增加了数据量。本发明数据增强不对sar_od数据集中的测试集进行数据增强,因此sar_od数据集与sar_od+中的测试集保持一致。表2sar_od和sar_od+训练集图片目标数量统计对比目标数量(个)345678910sar_od(张)1014218861sar_od+(张)2027516495目标数量(个)11121314151617总计sar_od(张)511010000220sar_od+(张)5612748864510440对本发明提出的数据增强方法进行实验验证,本发明采用fasterr-cnn为基础网络,对本发明制作的sar_od数据集与进行数据增强后的sar_od+数据集分别训练网络进行目标检测与识别任务对比实验效果。同时为了验证在数据量更少的情况下,数据增强的效果,将每个数据集的50%作为训练集进行实验。由表3所示,sar_od+数据集相较于原始数据集sar_od,评价指标map均得到了明显的提升,通过本发明数据增强方法得到的sar_od+数据集相较于原始数据集map提升7.5,并且在各个类别的平均精度(ap)和map的指标上均取得了最好的效果,尤其在平均精度较差的bmp2_sn9563和btr60有明显提升。sar_od+数据集训练的模型部分图像目标检测与识别结果如图6所示,其中,(a)列为原始图像,(b)列为真实标注图像,(c)列为检测结果图像。表3不同数据集基于fasterr-cnn目标检测结果由表4所示,在将训练数据减半的实验中,sar_od+相较于原始数据集sar_od训练的模型map提升12.9提升效果更加显著,并且在分类较差的2s1,bmp2_sn9563,btr60和btr70_snc71四类车辆目标平均提升20.8。实验证明,当数据量少的时候,通过本发明提出的基于卷积神经网络的数据增强方法可以有效增加数据量,提升目标检测与识别的平均精度。表4不同数据集50%训练数据基于fasterr-cnn目标检测与识别结果当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1