一种基于OTD_Loglogistic的SAR数据海洋目标检测方法
本发明属于海洋目标检测领域,具体涉及一种基于otd_loglogistic的sar数据海洋目标检测方法。
背景技术:
近年来,神经网络已应用在海洋目标检测上,但在应用时深度神经网络存在维数灾难的缺陷,会降低检测速度。平静的海面海洋杂波可以近似运用高斯模型建模,然而在风浪、潮汐等复杂海况下,sar后向散射概率分布出现长尾,不再符合高斯分布。传统cfar算法基于sar数据中海杂波服从高斯分布的假定,但在复杂海况中,海杂波分布极其复杂,此假定不具有科学性和普遍性。而且,cfar需要逐一统计图像中的像素,计算耗费长,滑动窗口无法对图像边缘的像素进行处理,会造成边缘处漏检的缺陷。
技术实现要素:
为了解决上述问题,本发明提出了一种基于otd_loglogistic的sar数据海洋目标检测方法,采用基于深度学习模型的初检和基于loglogistic的cfar精检相结合的方法,克服了现有技术的不足,提高了海洋目标检测效率和精度。
本发明的技术方案如下:
一种基于otd_loglogistic的sar数据海洋目标检测方法,采用基于深度学习模型的初检和基于loglogistic的cfar精检相结合的检测方法,首先,构建oceantda9轻量级深度学习模型,采用所构建的轻量级深度学习模型进行海洋目标初检,在此基础上采用基于loglogistic模型的cfar方法进行海洋目标精细检测,提取海洋目标特征。
优选地,oceantda9模型包含4个卷积层、1个卷积组和3个全连接层;每个卷积层的组织形式是convolution2d-relu-dropout-maxpooling;卷积组的组织形式是(convolution2d-relu-dropout)*2-maxpooling;3个全连接层中,前两个全连接层的组织形式是dense-relu-dropout,最后一个全连接层的组织形式是dense。
优选地,oceantda9模型的训练过程为:
s101.对海洋目标样本特征数据x进行归一化处理,采用的归一化公式如下:
其中,μ为特征的期望,σ为方差;
s102.配置训练优化算法、损失函数、监控参数;
s103.加载数据集,验证数据的合法性;
s104.将数据集分为多个周期,每个周期分为多个批次;
s105.将每个周期按批次打混索引,进行批次循环;
s106.计算交叉熵,采用反向传播算法和所改进的梯度下降算法winr-adagrad,以0.01的学习速率不断地修改变量以最小化交叉熵;
s107.对批次指定的样本数进行训练,学习权重、偏置,计算损失、精度直到一个周期的批次都循环结束,再进入下一个周期进行批循环;
s108.直到循环完所有周期,保存模型及训练损失、精度。
优选地,oceantda9模型损失函数采用目标分类和模型预测分类之间的交叉熵,其公式为:
式中,y-i是第i个样本的输入值,hθ(xi)是第i个样本x的输出值,参数θ0的初值设置为0.1,θ1的初值设置为标准差为0.1的正态分布浮点数。
优选地,海洋目标精细检测采用loglogistic概率密度函数来拟合复杂海况的海杂波分布,突出海杂波的长尾特征,在此基础上采用cfar方法进行海洋目标特征提取。
优选地,海洋目标精细检测的原理和过程为:
s201.计算初检保存在数组x中每个像素的频数绘制直方图;
s202.提取直方图中最小像素到最大像素间有效像素及对应的频数作为拟合数据并保存到数组x2、y2中;
s203.调用loglogistic复杂海况的海洋杂波概率密度函数式
求出拟合曲线的α、β参数;
s204.计算拟合优度,包括卡方和绝对值误差;
s205.计算拟合曲线有效像素的积分
s206.调用目标检测模型pixelsval>xtb,将疑似目标保存到数组row2中;
s207.对数组row2图像窗口中疑似目标像素聚簇,并保存各个目标簇的参数,包括目标簇中心坐标、长度、宽度、像素总数及倾斜角。
本发明所带来的有益技术效果:
通过构建的轻量级卷积神经网络——oceantda9,对海洋硬目标进行初检,克服了深度神经网络的维数灾难,提高了海洋图像中目标检测的速度;对复杂海况海杂波进行建模,采用loglogistic分布拟合复杂海况海杂波的分布,拟合效果更好,突出了海杂波的长尾分布特征,并基于loglogistic模型采用cfar进行海洋目标特征提取,提高了精度;
采用基于深度学习的海洋目标初检和基于loglogistic的cfar方法精简相结合的方式,克服了滑动窗口cfar需要逐一统计图像中的像素计算耗费长、无法对图像边缘的像素进行处理造成边缘处漏检等缺陷,提高了海洋目标的检测效率和精度。
附图说明
图1是本发明轻量级深度学习模型oceantda9的结构图;
图2是本发明oceantda9模型训练流程图;
图3是本发明海洋目标精检流程图;
图4是本发明基于otd_loglogistic的海洋目标检测流程图;
图5是本发明多核并行otd_loglogistic目标并行检测cpu-t图。
具体实施方式
下面结合附图以及具体实施方式对本发明作进一步详细说明:
一、轻量级深度学习模型构建
1、oceantdax系列模型构建
在构建轻量级深度学习模型时,首先设计了轻量级卷积神经网络模型oceantdax系列,oceantdax系列包括4种模型,分别为oceantda2、oceantda4、oceantda9、oceantda16。初步实验oceantda9模型检测效果最好。
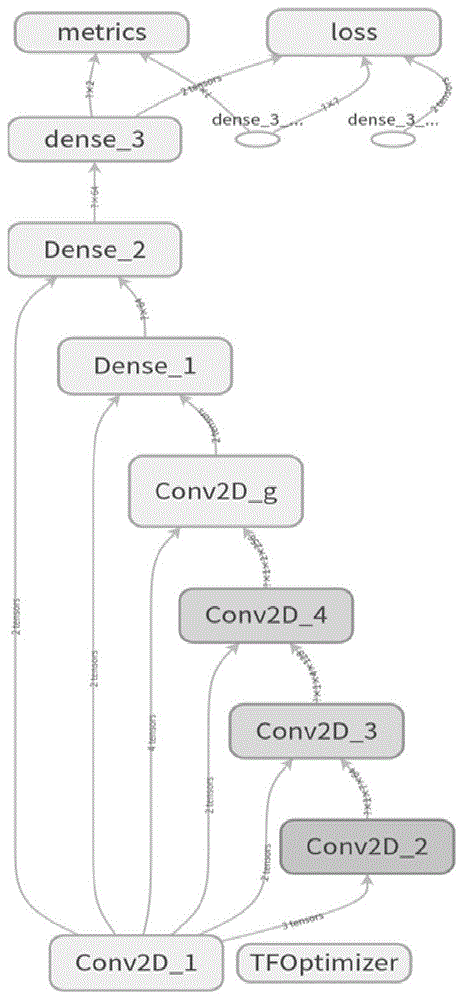
oceantda9模型的结构如图1所示,包含4个卷积层、1个卷积组和3个全连接层,前4个卷积层分别为conv2d_1、conv2d_2、conv2d_3、conv2d_4,每个卷积的形式一样,都是convolution2d-relu-dropout-maxpooling;中间1个卷积组是conv2d_g,组织形式是(convolution2d-relu-dropout)*2-maxpooling;最后3个是密集全连接dense层,分别为dense_1、dense_2、dense_3,其中前两个dense,每组都是dense-relu-dropout,最后一个全连接dense层仅有dense。
卷积过程是使用一个卷积核w,在每层像素矩阵x上不断按滑动步长stride扫描下去,每次扫到的数值x会和卷积核w中对应位置的数值进行相乘,然后与偏值b相加求和,生成一个新的矩阵xw+b。卷积核w相当于卷积操作中的一个过滤器,用于提取图像的特征,特征提取后会得到一个特征图。卷积核w里面的每个值就是训练模型过程中的神经元参数,即权重,训练开始时赋予w随机的初始值,训练网络过程中,网络会通过后向传播不断更新这些参数值,通过loss损失函数来评估参数值,直到取得最佳的参数值。oceantda9模型开始输入的是长28个像素、宽28个像素的单通道图像,卷积核的大小是3×3,滑动步长stride的大小为2。
oceantda9模型中的卷积层和全连接层的激活函数都使用relu(rectifiedlinearunits,整流线性单元)激活函数,relu激活函数应用非饱和激活函数f(x)=max(0,x),增加了决策函数和整个网络的非线性特性,而不影响卷积层的感受野。其他函数也可以用来增加非线性,例如饱和双曲正切函数f(x)=tanh(x),f(x)=|tanh(x)|和sigmoid函数f(x)=(1+e-x)-1。与其它激活函数相比,采用relu激活函数的训练神经网络速度快几倍,而且对泛化精度没有显著影响。
oceantda9模型在训练过程中,按照一定的比例将网络中的神经元进行丢弃,可以防止模型训练过拟合的情况。oceantda9模型中dropout都设置成0.2。
卷积操作后提取到的特征信息,相邻区域会有相似特征信息,如果全部保留这些特征信息会存在信息冗余,增加计算难度。通过池化可将这些相似特征信息相互替代,不断减小数据的空间大小,参数的数量和计算量会有相应的下降,这在一定程度上控制了过拟合。池化操作相当于降维操作,有最大池化(maxpooling)和平均池化,根据海洋目标检测特点,oceantda9模型采用核尺寸为2×2,滑动步长stride为2的maxpooling,每次池化操作后,矩阵的长宽都降低一半。
flatten将池化后的数据拉开,变成一维向量来表示,方便输入到全连接网络。oceantda9模型卷积、池化后,经flatten平整化后为一维512个特征的向量,进入全连接层。
oceantda9模型最后做3层dense全连接层,特征由512个神经元维压缩到64个,relu又接dropout0.2过渡,并再次用一个包含64个神经元的全连接dense作为缓冲后进入全连接层dense进一步压缩到2个神经元输入损失函数loss层中的softmax进行分类。
损失函数层(losslayer)用于决定训练过程如何来“惩罚”网络的预测结果和真实结果之间的差异,它通常是网络的最后一层。不同类型的任务采用不同的损失函数,softmax交叉熵损失函数常常被用于在k个类别中选出一个,而sigmoid交叉熵损失函数常常用于多个独立的二分类问题,欧几里德损失函数常常用于结果取值范围为任意实数的问题。oceantda9模型确定损失函数采用目标分类和模型预测分类之间的交叉熵,其公式为:
式中,y-i是第i个样本的输入值,hθ(xi)是第i个样本x的输出值,即yi。参数θ0的初值设置为0.1,θ1的初值设置为标准差为0.1的正态分布浮点数。
对oceantdax系列的4种模型进行对比实验,分别得到损失与批次的相关性曲线、精度与批次的相关性曲线。oceantda9模型训练次数为275000次,每次100个样本图像,模型训练到150000次左右接近拐点,随后损失下降缓慢,此时损失是0.02左右,耗时13982秒,最后50次模型损失均值是0.0131,标准差是0.00007;oceantda16模型训练次数也是275000次,其它2个模型的训练次数设置为550000次。模型训练开始时波动较大,随着时间推移,模型损失波动逐渐减少。从损失与批次相关性曲线可以看出损失下降由慢到快依次是2层、4层、16层和9层的oceantdax模型,综合效果表现最好的是9层模型oceantda9。再比较模型精度,从oceantdax系列模型训练精度相关性曲线中可以看出9层模型oceantda9训练精度为0.9973,训练精度最好。综合损失和精度,模型oceantda9检测效果最好,所以本发明最终选择oceantda9模型对海洋目标进行初检。
2、oceantda9模型训练
首先,要对样本数据x进行特征归一化处理。样本特征的取值范围不同,这可能导致迭代较慢,为了避免此弊端,需要对特征数据进行归一化处理。采用的归一化公式如下:
其中,μ为特征的期望,σ为方差。这样特征的新期望为0,新方差为1,迭代次数可以大大加快。
然后,本发明已确定训练的损失函数为目标分类和模型预测分类之间的交叉熵,采用反向传播算法和所改进的梯度下降算法winr-adagrad,以0.01的学习速率不断地修改变量以最小化交叉熵。模型具体训练流程如图2所示,训练的关键点在于存在回调函数。回调函数callbacks.on_train_begin()在训练开始时调用,指定logs保存的目录,callbacks.on_epoch_begin()在每个周期开始时调用,记录本次epoch的历史信息,在每个周期的循环中,主要是对每个epoch进行循环,其中核心针对每个batch的处理,按照batch批次打混索引,得到一个批次的索引后,进入batch批次循环。回调函数callbacks.on_batch_begin()的logs包含size,即当前batch的样本数,batch批次循环对指定的样本数进行训练,学习权重、偏置,计算损失、精度等。
模型训练好后,就可调用evaluate()方法在测试数据集上测试评估模型的性能。
loss,accuracy=model.evaluate(x_test,y_test)
evaluate()方法验证数据的有效性后,首先采用tf.argmax()预测正确的标签,tf.argmax()能返回在一个张量里沿着某条轴的最高条目的索引值,例如tf.argmax(y_ocean,1)是模型认为每个输入最有可能对应的那些标签,而tf.argmax(y_,1)代表正确的标签。然后用tf.equal来检测模型预测是否与真实标签匹配,一般函数会返回一组布尔值,为了确定正确预测项的比例,可以把布尔值转换成浮点数,然后取平均值。损失采用分类交叉熵的平均值做为每个批次的总损失。
correct_prediction=tf.equal(tf.argmax(y_ocean,1),tf.argmax(y_,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
categorical_crossentropy=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_,logits=y_ocean))
evaluate()返回模型配置时需要返回的损失loss和精度accuracy,可将这些简要信息保存到文件中,通过可视化软件进行可视化,以便利用这些简要信息进一步评估模型。同时训练脚本会为所有学习变量计算其移动均值,评估脚本则直接将所有学习到的模型参数替换成对应的移动均值,这一替代方式可以在评估过程中改善模型的性能。
采用改进优化算法winr-adagrad的9层oceantda9模型,学习速率设置为0.01,间隔距离tn设置为10,修正系数delta设置为0.6,训练8250次后的模型,对测试数据集的10000个样本图像进行测试,损失为0.0766,精度为99.83%,用时3.345秒。
模型训练好后,通过gfile()方法将模型保存成pb(protocolbuffers)格式的文件,便于海洋硬目标检测时调用。
二、基于oceantda9模型的海洋目标初检
为了进一步验证本发明oceantda9模型的优越性,分别对oceantda9、oceantdvgg、oceantdcnn模型进行海洋目标初检实验,得到损失_批次、精度_批次的关系曲线。oceantda9模型训练结束时损失是0.0625,精度为0.9996,耗时687秒,最后50次模型损失均值是0.2091,标准差是0.00029,精度平均值为0.9214,标准差为0.00015;oceantdvgg模型训练结束时损失是0.0563,精度为0.9985,耗时1244秒,最后50次模型损失均值是0.2101,标准差是0.00032,精度平均值为0.9212,标准差为0.00015;oceantdcnn模型训练结束时损失是0.0896,精度为0.9898,耗时540秒,最后50次模型损失均值是0.1930,标准差是0.00027,精度平均值为0.9284,标准差为0.00019。
所构建的oceantda9模型训练后共检测到钻井平台疑似目标90个。目标漏检数为0个,检出率为100%,虚警率为10.9%,用时2.36秒,sar图像检测能力约58.5km2/s。满足无漏检并保持10%左右的虚警率的检测需求。
三、基于loglogistic分布的海洋背景建模
平静的海面海洋杂波可以近似用高斯模型建模,然而在风浪、潮汐等复杂海况下,sar后向散射概率分布出现长尾,不再符合高斯分布。对研究海域海洋杂波分布情况进行实验和分析,得到复杂海况的海洋杂波概率密度分布。鉴于海洋杂波的概率密度函数具有较重的长尾,本发明首次将loglogistic(对数逻辑)分布函数用于拟合复杂海况海洋杂波。loglogistic的概率密度函数(probabilitydensityfunction,pdf)如下式所示,x>0,α>0,β>0。
对数逻辑分布的累积分布函数(cumulativedistributionfunction,cdf)如下式所示:
实验表明,loglogistic概率分布与复杂海况的海洋杂波概率密度拟合优度较高。所以,本发明采用对数逻辑分布对复杂海况的海洋杂波进行建模,基于此进行海洋目标的提取。
采用深度学习模型对28*28像素区域进行10次检测,得到疑似目标和非疑似目标,非疑似目标可视为背景。然后,统计直方图及得到loglogistic拟合曲线,经loglogistic统计模型拟合的海洋杂波得到最佳拟合曲线,在像素值233前积分达99.5%,极值像素255的概率值为0.0395,像素总数为28*28*8,图像的分辨率是13.89米*13.89米,极值像素255可达13.89米*13.89米*28*28*8*0.0395=47797.77m2。所以,仅从概率分布上很难确定47797.77m2的极值像素255是否为目标。
通过多次实验验证,取α=98.151,β=3.6501的对数逻辑模型作为海洋杂波拟合模型,此时拟合优度卡方值ks=0.5908,p=1,可以认为观测值和预期值是拟合的。对应的标准差σ=0.0032,绝对误差me=0.00198。
实验研究表明,采用tb=generalizedextremevaluepdffitokss(labb,labtb,rowb)或tb=mb+σab*t都是基于统计模型,统计模型缺乏空间特征,必须结合聚类等操作,通过空间连通性来确定疑似像素点是否为目标点。最终,对海洋杂波长度介于50.0-600.0米的簇聚类,得到检测因子的检测结果。
四、基于loglogistic模型的海洋目标精检测
为了改进双参数cfar逐窗口检测、计算量大的缺陷,采用基于深度学习oceantda9模型进行初检,再采用loglogistic模型进行目标精检测,提取海洋目标特征。计算初检保存在数组x中每个像素的频数绘制直方图,提取直方图中最小像素到最大像素间有效像素及对应的频数做为拟合数据并保存到数组x2、y2中,调用loglogistic复杂海况的海洋杂波概率密度函数式(3)拟合x2、y2,求出拟合曲线的α、β参数值并计算卡方、绝对值误差等拟合优度。利用下式计算拟合曲线有效像素的积分,当积分值达到阈值时,输出临界像素xtb。
调用目标检测模型pixelsval>xtb,将3*3图像窗口中疑似目标保存到数组row2中。对row2中的28*3行、28*3列图像窗口中疑似目标像素聚簇并保存各个目标簇的参数,包括目标簇的中心坐标等。具体检测流程如图3所示:(1)对行和列均为28*3的图像窗口中疑似目标像素聚簇并保存各个簇的参数;(2)当满足最小宽度和最大长度纵横比时,目标直线拟合提取目标长度、宽度及倾斜角;(3)当满足实际纵横比时进行目标椭圆拟合;(4)保存目标中心坐标、长度、宽度、像素总数及倾斜角;(5)当所有疑似目标检测完毕后结束。
采用loglogistic模型共提取海洋目标12个,得到编号为7032的提取目标的相关参数可视化结果。提取的钻井平台长13.89*36.0米,宽13.89*15.0米,面积约13.89*13.89*302平方米。该图像所在九宫格的像素均值为116.75,有3个疑似目标子图像,6个海杂波子图像,海杂波像素平均值为116.66,标准差为64.01,基于loglogistic的海洋目标检测的分割阈值为232,九宫格中像素值大于分割阈值的点数百分比为8.89%。提取目标中心轴拟合直线表达式为y=0.01x+32.50,九宫格中矩形拟合中心(50.00,33.00),长36.0像素,宽15.0像素,斜率-0.019,长宽比2.39。待检图像中椭圆拟合参数中心(2206.0,341.0),长轴中心线斜率-0.019,长半轴17.99像素,短半轴7.51像素,椭圆包含像素总数302.0个。
五、初检和精检结合的海洋目标检测实验
采用oceantda9初检和基于loglogistic的cfar精检相结合的检测方法——otd_loglogistic进行海洋目标检测实验,实验采用并行分布式构架进行,流程如图4所示。图5是双机16核cpu并行计算,0-15核cpu随机分配1-3个任务,最先完成任务的cpu用时3秒,最后完成任务的cpu用时约33秒。主节点的cpu显示第一幅疑似目标的时间是在程序运行3秒或2秒时显示的,其它工作节点第一幅疑似目标分别是在程序运行2、1、2、1或2时显示的。
双机16核otd_loglogistic海洋目标参数并行提取各节点cpu任务执行状态如表1所示。
表1双机多核otd_loglogisticcpu任务执行状态
按照上述otd_loglogistic海洋目标检测方法,对研究海域采用并行算法进行实验,得到28*28图像中的非疑似目标、疑似目标和目标。聚类后采用28*28图像中长度大于250米、小于1500米,目标纵横比<=10去虚警。
本发明通过采用oceantda9初检和基于loglogistic的cfar精检相结合的检测方法,克服了滑动窗口cfar需要逐一统计图像中的像素计算耗费长、无法对图像边缘的像素进行处理造成边缘处漏检等缺陷,可以有效提高海洋目标的检测效率和精度。
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!