中文古籍字符识别、组段与版面重建方法、介质和设备
本发明涉及中文古籍研究技术领域,特别涉及一种中文古籍字符识别、组段与版面重建方法、介质和设备。
背景技术:
随着深度学习的研究与发展,基于计算机视觉的图像文本检测、识别技术在日常生活、商业活动和科学研究中发挥着越来越重要的作用,并取得了不错的进展,研究成果涉及文档识别、票据识别和特定场景文字识别。但是,现存的研究仅是针对字迹清晰、背景对比明显、字符类别有限的文本图像,其字符分布遵循自左向右、自上而下的现代排版风格,对于字符类别庞大、版面风格迥异、字符排布遵循自上而下、自左向右的古籍文档识别的研究工作存在欠缺,例如,在页面污损残破、墨迹退化、存在生僻字的中华古籍善本数字化工作中,精确地检测单字符位置,再对字符进行识别,并将字符识别结果重组为文本列。
事实上,在传统的基于现代排版风格的文本检测、识别方法中,一种典型的投影分析法是将文档图像沿竖直方向压缩成一维向量,并根据一维向量所构成的波形图中的波谷位置来确定相邻文本行的界限,再逐一地对完成分割的文本行进行字符识别。但中文古籍文档中存在图标、印章和双列注释等特殊元素,传统的文本行检测算法或仅关注单行文字等简单版面,不适用于版面结构复杂、内容多样的古籍文档。同时,中文古籍文档存在手写、异体或生僻字型,而专注于常用印刷体汉字识别的传统算法或仅能处理有限类别的字符,不能准确地识别这些不常见的特殊字符,这导致传统算法在古籍文档识别中存在错判、遗漏等劣势。此外,目前缺少字符类别覆盖面广、字体风格多样的古籍文档数据集,现存古籍文档图像数据集标注数据中字符类别分布不均。
技术实现要素:
本发明的第一目的在于克服现有技术的缺点与不足,提供一种中文古籍字符识别方法,该方法不仅能够识别出常见的字符,而且还能够非常准确的识别出古籍中的一些不常见的特殊字符,克服现有技术中古籍文档识别存在错判、遗漏等问题。
本发明的第二目的在于提供一种中文古籍字符组段方法,该方法有效减少了运算资源的开销。
本发明的第三目的在于提供一种中文古籍文档版面重建方法,该方法能够得到字符识别准确、句读清晰、符合现代阅读系统的版面重建后的文本识别结果,有效提高了古籍文档版面重建的准确性。
本发明的第四目的在于提供一种存储介质。
本发明的第五目的在于提供一种计算设备。
本发明的第一目的通过下述技术方案实现:一种中文古籍字符识别方法,包括如下步骤:
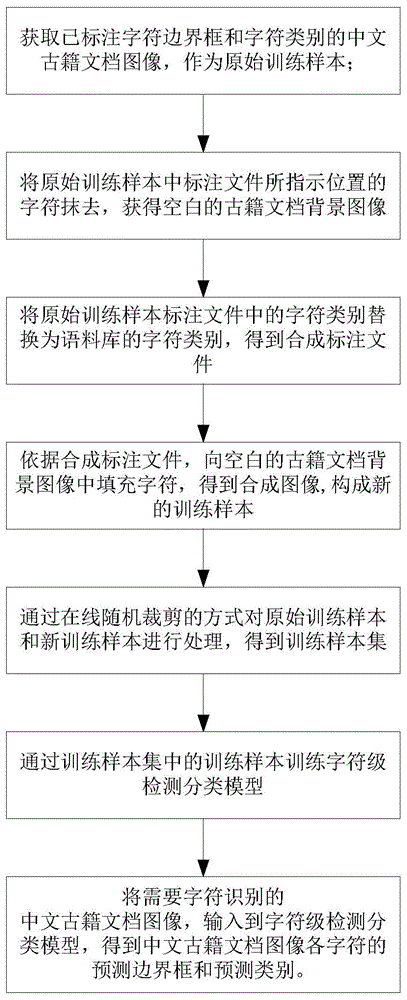
获取已标注字符边界框和字符类别的中文古籍文档图像,作为原始训练样本;同时获取原始训练样本的标注文件;
随机选取多个原始训练样本,并进行如下处理:
将原始训练样本中标注文件所指示位置的字符抹去,获得空白的古籍文档背景图像;
将原始训练样本标注文件中的字符类别替换为语料库的字符类别,得到合成标注文件;
依据合成标注文件,向空白的古籍文档背景图像中填充字符,得到合成图像;
通过上述合成图像和合成标注文件形成新的训练样本;
通过在线随机裁剪的方式对原始训练样本和新训练样本进行处理,得到训练样本集;
通过训练样本集中的训练样本训练字符级检测分类模型;
针对要识别字符的中文古籍文档图像,将其输入到字符级检测分类模型,通过字符级检测分类模型得到中文古籍文档图像各字符的预测边界框和预测类别。
优选的,通过在线随机裁剪的方式对原始训练样本和新训练样本进行处理,得到训练样本集的具体过程如下:
针对于各原始训练样本和各新训练样本,将其作为输入图像,每次数据加载过程均使用随机数生成函数,生成随机尺寸与位置的裁剪区域坐标信息;
利用裁剪区域坐标信息对输入图像样本进行裁切,并将因裁切操作而破碎的字符边界框标注信息剔除;
将在线随机裁切的图像样本拉伸至宽度为x像素、高度为y像素的区域,并对该区域内的字符边界框做线性变换,将上述线性变换后的图像样本作为训练样本,构成训练样本集;
训练得到字符级检测分类模型的具体过程如下:
将训练样本集中训练样本及其标注文件分别对应作为二阶段目标检测网络的训练样本与监督数据,进行有监督训练,获得用于检测中文古籍文档字符边界框、识别字符类别的字符检测分类模型。
优选的,针对要识别字符的中文古籍文档图像,通过字符级检测分类模型得到中文古籍文档图像各字符的预测边界框、预测类别和预测置信率,然后使用重叠抑制算法过滤相同位置、不同类别的字符,获得基于视觉的古籍文档字符级预测结果,具体如下:
预测字符边界框执行自上而下、自左向右的空间排序;
将竖直方向间距小于字符平均宽度t倍的字符归为一组,统计该字符组内相邻字符的交并比iou,提取该组内交并比大于阈值的所有字符,组成重叠字符数组;
针对于重叠字符数组,以字符预测置信率为条件进行降序排序,将置信率最高的字符判定为该位置预测字符,剔除重叠字符数组内其余所有字。
本发明的第二目的通过下述技术方案实现:一种中文古籍字符组段方法,包括如下步骤:
针对于获取到的中文古籍文档图像,通过本发明第一所述的方法获取到其中各字符的预测边界框和预测类别;
将各字符的预测边界框按照古籍阅读顺序及字符语义句群进行组段聚类与阅读顺序恢复,获得无标点符号的古籍文本内容。
优选的,字符组段聚类与阅读顺序恢复算法过程,具体步骤如下:
s1、以各字符的预测边界框为输入,按照古籍阅读顺序习惯对其进行空间排序,并计算字符边界框的几何特征信息;
s2、根据相邻字符边界框的几何特征信息,判断它们是否位于同列,以实现单个字符的组段聚类;
s3、针对中文古籍文档图像进行版线检测,使用版线对应当分属上下版面的字符竖列进行切分,获得语义合理的字符竖列数组;
s4、利用古籍阅读习惯、古籍版面风格先验知识,将步骤s3中所得的字符竖列进行拼接,实现古籍阅读顺序的恢复。
更进一步的,步骤s1的具体过程如下:
s1a、将各字符的预测边界框按照自右向左、自上而下的古籍阅读顺序进行空间二维排序;
s1b、统计古籍文档图像中所有预测字符边界框的平均面积与平均宽度,并计算每个字符边界框的几何特征信息,包括高度、宽度、面积与重心坐标;
步骤s2的具体过程如下:
s2a、基于各字符的预测边界框的空间二维排序,从第二个字符的预测边界框开始,计算当前字符与前序字符的几何参数,包括两者之间的重心偏移、顶点偏移、面积差值和宽度差值;
s2b、判定当前字符与前序字符的几何参数是否满足阈值条件,若是,则判定当前字符与前序字符位于同列,此时将当前字符加入前序字符所在的字符竖列数组;否则新建字符竖列数组,并把当前字符加入该新字符竖列数组中;
s2c、对字符竖列数组内的字符按照自上而下的古籍阅读顺序重新进行排序,获得古籍文档中以竖列为单位、符合版面语义的组段聚类结果;
步骤s3的具体过程如下:
s3a、以步骤s2得到的按列聚类所得的粗糙的字符竖列作为输入,通过计算相邻两个字符的重心竖直坐标的误差绝对值ycenter′与对应顶点的水平偏置绝对值offset,判断当前字符chari是否与前序字符chari-1存在版面语义关系,以实现对粗糙的字符竖列进行版面语义级别的精细化分割;
s3b、以字符竖列数组中相邻字符上下边界构造邻接区域,若邻接区域满足高度、灰度平均值、交并比的阈值条件,它将被归为候选区域;
s3c、利用图像形态学方法对候选区域进行处理,采用霍夫变换的方式对齐进行直线检测,获得候选区域的版线位置;若候选区域不存在版线,其版线参数将被设为负数;
s3d、利用统计学方法,过滤所有离群的候选区域版线,计算所有符合条件的版线参数均值,该均值将作为古籍文档中的版线竖直坐标;
s3e、针对于步骤s2b中所得的字符竖列数组中,使用版线对分属上下版面的字符竖列组进行切分,获得语义合理的字符竖列数组;
步骤s4的具体过程如下:
将字符竖列组按照自上而下、自右向左的顺序进行拼接;
其中:
若拼接过程中遇到属于双排夹注类型的字符竖列组,则按照自右向左的顺序对其先行合并,再按照自上而下的方向将其与正常字符竖列组进行拼接;
若中文古籍文档为单页双版的版面风格,则利用步骤s3d中所得的版线进行拼接界限,将位于版线上下区域的字符竖列组分开处理,最后再将两区域的字符竖列组拼接结果按上下顺序合并,获得篇章级的、无标点的、原始的中文古籍篇章内容,实现中文古籍文档阅读顺序的恢复。
本发明的第三目的通过下述技术方案实现:一种中文古籍版面重建方法,包括步骤:
针对于获取的中文古籍文档图像,首先通过本发明第二目的所述的中文古籍字符组段方法对中文古籍文档图像中识别出的字符进行组段和阅读顺序恢复,获得无标点符号的古籍文本内容;
构建语言模型古籍文档版面重建算法,包括纠错语言模型以及断句与标点语言模型,对无标点符号的古籍文本内容进行纠错以及断句;
利用字型库将断句后的文本内容填充到无字符的空白古籍背景图像当中,实现中文古籍文档数字化版面重建。
优选的,实现中文古籍文档数字化版面重建的具体过程如下:
以基于现代文进行预训练的bert-base-chinese语言模型作为基础,使用殆知阁古文文本数据集作为领域语料,进行基于掩蔽语言模型的领域自适应预训练,获得纠错语言模型;
以上述获取的纠错语言模型为基础,以具有标点符号及其对应标签的古文文本数据集作为语料库,进行断句与标点语言模型的微调训练,获得断句与标点语言模型;
将组段和阅读顺序恢复后得到的无标点符号的古籍文本内容作为输入,利用纠错语言模型进行语义级别的字符纠错;
将纠错语言模型字符纠错后得到的古籍文本内容输入到断句与标点语言模型中,进行基于上下文语义的断句,并且根据句子语境添加对应标点符号;
将加入标点符号的古籍文本内容按照自左向右、自上而下的现代阅读习惯,填充进空白的古籍文档背景当中,完成中文古籍文档数字化版面重建。
本发明的第四目的通过下述技术方案实现:一种存储介质,存储有程序,其特征在于,所述程序被处理器执行时,实现本发明第一目的所述中文古籍字符识别方法、本发明第二目的所述的中文古籍字符组段方法或本发明第三目的所述的中文古籍版面重建方法。
本发明的第五目的通过下述技术方案实现:一种计算设备,包括处理器以及用于存储处理器可执行程序的存储器,所述处理器执行存储器存储的程序时,实现本发明第一目的所述中文古籍字符识别方法、本发明第二目的所述的中文古籍字符组段方法或本发明第三目的所述的中文古籍版面重建方法。
本发明相对于现有技术具有如下的优点及效果:
(1)本发明中文古籍字符识别方法中,将原始训练样本中标注文件所指示位置的字符抹去,从而空白版面,并根据原字符的尺寸与位置填入新字符,在保留古籍文档版面风格的同时,带来更多的古籍文档样本,减少因生僻字带来的字符类别分布不均给分类器训练造成的负面干扰,提升了检测分类器的准确度;该方法不仅能够识别出常见的字符,而且还能够非常准确的识别出古籍中的一些不常见的特殊字符,克服现有技术中古籍文档识别存在错判、遗漏等问题。
(2)本发明中文古籍字符识别方法中,在线随机裁剪数据增强算法,通过随机位置、尺寸的方式对原始训练样本进行裁剪,令训练集样本的字符尺寸分布更加均匀,实现模型在测试阶段可良好适应各种尺寸的测试图像。
(3)本发明中文古籍字符识别方法中,针对要识别字符的中文古籍文档图像,通过字符级检测分类模型得到中文古籍文档图像各字符的预测边界框、预测类别和预测置信率后,使用重叠抑制算法过滤相同位置、不同类别的字符,获得基于视觉的古籍文档字符级预测结果;可见本发明使用重叠抑制算法剔除相同位置的不同类别的预测边界框,解决了传统非最大值抑制(nms)算法仅能处理相同类别的重复框的不足。
(4)本发明中文古籍字符组段方法中,将各字符的预测边界框按照古籍阅读顺序及字符语义句群进行组段聚类与阅读顺序恢复,获得无标点符号的古籍文本内容,该方法利用字符尺寸、位置与版面特征等信息将单字符组合为符合版面语义的字符竖列,无需引入行级边界框等高级信息即可实现文本列检测,减少运算资源的开销。
(5)本发明中文古籍字符组段方法中,统计分析古籍版式特征,设计了文本列精确分组算法,用于处理古籍文档图像中常见的双排夹注等特殊版面元素,实现对组段聚类算法所得的粗糙结果的精确分割,提升版面重建的准确性;另外,其中的版线检测,通过构造并筛选字符间的候选区域,利用图像形态学的方法实现线段检测,无需额外引入神经网络提供的版面特征信息,仅利用预测字符边界框信息即可实现低开销、高精度的单面双叶古籍文档的版面分析与阅读顺序恢复。
(6)本发明中文古籍文档版面重建方法中,引入了古文bert语言模型,用于古籍文档视觉识别结果的字符纠错,利用文本内容的上下文语义信息及词间关系来检验视觉识别结果的语义合理性,实现利用高层级的语义信息弥来补视觉识别的疏漏与错误。另外,在版面重建过程中,按照古籍阅读习惯将字符识别结果依次连接组成篇章,再利用古文语言模型对无标点的原始篇章文本进行断句标点,以将其转换为符合现代阅读习惯的文本,并将其重新填入于空白的版面,实现兼具实用与科研价值的中文古籍数字化操作。
附图说明
图1是本发明中文古籍字符识别方法流程图。
图2是本发明中文古籍字符组段方法流程图。
图3a至3d分别是本发明相邻字符的重心水平偏移a1、重心竖直偏移a3、最大顶点偏移a2、字符宽度a4的详细示意图。
图4是本发明中文古籍字符组段方法中版面分割线检测算法流程示意图。
图5是本发明中文古籍版面重建方法流程图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例1
本实施例公开了一种中文古籍字符识别方法,该方法能够通过智能设备例如计算机等进行执行,如图1所示,具体包括如下步骤:
步骤1、获取已标注字符边界框和字符类别的中文古籍文档图像,作为原始训练样本;同时获取原始训练样本的标注文件,标准文件中包括字符边界框尺寸、字符位置和字符类别。
上述字符位置可以通过字符边界框获取到,具体的,字符位置为边界框相对的两个顶角的坐标,例如:(xleft,ytop,xright,ybottom),(xleft,ytop)为边界框左上角的坐标,(xright,ybottom)为边界框右下角的坐标。
上述字符类别指的是具体的字符。
本实施例中,可以从公开的数据集mthv2中获取上述原始训练样本。本实施中,统计mthv2数据集的标注标签中出现的所有字符,构建一个字符字典,以字符词频为排序条件,获得字符到id的绝对映射关系,便于后续的检测分类网络训练的类别标签设计。
步骤2、随机选取多个原始训练样本,并进行如下处理:
步骤21、将原始训练样本中标注文件所指示位置的字符抹去,获得空白的古籍文档背景图像。
在本实施例中,从原始训练样本中获取字符的边界框标注信息,生成字符区域像素灰度值为255、背景区域为0的掩膜图像,然后利用图像形态学中的膨胀操作对掩膜图像进行处理,获得字符区域扩大的掩膜,接着利用图像修补(imageinpaint)算法,以掩膜中灰度值为255的区域作为目标区域,将原始训练样本中中所对应的目标区域使用周围的背景像素点进行替换或填充,实现字符擦除操作,得到空白的古籍文档背景图像。
步骤22、将原始训练样本标注文件中的字符类别替换为语料库的字符类别,得到合成标注文件。
在本实施例中,从公开的古文语料库殆知阁中获取经、史、子、集等数字格式的文本内容。将原始训练样本标注文件中的字符类别替换为殆知阁语料库中的字符类别。
步骤23、依据合成标注文件中指示的字符边界框的尺寸、字符位置、字符类别,向空白的古籍文档背景图像中填充字符,得到合成图像。
本实施例中,上述合成标注文件中所指示的字符边界框的尺寸对应是原始训练样本字符边界框的尺寸,因此在本步骤中,以原始训练样本的字符边界框作为数据合成的字符尺寸与空间位置限定条件,利用中日韩越统一表意文字宋体字型库,在步骤21所得的空白古籍文档背景图像中按照原先的尺寸与位置填入以殆知阁语料库为内容的宋体字符,合成符合古籍版面排布风格的文档图像数据,即得到合成图像。
步骤24、通过合成图像和合成标注文件形成新的训练样本。
步骤3、通过在线随机裁剪的方式对原始训练样本和新训练样本进行裁剪处理,得到训练样本集。
古籍文档扫描版数字图像的尺寸一般较大,直接地以固定尺寸重设大小或裁剪原图都会使字符样本的尺寸分布过于集中,容易导致模型的泛化能力被削弱。本步骤在线随机裁剪的方式对上述原始训练样本和新训练样本进行不同空间位置、不同尺寸的裁剪,得到尺寸特征分布均匀的训练样本,以此构成训练样本集。在线随机裁剪的过程如下:
步骤31、将各原始训练样本和步骤s24获取到的各新训练样本,作为原始训练图像,并且将其作为输入图像,每次数据加载过程均使用随机数生成函数,生成随机尺寸与位置的裁剪区域坐标信息。其中随机裁切位置的计算公式为:
x′left,y′top=random(0,w),random(0,h);
x′right,y′bottom=random(w-x′left,w),random(h-y′top,h);
其中,h、w分别为原始训练图像的高度与宽度,random(i,j)为在开区间(i,j)内生成随机整数的函数,(x′left,y′top)为裁剪图像相对于原始训练图像的左上角绝对坐标,(x′right,y′bottom)为裁剪图像相对于原始训练图像的右上角绝对坐标。利用左上角与右下角坐标即可在原始训练图像中确定矩形的裁切位置,得到随机位置、随机大小的裁剪图像块;
步骤32、利用裁剪区域坐标信息对输入图像样本进行裁切,并将因裁切操作而破碎的字符边界框标注信息剔除;
步骤33、将在线随机裁切的图像样本拉伸至宽度为x像素、高度为y像素的区域,并对该区域内的字符边界框做线性变换,将上述线性变换后的图像样本作为训练样本,构成训练样本集。
本实施例中,x为980,y为780。
步骤4、通过训练样本集中的训练样本训练字符级检测分类模型,具体为:将训练样本集中训练样本及其标注文件分别对应作为二阶段目标检测网络的训练样本与监督数据,进行有监督训练,获得用于检测中文古籍文档字符边界框、识别字符类别的字符检测分类模型。
本实施例中,以步骤33所得宽度为x像素、高度为y像素的裁剪图像块及其标注文件作为输入样本,使用smoothl1作为边界框回归的损失函数,使用crossentropy交叉熵作为类别逻辑回归的损失函数,训练一个二阶段目标检测网络的字符检测分类模型,该模型的类别数为词汇库容量,即6400类。
其中本步骤中,字符检测分类模型属于两阶段网络,首先通过锚点生成多种尺寸、不同位置的预设框,经第一阶段的区域提议网络从大量预设框中筛选出更可能存在目标的候选区域,再通过第二阶段的region-cnn网络进行精细化的边界框回归与类别预测。字符级检测分类模型的具体设计细节如下:
(1)、区域提议网络:依照特征金字塔网络的结构,可得到多个不同尺度的特征图,通过为不同尺度的特征图的锚点分配预设框,可对输入图像的各个位置实现密集目标采样。其中,预设框的长宽比设为0.5、1、2,边框长度设为32、64、128、256、512。预设框经二分类网络正负样本筛选与边界框回归后,存在字符可能性较低的预设框将被舍弃,而保留可能存在字符目标的候选区域,以减轻后续目标检测网络的运算压力;
(2)、目标检测网络:利用roialign将(1)中所得的候选区域池化为固定尺寸的特征图,以便于输入后续的rcnn目标检测网络。rcnn目标检测网络包含一个边界框精细回归模块和一个6400类的分类器,类别数等于词汇库容量,即为每个字符分配一个类别。目标检测网络的边界框回归使用soothl1损失函数,多类别逻辑回归使用交叉熵损失函数;
步骤5、针对要识别字符的中文古籍文档图像,首先将其缩放成x*y像素大小,然后将其输入到字符级检测分类模型,通过字符级检测分类模型得到中文古籍文档图像各字符的预测边界框、预测类别和置信率。
本步骤中,字符级检测分类模型输出的数据格式如下:
boundingbox=[xleft,ytop,xright,ybottom,classid,score]
其中,字符边界框(boundingbox)为使用左上与右下两点定义的矩形框,(xleft,ytop)为预测字符边界框左上角点的水平坐标与竖直坐标,(xright,ybottom)为右下角点坐标,即定义为对应字符的位置;classid为字符的预测类别id,可通过步骤1中提供的字符字典实现类别id到字符的转义;score为字符被预测为classid类别的置信率。
步骤6、针对要识别字符的中文古籍文档图像,通过字符级检测分类模型得到中文古籍文档图像各字符的预测边界框、预测类别和预测置信率,然后使用重叠抑制算法过滤相同位置、不同类别的字符,获得基于视觉的古籍文档字符级预测结果,具体如下:
步骤61、预测字符边界框执行自上而下、自左向右的空间排序;
步骤62、将竖直方向间距小于字符平均宽度t倍的字符归为一组,统计该字符组内相邻字符的交并比iou,提取该组内交并比大于阈值的所有字符,组成重叠字符数组。本实施例中。针对于每张测试图像,基于预测的边界框计算出改张图像的字符平均宽度。
步骤63、针对于重叠字符数组,以字符预测置信率为条件进行降序排序,将置信率最高的字符判定为该位置预测字符,剔除重叠字符数组内其余所有字。
本领域技术人员可以理解,实现本实施例方法中的全部或部分步骤可以通过程序来指令相关的硬件来完成,相应的程序可以存储于计算机可读存储介质中。应当注意,尽管在附图中以特定顺序描述了本实施例1的方法操作,但是这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。相反,描绘的步骤可以改变执行顺序,有些步骤也可以同时执行。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
实施例2
本实施例公开了一种中文古籍字符组段方法,包括如下步骤:
步骤7、针对于获取到的中文古籍文档图像,通过实施例1所述的方法获取到其中各字符的预测边界框和预测类别;
步骤8、将各字符的预测边界框按照古籍阅读顺序及字符语义句群进行组段聚类与阅读顺序恢复,获得无标点符号的古籍文本内容。如图2中所示,具体步骤如下:
s1、以各字符的预测边界框为输入,按照古籍阅读顺序习惯对其进行空间排序,并计算字符边界框的几何特征信息。具体如下:
s1a、将各字符的预测边界框按照自右向左、自上而下的古籍阅读顺序进行空间二维排序。
具体的,在本实施例中,利用字符的预测边界框左上角与右下角坐标计算字符框的重心坐标,由于古籍文档的字符排版风格为自上而下、自右向左,故以字符重心的水平方向坐标作为索引进行降序排序,得到字符边界框的排序结果。
s1b、统计古籍文档图像中所有预测字符边界框的平均面积与平均宽度,并计算每个字符边界框的几何特征信息,包括高度、宽度、面积与重心坐标。
本实施例中,以预测字符边界框平均面积的一半作为区分大小字符的判断阈值,将预测的字符框分为种尺寸类别,分别是大尺寸类和小尺寸类。其中当字符的预测边界框的面积大于判断阈值时,将该字符判定为大尺寸类,否则判定为小尺寸类。
s2、根据相邻字符边界框的几何特征信息,判断它们是否位于同列,以实现单个字符的组段聚类;具体如下:
步骤s2的具体过程如下:
s2a、基于各字符的预测边界框的空间二维排序,从第二个字符的预测边界框开始,计算当前字符与前序字符的几何参数,包括两者之间的重心偏移、顶点偏移、面积差值和宽度差值。如图3a至3d所示分别为相邻字符的重心水平偏移a1、重心竖直偏移a3、最大顶点偏移a2、字符宽度a4的详细示意图,图中方框即为字符的边界框。
在本实施例中,以古籍文档字符平均面积areaavg、平均宽度wavg以及字符框的特征信息(xleft,ytop,xright,ybottom,xcenter,ycenter,h,w,area)作为输入,分别计算相邻两个字符框chari与chari-1的重心水平坐标(xcenter,ycenter)、顶点坐标(xleft,ytop,xright,ybottom)、字符宽度w、字符面积area几个参数的误差绝对值,即对应两者字符之间的重心偏移、顶点偏移、面积差值和宽度差值。
s2b、判定当前字符chari与前序字符chari-1的几何参数是否满足阈值条件,若是,则判定当前字符chari与前序字符chari-1的位于同列,此时将当前字符chari加入前序字符chari-1的所在的字符竖列数组;否则新建字符竖列数组,并把当前字符chari加入该新字符竖列数组中。
在本实施例中,根据当前字符的尺寸类别,确定重心偏移阈值、顶点偏移阈值、面积差值阈值和宽度差值阈值。在当前字符与前序字符的重心偏移、顶点偏移、面积差值和宽度差值分别对应小于重心偏移阈值、顶点偏移阈值、面积差值阈值和宽度差值阈值时,判定当前字符与前序字符的几何参数满足阈值条件。
本实施例中,若当前字符chari属于大尺寸类别,则重心偏移阈值为0.15*thrw,顶角偏移阈值为0.15*thrw,面积差值阈值为0.8*thrarea,宽度差值阈值为0.75*thrw;若当前字符chari属于小尺寸类别,则重心偏移阈值为0.2*thrw,顶角偏移阈值为0.2*thrw,面积差值阈值为0.5*thrarea,宽度差值阈值为0.5*thrw;其中thrw为测试图像字符平均宽度,thrarea为测试图像字符平均面积。
s2c、对字符竖列数组内的字符按照自上而下的古籍阅读顺序重新进行排序,获得古籍文档中以竖列为单位、符合版面语义的组段聚类结果。
s3、针对中文古籍文档图像进行版线检测,使用版线对应当分属上下版面的字符竖列进行切分,获得语义合理的字符竖列数组;具体步骤如下:
s3a、以步骤s2得到的按列聚类所得的粗糙的字符竖列作为输入,通过计算相邻两个字符的重心竖直坐标的误差绝对值ycenter′与对应顶点的水平偏置绝对值offset,判断当前字符chari是否与前序字符chari-1存在版面语义关系,以实现对粗糙的字符竖列进行版面语义级别的精细化分割。
具体步骤如下:
s3a1、竖直偏置计算:输入按列聚类的字符竖列,计算相邻两个字符框重心的竖直坐标误差绝对值ycenter′,即竖直偏置,计算公式如下:
式中,i为当前字符在字符竖列数组中的索引,n为字符竖列数组的长度,运算符
s3a2、水平偏置计算:输入按列聚类的字符竖列,计算相邻两个字符的水平坐标xleft与xright的偏置距离的最大值,即水平偏置,计算公式如下:
式中,运算符max(a,b)为取最大值操作,
s3a3、条件判断:利用竖直与水平偏置,通过设定阈值与条件判断,对步骤s2中得到的粗糙的按列聚类的字符组进行精细化的分割,详细步骤如下:
(1)在竖排风格的古籍文档中,若同列的相邻字符的间隔过长,则它们应当被细分成两个上下子列,故可使用竖直偏置距离来对粗糙分组的字符竖列进行精细分割;在版面布局复杂的古籍文档中,有在一列字符中出现双排小字夹注的情形,小字夹注通常为上文字词的注解,故可使用水平偏置距离来判断当前字符是否偏离前序字符的左边界或右边界,解决同列大尺寸字符与双排夹注字符的混淆问题,实现字符在版面语义层面的组合聚类;
(2)若当前字符chari属于大尺寸字符时,竖直偏置ycenter′的阈值为为2.5*thrw,水平偏置offset的阈值0.15*thrw;若当前字符chari为小尺寸字符时,竖直偏置ycenter′的阈值为4*thrw,水平偏置offset的阈值0.2*thrw。当竖直偏置ycenter′与水平偏置offset均小于所对应的阈值时,认为当前字符chari与前序字符chari-1符合版面语义中同列字符的条件,无需进一步切分;否则认为这两个字符属于不同文本列,此时需新增空的文本列数组,并将当前字符chari加入该新增文本列数组;
s3b、以字符竖列数组中相邻字符上下边界构造邻接区域,若邻接区域满足高度、灰度平均值、交并比的阈值条件,它将被归为候选区域;具体的,如图4中所示,以步骤s3a得到的古籍文档字符竖列组作为输入,当字符竖列组长度超过长度t时,执行候选区域的生成与筛选流程,t可以设置为5;具体流程如下:
(1)输入长度大于t的字符竖列,依次构造相邻字符的间隔区域,该区域的可由如下公式表示:
式中,i表示当前字符在字符竖列数组中的索引,n表示字符竖列组的长度,xaxis为相邻两个字符的水平坐标集合,rp表示候选区域左上右下格式的两点定位坐标集合。当候选区域的高度不超过2.5*thrw时,认为该区域内出现版线的可能性较低,故将它舍弃;
(2)将步骤(1)中所得的候选区域与其对应字符竖列组中所有的字符作交并比运算(iou,intersectionoverunion),过滤iou大于0.1的候选区域,以减少混有字符的候选区域对版线检测精度的干扰。统计候选区域的灰度平均值,对于灰度平均值超过250的候选区域,认为该区域更可能是纯粹的背景区域,故将它舍弃;
(3)遍历古籍文档图像中所有的预测文本列,重复步骤(1)、(2),在降低运算资源开销的同时可提高版线检测的精度,完成候选区域的构建与筛选,获得存在版线几率更高的候选区域。
s3c、利用图像形态学方法对候选区域进行处理,采用霍夫变换的方式对齐进行直线检测,获得候选区域的版线位置;若候选区域不存在版线,其版线参数将被设为负数;如图4所示,具体如下:
(1)灰度反转:对候选区域的像素点灰度值在[0,255]范围内做灰度反转,可将原先为黑色(灰度值趋近于0)的版线转为白色,原先为白色(灰度值趋近于255)的背景转为黑色,完成背景与前景的转换。
(2)腐蚀膨胀:对完成灰度反转的候选区域执行图像形态学中腐蚀与膨胀操作,使候选区域中可能存在的版线更加平滑与清晰,同时减少间断点与毛刺。
(3)直线检测:对完成腐蚀膨胀操作的灰度反转的候选区域执行霍夫变换直线检测操作,可得到候选区域内线段的两个端点坐标。统计候选区域中被检测到的所有线段的竖直坐标,并求取其平均值,可得到表示该候选区域分割版线的竖直位置。
s3d、利用统计学方法,过滤所有离群的候选区域版线,计算所有符合条件的版线参数均值,该均值将作为古籍文档中的版线竖直坐标。本实施例中,对步骤s3c)检测所得的候选区域分割版线进行坐标换算,分割版线的竖直坐标加上候选区域左上角的竖直坐标,即可得到相对于古籍文档图像的分割版线绝对坐标。统计所有候选区域分割版线竖直坐标,组成版线数组seglinearr,对版线数组执行离群数过滤,具体步骤如下:
(1)计算版线数组的标准差std与均值mean:
(2)对版线数组seglinearr执行过滤,合群数区间可表示为:
[mean-thrfilter*std,mean+thrfilter*std]
式中,thrfilter为离群数过滤阈值,其值设定越小,被过滤的离群数越多,保留下来的合群数的分布更集中;
对经过离群数过滤的版线数组seglinearr求均值,可得到表示单面双叶的古籍文档分割版线的竖直坐标,对于单面单页古籍文档,该值将被缺省为-1。
s3e、针对于步骤s2b中所得的字符竖列数组中,使用版线对分属上下版面的字符竖列组进行切分,获得语义合理的字符竖列数组;
s4、利用古籍阅读习惯、古籍版面风格先验知识,将步骤s3中所得的字符竖列进行拼接,实现古籍阅读顺序的恢复。具体如下:
将字符竖列组按照自上而下、自右向左的顺序进行拼接。其中:
若版线坐标数值为-1,即不存在分割版线,则表明该古籍文档为单面单叶风格,仅需以自上而下、自右向左的顺序拼接字符竖列,得到古籍文档的原始段落;
若版线坐标存在,应先将跨越版线的字符竖列组版线所指示的竖直位置一分为二,得到符合版面语义的字符竖列,接着将字符竖列组分割版线作为界限分成上下两组,再将每组字符竖列按照自上而下、自右向左的顺序进行拼接组成段落,最后将上下两组段落进行合并,得到古籍文档的原始段落。
若拼接过程中遇到属于双排夹注类型的字符竖列组,即待合并的两个字符竖列组的顶点偏移距离大于字符平均宽度阈值,则按照自右向左的顺序对其先行合并,再按照自上而下的方向将其与正常字符竖列组进行拼接;
本领域技术人员可以理解,实现本实施例方法中的全部或部分步骤可以通过程序来指令相关的硬件来完成,相应的程序可以存储于计算机可读存储介质中。应当注意,尽管在附图中以特定顺序描述了本实施例2的方法操作,但是这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。相反,描绘的步骤可以改变执行顺序,有些步骤也可以同时执行。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
实施例3
本实施例公开了一种中文古籍版面重建方法,包括步骤:
步骤9、针对于获取的中文古籍文档图像,首先通过实施例2所述的中文古籍字符组段方法对中文古籍文档图像中识别出的字符进行组段和阅读顺序恢复,获得无标点符号的古籍文本内容;
步骤10、构建语言模型古籍文档版面重建算法,包括纠错语言模型以及断句与标点语言模型,对无标点符号的古籍文本内容进行纠错以及断句。如图5所示,具体如下:
(1)以基于现代文进行预训练的bert-base-chinese语言模型作为基础,使用殆知阁古文文本数据集作为领域语料,进行基于掩蔽语言模型的领域自适应预训练,获得纠错语言模型。
(2)以上述获取的纠错语言模型为基础,以具有标点符号及其对应标签的古文文本数据集作为语料库,进行断句与标点语言模型的微调训练,获得断句与标点语言模型。
(3)将组段和阅读顺序恢复后得到的无标点符号的古籍文本内容作为输入,利用纠错语言模型进行语义级别的字符纠错。具体如下:
(31)设计窗长为128、步进为64的滑动窗口,对古籍段落文本进行截取。为确保上下文语义的连贯性,仅对滑窗中序号为[32,96]的字符执行纠错处理,而滑窗的前后32个字符不作任何操作。对于滑窗中部待处理字符,若其置信率低于设定阈值,它将被执行mask掩蔽预处理。为保证字符纠错的精度,每次掩蔽操作仅处理一个字符,滑窗中部的待处理字符将依据上述流程逐一地处理;
(32)将经过掩蔽预处理的语句输入语言模型,语言模型根据上下文语义及词间关系预测mask掩蔽字符,输出置信率前五的候选结果。若置信率最高的候选预测字符与掩蔽位置原始字符相同,则认为掩蔽位置基于图像识别结果的字符无误;若置信率最高的候选预测字符与掩蔽位置原始字符不同,但候选预测字符的置信率高于设定阈值,则认为原始字符错误,并使用预测字符进行替换;若置信率最高的候选预测字符与掩蔽位置原始字符不同,且候选预测字符的置信率低于设定阈值,按照视觉识别结果优先的规则,保持掩蔽位置的原始字符不变。
(4)将纠错语言模型字符纠错后得到的古籍文本内容输入到断句与标点语言模型中,进行基于上下文语义的断句,并且根据句子语境添加对应标点符号,实现古籍文档到现代文档的阅读风格转换;具体如下:
(41)设计一个缓冲区间策略,对输入的古籍文本进行区间切片,区间长度设为128字符。在执行断句操作时,以缓存区间的形式向语言模型输入数据,每次仅保留前三句的断句结果,余下的缓冲区间末尾的文本将被合并到后续的待处理语料中,同时缓冲区间向后移动,继续进行后续操作。该策略可避免由缓冲区间随机切割所带来的异常断句现象,保证缓冲区间内文本的语义连贯性;
(42)将缓冲区间文本输入到训练好的断句与标点语言模型,模型将根据文本的上下文语义与词间关系,预测每个字符在句中的位置,若字符位于句首,其预测标签为b(begin),若字符位于句中,其预测标签为i(inside)。此外,句子标点符号的标签分别为逗号com(comma),句号per(period),冒号col(colon),问号qm(questionmark),感叹号em(exclamationmark),句子标点符号的标签向前对齐,即句子末尾的标点若为逗号,则该句子所有字符都将带有逗号标签,如“[b-com,i-com,...,i-com]”;
(43)利用步骤(42)所得的预测标签对原始古籍文本进行句读与标点,遵循向前对齐原则,将句中所有字符对应的标点标签填入句末,得到加入现代标点的古籍文本。
步骤11、利用字型库将断句后的文本内容填充到无字符的空白古籍背景图像当中,实现中文古籍文档数字化版面重建。
在本实施例中,使用本擦除算法,将需要测试的原始古籍文档图像转换为无字符的空白版面图像。
在本实施例中,利用中日韩越统一表意文字的思源宋体字型库,将加入标点符号的古籍文本内容按照自左向右、自上而下的现代阅读习惯,填充进空白的古籍文档背景当中,获得符合现代阅读习惯、更加清晰的古籍文档识别结果,实现中文古籍文档数字化、现代化的版面重建。
在本实施例中,上步骤10中,基于bert的古文语言模型的设计与训练的具体步骤如下:
s1、数据预处理:以殆知阁古文语料库作为输入,它包含经、史、子、集等体裁的古文文本,语料库内大多数文本均经过现代加工,带有标点符号。为使古文语言模型具备字符级别的纠错能力,需让它学习语料内容的词间关系与上下文语义,因此可通过类似完形填空的方式实现字符预测功能。为此,训练语料内容需按照如下方式进行掩蔽处理:
(s11)、利用伯努利分布,从原始语料中随机取出15%的字符,对其进行掩蔽处理,其概率分布函数如下:
式中,p取值为0.15,表示随机变量x=1的概率为0.15,即原始语料中每个字符在训练过程中被掩蔽的几率为15%。
(s12)、对于步骤(s11)所得到的待掩蔽字符,其中的80%将被赋值为[mask],10%被随机替换成为其他字符,余下的10%将保留原值。在训练过程中,模型通过预测[mask]字符来增强对语料上下文关系的感知、
(s13)、对步骤(s11)中15%的掩蔽字符赋予positive标签,余下的85%未处理字符赋予negative标签,以便后续训练中的损失计算聚焦于掩蔽位置的字符、
s2、领域语料训练:设计一个具有12层transformer编码器、768维隐藏层、12个自注意力头的自编码语言模型,利用token嵌入层从输入的语料内容中提取字符向量、文本向量和位置向量,通过学习语料内容的隐含表征信息,获得能够刻画语言本质、融合全文语义信息的向量表征。其中,字向量为词汇表的一维索引数值,文本向量用于刻画全局语义信息,位置向量用于描述不同位置字词的特定含义。语言模型中预测字符输出端将接入一个维度为词汇库大小的全连接层,通过softmax层进行逻辑回归后,使用交叉熵损失来衡量语言模型预测字符准确性,交叉熵函数具体如下:
其中,lce是交叉熵(crossentropy)损失的符号,n为测试样本总数,m为字符类别数量,即词汇库的字符容量;yic为指示预测字符i的属于真实类别c的变量,若属于则为1,否则为0;pic表示预测字符i属于类别c的预测概率;
进一步地,使用上述步骤s1提供的方法对字符数约为4亿的殆知阁古文语料进行数据预处理,然后利用预处理语料通过预测[mask]位置字符的方式训练上述自编码语言模型,获得能够根据上下文语义判断字符合理性的纠错语言模型;
s3、任务语料训练:用于断句标点任务的语言模型与步骤2中所设计的模型类似,区别仅在于全连接层输出维度为标点符号类别数。对于断句与自动标点任务,其标签定义细节如下:
(1)句首字符标签设为b(begin),句中字符标签设为i(inside),这两个标签将作为一级标签,用于精确定位断句位置;
(2)为降低标签体系复杂度,仅选取五类常用的标点元素,分别为逗号com(comma)、句号per(period)、冒号col(colon)、问号qm(questionmark)和感叹号em(exclamationmark),它们将作为二级标签,用于指示断句位置应当填入的标点符号;
(3)为节省运算资源,断句与标点任务应融合训练,因此需将断句与标点标签合并为组合标签。在组合标签体系中,句子的标点标签需向前对齐,即句子末尾的标点若为逗号,则该句子所有字符都将带有逗号标签,标签实例如下:
原始语料:“月明星稀,乌鹊南飞。绕树三匝,何枝可依?”
训练标签:“[b-com,i-com,i-com,i-com,b-per,i-per,i-per,b-com,i-com,i-com,i-com,b-qm,i-qm,i-qm,i-qm]”;
本实施例中,利用按照上述规则定义的标签训练步骤2中设计的模型,其中全连接层的输出维度为10,损失函数同为交叉熵,经多次迭代训练后可得到古断句与标点语言模型。
本领域技术人员可以理解,实现本实施例方法中的全部或部分步骤可以通过程序来指令相关的硬件来完成,相应的程序可以存储于计算机可读存储介质中。应当注意,尽管在附图中以特定顺序描述了本实施例3的方法操作,但是这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。相反,描绘的步骤可以改变执行顺序,有些步骤也可以同时执行。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
实施例4
本实施例公开了一种存储介质,存储有程序,所述程序被处理器执行时,实现实施例1所述的中文古籍字符识别方法、实施例2所述的中文古籍字符组段方法或实施例3所述的中文古籍版面重建方法。
在本实施例中,存储介质可以是磁盘、光盘、计算机存储器、只读存储器(rom,read-onlymemory)、随机存取存储器(ram,randomaccessmemory)、u盘、移动硬盘等介质。
实施例5
本实施例公开了一种计算设备,包括处理器以及用于存储处理器可执行程序的存储器,其特征在于,所述处理器执行存储器存储的程序时,实现实施例1所述的中文古籍字符识别方法、实施例2所述的中文古籍字符组段方法或实施例3所述的中文古籍版面重建方法。
本实施例中,计算设备可以是台式电脑、笔记本电脑、智能手机、pda手持终端、平板电脑等终端设备。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!