一种结合命名实体识别的开放域信息抽取方法
本发明涉及信息抽取
技术领域:
,具体涉及一种结合命名实体识别的开放域信息抽取方法。
背景技术:
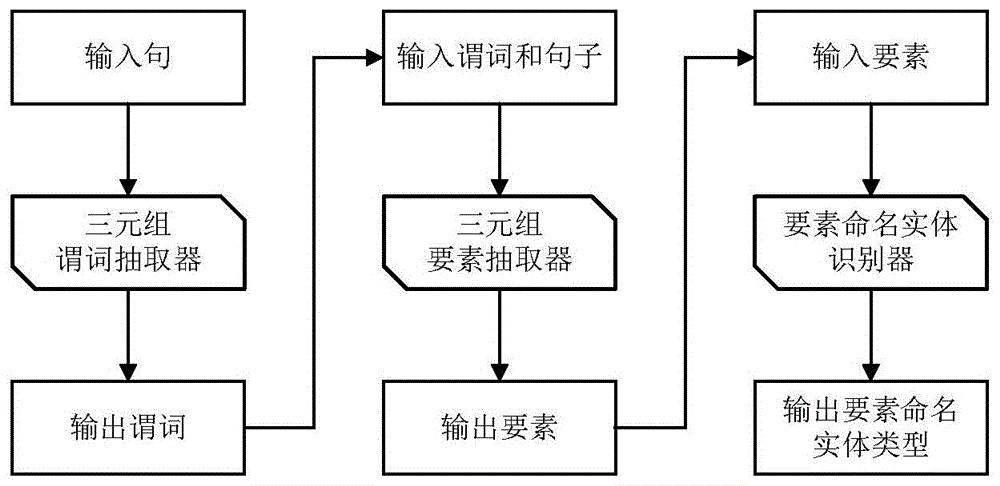
:开放域信息抽取是指从非结构化文本数据中抽取由关系短语和要素短语构成的结构化三元组。比如在句子“barackobama,aformeru.spresident,wasborninhawaii.”中,“wasbornin”是一个三元组的谓词短语,而“barackobama”和“hawaii”为该三元组的要素短语。开放域信息抽取是涉及知识图谱构建的重要任务,可以进一步应用到文本蕴含、自动问答等领域。目前,开放域信息抽取方法仅支持从给定句子中抽取三元组信息,而无法有效获得三元组中要素短语的命名实体类型,比如在上例中,系统无法得知“barackobama”是人名而“hawaii”是地名。相比于传统开放域信息抽取,结合命名实体识别的开放域信息抽取能提供额外的命名实体类别信息,这对于知识图谱构建大有裨益,其实现也更具挑战。面对这一挑战,一种常见做法是构建结合开放域信息抽取和命名实体识别的流水线系统。然而,流水线系统通常面临误差累积问题,即两个模型的预测误差存在相互叠加后放大的现象。为应对这一问题,一种常见做法是设计端到端的模型来联合开放域信息抽取和命名实体识别两种任务。然而,据我们所知,目前尚没有公开发表的工作进行这方面的研究。此外,传统的基于序列标注的开放域信息抽取方法无法有效应对嵌套三元组的情况。例如在句子“ratherominously,rabbitstudiesrevealthatru-486cancausebirthdefects.”中,其中一个三元组为(“studies”、“reveal”、“thatru-486cancausebirthdefects”),而另一个三元组嵌套在第一个三元组中,为(“ru-486”、“cause”、“birthdefects”),此时单词如“ru-486”、“cause”等拥有多个bio标签,而序列标注方法无法同时输出多个标签。因此,如何有效解决嵌套三元组抽取问题也是一大挑战。技术实现要素:本发明的目的在于克服现有基于序列标注的流水线式方法存在的误差累积、嵌套三元组抽取精度低的缺陷,提出一种联合开放域信息抽取及命名实体识别的方法,为了实现上述目的,本发明提出了一种结合命名实体识别的开放域信息抽取方法,所述方法包括:将待抽取的句子输入预先建立和训练好的三元组谓词抽取器,输出谓词短语;将谓词短语和待抽取的句子输入预先建立和训练好的三元组要素抽取器,输出三元组要素短语的位置;三元组要素包括:主语、宾语及定语;将三元组要素抽取器中获取的序列隐状态表示和三元组要素短语的位置,输入预先建立和训练好的命名实体识别器,输出三元组要素短语的命名实体类别;其中,三元组谓词抽取器用于抽取输入句子中出现的三元组涉及的谓词,三元组谓词抽取器单独进行训练,三元组要素抽取器用于抽取输入句子中出现的三元组涉及的要素短语;命名实体识别器用于识别三元组要素短语的命名实体类别;三元组要素抽取器和命名实体识别器联合进行训练。作为上述方法的一种改进,所述三元组谓词抽取器包括:第一预处理模块、第一预训练语言模型和条件随机场层,第一预训练语言模型包含l个依次连接的预训练transformer块;所述第一预处理模块,用于将输入句子转换为第一输入序列:<[cls],tok1,tok2,…,tokn,[sep]>,其中,[cls]和[sep]均为特殊符号,tok1,tok2,…,tokn为输入句子中包含n个字符;然后获得第一输入序列的预训练的词嵌入表示h0,该词嵌入表示h0为字符嵌入、位置嵌入和分段嵌入之和,将词嵌入表示h0输入第一预训练语言模型;所述第一预训练语言模型,用于利用l个预训练transformer块对输入的词嵌入表示h0依次进行编码:其中,hi为第i个transformer块输出的第一序列隐状态表示,transformerblock()表示transformer函数;将第l个transformer块输出的第一序列隐状态表示hl输入条件随机场层;所述条件随机场层,用于对第一序列隐状态表示hl进行预测,输出每个字符在bio标签体系下的概率分布yp,yp是一个维度为(n+2)×3的概率分布,对该概率分布进行解码,可以得到第一输入序列的bio预测标签,进而获得预测的谓词短语。作为上述方法的一种改进,所述方法还包括:对三元组谓词抽取器进行训练的步骤;具体包括:步骤101)收集领域相关文本,按照bio标签体系标注文本中出现的三元组谓词短语,得到三元组谓词抽取训练样本;步骤102)第一预处理模块对输入的三元组谓词抽取训练样本的句子进行预处理,输出词嵌入表示;步骤103)第一预训练语言模型对词嵌入表示输入进行编码,输出第一序列隐状态表示hl;步骤104)条件随机场层基于第一序列隐状态表示hl预测单词的谓词标签;步骤105)通过预测的谓词标签与步骤101)标注的真实三元组谓词短语,计算交叉熵损失函数连同第一预训练语言模型一起进行微调,以训练三元组谓词抽取器。作为上述方法的一种改进,所述三元组要素抽取器包含第二预处理模块、第二预训练语言模型和多头指针网络;第二预训练语言模型包含l个依次连接的预训练transformer块;所述三头指针网络包括三个头指针;所述第二预处理模块,用于将输入句子和抽取的谓词短语拼接为第二输入序列:<[cls],tok1,…,tokm,[sep],tok1,tok2,…,tokn,[sep]>,其中谓词短语包含m个字符:tok1,…,tokm,输入句子包含n个字符:tok1,tok2,…,tokn;然后获得第二输入序列的词嵌入表示并输入第二预训练语言模型;所述第二预训练语言模型,用于利用l个预训练transformer块对输入的词嵌入表示依次进行编码:其中,为第i个transformer块输出的第二序列隐状态表示;将第l个transformer块输出的第二序列隐状态表示输入三头指针网络;所述三头指针网络,用于分别利用三个头指针预测三元组要素在输入序列中位置,其中第j个头指针输出两组概率分布和为:其中,和为维度是1×d的可训练参数,d表示隐状态维度,用于计算向量x=(x1,x2...xk)的概率分布,j=1,2,3;通过取和中得分最大的位置,即可预测第j个要素在第二输入序列中的开始位置sj和结束位置ej。作为上述方法的一种改进,所述命名实体识别器包括:自注意力加权模块和感知机分类器:所述自注意力加权模块,用于根据三元组要素抽取器的第二预训练语言模型输出的第二序列隐状态表示以及第j个要素在第二输入序列中的开始位置sj和结束位置ej,计算第j个要素的自注意力概率分布aj:其中,wa为维度是1×d的可训练参数;然后计算基于该自注意力分布的第j个要素加权和作为第j个要素隐状态表示将输入感知机分类器;所述感知机分类器,用于输出第j个要素的命名实体类别概率分布其中,wc为维度是c×d的可训练参数,c表示命名实体类别个数;取中得分最大对应的实体类型,即是预测的要素实体类别。作为上述方法的一种改进,所述方法还包括:对三元组要素抽取器和命名实体识别器进行联合训练的步骤;具体包括:步骤201)在三元组谓词抽取训练样本基础上,额外标注要素短语的位置以及要素短语的命名实体类型,得到联合训练样本;步骤202)三元组要素抽取器的第二预处理模块对输入的三元组谓词抽取训练样本的句子及其真实谓词短语进行预处理,输出词嵌入表示;步骤203)第二预训练语言模型对输入的词嵌入表示进行编码,得到序列隐状态表示,分别输出至三元组要素抽取器的三头指针网络和命名实体识别器的自注意力加权模块;步骤204)三头指针网络基于序列隐状态表示,预测三元组要素短语在句子中位置;步骤205)通过预测的三元组要素短语在句子中位置和步骤201)标注的真实要素短语位置,计算交叉熵损失函数步骤206)自注意力加权模块基于标注的要素短语位置和序列隐状态表示,计算并输出标注的要素短语的隐状态表示;步骤207)感知机分类器基于要素短语的隐状态表示,预测要素的命名实体类别;步骤208)通过预测的要素的命名实体类别与步骤201)标注的真实命名实体类型,计算交叉熵损失函数步骤209)计算总损失函数连同第二预训练语言模型一起进行微调,由此联合训练三元组要素抽取器和命名实体识别器。本发明的技术优势在于:1、本发明的方法针对流水线方法中存在的误差累积问题,通过复用要素抽取的隐状态表示来同时进行要素抽取和命名实体识别,有效地提高了命名实体识别任务的精确度,并缩短了训练和推理时间;2、本发明的方法设计了一个基于神经网络的谓词抽取器,相比于传统基于词性标注的方法,本方法在谓词抽取上的性能更佳;3、本发明的方法通过使用多头指针网络来预测要素在原文中位置,有效克服了嵌套三元组抽取问题,相比于使用序列标注的传统抽取方法,有效提高了三元组抽取的准确率和召回率。附图说明图1为本发明的结合命名实体识别的开放域信息抽取方法的示意图;图2为本发明的三元组谓词抽取器结构图;图3为本发明的三元组要素抽取器结构图;图4为本发明的命名实体识别器结构图;图5为本发明的三元组谓词抽取器、三元组要素抽取器以及命名实体识别器训练过程的流程图。具体实施方式下面结合附图对本发明做进一步详细的说明。如图1所示,本发明提出的一种结合命名实体识别的开放域信息抽取方法,包括:用于抽取输入文本中出现的谓词短语的三元组谓词抽取器、用于抽取输入文本中出现的三元组要素短语的三元组要素抽取器,以及用于识别三元组要素实体类别的命名实体识别器。三元组谓词抽取器的输出为三元组要素抽取器的输入,三元组要素抽取器的输出为要素命名实体识别器的输入;三元组谓词抽取器输出谓词短语,三元组要素抽取器输出三元组要素短语(主语、宾语和定语),要素命名实体识别器输出三元组要素的实体类别。该方法包括以下步骤:步骤1)将待抽取的句子输入三元组谓词抽取器,输出谓词短语;如图2所示,三元组谓词抽取器包括:第一预处理模块、第一预训练语言模型和条件随机场层,第一预训练语言模型包含l个依次连接的预训练transformer块;第一预处理模块,用于将输入句子转换为第一输入序列:<[cls],tok1,tok2,…,tokn,[sep]>,其中,[cls]和[sep]均为特殊符号,tok1,tok2,…,tokn为输入句子中包含n个字符;然后获得第一输入序列的预训练的词嵌入表示h0,该词嵌入表示h0为字符嵌入、位置嵌入和分段嵌入之和,将词嵌入表示h0输入第一预训练语言模型;第一预训练语言模型,用于利用l个预训练transformer块对输入的词嵌入表示h0依次进行编码:其中,hi为第i个transformer块输出的第一序列隐状态表示,transformerblock()表示transformer函数;将第l个transformer块输出的第一序列隐状态表示hl输入条件随机场层;条件随机场层,用于对第一序列隐状态表示hl进行预测,输出每个字符在bio标签体系下的概率分布yp,yp是一个维度为(n+2)×3的概率分布,对该概率分布进行解码,可以得到第一输入序列的bio预测标签,进而获得预测的谓词短语。步骤2)将谓词短语和待抽取的句子输入三元组要素抽取器,输出到三元组要素短语的位置;如图3所示,三元组要素抽取器包含第二预处理模块、第二预训练语言模型和多头指针网络;第二预训练语言模型包含l个依次连接的预训练transformer块;三头指针网络包括三个头指针;第二预处理模块,用于将输入句子和抽取的谓词短语拼接为第二输入序列:<[cls],tok1,…,tokm,[sep],tok1,tok2,…,tokn,[sep]>,其中谓词短语包含m个字符:tok1,…,tokm,输入句子包含n个字符:tok1,tok2,…,tokn;然后获得第二输入序列的词嵌入表示并输入第二预训练语言模型;第二预训练语言模型,用于利用l个预训练transformer块对输入的词嵌入表示依次进行编码:其中,为第i个transformer块输出的第二序列隐状态表示;将第l个transformer块输出的第二序列隐状态表示输入三头指针网络;三头指针网络,用于分别利用三个头指针预测三元组要素在输入序列中位置,其中第j个头指针输出两组概率分布和为:其中,和为维度是1×d的可训练参数,d表示隐状态维度,用于计算向量x=(x1,x2...xk)的概率分布,j=1,2,3;通过取和中得分最大的位置,即可预测第j个要素在第二输入序列中的开始位置sj和结束位置ej。步骤3)将三元组要素抽取器中获取的序列隐状态表示和三元组要素的短语位置,输入命名实体识别器,得到要素短语的命名实体类别。如图4所示,命名实体识别器包括:自注意力加权模块和感知机分类器:自注意力加权模块,用于根据三元组要素抽取器的第二预训练语言模型输出的第二序列隐状态表示以及第j个要素在第二输入序列中的开始位置sj和结束位置ej,计算第j个要素的自注意力概率分布aj:其中,wa为维度是1×d的可训练参数;然后计算基于该自注意力分布的第j个要素加权和作为第j个要素隐状态表示将输入感知机分类器;感知机分类器,用于输出第j个要素的命名实体类别概率分布其中,wc为维度是c×d的可训练参数,c表示命名实体类别个数;取中得分最大对应的实体类型,即是预测的要素实体类别。如图5所示,对三元组谓词抽取器、三元组要素抽取器以及命名实体识别器进行训练的主要步骤包括:步骤s1)训练三元组谓词抽取器,用于抽取输入文本中出现的三元组涉及的谓词,具体包括如下步骤:首先确定输入数据源,数据源为军事类动态新闻中文文本,收集领域内文本后,按照bio标准格式标注文本中出现的三元组谓词短语,以句子“尼米兹号航母全长332.8米”为例,标注后如表1所示:其中b-p表示谓词起始词、i-p表示谓词非起始词、o表示不属于三元组的其他词。表1尼米兹号全长332米。oooob-pi-pooo标注完毕后,对输入句的开头和结尾拼接特殊符号[cls]和[sep]以转换为输入序列<[cls]、输入句、[sep]>,使用预训练语言模型对输入序列编码,获得输入序列的隐状态表示。基于该表示,使用条件随机场(crf)层来预测单词的bio标签,与真实标签计算交叉熵损失函数,最后基于该损失函数训练三元组谓词抽取器。步骤s2)对三元组要素抽取器和命名实体识别器进行联合训练的步骤;三元组要素抽取器,用于抽取输入文本中出现的三元组涉及的要素;命名实体识别器,用于识别三元组要素短语的命名实体类别;步骤s2-1)在三元组谓词抽取训练样本基础上,额外标注要素短语的位置以及要素短语的命名实体类型,得到联合训练样本;在前期标注数据基础上,继续按照bio标准格式标注谓词对应的三元组要素短语,以上例中句子为例,谓词“全长”对应的要素短语标注后如表2所示:其中b-a0表示要素主体起始词、i-a0表示要素主体非起始词、b-a1表示要素客体起始词、i-a1表示要素客体非起始词、o表示不属于三元组的其他词。表2尼米兹号全长332米。b-a0i-a0i-a0i-a0oob-a1b-a1o在前期标注数据基础上,额外标注要素短语的命名实体类型,以上例中句子为例,主体“尼米兹号”对应的实体类型应是谓词“舰艇”。本发明所涉及的实体类型如表3所示:表3命名实体类型说明生产厂商武器装备的生产厂商类机构实体隶属单位武器装备的隶属单位类机构实体武器包括枪支、弹药、导弹等设备包括通信设备、电子战设备等车辆包括坦克、战车、无人车等飞机包括战斗机、轰炸机、无人机等舰艇包括航母、驱逐舰、潜艇等人员人员类实体国家国家类实体时间时间类实体地点地点类实体步骤s2-2)三元组要素抽取器的第二预处理模块对输入的三元组谓词抽取训练样本的句子及其真实谓词短语进行预处理,输出词嵌入表示;步骤s2-3)第二预训练语言模型对输入的词嵌入表示进行编码,得到序列隐状态表示,分别输出至三元组要素抽取器的三头指针网络和命名实体识别器的自注意力加权模块;步骤s2-4)三头指针网络基于序列隐状态表示,预测三元组要素短语在句子中位置;步骤s2-5)通过预测的三元组要素短语在句子中位置和步骤s2-1)标注的真实要素短语位置,计算交叉熵损失函数步骤s2-6)自注意力加权模块基于标注的要素短语位置和序列隐状态表示,计算并输出标注的要素短语的隐状态表示;步骤s2-7感知机分类器基于要素短语的隐状态表示,预测要素的命名实体类别;步骤s2-8)通过预测的要素的命名实体类别与步骤s2-1)标注的真实命名实体类型,计算交叉熵损失函数步骤s2-9)计算总损失函数连同第二预训练语言模型一起进行微调,由此联合训练三元组要素抽取器和命名实体识别器。本发明的技术创新点主要包括:1、本发明设计了一个基于神经网络的三元组谓词抽取器,可能的替换方案是使用基于词性标注的谓词抽取器。2、本发明设计了一个基于多头指针网络的三元组要素抽取器,可能的替换方案是使用基于序列标注的要素抽取器。3、本发明设计了一个复用隐状态表示的要素命名实体识别器,可能的替换方案是使用基于序列标注的命名实体识别器。最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制。尽管参照实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,对本发明的技术方案进行修改或者等同替换,都不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1