一种基于数据重采样的类不平衡软件缺陷预测方法
本发明属于软件缺陷预测领域,具体涉及一种基于数据重采样的类不平衡软件缺陷预测方法。
背景技术:
随着社会的发展与科学技术的提升,互联网已经深入的融合到我们的生活中的方方面面,无论是网上购物,出门坐车,智能家居,餐厅点餐等我们日常生活中的各种活动都可以通过软件完成,软件的使用场景已经渗透在我们吃穿住行等方方面面。在软件开发的过程中,软件功能需求不断的增加,软件服务的人群数量在不断的增加,软件开发时间不断的被压缩,各种问题导致在软件开发的过程中,软件很容易出现缺陷,软件缺陷的发生会使得软件不能提供正常的功能,会造成巨大的生产和经济损失,给人们的正常生活造成巨大的影响,因此竭力避免软件缺陷的发生是重要且必要的,因此在软件开发过程中进行软件缺陷预测能够帮助开发人员尽快的发现在软件开发过程中发生的缺陷,能够及时的进行软件缺陷的代码修改,从而避免各种生产经济损失。
然而在现实开发环境中,存在软件缺陷的数据是远远小于不存在软件缺陷的数据的,这时候构建的软件缺陷预测模型,更不容易发现存在软件缺陷的代码模块,然而理想的软件缺陷预测模型需要对存在缺陷的数据更敏感,能够更加精确的预测出代码模块是否存在缺陷,因此解决软件缺陷预测的类不平衡问题变得十分重要。针对上面的不足,本发明提出了一个类不平衡软件缺陷预测方法。
技术实现要素:
本发明主要目的是解决软件缺陷预测中的类不平衡问题提出一个类不平衡问题软件缺陷预测方法,普遍适用于软件缺陷预测。为了实现上述目的,本发明包括如下步骤:
步骤1,选取少数类数据集合中任意个少数类数据依次与少数类数据集合中每个少数类数据进行欧式距离计算,在少数类数据集合中筛选出与选取的少数类数据距离最近的少数类数据,选取少数类数据集合中任意个少数类数据依次与多数类数据集合中每个多数类数据进行欧式距离计算,在多数类数据集合中筛选出与选取的少数类数据距离最近的多数类数据,根据选取的少数类数据与少数类数据集合中每个少数类数据最近欧式距离、根据选取的少数类数据与多数类数据集合中每个少数类数据最近欧式距离计算选取的少数类数据的距离参数;在少数类数据集合中根据少数类数据的距离参数对少数类数据进行标记,并得到少数类数据的数据点类型;计算少数类数据集合中每个少数类数据的k近邻点集合,进一步在每个少数类数据的k近邻点集合划分为k近邻点多数类数据集合、k近邻点少数类数据集合,分别统计k近邻点多数类数据集合中多数类数据的数量、k近邻点少数类数据集合中少数类数据的数量,计算少数类数据集合中每个少数类数据的新生成的少数类数据数量;
步骤2,分别选择第一分类器、第二分类器,对新生成的软件缺陷预测少数类数据进行置信度评价,得到训练数据集;
步骤3,运用步骤2选择的第一分类器、第二分类器以及得到的训练集s′,通过加权投票得到最终的预测结果;
作为优选,步骤1所述软件缺陷数据为:s={smin,smax};
步骤1所述少数类数据集合为:
步骤1所述多数类数据集合为:
其中,smin表示少数类数据集合,用smax表示多数类数据集合,pi表示少数类数据集合中第i个少数类数据,i∈[1,n],n表示少数类数据集合中少数类数据的数量,dk表示多数类数据集合中第k个多数类数据,k∈[1,k],k表示多数类数据集合中多数类数据的数量;
步骤1所述与选取的少数类数据距离最近的少数类数据为:
其中,
步骤1所述与选取的少数类数据距离最近的多数类数据为:
其中,
步骤1所述选取的少数类数据与少数类数据集合中每个少数类数据最近欧式距离为:
步骤1所述选取的少数类数据与多数类数据集合中每个多数类数据最近欧式距离为:
步骤1所述计算选取的少数类数据的距离参数为:
其中,∝i为少数类数据集合中第i个少数类数据的距离参数;
步骤1所述在少数类数据集合中根据少数类数据的距离参数对少数类数据进行标记为:
若∝i<1,则少数类数据集合中与选取的第i个少数类数据的数据点类型标记为安全点,flagi=1;
若∝i=1,则少数类数据集合中与选取的第i个少数类数据的数据点类型标记为混淆点,flagi=2;
若∝i>1,则少数类数据集合中与选取的第i个少数类数据的数据点类型标记为危险点,flagi=3;
步骤1所述计算少数类数据集合中每个少数类数据的k近邻点集合:
步骤1所述在每个少数类数据的k近邻点集合划分为k近邻点多数类数据集合、k近邻点少数类数据集合,具体为:
步骤1所述k近邻点多数类数据集合中多数类数据的数量,记为
步骤1所述k近邻点少数类数据集合中少数类数据的数量,记为
步骤1所述计算少数类数据集合中每个少数类数据的新生成的少数类数据数量,具体为:
其中,∝i为少数类数据集合中第i个少数类数据的距离参数,ni为少数类数据集合中第i个每个少数类数据的新生成的少数类数据数量;
步骤1所述,计算新生成的软件缺陷预测数据;
步骤1所述,少数类数据集合中第i个少数类数据会生成ni新少数类数据,因此将新生成的少数类数据用pnewi,j来表示,其中j∈[1,ni]
步骤1所述少数类数据集合中第i个少数类数据的第j个新生成数据的偏离多数类的偏量,记做εi,j;
其中少数类数据集合中第i个少数类数据的第j个新生成数据的偏离多数类的偏量εi,j,其计算公式为:
其中,
步骤1所述少数类数据集合中第i个少数类数据的第j个新生成数据偏向多数类的偏量,记做σi,j;
步骤1所述少数类数据集合中第i个少数类数据的第j个新生成数据偏向多数类的偏量σi,j,其计算公式为:
其中,
步骤1所述新生成的软件缺陷预测数据少数类数据,记做pnewi,j;
新生成的软件缺陷预测数据第i个少数类数据的第j个新生成数据计算公式为:
步骤1所述得到新成少数类数据集,记做snew;
步骤1所述少数类点pi新生成缺陷数据的个数ni,按照上面生成的少数类数据pnew的方式,得到新成少数类数据集snew。
其中,
作为优选,所述步骤2具体如下:
步骤2所述分别计算第一分类器的影响程度、第二分类器的影响程度;
步骤2所述利用新成少数类数据集snew训练第一分类器h1,利用新成少数类数据集snew,依次带入第一分类器h1,得到预测的类别lp1,对于snew中的第i个点p’i,其弱标记为
利用新成少数类数据集snew训练第二分类器h2,利用新成少数类数据集snew依次带入第二分类器h2,得到预测的类别lp2,对于snew中的第i个点p′i,其弱标记为
所述第一分类器的影响程度为:
其中,n为少数类数据集合smin元素个数,第一分类器h1预测类别与弱标记lw类别相同
所述第二分类器的影响程度为:
其中,n为少数类数据集合smin元素个数,第一分类器h1预测类别与弱标记lw类别相同
步骤2所述根据第一分类器的影响程度、第二分类器的影响程度更新少数类数据的标签更新少数类数据的标签,以构建更新后原始软件缺陷数据;
步骤2所述,计算弱标记
步骤2所述,对新少数类数据集的弱标记
步骤2所述,新成少数类数据即snew被重新进行筛选,得到新成少数类数据snew′,将snew′加入原始软件缺陷数据s得到新训练集s′;
作为优选,所述步骤3具体包括下述步骤:
得到新训练数据集s′后,训练第一分类器h1和第二分类器h2,通过训练好的第一分类器h1和第二分类器h2预测数据v分别得到第一分类器预测结果l1和第二分类器l2,继续利用第一分类器的影响程度o1和第二分类器的影响程度o2,利用计算公式lpre=l1*o1+l2*o2的值来得到预测结果;
步骤3所述,当lpre值大于β的时候,预测v的类别为少数类;
步骤3所述,当lpre的值小于等于β的时候,预测v的类别为多数类;
与现有技术相比,本发明的优点和积极效果在于:
本发明能够良好的解决类不平衡问题。
本文增加了对新生成少数类数据的筛选过程,去除掉偏离实际的数据,保留能够表现出少数类真实特征的数据。
本文提出了一个能解决类不平衡的软件缺陷预测方法,能够广泛的适用于各种软件缺陷数据并且解决类不平衡问题。
附图说明
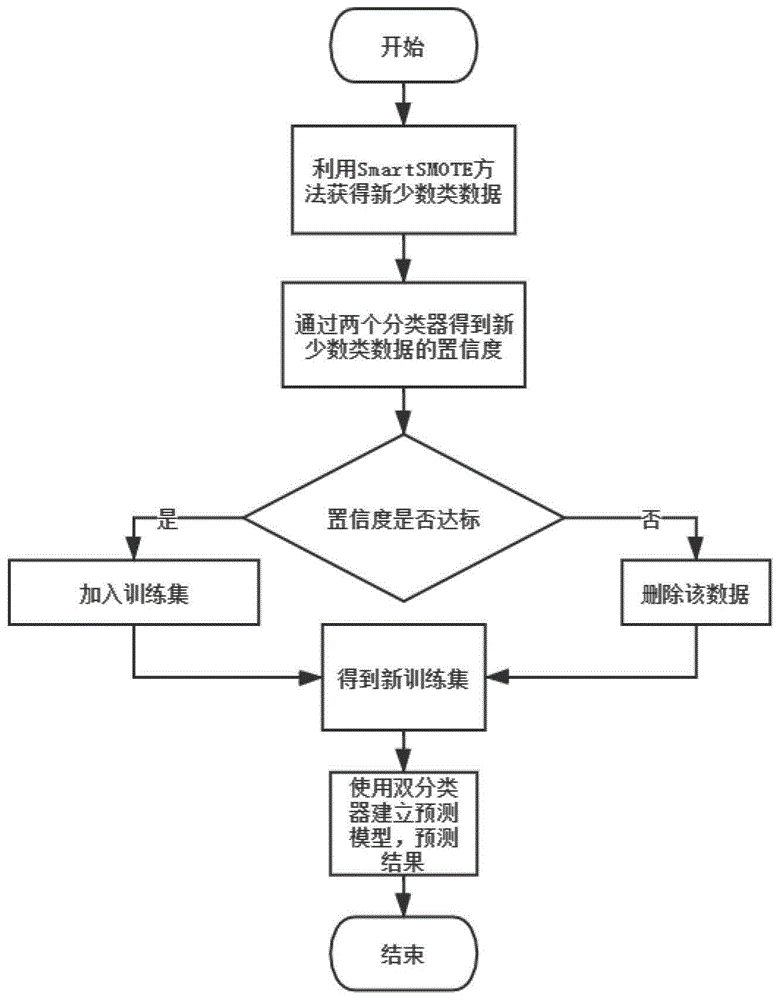
图1:为本发明的类不平衡的软件缺陷预测方法图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图和具体实施对本发明做进一步描述,在此仅用本发明的适宜性实例说明来解释本发明,但并不作为本发明的限定。
本发明的总实施流程图如图1所示,具体实施如下:
步骤1,选取少数类数据集合中任意个少数类数据依次与少数类数据集合中每个少数类数据进行欧式距离计算,在少数类数据集合中筛选出与选取的少数类数据距离最近的少数类数据,选取少数类数据集合中任意个少数类数据依次与多数类数据集合中每个多数类数据进行欧式距离计算,在多数类数据集合中筛选出与选取的少数类数据距离最近的多数类数据,根据选取的少数类数据与少数类数据集合中每个少数类数据最近欧式距离、根据选取的少数类数据与多数类数据集合中每个少数类数据最近欧式距离计算选取的少数类数据的距离参数;在少数类数据集合中根据少数类数据的距离参数对少数类数据进行标记,并得到少数类数据的数据点类型;计算少数类数据集合中每个少数类数据的k近邻点集合,进一步在每个少数类数据的k近邻点集合划分为k近邻点多数类数据集合、k近邻点少数类数据集合,分别统计k近邻点多数类数据集合中多数类数据的数量、k近邻点少数类数据集合中少数类数据的数量,计算少数类数据集合中每个少数类数据的新生成的少数类数据数量。
步骤1所述软件缺陷数据为:s={smin,smax};
步骤1所述少数类数据集合为:
步骤1所述多数类数据集合为:
其中,smin表示少数类数据集合,用smax表示多数类数据集合,pi表示少数类数据集合中第i个少数类数据,i∈[1,n],n表示少数类数据集合中少数类数据的数量,dk表示多数类数据集合中第k个多数类数据,k∈[1,k],k表示多数类数据集合中多数类数据的数量;
步骤1所述与选取的少数类数据距离最近的少数类数据为:
其中,
步骤1所述与选取的少数类数据距离最近的多数类数据为:
其中,
步骤1所述选取的少数类数据与少数类数据集合中每个少数类数据最近欧式距离为:
步骤1所述选取的少数类数据与多数类数据集合中每个多数类数据最近欧式距离为:
步骤1所述计算选取的少数类数据的距离参数为:
其中,∝i为少数类数据集合中第i个少数类数据的距离参数;
步骤1所述在少数类数据集合中根据少数类数据的距离参数对少数类数据进行标记为:
若∝i<1,则少数类数据集合中与选取的第i个少数类数据的数据点类型标记为安全点,flagi=1;
若∝i=1,则少数类数据集合中与选取的第i个少数类数据的数据点类型标记为混淆点,flagi=2;
若∝i>1,则少数类数据集合中与选取的第i个少数类数据的数据点类型标记为危险点,flagi=3;
步骤1所述计算少数类数据集合中每个少数类数据的k近邻点集合,实验设置k=5:
步骤1所述在每个少数类数据的k近邻点集合划分为k近邻点多数类数据集合、k近邻点少数类数据集合,具体为:
步骤1所述k近邻点多数类数据集合中多数类数据的数量,记为
步骤1所述k近邻点少数类数据集合中少数类数据的数量,记为
步骤1所述计算少数类数据集合中每个少数类数据的新生成的少数类数据数量,具体为:
其中,∝i为少数类数据集合中第i个少数类数据的距离参数,ni为少数类数据集合中第i个每个少数类数据的新生成的少数类数据数量;
步骤1所述,计算新生成的软件缺陷预测数据;
步骤1所述,少数类数据集合中第i个少数类数据会生成ni新少数类数据,因此将新生成的少数类数据用pnewi,j来表示,其中j∈[1,ni]
步骤1所述少数类数据集合中第i个少数类数据的第j个新生成数据的偏离多数类的偏量,记做εi,j;
其中少数类数据集合中第i个少数类数据的第j个新生成数据的偏离多数类的偏量εi,j,其计算公式为:
其中,
步骤1所述少数类数据集合中第i个少数类数据的第j个新生成数据偏向多数类的偏量,记做σi,j;
步骤1所述少数类数据集合中第i个少数类数据的第j个新生成数据偏向多数类的偏量σi,j,其计算公式为:
其中,
步骤1所述新生成的软件缺陷预测数据少数类数据,记做pnewi,j;
新生成的软件缺陷预测数据第i个少数类数据的第j个新生成数据计算公式为:
pnewi,j=pi+εi,j+σi,j
步骤1所述得到新成少数类数据集,记做snew;
步骤1所述少数类点pi新生成缺陷数据的个数ni,按照上面生成的少数类数据pnew的方式,得到新成少数类数据集snew。
其中,
步骤2,分别选择第一分类器、第二分类器,对新生成的软件缺陷预测少数类数据进行置信度评价,得到训练数据集;
所述步骤2具体如下:
步骤2所述分别计算第一分类器的影响程度、第二分类器的影响程度;
步骤2所述利用新成少数类数据集snew训练第一分类器h1,利用新成少数类数据集snew,依次带入第一分类器h1,得到预测的类别lp1,对于snew中的第i个点p’i,其弱标记为
利用新成少数类数据集snew训练第二分类器h2,利用新成少数类数据集snew依次带入第二分类器h2,得到预测的类别lp2,对于snew中的第i个点p’i,其弱标记为
所述第一分类器的影响程度为:
其中,n为少数类数据集合smin元素个数,第一分类器h1预测类别与弱标记lw类别相同
所述第二分类器的影响程度为:
其中,n为少数类数据集合smin元素个数,第一分类器h1预测类别与弱标记lw类别相同
步骤2所述根据第一分类器的影响程度、第二分类器的影响程度更新少数类数据的标签更新少数类数据的标签,以构建更新后原始软件缺陷数据;
步骤2所述,计算弱标记
步骤2所述,对新少数类数据集的弱标记
步骤2所述,新成少数类数据即snew被重新进行筛选,得到新成少数类数据snew′,将snew′加入原始软件缺陷数据s得到新训练集s′;
步骤3,运用步骤2选择的第一分类器、第二分类器以及得到的训练集s′,通过加权投票得到最终的预测结果;
所述步骤3具体包括下述步骤:
得到新训练数据集s′后,训练第一分类器h1和第二分类器h2,通过训练好的第一分类器h1和第二分类器h2预测数据v分别得到第一分类器预测结果l1和第二分类器l2,继续利用第一分类器的影响程度o1和第二分类器的影响程度o2,利用计算公式lpre=l1*o1+l2*o2的值来得到预测结果;
步骤3所述,当lpre值大于β=0.5的时候,预测v的类别为少数类;
步骤3所述,当lpre的值小于等于β=0.5的时候,预测v的类别为多数类;。
本实施例将本发明的方法与现有的一些主流的smote+svm、smote+决策树、smote+k近邻、smote+朴素贝叶斯方法进行了比较,选取了精度、f-measure、平衡度、auc指标比较结果。在对比的所有方法中,本发明方法的准确率最高,识别准确率已经达到了领域先进水平。
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明所述系统及其实施方法所做的同等变化,都应涵盖在本发明的保护范围之内。因此,本发明的保护范围应该以权利要求的保护范围为准。
- 还没有人留言评论。精彩留言会获得点赞!