基于半监督对抗学习的冠脉造影血管图像分割的方法
本发明属于医学技术领域,具体涉及一种基于半监督对抗学习的冠脉造影血管图像分割的方法。
背景技术:
半监督对抗学习是一种不需要过多标注数据的方法,相比于监督学习需要大量的人工标注数据,半监督对抗学习只需要少量的标注数据和大量的未标注数据即可。随着深度学习中半监督学习和对抗网络的出现,并且半监督学习和对抗网络已经在很多图像处理领域取得了巨大的成就。因此,使用深度学习来解决冠脉造影血管图像分割问题是将来研究的重点,并在此基础上结合利用半监督学习和生成对抗网络的方法来进行分割,解决了样本标注不足的问题。
半监督学习有一个非常吸引人的优点,它不需要大量的标注数据,它可以在模型训练中利用大量未标记的数据,从而可以大大减轻人工标注的任务。生成对抗网络的对抗学习也应用到了语义分割当中,将这两者结合可以在血管分割方法取得一些进展。一个典型的对抗网络由两个子网络组成,即生成器和鉴别器,让生成器和鉴别器进行博弈,从而可以产生不错的输出。在此背景下,我们的分割网络作为对抗网络的生成器,鉴别器采用一个完全卷积的网络作为鉴别器网络,分割网络对输入图像进行分割预测,使得所得的预测图接近groundtruth图。对抗学习是让分割网络和鉴别器进行博弈,在训练过程中通过相互竞争让它们同时得到增强,最终使分割网络达到一个好的分割效果。
技术实现要素:
本发明提供了一种利用半监督对抗学习网络来对冠脉造影血管图像进行分割预测,完成冠脉造影血管分割任务的方法。
一种基于半监督对抗学习的冠脉造影血管图像分割的方法,包括以下步骤:
(1)获取实验所需要的冠脉造影数据,其中包括标注数据和未标注数据;
(2)用带标注的数据对鉴别器网络和分割网络进行训练,鉴别器网络受损失函数ld监督训练,分割网络受dice损失ldice和对抗损失ladv监督训练;
(3)用未标注数据对分割网络进行训练,此时分割网络受鉴别器网络生成的置信度图和半监督损失lsemi监督训练;
(4)在训练的过程中,鉴别器网络学习区分groundtruth图和分割网络的分割预测图,而损失函数ldice和ladv则鼓励分割网络产生接近groundtruth图的预测概率图,鉴别器网络与分割网络之间的关系构成了对抗学习;
(5)上述(2)、(3)和(4)步骤重复训练,直到分割网络的训练完成,训练完成后保存模型,该模型即是我们所要的分割预测模型;
所述分割网络为经典的医学图像分割网络unet,鉴别器网络为一个全卷积网络,所述对抗学习是让分割网络和鉴别器进行博弈,在训练过程中通过相互竞争让它们同时得到增强,最终使分割网络达到一个好的分割效果。
本发明技术方案的进一步改进在于:所述的鉴别器网络由5个卷积层组成,分别具有4×4的核和{64,128,256,512,1}个通道,步长为2,第1,2,3,4个卷积层后面都有一个由0.01参数化的leaky-relu,在最后一层卷积层后面添加一个上采样层,以将输出重新缩放到输入映射的大小,从而将模型转换成全卷积网络;leaky-relu的激活公式如下:
本发明技术方案的进一步改进在于:分割网络采用unet网络,unet分为收缩路径和扩展路径,收缩路径是经典的卷积网络结构,由五个相同的模块组成,每个模块包括两个卷积核大小均为3×3的卷积和一个激活函数relu,第1,2,3,4个模块后面包含一个2x2的步长为2的最大池化层;扩展路径中的每一步包括对特征映射先进行上采样,然后进行2x2卷积,该卷积为up-convolution;该特征映射将特征通道的数量减半,与收缩路径中相应裁剪的特征拼接起来,然后后接两个3x3卷积,每个卷积后都有一个激活函数relu;在最后一层,使用1x1卷积来将每个64通道特征图映射到特定深度并且使用softmax输出来匹配输入图像的大小。
本发明技术方案的进一步改进在于:训练鉴别器的损失函数为:
ld=-∑h,w(1-yn)log(1-d(s(xn))(h,w))+ynlog(d(yn)(h,w))(2)
其中,ld是鉴别器网络的损失函数,d(s(xn))(h,w)是输入图像x在位置(h,w)的置信度图,d(yn)(h,w)是one-hot编码后groundtruth向量yn的置信度图;其中如果样本来自分割网络,则yn=0,如果样本来自groundtruth,则yn=1;训练鉴别器使用标注的数据;训练分割网络的损失函数为:
lseg=λadvladv+λsemilsemi(3)
其中ladv和lsemi分别为对抗损失和半监督损失;在式(3)中,用λadv和λsemi两个权值来最小化所提出的多任务损失函数;
通过鉴别器网络中的对抗损失来使用对抗学习过程,对抗损失为:
ladv=-∑h,wlog(d(s(xn))(h,w))(4)
应用所述损失训练分割网络,通过最大化从groundtruth分布生成预测结果的概率欺骗鉴别器,在自学框架内使用训练有素的鉴别器和未标记的数据所产生的半监督损失函数为:
其中i(·)是指标函数,tsemi是控制自学过程灵敏度的阈值。
本发明技术方案的进一步改进在于:步骤(3)所述的置信度图用来推断与groundtruth足够接近的区域,而通过训练的分割网络可以最大化生成与groundtruth分布相近的预测结果,从而能骗过鉴别器。
由于采用了上述技术方案,本发明取得的技术效果如下:
本申请首次将半监督对抗学习的方法应用在冠脉造影血管分割,可以大大缓解冠脉造影标注数据紧缺的问题,从而帮医生减轻标注工作量。主要解决了针对当前医学图像数据集比较缺少的问题,提出使用半监督对抗学习的方法对我们所采集的冠脉造影血管图像进行分割,使得我们的数据集在不需要大量的人工标注的情况下即可达到我们所要的分割效果,解决了医学图像冠脉造影数据紧缺的问题。
附图说明
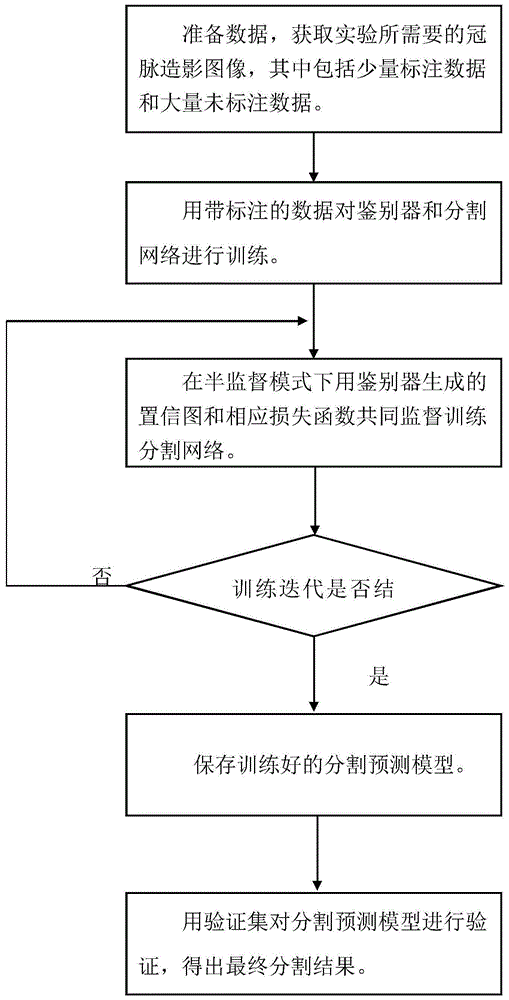
图1是本发明的总体框架线路图;
图2是本发明整体技术路线图;
图3是本发明分割网络结构;
图4是本发明鉴别器网络结构。
具体实施方式
在我们的方法中,我们的发明整体技术路线图如图2所示,其中我们采用unet网络作为我们的分割网络如图3,unet网络在医学图像分割领域一直表现很好,因此选用它作为我们的分割网络。unet分为收缩路径和扩展路径,收缩路径是经典的卷积网络结构,由五个相同的模块组成,每个模块包括两个卷积核大小均为3x3的卷积和一个激活函数relu,第1,2,3,4个模块后面均包含一个2x2的步长为2的最大池化层。扩展路径中的每一步包括对特征映射先进行上采样,然后进行2x2卷积,该卷积为up-convolution。该特征映射将特征通道的数量减半,与收缩路径中相应裁剪的特征拼接起来,然后后接两个3x3卷积,每个卷积都有一个激活函数relu。由于每个卷积中边界像素的丢失,裁剪是必要的。在最后一层,使用1x1卷积来将每个64通道特征图映射到特定深度并且使用softmax输出来匹配输入图像的大小。
鉴别器网络如图4,由5个卷积层组成,它们分别具有4×4的卷积核和{64,128,256,512,1}个通道,步长为2,第1,2,3,4个卷积层后面都有一个由0.01参数化的leaky-relu激活函数,通过在最后一层添加一个上采样层,以将输出重新缩放到输入映射的大小,从而将模型转换成全卷积网络。
其中当输入数据为带标注的数据时,鉴别器网络受损失函数ld监督训练,分割网络受dice损失ldice和对抗损失ladv监督训练,其中ld、ldice、ladv的表达式如下:
ld=-∑h,w(1-yn)log(1-d(s(xn))(h,w))+ynlog(d(yn)(h,w))(2)
ldice=1-2|s(xn)∩yn|/(s(xn)+yn)(6)
ladv=-∑h,wlog(d(s(xn))(h,w))(4)
损失函数ld负责监督训练鉴别器网络,通过训练鉴别器网络,可以提高鉴别器网络区分groundtruth图与分割网络的分割预测图的能力。损失函数dice损失ldice和对抗损失ladv负责监督训练分割网络,其中对抗损失可以使分割网络最大化从groundtruth分布生成预测结果的概率来欺骗鉴别器。
当输入数据为未带标注的数据时,分割网络受鉴别器所生成的置信度图和半监督损失lsemi共同监督训练。其中鉴别器网络计算出分割预测的置信度图,然后以此为一个监督信号,结合半监督损失lsemi来训练分割网络。损失函数lsemi如下:
最后的分割网络的损失函数为:
lseg=λadvladv+λsemilsemi(3)
当最后的训练完成后,保存我们的分割预测模型,再利用验证集验证该模型,则该分割预测模型即是我们所想要的。
一种基于半监督学习和生成对抗网络的新型分割方法,并基于unet网络结构来完成我们的血管分割任务,该技术还未在冠脉造影图像上实施过,通过利用半监督对抗学习来解决冠脉造影标注数据紧缺的问题,其总体线路如图1所示,具体做法如下:
1.准备数据,获取实验所需要的冠脉造影数据,其中包括标注数据和未标注数据。我们的血管数据集是我们亲自去医院进行采集的冠脉造影图像,然后经过专业人士进行标注所得。我们将其分为训练集和验证集,并对训练集进行图像预处理,其中数据集中的一小部分图像为标注图像,其余大部分为原始图像。
2.利用带标注的数据对分割网络和鉴别器进行训练。
分割网络采用unet网络结构。unet分为收缩路径和扩展路径,收缩路径是经典的卷积网络结构,由五个相同的模块组成,每个模块包括两个卷积核大小均为3×3的卷积和一个激活函数relu,第1,2,3,4个模块后面均包含一个2x2的步长为2的最大池化层。扩展路径中的每一步包括对特征映射先进行上采样,然后进行2x2卷积,该卷积为up-convolution。该特征映射将特征通道的数量减半,与收缩路径中相应裁剪的特征拼接起来,然后后接两个3x3卷积,每个卷积都有一个激活函数relu。由于每个卷积中边界像素的丢失,裁剪是必要的。在最后一层,使用1x1卷积来将每个64通道特征图映射到特定深度并且使用softmax输出来匹配输入图像的大小。
鉴别器网络由5个卷积层组成,分别具有4×4的核和{64,128,256,512,1}个通道,步长为2,第1,2,3,4个卷积层后面都有一个由0.01参数化的leaky-relu激活函数,通过在最后一层添加了一个上采样层,以将输出重新缩放到输入映射的大小,从而将模型转换成全卷积网络。激活公式如下:
用带标注的图像对鉴别器网络和分割网络进行迭代训练,损失函数ld负责监督训练鉴别器网络,分割网络受dice损失ldice和对抗损失ladv监督训练,其中对抗损失如下:
ladv=-∑h,wlog(d(s(xn))(h,w))(4)
有了这个损失,我们训练分割网络,通过最大化从groundtruth分布生成预测结果的概率来欺骗鉴别器网络,而鉴别器网络则通过训练以及生成的置信图学习区分groundtruth图和分割网络的分割预测的概率图。
3.将分割预测图传递给鉴别器网络来计算置信度图,以此为监控信号,然后使用自学方案训练具有masked交叉熵损失的分割网络,从而训练出分割预测模型。
4.利用验证集对分割预测模型进行验证,得到最终分割结果。
- 还没有人留言评论。精彩留言会获得点赞!