基于强化学习的大型电动汽车充电站的充电优化调度方法
本发明涉及一种基于强化学习的大型电动汽车充电站的充电优化调度方法,属于智能优化调度技术领域。
背景技术:
当今社会随着人们对环境问题的日益关切,能源需求逐渐增大,日常能源消耗量也日益增大,电动汽车作为新型交通工具,凭借其污染轻、噪声小和驾驶成本低等特性取得了长足的发展。但是大规模电动汽车接入电网会对电力系统的平稳运行造成极大的影响。与燃油汽车能够迅速加油瞬间完成能量的补充不同,电动汽车的充电过程具有一定的周期性,考虑到大多数用户选择在无出行需求的时段将汽车暂放于充电站充电以及不同时段电价的变化等实际情况,对电动汽车充电站的充电调度方法进行研究。
目前传统的充电站还采用人工调度的方案,大多充电站采取先到先充电策略,并未充分考虑电网的负载以及电价的实时变化,经济效益以及充电效率低下。而在电动汽车充电调度策略领域的学术研究主要采用模型预测控制,但是在充电汽车的实际环境中,对于充电站而言,电动汽车的达到时间具有不确定性,客户的主动行为具有随机性(如延迟取车,提前取消订单),因而运用的固定的调度模型求解获取调度方案效果有限,而且对于不同的规模的充电站不具备通用性。因而当下怎样解决调度模型的通用性以及最大化能源和经济效益是各个电动汽车充电站迫切需要解决的问题。
技术实现要素:
本发明目的在于提出了一种基于强化学习的大型电动汽车充电站的电动汽车充电优化调度方法。
本发明具体包括如下步骤:
步骤一、数据集准备:
直接采集充电站内历史数据,为状态空间矩阵和动作空间矩阵的创建做准备;所需要的数据主要包括电动汽车的到达充电站的时间tarrival、离开充电站的时间δtdepart以及其充电需求w;为方便计量,将充电需求转化为电动汽车充满所需要的充电时间δtcharge;
步骤二、定义状态空间:
电动汽车充电特征:电动汽车到达时间、电动汽车离开时间、需要的充电量和电动汽车充电率;由于未来电动汽车的到达时间未知,因此在当前的电动汽车表示中不包括到达时间;如果电动汽车的充电率ws,则充电量转换为完成充电所需的时间为:
δtcharge=w/ws(1);
如果系统中有ns辆电动汽车,则其特征v表示为如下所示集合:
式子(1)中
每个状态空间s=(t,xs),xs表示总需求矩阵,t∈{1,…,smax}表示时隙,其中smax表示按照给定的时间间隙δtslot划分的一天中的最大决策时间段数;每个给定时隙δtslot的总需求通过合并算法获得,需求可以使用二维网格表示,即矩阵xs,一个轴表示汽车的离开时间δtdepart,另一个轴表示汽车的充电时间δtcharge;所得总需求矩阵xs具有尺寸smax×smax,最大的决策时间段数smax取决于最大连接时间hmax,即电动汽车连接到充电站的最长持续时间:smax=hmax/δtslot;确保最大电动汽车数量nmax不会影响状态空间的大小;
根据电动汽车的离开时间和所需充电量,将电动汽车的允许调度空间即充电灵活性表示为δtflex=δtdepart-δtcharge,从xs的对角线推断出:
根据上述公式,矩阵xs主对角线上的单元中的电动汽车的灵活性为零;而xs上对角线上的单元中的电动汽车可调度安排,即充电可延迟;负δtflex对应于xs中较低对角线,表示无法满足其充电需求的电动汽车;
步骤三、定义动作空间:
将状态空间s=(t,xs)采取的动作表示是否对当前连接的电动汽车充电z,将基于充电灵活性δtflex做出决策;步骤二中具有相同充电灵活性δtflex的电动汽车会被合并到xs的相同对角线上的单元中;将xs的每个对角线表示为xs(d),其中d=0,…,smax-1,xs(0)是主对角线,xs(d)表示矩阵上三角的第d条对角线,而xs(-d)是xs的下三角的第d对角线;将
步骤四、建立动作价值函数:
为使得一组电动汽车的充电负载保持平稳,同时确保在每辆电动汽车离开前已完成充电需求及尽可能的降低电价成本;通过动作us从状态s过渡到s'价值函数包括三部分:
c(s,us,s')=cdemand(xs,us)+cpenalty(xs')+celectricity(ns,p,st)(4);
其中,cdemand(xs,us)是时隙中所有已连接的电动汽车的总功耗成本,cpenalty(xs')是未完成充电的惩罚函数,celectricity(ns,p,st)为当前时隙下的电价成本;
为了实现负载均衡,选择cdemand作为时隙总功耗的二次函数;所有电动汽车的充电率均相同,因此时隙中的总功耗与要充电的电动汽车数量成正比;因此,c(s,us,s')转换价值函数的第一部分为:
式子(4)中
由于在当前状态s=(t,xs)中采取动作生成下一个状态s'=(t+1,xs');价值函数的第二项是跟下一个状态s'=(t+1,xs')有关的一个惩罚项,故价值函数的第二部分为:
m为一个恒定的惩罚因子,将其设置为大于2nmax,以确保任何电动汽车的充电始终在出发前完成,
根据当前的实时的电价水平、目前状态下充电桩的连接个数以及电桩的平均充电功率,设计电站的分时电价成本,故价值函数的第三部分为:
式子(6)中ns表示在状态s下充电桩被连接的数量,p表示充电桩的平均充电功率,st表示t时刻的电价;
步骤五、数据处理:
根据步骤二、步骤三及步骤四对于状态空间和动作空间的定义以及价值函数模型的建立,对步骤一所采集的数据进行处理,以一天上午某时刻充电站的车辆情况作为当前状态s,以晚上某时刻作为一天的最后一个状态;随机的采取动作us,并以元组(s,us,s',c(s,us,s'))的形式记录组成数据集;并将数据集分为两个部分,一部分数据作为神经网络训练集,另一部分数据作为神经网络测试集;
步骤六、神经网络训练:
首先构建一个含有一个输入神经元,两个具有激励函数的隐藏层以及一个输出层的神经网络,然后将步骤五所整理的训练数据集元组中的状态动作对(s,u)以长度为
其中qn(s,us)的初始迭代值为c(s,us,s'),每次的输出均可以保证整体的动作价值函数的累加和为最小,为了稳定学习过程,使用huber损失代替均方差误差;循环迭代t次后,神经网络隐藏层之间的权重相对固定,自此神经网络模型训练结束;
步骤七、利用测试集元组数据测试模型:
根据步骤六所训练的神经网络模型,运用步骤五所得的测试集数据对模型进行测试;在对模型测试时,构造评价函数,用于评价神经网络模型的有效性;评价函数如下:
其中βtest表示测试集数据长度,e为测试集数据的子集,
步骤八、调度方案生成:
充电站根据当下充电站所到达的电动汽车的离开时间和充电需求,作为神经网络的输入,经过神经网络模型的迭代循环,最终得到该输入条件下最优的价值函数;提取每次迭代得到的价值函数所采取的动作,迭代结束后将所有的动作整合成最优动作集π*={u1,u2,…,ut},π*即为当前充电站所到达电动汽车的最优充电策略;
步骤九、执行调度方案:
当上述步骤执行完毕后,按照所生成的调度方案π*,对充电站内的电动汽车进行充电;如果有新的到达车辆,则返回步骤8,根据当前车站内各个电动汽车的离开时间和充电需求,如果在此之前有些电动汽车已经充电一段时间了,则其充电需求为剩余充电时间;重新生成神经网络模型输入元组,迭代运算得到最优价值函数;迭代结束后将所有的动作整合成最优动作集π*(π*={u1,u2,…,ut}),再根据该策略,对当前充电站内的电动汽车充电。
本发明以最小化电网负载和电价成本为优化目标,采用了基于强化学习的神经网络模型构建方法,根据充电站大量历史数据,训练模型,并通过测试集数据测试模型的有效性,然后根据每天到达充电站的车辆情况,确定输入变量,通过神经网络的迭代运算得到最优的目标函数值,并从迭代过程中提取每次状态迭代变化所采取的动作,最终所得的动作集即为最优调度策略。因为神经网络模型是通过大量历史数据训练所得,因而有效了解决了充电环境下的不确定性问题,而且相对于固定的预测控制模型而言,本发明的方法并不受限于充电站的规模以及充电站达到的电动汽车的数量,训练所得的模型更具有通用性,适用于不同规模下的电动汽车充电站。
附图说明
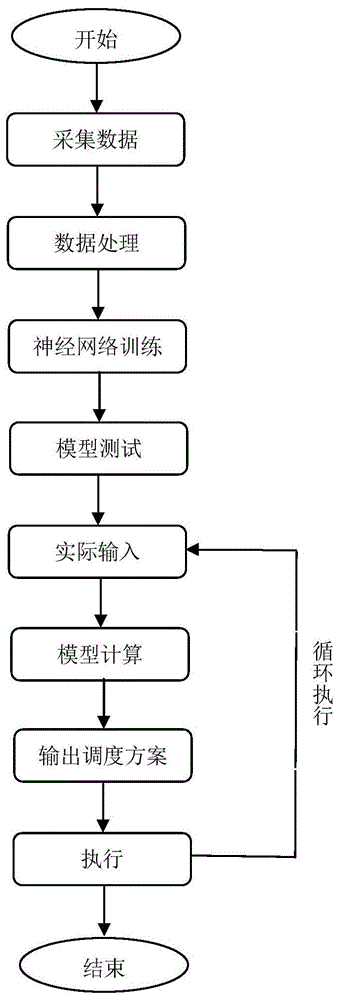
图1位本发明的流程图;
图2为本发明的状态空间构成示意图。
具体实施方式
以下结合附图对本发明进行进一步的描述。
如图1所示,一种基于强化学习的大型电动汽车充电站的电动汽车充电优化调度方法,具体包括如下步骤:
步骤一、数据集准备:
本方法所需的数据为充电站历史数据,可在现有的充电站内直接采集,为保证数据的有效性,可采取最近一整年内充电站的数据,为状态空间矩阵和动作空间矩阵的创建做准备。所需要的数据主要包括电动汽车的到达充电站的时间tarrival、离开充电站的时间δtdepart以及其充电需求w。对于电动汽车的充电需求,本发明将其转化为电动汽车充满所需要的充电时间δtcharge。
步骤二、定义状态空间:
电动汽车充电特征:(i)电动汽车到达时间,(ii)电动汽车离开时间,(iii)需要的充电量和(iv)电动汽车充电率。对于(i),由于假设不知道未来电动汽车的到达时间,因此在当前的电动汽车表示中不包括到达时间。对于(iii)和(iv),如果电动汽车的充电率ws,则充电量转换为完成充电所需的时间为:
δtcharge=w/ws(1);
因此,如果系统中有ns辆电动汽车,则其特征表示为如下所示集合
式子(1)中
对于每个状态s使用两个变量表示:时隙(t∈{1,…,smax})和总需求(xs),其中smax表示按照给定的时间间隙δtslot划分的一天中的最大决策时间段数,因此状态空间s=(t,xs)。每个给定时隙δtslot的总需求通过合并算法获得,需求可以使用二维网格表示,即矩阵xs,一个轴表示汽车的离开时间δtdepart,另一个轴表示汽车的充电时间δtcharge,如图2所示。所得总需求矩阵xs具有尺寸smax×smax,最大的决策时间段数smax取决于最大连接时间hmax,即电动汽车连接到充电站的最长持续时间:smax=hmax/δtslot。这确保了最大电动汽车数量nmax不会影响状态空间的大小。
本方法的状态表示具有可扩展性优点,它以紧凑和可比较的形式表示电动汽车的总需求(按照δtdepart和δtcharge的形式),而且电动汽车的允许调度空间即充电灵活性(表示为δtflex=δtdepart-δtcharge),可以很容易地从xs的对角线推断出:
根据上述公式,矩阵xs主对角线上的单元(即x=y)中的电动汽车的灵活性为零,而xs上对角线上的单元中的电动汽车是可调度安排的(即充电可延迟)。负δtflex对应于xs中较低对角线,表示无法满足其充电需求的电动汽车。
步骤三、定义动作空间:
在状态s=(t,xs)采取的动作表示是否对当前连接的电动汽车充电。将基于充电灵活性δtflex做出决策。步骤2所述,具有相同充电灵活性δtflex的电动汽车会被合并到xs的相同对角线上的单元中。将xs的每个对角线表示为xs(d),其中d=0,…,smax-1,xs(0)是主对角线,xs(d)表示矩阵上三角的第d条对角线,而xs(-d)是xs的下三角的第d对角线。将
步骤四、建立动作价值函数:
考虑的目标是使一组电动汽车的充电负载保持平稳,同时确保在每辆电动汽车离开前已完成充电需求及尽可能的降低电价成本。因此,通过动作us从状态s过渡到s'价值函数包括三部分:
c(s,us,s')=cdemand(xs,us)+cpenalty(xs')+celectricity(ns,p,st)(4);
其中,cdemand(xs,us)是时隙中所有已连接的电动汽车的总功耗成本,cpenalty(xs')是未完成充电的惩罚函数,celectricity(ns,p,st)为当前时隙下的电价成本。
为了实现负载均衡,选择cdemand作为时隙总功耗的二次函数。由于假设所有电动汽车的充电率均相同,因此时隙中的总功耗与要充电的电动汽车数量成正比。因此,c(s,us,s')转换价值函数的第一部分为:
式子(4)中
由于在当前状态s=(t,xs)中采取动作生成下一个状态s'=(t+1,xs')。价值函数的第二项是跟下一个状态s'=(t+1,xs')有关的一个惩罚项,故价值函数的第二部分为:
m为一个恒定的惩罚因子,将其设置为大于2nmax,以确保任何电动汽车的充电始终在出发前完成,
根据当前的实时的电价水平、目前状态下充电桩的连接个数以及电桩的平均充电功率,设计电站的分时电价成本,故价值函数的第三部分为:
式子(6)中ns表示在状态s下充电桩被连接的数量,p表示充电桩的平均充电功率,st表示t时刻的电价。
步骤五、数据处理:
根据步骤2、步骤3及步骤4对于状态空间和动作空间的定义以及价值函数模型的建立,对步骤1所采集的数据进行处理,以一天上午6点充电站的车辆情况作为当前状态s,以晚上12点作为一天的最后一个状态。随机的采取动作us,并以元组(s,us,s',c(s,us,s'))的形式记录组成数据集。并将数据集分为两个部分,前四分之三的数据为神经网络训练集,后四分之一的数据为神经网络测试集。
步骤六、神经网络训练:
首先构建一个含有一个输入神经元,两个具有激励函数的隐藏层以及一个输出层的神经网络,然后将步骤5所整理的训练数据集元组中的状态动作对(s,u)以长度为
其中qn(s,us)的初始迭代值为c(s,us,s'),每次的输出均可以保证整体的动作价值函数的累加和为最小,为了稳定学习过程,使用huber损失代替均方差误差。循环迭代t次后,神经网络隐藏层之间的权重相对固定,自此神经网络模型训练结束。
步骤七、利用测试集元组数据测试模型:
根据步骤6所训练的神经网络模型,运用步骤5所得的测试集数据对模型进行测试。在对模型测试时,本方法构造了评价函数,用于评价神经网络模型的有效性。评价函数如下:
其中βtest表示测试集数据长度,e为测试集数据的子集,
步骤八、调度方案生成:
充电站根据当下充电站所到达的电动汽车的离开时间和充电需求,作为神经网络的输入,经过神经网络模型的迭代循环,最终得到该输入条件下最优的价值函数。提取每次迭代得到的价值函数所采取的动作,迭代结束后将所有的动作整合成最优动作集π*(π*={u1,u2,…,ut}),π*即为当前充电站所到达电动汽车的最优充电策略。
步骤九、执行调度方案:
当上述步骤执行完毕后,按照所生成的调度方案π*,对充电站内的电动汽车进行充电。如果有新的到达车辆,则返回步骤8,根据当前车站内各个电动汽车的离开时间和充电需求(如果在此之前有些电动汽车已经充电一段时间了,则其充电需求为剩余充电时间),重新生成神经网络模型输入元组,迭代运算得到最优价值函数。迭代结束后将所有的动作整合成最优动作集π*(π*={u1,u2,…,ut}),再根据该策略,对当前充电站内的电动汽车充电。
- 还没有人留言评论。精彩留言会获得点赞!