一种医学影像数据的图像分割方法
本发明属于数据识别技术领域,具体涉及一种医学影像数据的图像分割方法。
背景技术:
医学图像分割是从x-ray、ct等医学诊断涉及的图像中分割出发生病变的像素点,这是目前医学图像领域最热门的研究方向之一。医学图像分割的目的是传递与提取医学图像中器官或组织的形状、体积等关键信息。
近些年来,卷积神经网络(cnn)被普遍用于医学图像分割,尤其是u-net神经网络结构,受到业界很多学者的追捧。通常情况下,u-net训练时使用的数据集与测试时使用的数据集如果来自相同的设备或者医院研究机构时,分割效果会很好。但是,如果训练用数据集与测试用数据集来自于不同的设备或研究机构时,u-net的分割效果往往很差,而造成这个问题的原因主要是两个数据集之间发生了领域偏移,领域偏移又通常是因设备不同引起,因而影响分割模型的泛化能力。
为了解决上述问题,通常是通过增加数据集来提高泛化能力,但是医学数据集往往较难获得,从而泛化能力的提升有限。
技术实现要素:
为解决上述问题,提供一种能够解决不同设备或研究机构的医学数据集间领域偏移问题的纠正方法,本发明采用了如下技术方案:
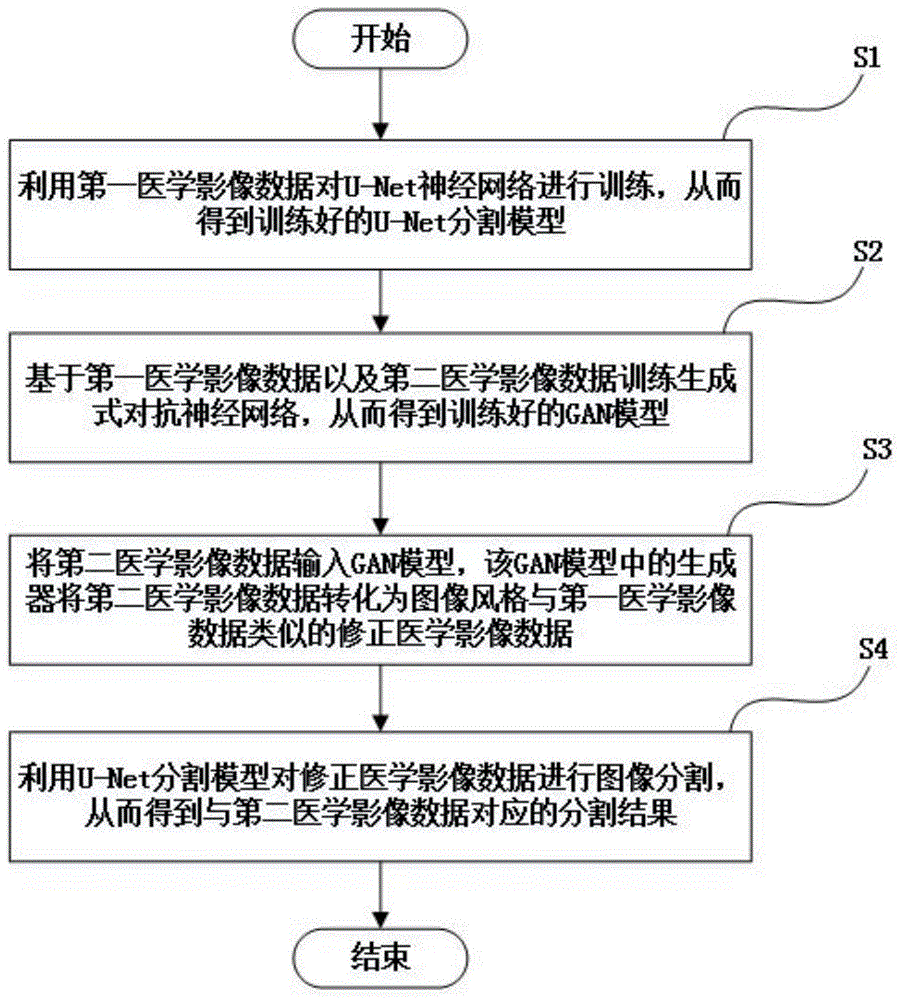
本发明提供了一种医学影像数据的图像分割方法,用于针对存在领域偏移的第一医学影像数据与第二医学影像数据进行图像分割,其特征在于,包括如下步骤:步骤s1,利用第一医学影像数据对u-net神经网络进行训练,从而得到训练好的u-net分割模型;步骤s2,基于第一医学影像数据以及第二医学影像数据训练生成式对抗神经网络,从而得到训练好的gan模型;步骤s3,将第二医学影像数据输入gan模型,该gan模型中的生成器将第二医学影像数据转化为图像风格与第一医学影像数据类似的修正医学影像数据;步骤s4,利用u-net分割模型对修正医学影像数据进行图像分割,从而得到与第二医学影像数据对应的分割结果。
根据本发明提供的一种医学影像数据的图像分割方法,还可以具有这样的技术特征,其中,gan模型的训练过程包括如下步骤:步骤t1,利用生成式对抗神经网络中的生成器对第二医学影像数据进行转换得到训练用医学影像数据;步骤t2,利用生成式对抗神经网络中的判别器判别训练用医学影像数据是否与第一医学影像数据风格类似,判别为真时进入步骤t3,判别为否时进入步骤t4;步骤t3,基于第一医学影像数据以及第二医学影像数据构建判别器的判别损失函数,基于该判别损失函数更新判别器,直到判别器判别为训练用医学影像数据与第一医学影像数据风格不类似;步骤t4,基于第一医学影像数据以及第二医学影像数据构建生成器的生成损失函数,基于该生成损失函数更新生成器,直到判别器判别为训练用医学影像数据与第一医学影像数据风格类似;步骤t5,重复步骤t3以及步骤t4,直到生成式对抗神经网络中的各层模型参数收敛,从而得到训练好的gan模型。
根据本发明提供的一种医学影像数据的图像分割方法,还可以具有这样的技术特征,其中,生成式对抗神经网络为pix2pix网络。
根据本发明提供的一种医学影像数据的图像分割方法,还可以具有这样的技术特征,其中,步骤s1包括如下子步骤:步骤s1-1,将第一医学影像数据分批次输入u-net神经网络中,从而完成一次迭代;步骤s1-2,对u-net神经网络中最后一层的模型参数计算出损失误差,基于该损失误差通过反向传播算法更新u-net神经网络;步骤s1-3,重复步骤s1-1至步骤s1-2直到u-net神经网络中各层模型参数收敛,从而得到u-net分割模型。
根据本发明提供的一种医学影像数据的图像分割方法,还可以具有这样的技术特征,其中,损失误差由交叉熵损失函数基于第一医学影像数据以及该第一医学影像数据对应的真实标签计算得到。
根据本发明提供的一种医学影像数据的图像分割方法,还可以具有这样的技术特征,其中,第一医学影像数据以及第二医学影像数据分别来自不同的设备或者研究机构。
发明作用与效果
根据本发明的一种医学影像数据的图像分割方法,由于gan模型中的生成器将第二医学影像数据转化为图像风格与第一医学影像数据类似的修正医学影像数据,因此,在一定程度上解决了第一医学影像数据与第二医学影像数据之间的领域偏移问题。另外,还由于基于第一医学影像数据训练得到的u-net分割模型能够对修正医学影像数据进行图像分割,从而得到与第二医学影像数据对应的分割结果,因此,提升了u-net分割模型的泛化性。
通过本发明的医学影像数据的图像分割方法,能够对来自不同设备或研究机构的医学影像数据进行图像分割,从而得到准确率较高的分割结果。
附图说明
图1为本发明实施例的一种医学影像数据的图像分割方法的流程图;
图2为本发明实施例的u-net神经网络的结构示意图;
图3为本发明实施例的pix2pix网络的流程示意图。
具体实施方式
为了使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,以下结合实施例及附图对本发明的一种医学影像数据的图像分割方法作具体阐述。
<实施例>
为了加快各个模型的训练过程,本实施例通过一张1080ti显卡进行gpu加速,并将训练完成的权重文件以及分割得到的分割结果存储在计算机中。
图1为本发明实施例的一种医学影像数据的图像分割方法的流程图。
如图1所示,一种医学影像数据的图像分割方法包括如下步骤:
步骤s1,利用第一医学影像数据对u-net神经网络进行训练,从而得到训练好的u-net分割模型。
其中,第一医学影像数据以及第二医学影像数据分别来自不同的设备或者研究机构,两者之间存在领域偏移。
本实施例中,第一医学影像数据来自philips设备,总共有44份;第二医学影像数据来自ge设备,总共有50份。
其中,步骤s1包括如下子步骤:
步骤s1-1,将第一医学影像数据分批次输入u-net神经网络(由深度学习框架pytorch完成模型的搭建)中,从而完成一次迭代。
其中,在将第一医学影像数据输入u-net神经网络之前,先对第一医学影像数据进行预处理,从而使得分辨率存在差距的第一医学影像数据变成分辨率统一的预处理医学影像数据,本实施例中,预处理方法至少包括将第一医学影像数据的分辨率统一强制转换为192*192大小的预处理医学影像数据。
本实施例中,第一医学影像数据的批次大小设置为16,迭代次数设为20。
图2为本发明实施例的u-net神经网络的结构示意图。
如图2所示,u-net神经网络的结构左侧为一个编码器,右侧为一个解码器,两侧呈对称。左右两侧都主要由卷积层、池化层、激活层、批量归一化层以及全连接层(即fc)等组成。
其中,编码器分为4个编码子模块,每个编码子模块包含两个3*3卷积层,每个卷积层(即conv)后面采用relu激活函数来对原始图片进行降采样操作,在每个编码子模块后会跟随一个2*2的最大池化层(maxpool)。卷积时使用的是valid模式,故后一个编码子模块的分辨率大小为前一个编码子模块的分辨率减去4的一半。
解码器包含4个解码子模块,分辨率通过上采样操作依次上升,直到与输入图像的分辨率大小一致。每个解码子模块由一个2*2的卷积层(激活函数也是relu)和两个3*3的卷积层组成。每一解码子模块的上采样(即up-conv)都会加入来自相对应收缩路径的特征图(经裁剪以保持相同的形状),从而实现融合(即concat)。
步骤s1-2,对u-net神经网络中最后一层的模型参数计算出损失误差,基于该损失误差通过反向传播算法更新u-net神经网络。
其中,损失误差由交叉熵损失函数基于第一医学影像数据以及该第一医学影像数据对应的真实标签计算得到。
步骤s1-3,重复步骤s1-1至步骤s1-2直到u-net神经网络中各层模型参数收敛,从而得到u-net分割模型。
本实施例中,u-net神经网络训练过程中还通过随机梯度下降算法进行参数优化,并将学习率设置为0.00001,从而训练得到u-net分割模型。
步骤s2,基于第一医学影像数据以及第二医学影像数据训练生成式对抗神经网络,从而得到训练好的gan模型。
其中,生成式对抗神经网络为pix2pix网络,属于生成式对抗网络(gan)中的一种,主要采用cgan网络的结构,包括了一个生成器和一个判别器。
其中,生成器是一个类似于u-net的结构,其结构类似encoder-decoder,总共包含15层。其中,8层卷积层作为encoder,7层反卷积层作为decoder,并引入了skip-connection,即每一层反卷积层的输入都是前一层的输出加上该层对称的卷积层的输出,从而保证encoder的信息在decoder时可以不断地被重新记忆,使得生成的图像尽可能保留原图像的一些信息。
图3为本发明实施例的pix2pix网络的流程示意图。
如图3所示,另外,gan模型的训练过程包括如下步骤:
步骤t1,利用生成式对抗神经网络(即pix2pix网络)中的生成器g对第二医学影像数据(即x)进行转换得到训练用医学影像数据。
步骤t2,利用生成式对抗神经网络中的判别器d判别训练用医学影像数据是否与第一医学影像数据y风格类似,判别为真时进入步骤t3,判别为否时进入步骤t4。
步骤t3,基于第一医学影像数据以及第二医学影像数据构建判别器的判别损失函数,基于该判别损失函数更新判别器,直到判别器判别为训练用医学影像数据与第一医学影像数据风格不类似。
步骤t4,基于第一医学影像数据以及第二医学影像数据构建生成器的生成损失函数,基于该生成损失函数更新生成器,直到判别器判别为训练用医学影像数据与第一医学影像数据风格类似。
步骤t5,重复步骤t3以及步骤t4,直到生成式对抗神经网络中的各层模型参数收敛,从而得到训练好的gan模型。
步骤s3,将第二医学影像数据输入gan模型,该gan模型中的生成器将第二医学影像数据转化为图像风格与第一医学影像数据类似的修正医学影像数据。
步骤s4,利用u-net分割模型对修正医学影像数据进行图像分割,从而得到与第二医学影像数据对应的分割结果。
为了验证本发明的医学影像数据的图像分割方法的效果,基于第一医学影像数据以及第二医学影像数据中的测试集进行测试。
利用u-net分割模型直接对第二医学影像数据中的测试集进行分割,分割结果的准确率为0.474;而本发明则先利用gan模型对第二医学影像数据中的测试集进行处理生成图像风格与第一医学影像数据类似的测试集,然后利用u-net分割模型对图像风格与第一医学影像数据类似的测试集进行图像分割,分割结果的准确率为0.892。因此,本发明的医学影像数据的图像分割方法能够有效解决不同设备或研究机构之间的医学影像数据之间的领域偏移问题。
实施例作用与效果
根据本实施例提供的一种医学影像数据的图像分割方法,由于gan模型中的生成器将第二医学影像数据转化为图像风格与第一医学影像数据类似的修正医学影像数据,因此,在一定程度上解决了第一医学影像数据与第二医学影像数据之间的领域偏移问题。另外,还由于基于第一医学影像数据训练得到的u-net分割模型能够对修正医学影像数据进行图像分割,从而得到与第二医学影像数据对应的分割结果,因此,提升了u-net分割模型的泛化性。
上述实施例仅用于举例说明本发明的具体实施方式,而本发明不限于上述实施例的描述范围。
- 还没有人留言评论。精彩留言会获得点赞!