一种基于先验知识的网约车相似地址识别方法与流程
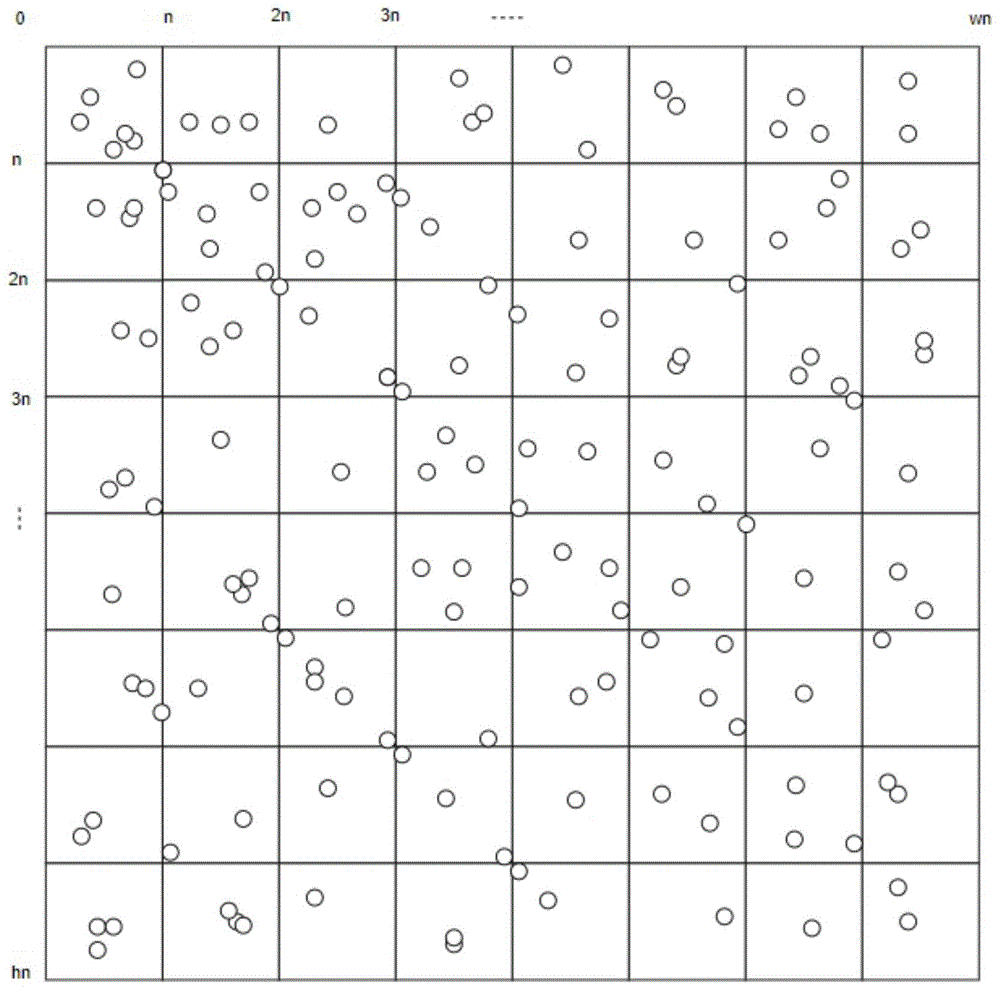
本发明涉及网约车、旅游等位置服务(lbs)领域,特别涉及一种基于先验知识的网约车相似地址识别方法。
背景技术:
:位置服务在互联网的发展中起重要作用,网约车行业中,需要位置服务定位司机和乘客的位置,以便司机及时找到乘客。而交通管制以及实际路况中,可用于上车点的位置是固定的几个。识别地理位置相似的点为同一个位置,把此位置作为用户常用的上车点的推荐,以及据此数据分析用户行为,构建知识图谱,提供个性化服务。业界以前提供的是文本相似度算法和判定2个地址为同一位置。这种算法因缺少地理经纬度信息,难以准确判断是同一位置。基于此,本发明公开了一种基于先验知识的网约车相似地址识别方法,能精确识别用户常用地址,作为推荐上车点。技术实现要素:本发明要解决的技术问题是克服现有技术的缺陷,提供一种基于先验知识的网约车相似地址识别方法。为了解决上述技术问题,本发明提供了如下的技术方案:本发明提供一种基于先验知识的网约车相似地址识别方法,包括以下步骤:s1、对于同一个城市,按经纬度划分方形单元网格,其起点为(0,n),(n,n),(2n,n),(3n,n)...,方形网格大小为n,城市分割为(w*n,h*n)的矩形,w*n为城市长度,h*n为城市宽度;s2、初始化文本相似度模型m,具体操作为把该城市所有地址使用word2vec建立模型,所得相似度模型函数记作g(e1,e2);s3、根据用户打车历史定位,统计城市内地址被使用次数k,记作k=f(e);s4、对单元网格内的地址,两两计算文本相似度r=g(e1,e2),相似度r>α归于一类,其中α为预设的参数,共计分为x类,同一类的存入集合,则得到独立集合q1,q2,q3…qx;s5、处理边界问题,按起点为(-n/2,-n/2),(n/2,n/2),(3n/2,n/2)...划分方形单元网格,处理虚线网格单元,两两计算文本相似度r=g(e1,e2),相似度r>α归于一类,其中α为预设的参数,共计分为y类,同一类的存入独立集合,则得到集合p1,p2,p3…py;s6、q1,q2,q3…qx与p1,p2,p3…py含有相同元素的合并,合并规则如下所示:i:qi(1≤i≤x)中元素若存在于pj(1≤j≤y)中,则对应的集合合并;ii:pj(1≤j≤y)中元素若存在于qi(1≤i≤x)中,则对应的集合合并;iii:qi(1≤i≤x)中元素若存在于qj(1≤j≤x)中,i≠j,则对应的集合合并;iv:pj(1≤j≤y)中元素若存在于pi(1≤i≤y)中,i≠j,则对应的集合合并;重复上述规则,直至不再有可合并的集合;最终形成h1,h2,h3…hw;hi∩hj=φ,(1≤i≤w,1≤j≤w,i≠j);s7、归于一类hi(1≤i≤w)的地址中,选择用户使用最多的地址作为等价地址uaddr,其他的地址作为表征地址vaddr,构造表征地址到等价地址的映射表t;s8、输出某城市的地址映射表t,映射表中的等价地址uaddr即为用户使用最多的常用地址,表征地址vaddr为被合并的地址;s9、网约车中用户呼叫时,获取到城市、经纬度、导航定位地址,去t中查询到对应的等价地址uaddr展示给用户使用,作为推荐上车点。与现有技术相比,本发明的有益效果如下:本发明提供了一种基于先验知识的网约车相似地址识别方法,计算地址相似度可用于识别出相同地址,对于构建知识图谱具有重要作用;传统的文本计算相似度的方法无法有效利用先验知识,具有准确率低的问题;对于网约车服务因具有城市,经纬度两项先验知识,在此基础上,可以提升识别准确率。附图说明附图用来提供对本发明的进一步理解,并且构成说明书的一部分,与本发明的实施例一起用于解释本发明,并不构成对本发明的限制。在附图中:图1是本发明的实施例示意图之一;图2是本发明的实施例示意图之二。具体实施方式以下结合附图对本发明的优选实施例进行说明,应当理解,此处所描述的优选实施例仅用于说明和解释本发明,并不用于限定本发明。实施例1本发明如图1-2所示,本发明提供一种基于先验知识的网约车相似地址识别方法,包括以下步骤:s1、对于同一个城市,按经纬度划分方形单元网格,其起点为(0,n),(n,n),(2n,n),(3n,n)...,方形网格大小为n,城市分割为(w*n,h*n)的矩形,w*n为城市长度,h*n为城市宽度(如图1所示,小圈代表地点e,小圈位于所划分的单元网格内);s2、初始化文本相似度模型m,具体操作为把该城市所有地址使用word2vec建立模型,所得相似度模型函数记作g(e1,e2);s3、根据用户打车历史定位,统计城市内地址被使用次数k,记作k=f(e);s4、对单元网格内的地址,两两计算文本相似度r=g(e1,e2),相似度r>α归于一类,其中α为预设的参数,共计分为x类,同一类的存入集合,则得到独立集合q1,q2,q3…qx;s5、处理边界问题,按起点为(-n/2,-n/2),(n/2,n/2),(3n/2,n/2)...划分方形单元网格,图2处理虚线网格单元,两两计算文本相似度r=g(e1,e2),相似度r>α归于一类,其中α为预设的参数,共计分为y类,同一类的存入独立集合,则得到集合p1,p2,p3…py;s6、q1,q2,q3…qx与p1,p2,p3…py含有相同元素的合并,合并规则如下所示:i:qi(1≤i≤x)中元素若存在于pj(1≤j≤y)中,则对应的集合合并;ii:pj(1≤j≤y)中元素若存在于qi(1≤i≤x)中,则对应的集合合并;iii:qi(1≤i≤x)中元素若存在于qj(1≤j≤x)中,i≠j,则对应的集合合并;iv:pj(1≤j≤y)中元素若存在于pi(1≤i≤y)中,i≠j,则对应的集合合并;重复上述规则,直至不再有可合并的集合;最终形成h1,h2,h3…hw;hi∩hj=φ,(1≤i≤w,1≤j≤w,i≠j);s7、归于一类hi(1≤i≤w)的地址中,选择用户使用最多的地址作为等价地址uaddr,其他的地址作为表征地址vaddr,构造表征地址到等价地址的映射表t,等价地址表征地址uaddr1vaddr1uaddr1vaddr2uaddr1vaddr3uaddr2vaddr4uaddr2vaddr5上表中,uaddr1,vaddr1,vaddr2,vaddr3为同一类地址;f(uaddr1)=max(f(e)),e∈hi={uaddr1,vaddr1,vaddr2,vaddr3};s8、输出某城市的地址映射表t,映射表中的等价地址uaddr即为用户使用最多的常用地址,表征地址vaddr为被合并的地址;s9、网约车中用户呼叫时,获取到城市、经纬度、导航定位地址,去t中查询到对应的等价地址uaddr展示给用户使用,作为推荐上车点。具体的,本发明提供了一种基于先验知识的网约车相似地址识别方法,计算地址相似度可用于识别出相同地址,对于构建知识图谱具有重要作用;传统的文本计算相似度的方法无法有效利用先验知识,具有准确率低的问题;对于网约车服务因具有城市,经纬度两项先验知识,在此基础上,可以提升识别准确率。最后应说明的是:以上所述仅为本发明的优选实施例而已,并不用于限制本发明,尽管参照前述实施例对本发明进行了详细的说明,对于本领域的技术人员来说,其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1