一种视频三维融合时GPU加速的视频纹理更新方法
本发明涉及视频编解码、视频gis和高性能处理领域,尤其涉及一种视频三维融合时gpu加速的视频纹理更新方法。
背景技术:
高速公路智能化、智慧化是当下公路运输的发展方向,是实现公路高效运输、安全运输和绿色运输的必然要求。视频监控系统是多媒体技术、计算机网络、工业控制和人工智能等多种技术的综合运用,以其直观方便、信息内容丰富等特点,更是一般安全防范系统的重要组成部分。视频影像具有来源广泛、信息获取方式灵活和实时传输方便等特点,能够提供实时动态、多角度、多方位的监控现场信息。
传统的视频监控系统一般是通过一组视频监视器观看,但这样观察到的视频影像信息容易超出了人类的观察、理解和反应能力。对于整个视频监控区域来说,所有的视频影像是分散、无组织的,监控人员常常需要盯住数十幅甚至上百幅视频影像画面并且对每一个幅视频影像都需要了解所对应摄像头的确切位置,这样不仅加大了监控人员的工作负荷程度,而且在面对大量独立的摄像机和视频画面的时候,进行监控并对图像进行解析,不可避免地会因为人员疲劳和信息不完整连贯而产生疏漏。另外,当对移动的目标进行跟踪时,也会由于画面切换而容易丢失。因此,传统的视频监控方式不利于从宏观上把握各视频监控场景的动态信息。
视频gis是地理信息行业当前热门的技术,综合利用增强虚拟技术、gis技术,将多源海量实时监控视频与统一的三维gis场景进行融合可视化,使监控视频空间化,增强了视频监控的整体性,有利于目标的跟踪分析和海量监控视频集成浏览。然而,现有的三维gis场景与多视频融合中的视频纹理更新方法主要基于传统的cpu处理,会与三维渲染系统抢占资源,导致三维gis场景渲染效率降低,而且现有方法能同时融入三维gis场景中的视频个数较少。
技术实现要素:
本发明利用gpu并行加速能力和与cpu相互独立运行的性质,提出了一种三维gis场景与多视频融合中基于gpu加速的视频纹理更新方法。
本发明的技术方案为一种视频三维融合时gpu加速的视频纹理更新方法,包括以下步骤:
步骤1,构建视频流数据集,所述视频流数据集由n个视频构成;
步骤2,判断步骤1所述的视频流数据集中每个视频在三维gis场景中对应融合的视频纹理的可见性,进一步构建多个待融合的视频;
步骤3,将步骤2所述的m个带融合的视频分别通过循环调用解复用方法、gpu硬解码得到每个视频对应的单帧yuv格式视频影像;
步骤4,将步骤3所述的每个视频对应的单帧yuv格式视频影像分别通过基于cuda加速的yuv2rgb算法得到相应的单帧rgb格式视频影像,并对存在畸变的视频影像进行基于cuda加速的图像畸变校正预处理,得到每个视频预处理后视频影像;
步骤5,将步骤4所述的每个视频预处理后视频影像利用cuda和opengl互操作技术由gpu中cuda内存空间拷贝到opengl内存空间;
步骤6,将步骤5所述的每个视频预处理后视频影像存储为二维视频纹理数组imgs,进一步将二维视频纹理数组imgs利用投影纹理算法融合到三维gis场景;
作为优选,步骤2具体如下:
计算三维gis场景中视频纹理中心点的世界坐标点对应的设备屏幕坐标点:
其中,
计算设备屏幕坐标点
设h表示用户观察窗口的长度,设w表示用户观察窗口的宽度;
若xc>0且xc<w且yc>0且yc<h满足时,则设备屏幕坐标点相对用户观察窗口可见,即对应的三维gis场景中视频纹理中心点的世界坐标点
否则,设备屏幕坐标点ci相对用户观察窗口不可见,即对应的三维gis场景中视频纹理中心点的世界坐标点不在用户视域内;
计算用户视点对应世界坐标点p(xp,yp,zp)和
其中,xp为用户视点对应世界坐标点p的x轴坐标分量,yp为用户视点对应世界坐标点p的y轴坐标分量,zp为用户视点对应世界坐标点p的z轴坐标分量,
对距离dk按升序进行排序,取前m(m<26且m≤k)个点
作为优选,步骤6具体如下:
计算世界坐标系中模型顶点坐标pw的公式如下,
pw=minvmmvpglv
其中,mmv为场景相机的模型视图变换矩阵,minv为三维gis场景相机视图变换矩阵的逆矩阵,pglv为模型坐标系中的模型顶点坐标;
计算世界坐标系中模型顶点法向量nv的公式如下,
nv=mat3(minvmmv)pgln
其中,mat3()表示去除齐次坐标后的变换矩阵,pgln为模型坐标系中的模型顶点法向量;
计算第i个虚拟投影相机裁剪坐标系中模型顶点坐标
其中,
计算模型顶点
其中,
在第i个虚拟投影相机视域范围内,计算虚拟投影相机视线向量和模型顶点法向量之间向量点积dotpi的公式如下,
其中,normalize()为向量正则化函数,dot()为向量点积函数,
计算模型顶点在第i个虚拟投影相机中的归一化屏幕坐标ti的公式如下,
其中,mn为归一化矩阵。
当模型顶点面向第i个虚拟投影相机,计算在第i个虚拟投影相机内归一化屏幕坐标对应深度图上深度值hi的公式如下,
其中,texture()表示纹理采样函数,depths为存储虚拟投影相机对应场景深度图的二维纹理数组,l为第i个视频对应migs和depths数组索引,
计算模型顶点深度值和深度图上对应深度值之间的大小关系来过滤被遮挡的朝向虚拟投影相机的模型顶点,若条件
计算上述模型顶点对应第i个视频纹理上颜色值的公式如下,
其中,texture()表示纹理采样函数,imgs为存储预处理后视频影像的二维纹理数组,表示从二维纹理数组imgs第l层视频纹理上根据屏幕坐标采样模型顶点颜色值。
本发明的优势在于:提出了一种三维gis场景与多视频融合中新的视频纹理更新方法,构建了一套完整的在gpu中进行视频解码、后处理与视频纹理更新的框架;能极大的释放cpu的计算压力,保证三维gis场景的渲染效率并大大提高了三维gis场景能够同时融合的视频个数,便于用户从全局角度对整个监控区域进行观察。
附图说明
图1:是本发明实施例与传统视频纹理方式的渲染效率对比图;
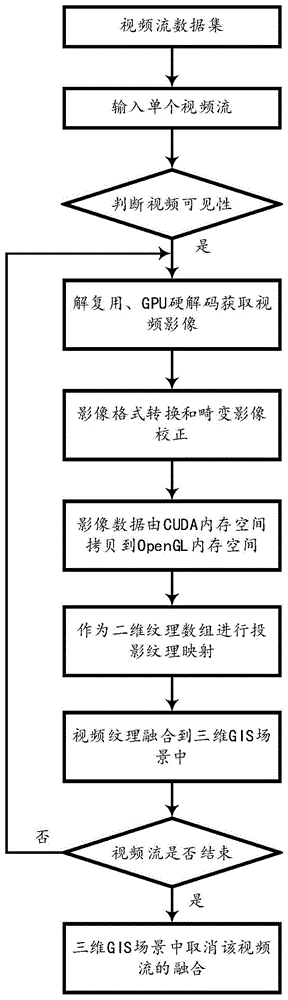
图2:是本发明实施例的总体流程图。
图3:是本发明实施例的视频硬解码流程图;
图4:是本发明实施例的原始广角影像和校正后广角影像对比图;
图5:是本发明实施例的多线程实时更新视频纹理流程图;
图6:是本发明实施例的后台线程操作流程图;
图7:是本发明实施例的三维gis场景多线程视频纹理更新流程图;
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,下面结合附图和具体实施对本发明做进一步描述,在此仅用本发明的适宜性实例说明来解释本发明,但并不作为本发明的限定。
本发明的关键在于将视频纹理更新这一计算量大、重复性强的工作交由gpu进行操作,利用gpu并行加速视频纹理更新中的视频解码、后处理以及视频纹理更新等操作。
如图1所示,传统的基于cpu处理的视频纹理更新方式随着三维gis场景中同时融合的视频个数的增加,三维gis场景的渲染效率也随之逐渐下降,且当同时融合视频个数超过14个时会导致整个系统的崩溃。但是,本发明实施例的方法不会影响三维gis场景的渲染效率,可以保证在三维gis场景中同时融合最少25个视频。
下面结合图2介绍本发明的具体实施例为一种三维gis场景与多视频融合中基于gpu加速的视频纹理更新方法,下述各步骤中对变量赋值,赋值方式如下:
步骤1,构建视频流数据集,所述视频流数据集由n个视频构成;
步骤2,判断步骤1所述的视频流数据集中每个视频在三维gis场景中对应融合的视频纹理的可见性,进一步构建多个待融合的视频;
步骤2具体如下:
计算三维gis场景中视频纹理中心点的世界坐标点对应的设备屏幕坐标点:
其中,
计算设备屏幕坐标点
设h=1024表示用户观察窗口的长度,设w=768表示用户观察窗口的宽度;
若xc>0且xc<w且yc>0且yc<h满足时,则设备屏幕坐标点相对用户观察窗口可见,即对应的三维gis场景中视频纹理中心点的世界坐标点
否则,设备屏幕坐标点ci相对用户观察窗口不可见,即对应的三维gis场景中视频纹理中心点的世界坐标点不在用户视域内;
计算用户视点对应世界坐标点p(xp,yp,zp)和
其中,xp为用户视点对应世界坐标点p的x轴坐标分量,yp为用户视点对应世界坐标点p的y轴坐标分量,zp为用户视点对应世界坐标点p的z轴坐标分量,
对距离dk按升序进行排序,取前m(m<26且m≤k)个点
步骤3,将步骤2所述的m个待融合的视频分别通过循环调用解复用方法、gpu硬解码得到每个视频对应的单帧yuv格式视频影像;
步骤4,将步骤3所述的每个视频对应的单帧yuv格式视频影像分别通过基于cuda加速的yuv2rgb算法得到相应的单帧rgb格式视频影像,并对存在畸变的视频影像进行基于cuda加速的图像畸变校正预处理,得到每个视频预处理后视频影像;
步骤5,将步骤4所述的每个视频预处理后视频影像利用cuda和opengl互操作技术由gpu中cuda内存空间拷贝到opengl内存空间;
步骤6,将步骤5所述的每个视频预处理后视频影像存储为二维视频纹理数组imgs,进一步将二维视频纹理数组imgs利用投影纹理算法融合到三维gis场景;
步骤6具体如下:
计算世界坐标系中模型顶点坐标pw的公式如下,
pw=minvmmvpglv
其中,mmv为场景相机的模型视图变换矩阵,minv为三维gis场景相机视图变换矩阵的逆矩阵,pglv为模型坐标系中的模型顶点坐标;
计算世界坐标系中模型顶点法向量nv的公式如下,
nv=mat3(minvmmv)pgln
其中,mat3()表示去除齐次坐标后的变换矩阵,pgln为模型坐标系中的模型顶点法向量;
计算第i个虚拟投影相机裁剪坐标系中模型顶点坐标
其中,
计算模型顶点
其中,
在第i个虚拟投影相机视域范围内,计算虚拟投影相机视线向量和模型顶点法向量之间向量点积dotpi的公式如下,
其中,normalize()为向量正则化函数,dot()为向量点积函数,
计算模型顶点在第i个虚拟投影相机中的归一化屏幕坐标ti的公式如下,
其中,mn为归一化矩阵。
当模型顶点面向第i个虚拟投影相机,计算在第i个虚拟投影相机内归一化屏幕坐标对应深度图上深度值hi的公式如下,
其中,texture()表示纹理采样函数,depths为存储虚拟投影相机对应场景深度图的二维纹理数组,l为第i个视频对应imgs和depths数组索引,
计算模型顶点深度值和深度图上对应深度值之间的大小关系来过滤被遮挡的朝向虚拟投影相机的模型顶点,若条件
计算上述模型顶点对应第i个视频纹理上颜色值的公式如下,
其中,texture()表示纹理采样函数,imgs为存储预处理后视频影像的二维纹理数组,表示从二维纹理数组imgs第l层视频纹理上根据屏幕坐标采样模型顶点颜色值。
本发明的第二实施例包括步骤如下:
步骤1,创建sqlite数据库并预先保存输入本地视频文件路径或网络视频的地址,以便系统运行时调用视频数据。其中,本地视频文件包含mp4、avi等视频格式,网络视频一般采用rtsp流媒体协议进行传输视频流。
步骤2,从步骤1所得数据库中读取视频源地址,解复用视频文件或网络视频流获取视频数据和视频相关信息,然后使用硬解码技术解码视频数据,获取yuv格式的视频影像。
步骤3,将步骤2所得的yuv格式视频影像转换为便于图像显示的rgb格式,以及对存在明显畸变的视频影像需要进行畸变纠正,如广角影像、全景影像等。
步骤4,通过cuda与opengl互操作技术直接利用步骤3所得的视频影像数据更新三维gis场景中视频融合区域的视频纹理以达到实时渲染的效果。
步骤5,利用多线程技术来实现多视频接入和视频纹理生成与更新来提高三维gis场景的渲染效率。其中,主线程(用户界面线程)用来处理虚拟三维场景的一般操作,后台线程用来处理视频纹理的实时生成和后处理操作,生成后的视频纹理交由主线程进行纹理更新。
步骤6,主线程逐帧渲染三维gis场景过程中,在opengl着色器中利用投影纹理算法将更新的视频纹理融合到三维gis场景中。
进一步,步骤2中解复用操作是使用ffmpeg开源计算机程序解复用视频文件或rtsp网络视频流,从音视频信号源中分流出不同的音频和视频比特流以及视频分辨率、编码格式等视频数据信息;然后利用编码格式初始化对应的视频硬解码器。
nvidiagpu包含一个或多个基于硬件的解码器videodecode(与cuda内核分开),可为多种流行的编解码器提供完全加速的基于硬件的视频解码和编码,且相对图形渲染和cpu计算可独立运行。本发明实例使用nvdecodeapi用于加速视频解码,解码类型包括mprg-2、vc-1、h264、h265、vp8、vp9和av1等编码格式。视频解码器将解复用获得的视频数据拷贝到gpu内存中,由videodecode解码器对视频数据进行解码获得视频影像数据。解码后的视频图像数据格式为yuv格式,不能直接用于图像渲染显示。如图3所示,gpu硬解码阶段包括五个主要步骤:
a)cuvidcreatedecoder创建一个特定编码格式的解码器,特定编码格式由视频解复用获得;
b)cuviddecodepicture调用videodecode解码一帧视频影像;
c)cuvidmapvideoframe获取解码后视频影像数据在gpu内存中的地址a,将解码后的视频影像数据拷贝到gpu内存中的新地址b;
d)cuvidunmapvideoframe释放地址a对应的gpu内存;
e)cuviddestroydecode销毁解码器。
进一步,步骤3对解码后的视频影像数据进行后处理,整个后处理过程都在gpu中进行,由cuda进行并行计算处理,具体包括:
1)根据影像数据yuv格式和rgb格式的转换公式,编写用于影像数据yuv格式转换到rgb格式的cuda核函数,利用cuda加速视频图像格式转换的过程;
式中y、u、v表示yuv格式影像在y、u、v三个通道上对应的颜色值,r、g、b表示rgb格式影像在r、g、b三个通道上对应的颜色值。
2)对于畸变较大的影像(如广角影像的桶形畸变和全景影像的全景畸变等)进行畸变校正,进而使影像校正到正常人眼不产生扭曲的程度。具体的,首先通过预处理获得原始影像和校正后影像之间的映射关系,然后通过双线性插值就可计算得到校正后影像:
式中,x和y表示校正后影像上p点的横坐标和纵坐标,x_0和y_0表示p点对应原始影像上的横坐标和纵坐标,mapx和mapy分别表示校正后影像像素坐标与原始影像像素坐标的映射矩阵,bilinear()表示双线性插值算法,(x,y)表示计算得到的点p的像素值。
视频影像畸变矫正过程中涉及大量的数值计算,结合视频解码后的影像数据本身就存储于显存中,本发明实例采用cuda并行计算加速影像的畸变校正。
具体步骤如下:
a)将mapx和mapy作为全局变量,仅初始化一次并拷贝到显存中;
b)结合mapx和mapy实现双线性插值算法的cuda核函数;
c)输入解码后的一帧视频影像,调用cuda核函数进行畸变校正,输出校正后的视频影像。视频影像校正前后对比如图4所示。
进一步,步骤4处理后的视频影像数据,利用cuda与opengl互操作技术来更新视频纹理,如图5,opengl纹理和cuda程序通过缓冲区共享数据,避免将显存中的视频影像数据拷贝至主存到作为纹理绑定到纹理单元上这中间的显存-主存、主存-显存的数据拷贝耗费的时间。cuda与opengl互操作技术可利用cuda处理后的视频影像数据实时更新opengl中的视频纹理数据,具体操作步骤如下:
a)利用cudagraphicsresource_t在cuda中注册资源buffer;
b)获取opengl纹理对象texid,利用cudagraphicsglregisterimage()将buffer注册给纹理对象texid
c)利用cudagraphicsmapresources()开启映射关系;
d)利用cudagraphicssubresourcegetmappedarray()将cudaarray绑定到资源对象buffer上,然后利用cudamemcpytoarray()将视频影像数据数据拷贝到buffer中;
e)利用cudagraphicsunmapresources()解除映射关系;
f)利用cudagraphicsunregisterresource()解除在cuda中注册的资源buffer。
进一步,步骤5中的单个后台线程完成视频解复用、视频硬解码和视频影像后处理整个流程,如图6所示,负责从视频中实时生成可以在三维gis场景中渲染的视频纹理数据;当三维gis场景中需要接入多个视频时,如图7所示,每个后台线程负责一个视频的视频纹理的实时生成,主线程按照步骤4的方法使用后台线程生成的视频纹理数据更新opengl中对应的视频纹理数据,然后将更新的视频纹理融合到三维gis场景中。
具体实施时,首先创建步骤1的数据库和搭建步骤5的多线程框架,然后确定三维gis场景中需要融合的视频纹理及其对应的视频,进而开启后台线程进行步骤2、步骤3和步骤4的操作,最后根据步骤5将不断更新视频纹理融合到三维gis场景中。具体实现视频纹理与三维gis场景融合属于现有技术中的方法,本发明不予赘述。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!