基于深度学习的MRI影像合成CT影像的方法
本发明属于计算机视觉领域以及医疗影像领域,涉及一种跨模态医学影像生成方法,具体涉及一种基于深度学习的mri影像合成ct影像的方法。
背景技术:
医学影像对于医学诊断及治疗具有重要意义。通常在诊断及治疗过程中,由于单一模态数据的局限性,医生需要通过不同模态的数据作为诊断依据以及辅助治疗。ct(计算机断层扫描)与mri(磁共振成像)往往是医生常用的参考影像。ct是目前图像引导放射治疗过程中常用的基准影像,能够提供制定放疗剂量计划所需要的密度信息,且有空间分辨率高,操作简洁的优点。然而相较于mri成像,其对软组织成像的对比度较差,并且扫描过程中存在的电离辐射可能会增加二次癌症的风险。mri影像与电子密度无直接联系,因而无法用于剂量计算以及患者的摆位验证,但其对软组织高对比度的成像有助于精确勾画靶区并观察相应变化。然而同时做ct及mri一定程度增加了患者的经济及身体负担,且通过影像配准技术对ct及mri影像进行空间上配准的方法可能存在误差,从而影响治疗的准确性。因而单独使用mri影像作为辅助放射治疗的方法是该领域的热点研究问题。
为了解决上述问题,早期研究人员使用手动或半自动的方法对mri影像的不同组织进行分割分类,通过分类结果为不同的组织人工分配相应的电子密度及衰减值从而获取合成ct。该方法工作量大且不具有泛化性,且实验结果与不同主体分割分类的精度相关性过高,因而对于不同主体,在准确度上存在较大差异。随后研究人员提出了基于图谱的方法,该方法基于图像空间域上两个模态影像的配准变换,实验的结果与配准的结果强相关。由于配准结果必然存在系统误差,该方法的实验结果对于前述问题的解决能力较差。随后研究人员着力于基于体素应用机器学习方法从而获取合成ct,具体方法主要分为回归及聚类,然而这些方法会受到解剖结构的局限。
近年来,随着深度学习的不断发展,一方面卷积神经网络及其发展在图像特征提取的分割、分类问题上效果显著;另一方面对抗式生成网络在图像域变换上的应用得到了良好的发展,对于非刚体的图像变换取得了显著的成果。而深度学习在医学图像领域的应用也随之称为热点问题。对于深度学习应用于跨模态的医学影像的生成问题,有研究人员提出了深度卷积神经网络基于mri生成ct的方法,该方法实验结果较前述方法在实验结果上存在较大改进。同时一些研究人员采用条件对抗生成网络作为生成器用于患者ct的合成问题。
然而,受限于样本数据量少,影像在采样重建的过程中丢失或扭曲关键信息等问题,造成实验结果精度不够,泛化性较差的场景一直存在。而在现实情况中,由于ct及mri成像原理的不同,及拍摄仪器、光照、技术、角度、以及位偏移等问题的存在也对实验结果产生一定影响,跨模态影像生成任务面临重重困难。并且医学影像本身对精度要求极高,生成影像必须具有与实际影像极为相似的特征以及分布信息才能够用于实际应用。
技术实现要素:
本发明是为了解决上述问题而进行的,目的在于提供一种基于深度学习的mri影像合成ct影像的方法,用于在已有的原始mri影像的基础上,通过深度学习中的全卷积神经网络与对抗式生成网络,以监督学习训练的方式跨模态生成相应的合成ct影像。
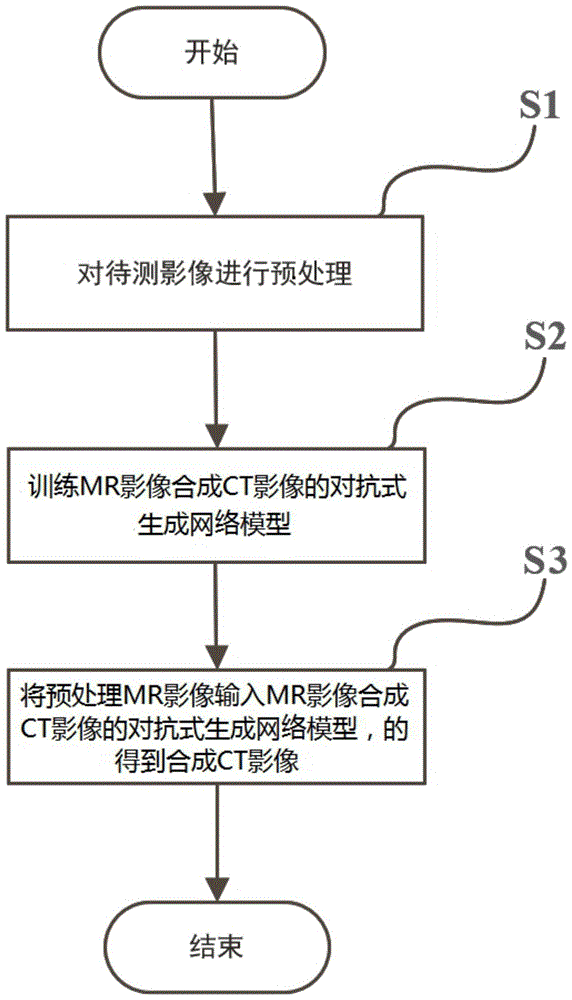
本发明提供了一种基于深度学习的mri影像合成ct影像的方法,具有这样的特征,包括如下步骤:
步骤s1,选取原始mri和ct影像分别作为浮动影像以及参考影像,而后进行n4偏置校正和标准化获得预处理后的mri及ct影像;
步骤s2,采用s1预处理mri影像和预处理ct影像训练用于将mri影像合成ct影像的对抗式生成网络模型;
步骤s3,将预处理mri影像输入mri影像合成ct影像的对抗式生成网络模型,从而将预处理mri影像转换为合成ct影像。
其中,mri影像合成ct影像的对抗式生成网络模型包括生成器网络和判别器网络,步骤s2具体包括如下子步骤:
步骤t1,构建mri影像合成ct影像的初始对抗式生成网络模型;
步骤t2,将多张预处理mri影像作为输入,经由生成器后得到合成sct影像,sct影像为预处理mri影像经由生成器网络后的合成ct影像;
步骤t3,将合成sct影像与相对应的经过s1步骤中预处理的真实ct影像作为判别器网络的训练集的训练数据,输入到判别器网络中并训练判别器网络;
步骤t4,将预处理mri影像和预处理ct影像的一次训练作为一个epoch,对训练数据重复步骤t2至步骤t3的训练过程,观察生成器网络的损失函数与判别器网络的损失函数直至收敛后停止训练,得到mri影像合成ct影像的对抗式生成网络模型。
在本发明提供的基于深度学习的mri影像合成ct影像的方法中,还可以具有这样的特征:其中,步骤t2具体包括如下子步骤:
步骤t2-1,将训练集中的各个mri训练影像依次输入构建好的mri影像合成ct影像的对抗式生成网络模型的生成器网络,并进行一次迭代;
步骤t2-2,迭代后的生成器网络输出的图像即为合成的sct影像,计算合成ct影像的对抗损失l1:
l1=lbce(d(g(x)),1)(1);
步骤t2-3,通过生成器网络的最后一层参数,算出合成ct影像与其对应的真实的预处理ct影像的欧氏距离l2:
l2=lg(x,y)=||y-gx)|22(2);
步骤t2-4,对生成器网络输出的合成ct影像,计算其与对应的标准ct影像之间的图像梯度差损失函数l3:
步骤t2-5,计算总损失函数lg:
lg=λ1l1+λ2l2+λ3l3(4);
步骤t2-6,对于训练集中的所有训练数据,重复步骤t2-1至步骤t2-5直至达到训练完成条件,得到训练后的mri影像合成ct影像的对抗式生成网络模型中的生成器网络,
式(1)-式(4)中,lbce表示对交叉熵损失范式的计算,计算方法为:
在本发明提供的基于深度学习的mri影像合成ct影像的方法中,还可以具有这样的特征:其中,步骤t3具体包括如下子步骤:
步骤t3-1,以mri影像合成ct影像的对抗式生成网络模型的生成器网络输出的合成ct影像作为判别器网络的输入,通过判别器网络计算该合成ct影像的特征及分布信息与真实ct影像的差异,并且计算出相应的损失函数ld:
步骤t3-2,通过损失函数ld以及判别器网络的最后一层参数,反向传播从而更新网络参数;
步骤t3-3,对于训练过程中生成器网络的不断优化,将其输出的合成ct影像作为输入,重复步骤t3-1至步骤t3-2,直至达到训练完成条件,得到训练后的mri影像合成ct影像的对抗式生成网络模型中的判别器网络,
式(5)中,g(x)表示原始mri影像经由生成器网络后得到的sct影像,y表示原始mri影像对应的真实ct影像,
在本发明提供的基于深度学习的mri影像合成ct影像的方法中,还可以具有这样的特征:其中,步骤t4中,判别器网络的损失函数的取值在[0,1]之间。
发明的作用与效果
根据本方面所涉及的基于深度学习的mri影像合成ct影像的方法,因为使用成对的mri影像与ct影像对初始模型进行监督训练,所以使得模型初步具备对mri影像转换为合成ct影像的性能,而后,采用主动学习方法并利用训练后的对抗式生成网络模型来对训练集以外的mri影像数据进行验证,因而能够将这些数据作为模型训练结果在精度上的评价标准。此外,本发明的基于深度学习的mri影像合成ct影像的方法能够通过对抗式生成网络模型高效地将不同模态的mri影像生成相应的合成ct影像,并对模型的泛化性能和精度在峰值信噪比等衡量指标上进行定量验证。
因此,采用本发明的基于深度学习的mri影像合成ct影像的方法,能够在已有的mri模态影像的基础上,通过深度学习中的全卷积神经网络与对抗式生成网络,以监督学习训练的方式跨模态生成相应的合成ct影像,且实验结果的精度高,场景的泛化性较好。
附图说明
图1是本发明的实施例中基于深度学习的mri影像合成ct影像方法的流程图;
图2是本发明的实施例中基于深度学习的mri影像合成ct影像方法训练步骤的流程图;
图3是本发明的实施例中基于深度学习的mri影像合成ct影像方法中生成器网络的结构示意图;
图4是本发明的实施例中基于深度学习的mri影像合成ct影像方法中判别器网络的结构示意图。
具体实施方式
为了使本发明实现的技术手段与功效易于明白了解,以下结合实施例及附图对本发明作具体阐述。
实施例:
本实施例的一种基于深度学习的mri影像合成ct影像方法通过一台计算机运行,该计算机需要一张显卡进行gpu加速从而完成模型的训练过程,训练完成的mri影像合成ct影像的对抗式生成网络模型模型以可执行代码的形式存储在计算机中。
本实施例中,采用的数据集为同一病例不同模态的mri影像及ct影像。
图1是本发明的实施例中基于深度学习的mri影像合成ct影像方法的流程图。
如图1所示,本实施例提供一种基于深度学习的mri影像合成ct影像的方法,用于在已有的原始mri影像的基础上跨模态生成相应的合成ct影像,包括如下步骤:
步骤s1,选取原始mri影像作和原始ct影像分别作为浮动影像以及和参考影像,而后进行n4偏置校正及标准化预处理获得预处理后的mri及ct影像。
图2是本发明的实施例中基于深度学习的mri影像合成ct影像方法训练步骤的流程图
步骤s2,采用预处理mri影像和预处理ct影像训练用于将mri影像合成ct影像的对抗式生成网络模型,如图2所示。
本实施例中,本实施例中,mri影像合成ct影像的对抗式生成网络模型是预先通过模型训练步骤训练获得的并处存在计算机中,计算机可以通过可执行代码调用该模型并同时批量处理多张mri影像,得到并输出每张mri影像通过网络模型转化后的合成ct影像。
本实施例中,mri影像合成ct影像的对抗式生成网络模型的输出维数是二维,表示原始mri影像经过深度学习网络模型的图像非线性变换后转化为的合成ct影像。
其中,mri影像合成ct影像的对抗式生成网络模型包括生成器网络和判别器网络,生成器网络用于将mri影像通过非线性图像变换转化为合成ct影像,判别器网络用于将生成器网络输出的合成ct影像与真实的对应ct影像作为对比,比较二者之间的差异性并计算损失函数。
在训练过程中,随着网络的训练,合成ct影像的质量将不断提升,判别器网络用于判别合成ct影像的准确性,是一个二分类器,且判别器网络以生成器网络的输出即合成ct影像及真实的ct影像作为输入,并且输出合成ct影像被判别为真实ct影像的定量标准。
图3是本发明的实施例中基于深度学习的mri影像合成ct影像方法中生成器网络的结构示意图,图4是本发明的实施例中基于深度学习的mri影像合成ct影像方法中判别器网络的结构示意图。
具体地,如图3所示,生成器网络为全卷积网络架构,包括依次设置的输入层、9个不同的卷积层以及输出层,由于使用了全卷积网络对三维影像特征进行提取,舍弃了传统卷积层中的全连接操作;如图4所示,判别器网络为卷积网络分类器模型架构,包括依次设置的输入层、4个不同的卷积层、最大池化层以及3个不同的全连接层。
本实施例中,步骤s2具体包括如下子步骤:
步骤t1,构建mri影像合成ct影像的初始对抗式生成网络模型,其中,模型包含生成器网络与判别器网络两个部分,生成器网络用于将mri影像通过非线性图像变换转化为合成ct影像,判别器网络用于将生成器网络输出的合成ct影像与真实的对应ct影像作为对比,比较二者之间的差异性并计算损失函数。
本实施例中,mri影像合成ct影像的初始对抗式生成网络模型的生成器网络以全卷积神经网络为骨干,判别器网络以传统卷积神经网络为骨干,利用现有的深度学习框架pytorch完成模型的搭建。同时,两个网络相互进行博弈,判别器网络的作用是判别生成器网络的输出图像是否与真实图像相似,生成器网络的作用是尽可能的使生成的合成ct影像能够通过判别器的判定,且网络结构中包含多层超参数,初始值以随机数生成的方式进行赋值;生成器网络由全卷积模块、relu激活层、批量归一化层(batchnormalization)、欧式距离及图像梯度损失模块构建而成,判别器网络由卷积层、relu激活层、sigmoid激活层、最大池化层、全连接层组成。具体网络结构将在后文中详述。
步骤t2,将多张预处理mri影像作为输入,经由生成器后得到合成sct影像,sct影像为预处理mri影像经由生成器网络后的合成ct影像。
本实施例中,进行初始训练时,合成ct影像可能不具有明显的ct影像特征,影像的质量将随着模型的训练逐渐提升,并最终具有与真实ct影像相近的结构,此外,将训练集中的mri影像分批次进入生成器网络模型中进行训练,步骤t2具体包括如下子步骤:
步骤t2-1,将训练集中的各个mri训练影像依次输入构建好的mri影像合成ct影像的对抗式生成网络模型的生成器网络,并进行一次迭代。
步骤t2-2,迭代后的生成器网络输出的图像即为合成ct影像,计算合成ct影像的对抗损失l1,其公式为:
l1=lbce(d(g(x)),1)(1)。
本实施例中,对抗损失l1作为衡量生成器作为判别器网络判别结果的有效性指标,用于约束生成器网络的生成影像质量。
步骤t2-3,通过生成器网络的最后一层参数,算出合成ct影像与其对应的真实的预处理ct影像的欧氏距离l2,其公式为:
l2=lg(x,y)=||y-g(x)||22(2)。
本实施例中,欧氏距离l2作为生成影像与真实影像的定量评价指标,表示二者之间的区别。
步骤t2-4,对生成器网络输出的合成ct影像,计算其与对应的标准ct影像之间的梯度差损失函数l3,并通过不同坐标轴位上的相邻像素差作为损失度量,其公式为:
步骤t2-5,计算总损失函数lg:
lg=λ1l1+λ2l2+λ3l3(4)。
步骤t2-6,对于训练集中的所有训练数据,重复步骤t2-1至步骤t2-5直至达到训练完成条件,得到训练后的mri影像合成ct影像的对抗式生成网络模型中的生成器网络。
式(1)-式(4)中,lbce表示对交叉熵损失范式的计算,计算方法为:
上述的生成器网络的训练过程中,每次迭代即训练图像通过网络后,网络的最后一层的网络参数会分别计算出损失误差函数,该损失误差函数包括交叉熵函数、欧式距离函数、梯度差损失函数三者的加权和,然后将计算得到的损失函数反向传播,采用自适应动量估计方法进行参数优化,学习率为10-6,从而更新网络参数。另外,生成器网络的训练的训练完成条件综合生成器网络与判别器网络二者的损失函数,当各层的模型参数大致收敛后完成训练。
步骤t3,将合成ct影像与相对应的真实的预处理ct影像作为判别器网络的训练集的训练数据,输入到判别器网络中并训练判别器网络,经由判别器网络判别两幅图像的之间的损失函数,损失函数的值表示两幅图像之间的相似性,即判别合成ct影像的真假。
本实施例中,将生成器网络生成的合成ct影像分批次进入判别器网络中进行训练,步骤t3具体包括如下子步骤:
步骤t3-1,以mri影像合成ct影像的对抗式生成网络模型的生成器网络输出的合成ct影像作为判别器网络的输入,通过判别器网络计算该合成ct影像的特征及分布信息与真实ct影像的差异,并且计算出相应的损失函数ld:
步骤t3-2,通过损失函数ld以及判别器网络的最后一层参数,反向传播从而更新网络参数;
步骤t3-3,对于训练过程中生成器网络的不断优化,将其输出的合成ct影像作为输入,重复步骤t3-1至步骤t3-2,直至达到训练完成条件,得到训练后的mri影像合成ct影像的对抗式生成网络模型中的判别器网络,
式中,g(x)表示原始mri影像经由生成器网络后得到的sct影像,y表示原始mri影像对应的真实ct影像,
经过上述迭代训练并在迭代过程中进行误差计算和反向传播的过程,即可获得训练完成的mri影像合成ct影像的对抗式生成网络模型中的判别器网络。
步骤t4,将预处理mri影像和预处理ct影像的一次训练作为一个epoch,对训练数据重复步骤t2至步骤t3的训练过程,观察生成器网络的损失函数与判别器网络的损失函数直至收敛后停止训练,得到mri影像合成ct影像的对抗式生成网络模型。
本实施例中,生成器网络的损失函数与判别器网络的损失函数的取值均在[0,1]之间,表示合成ct影像是否被判别为真实ct影像,0表示判别器认为合成ct影像为假,1表示判别器认为合成ct影像为真。
步骤s3,将预处理mri影像输入mri影像合成ct影像的对抗式生成网络模型,从而将预处理mri影像转换为合成ct影像。
本实施例中mri影像合成ct影像的对抗式生成网络模型学习到的是通过同一个人的mri图像及其ct图像特征之间的联系,从而跨模态的通过mri影像生成ct影像。
实施例的作用与效果
根据本实施例所涉及的基于深度学习的mri影像合成ct影像的方法,因为使用成对的mri影像与ct影像对初始模型进行监督训练,所以使得模型初步具备对mri影像转换为合成ct影像的性能,而后,采用主动学习方法并利用训练后的对抗式生成网络模型来对训练集以外的mri影像数据进行验证,因而能够将这些数据作为模型训练结果在精度上的评价标准。此外,本实施例的基于深度学习的mri影像合成ct影像的方法能够通过对抗式生成网络模型高效地将不同模态的mri影像生成相应的合成ct影像,并对模型的泛化性能和精度在峰值信噪比等衡量指标上进行定量验证。
因此,采用本实施例的基于深度学习的mri影像合成ct影像的方法,能够在已有的mri模态影像的基础上,通过深度学习中的全卷积神经网络与对抗式生成网络,以监督学习训练的方式跨模态生成相应的合成ct影像,且实验结果的精度高,场景的泛化性较好。
上述实施方式为本发明的优选案例,并不用来限制本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!